Hive SQL操作与函数自定义(二)
http://blog.csdn.net/u013980127/article/details/52606024
9 Operators and UDFs
9.1 内置运算符
9.1.1 关系运算符
| 操作符 | 运算对象的类型 | 描述 |
|---|---|---|
| A <=> B | ALL | 都是NULL时,返回TRUE,有一为NULL时,返回FALSE,都不为NULL时,与‘=’运算符一样。 |
| A <> B | ALL | A或B为NULL时,返回NULL,否则A不等于B是返回TRUE,反之FALSE。 |
| A RLIKE B | strings | A或B为NULL时,返回NULL,A的子串与正则表达式B匹配时,返回TRUE,反之FALSE。 |
| A REGEXP B | strings | 同A RLIKE B |
其他不在此列举。
9.1.2 算数运算符
只要有一个操作数为NULL,结果为NULL。
Arithmetic Operators
9.1.3 逻辑运算符
Logical Operators
9.1.4 复杂类型
| 构造函数 | 操作数 | 描述 |
|---|---|---|
| map | (key1, value1, key2, value2, …) | 创建map |
| struct | (val1, val2, val3, …) | 创建struct,属性名为col1, col2等 |
| named_struct | (name1, val1, name2, val2, …) | 创建struct |
| array | (val1, val2, …) | 创建array |
| create_union | (tag, val1, val2, …) | 创建tag指向的union |
9.1.5 复杂类型的运算符
| 运算符 | 操作数类型 | 描述 |
|---|---|---|
| A[n] | A是Array,n是int | 返回数组A的第n个值 |
| M[key] | M是Map |
返回key对应的value |
| S.x | S是struct | 返回属性x的值 |
9.2 内置函数
9.2.1 数学函数
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| DOUBLE | round(DOUBLE a) | 返回对a四舍五入的BIGINT值 |
| DOUBLE | round(DOUBLE a, INT d) | 小数部分d位之后数字四舍五入 |
| DOUBLE | bround(DOUBLE a) | 银行家舍入法(1~4:舍,6~9:进,5->前位数是偶:舍,5->前位数是奇:进) |
| DOUBLE | bround(DOUBLE a, INT d) | 银行家舍入法,保留d位小数 |
| BIGINT | floor(DOUBLE a) | 对给定数据进行向下舍入最接近的整数 |
| BIGINT | ceil(DOUBLE a) ceiling(DOUBLE a) |
将参数向上舍入为最接近的整数 |
| DOUBLE | rand() rand(INT seed) |
返回大于或等于0且小于1的平均分布随机数 |
| DOUBLE | exp(DOUBLE a) exp(DECIMAL a) |
返回e的n次方 |
| DOUBLE | ln(DOUBLE a) ln(DECIMAL a) |
返回给定数值的自然对数 |
| DOUBLE | log10(DOUBLE a) log10(DECIMAL a) |
返回给定数值的以10为底自然对数 |
| DOUBLE | log2(DOUBLE a) log2(DECIMAL a) |
返回给定数值的以2为底自然对数 |
| DOUBLE | log(DOUBLE base, DOUBLE a) log(DECIMAL base, DECIMAL a) |
返回给定底数及指数返回自然对数 |
| DOUBLE | pow(DOUBLE a, DOUBLE p) power(DOUBLE a, DOUBLE p) |
返回某数的乘幂 |
| DOUBLE | sqrt(DOUBLE a) sqrt(DECIMAL a) |
返回数值的平方根 |
| STRING | bin(BIGINT a) | 返回二进制格式 |
| string | hex(BIGINT a) hex(STRING a) hex(BINARY a) |
将整数、字符或二进制转换为十六进制格式 |
| binary | unhex(STRING a) | 十六进制字符转换由数字表示的字符。 |
| string | conv(BIGINT num, INT from_base, INT to_base) conv(STRING num, INT from_base, INT to_base) |
将指定数值,由原来的度量体系转换为指定的体系。例如CONV(‘a’,16,2),返回。参考:’1010′ |
| double | abs(DOUBLE a) | 取绝对值 |
| int or double | pmod(INT a, INT b) pmod(DOUBLE a, DOUBLE b) |
返回a除b的余数的绝对值 |
| double | sin(DOUBLE a) sin(DECIMAL a) |
返回给定角度的正弦值 |
| double | asin(DOUBLE a) asin(DECIMAL a) |
返回x的反正弦,即是X。如果X是在-1到1的正弦值,返回NULL。 |
| double | cos(DOUBLE a) cos(DECIMAL a) |
返回余弦 |
| double | acos(DOUBLE a) acos(DECIMAL a) |
返回X的反余弦,即余弦是X,,如果-1<= A <= 1,否则返回null. |
| double | tan(DOUBLE a) tan(DECIMAL a) |
求正切值 |
| double | atan(DOUBLE a) atan(DECIMAL a) |
求反正切值 |
| double | degrees(DOUBLE a) degrees(DECIMAL a) |
将弧度值转换角度值 |
| double | radians(DOUBLE a) radians(DOUBLE a) |
将角度值转换成弧度值 |
| int or double | positive(INT a) positive(DOUBLE a) |
返回A的值,例如positive(2),返回2。 |
| int or double | negative(INT a) negative(DOUBLE a) |
返回A的相反数,例如negative(2),返回-2。 |
| double or int | sign(DOUBLE a) sign(DECIMAL a) |
如果a是正数则返回1.0,是负数则返回-1.0,否则返回0.0 |
| double | e() | 数学常数e |
| double | pi() | 数学常数pi |
| BIGINT | factorial(INT a) | 求a的阶乘 |
| double | cbrt(DOUBLE a) | 求a的立方根 |
| int bigint |
shiftleft(TINYINT | SMALLINT | INT a, INT b) shiftleft(BIGINT a, INT b) |
按位左移 |
| int bigint |
shiftright(TINYINT | SMALLINT | INT a, INT b) shiftright(BIGINT a, INT b) |
按位右移 |
| int bigint |
shiftrightunsigned(TINYINT | SMALLINT | INT a, INT b) shiftrightunsigned(BIGINT a, INT b) |
无符号按位右移(<<<) |
| T | greatest(T v1, T v2, …) | 求最大值 |
| T | least(T v1, T v2, …) | 求最小值 |
9.2.2 集合函数
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| int | size(Map |
返回Map的大小 |
| int | size(Array |
返回Array的大小 |
| array |
map_keys(Map |
返回Map的key集合 |
| array |
map_values(Map |
返回Map的value集合 |
| boolean | array_contains(Array |
返回Array是否包含value |
| array |
sort_array(Array |
返回Array按自然顺序升序排列后的数组 |
9.2.3 类型转换函数
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| binary | binary(string | binary) | 转换参数为binary |
| Expected “=” to follow “type” | cast(expr as |
转换表达式expr为type类型,例如cast(‘1’ as BIGINT)。如果转换不成功,则返回null;非空字符串转换为boolean,返回true。 |
9.2.4 日期函数
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| string | from_unixtime(bigint unixtime[, string format]) | 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间格式 |
| bigint | unix_timestamp() | 获得当前时区的UNIX时间戳 |
| bigint | unix_timestamp(string date) | 转换格式为“yyyy-MM-dd HH:mm:ss“的日期到UNIX时间戳。如果转化失败,则返回0 |
| bigint | unix_timestamp(string date, string pattern) | 转换pattern格式的日期到UNIX时间戳。如果转化失败,则返回0。 |
| pre 2.1.0: string 2.1.0 on: date |
to_date(string timestamp) | 返回日期时间字段中的日期部分。 |
| int | year(string date) | 返回日期中的年。 |
| int | quarter(date/timestamp/string) | 返回第几季(1.3.0开始) |
| int | month(string date) | 返回日期中的月份 |
| int | day(string date) dayofmonth(date) | 返回日期中的天 |
| int | hour(string date) | 返回日期中的小时 |
| int | minute(string date) | 返回日期中的分钟 |
| int | second(string date) | 返回日期中的秒 |
| int | weekofyear(string date) | 返回日期在当前的周数 |
| int | datediff(string enddate, string startdate) | 返回结束日期减去开始日期的天数 |
| pre 2.1.0: string 2.1.0 on: date |
date_add(string startdate, int days) | 返回开始日期startdate增加days天后的日期 |
| pre 2.1.0: string 2.1.0 on: date |
date_sub(string startdate, int days) | 返回开始日期startdate减少days天后的日期 |
| timestamp | from_utc_timestamp(timestamp, string timezone) | 转换UTC时间为指定时区的时间 |
| timestamp | to_utc_timestamp(timestamp, string timezone) | 转换指定时区的时间为UTC时间 |
| date | current_date | 返回查询时的日期 |
| timestamp | current_timestamp | 返回查询时的时间 |
| string | add_months(string start_date, int num_months) | 返回当前时间下再增加num_months个月的日期,如果当前日期是最后一天,则计算后的日期也为最后一天 |
| string | last_day(string date) | 返回这个月的最后一天的日期,忽略时分秒部分(HH:mm:ss) |
| string | next_day(string start_date, string day_of_week) | 返回当前时间的下一个星期X所对应的日期。day_of_week是星期的2个、3个或整个单词 (e.g. Mo, tue, FRIDAY). |
| string | trunc(string date, string format) | 返回时间的最开始年份或月份 如trunc(“2016-06-26”,“MM”)=2016-06-01 trunc(“2016-06-26”,“YY”)=2016-01-01 注意所支持的格式为MONTH/MON/MM, YEAR/YYYY/YY |
| double | months_between(date1, date2) | 返回date1与date2之间相差的月份,如date1>date2,则返回正,如果date1 |
| string | date_format(date/timestamp/string ts, string fmt) | 按指定格式返回时间date 如:date_format(“2016-06-22”,”MM-dd”)=06-22 |
9.2.5 条件函数
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| T | if(boolean testCondition, T valueTrue, T valueFalseOrNull) | testCondition为true,返回valueTrue,否则返回valueFalseOrNull |
| boolean | isnull(a) | a为null时,返回true;否则返回false |
| boolean | isnotnull (a) | a不为null时,返回true;否则返回false |
| T | nvl(T value, T default_value) | value为null时,返回default_value,否则返回value |
| T | COALESCE(T v1, T v2, …) | 返回第一个不为null的值,都为null时,返回null |
| T | CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | 类似switch |
| T | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 类似if else语句 |
| T | nullif(a, b) | a = b时,返回null,否则返回a |
9.2.6 字符串函数
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| int | ascii(string str) | 返回str中首个ASCII字符串的整数值 |
| string | base64(binary bin) | 将二进制bin转换成base64的字符串 |
| string | chr(bigint | double A) | 返回ASCII字符,大于256,则A%256 |
| string | concat(string | binary A, string | binary B…) | 对二进制字节码或字符串按次序进行拼接 |
| array |
context_ngrams(array |
与ngram类似,但context_ngram()允许你预算指定上下文(数组)来去查找子序列 |
| string | concat_ws(string SEP, string A, string B…) | 与concat()类似,但使用指定的分隔符进行分隔 |
| string | concat_ws(string SEP, array |
拼接Array中的元素并用指定分隔符进行分隔 |
| string | decode(binary bin, string charset) | 使用指定的字符集charset将二进制值bin解码成字符串,支持的字符集有:’US-ASCII’, ‘ISO-8859-1’, ‘UTF-8’, ‘UTF-16BE’, ‘UTF-16LE’, ‘UTF-16’,如果任意输入参数为NULL都将返回NULL |
| binary | encode(string src, string charset) | 使用指定的字符集charset将字符串编码成二进制值,支持的字符集有:’US-ASCII’, ‘ISO-8859-1’, ‘UTF-8’, ‘UTF-16BE’, ‘UTF-16LE’, ‘UTF-16’,如果任一输入参数为NULL都将返回NULL |
| int | find_in_set(string str, string strList) | 返回以逗号分隔的字符串中str出现的位置,如果参数str为逗号或查找失败将返回0,如果任一参数为NULL将返回NULL回 |
| string | format_number(number x, int d) | 将数值X转换成”#,###,###.##”格式字符串,并保留d位小数,如果d为0,将进行四舍五入且不保留小数 |
| string | get_json_object(string json_string, string path) | 从指定路径上的JSON字符串抽取出JSON对象,并返回这个对象的JSON格式,如果输入的JSON是非法的将返回NULL,注意此路径上JSON字符串只能由数字 字母 下划线组成且不能有大写字母和特殊字符,且key不能由数字开头,这是由于Hive对列名的限制 |
| boolean | in_file(string str, string filename) | 如果文件名为filename的文件中有一行数据与字符串str匹配成功就返回true |
| int | instr(string str, string substr) | 查找字符串str中子字符串substr出现的位置,如果查找失败将返回0,如果任一参数为Null将返回null,注意位置为从1开始的 |
| int | length(string A) | 返回字符串的长度 |
| int | locate(string substr, string str[, int pos]) | 查找字符串str中的pos位置后字符串substr第一次出现的位置 |
| string | lower(string A) lcase(string A) | 将字符串A的所有字母转换成小写字母 |
| string | lpad(string str, int len, string pad) | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从左侧填补。 |
| string | ltrim(string A) | 删除字符串左边的空格,其他的空格保留 |
| array |
ngrams(array |
返回出现次数TOP K的的子序列,n表示子序列的长度 |
| string | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 返回从URL中抽取指定部分的内容,参数url是URL字符串,而参数partToExtract是要抽取的部分,这个参数包含(HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO,例如:parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘HOST’) =’facebook.com’,如果参数partToExtract值为QUERY则必须指定第三个参数key 如:parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘QUERY’, ‘k1’) =‘v1’ |
| string | printf(String format, Obj… args) | 按照printf风格格式输出字符串 |
| string | regexp_extract(string subject, string pattern, int index) | 抽取字符串subject中符合正则表达式pattern的第index个部分的子字符串,注意些预定义字符的使用,如第二个参数如果使用’\s’将被匹配到s,’\\s’才是匹配空格 |
| string | regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) | 按照Java正则表达式PATTERN将字符串INTIAL_STRING中符合条件的部分成REPLACEMENT所指定的字符串,如里REPLACEMENT这空的话,抽符合正则的部分将被去掉 如:regexp_replace(“foobar”, “oo|ar”, “”) = ‘fb.’ 注意些预定义字符的使用,如第二个参数如果使用’\s’将被匹配到s,’\\s’才是匹配空格 |
| string | repeat(string str, int n) | 重复输出n次字符串str |
| string | replace(string A, string OLD, string NEW) | 置换字符串 |
| string | reverse(string A) | 反转字符串 |
| string | rpad(string str, int len, string pad) | 从右边开始对字符串str使用字符串pad填充,最终len长度为止,如果字符串str本身长度比len大的话,将去掉多余的部分 |
| string | rtrim(string A) | 去掉字符串后面出现的空格 |
| array |
sentences(string str, string lang, string locale) | 字符串str将被转换成单词数组,如:sentences(‘Hello there! How are you?’) =( (“Hello”, “there”), (“How”, “are”, “you”) ) |
| string | space(int n) | 返回n个空格 |
| array | split(string str, string pat) | 按照正则表达式pat来分割字符串str,并将分割后的数组字符串的形式返回 |
| map |
str_to_map(text[, delimiter1, delimiter2]) | 将字符串str按照指定分隔符转换成Map,第一个参数是需要转换字符串,第二个参数是键值对之间的分隔符,默认为逗号;第三个参数是键值之间的分隔符,默认为”=” |
| string | substr(string | binary A, int start) substring(string | binary A, int start) |
对于字符串A,从start位置开始截取字符串并返回 |
| string | substr(string | binary A, int start, int len) substring(string | binary A, int start, int len) |
对于二进制/字符串A,从start位置开始截取长度为length的字符串并返回 |
| string | substring_index(string A, string delim, int count) | 截取第count分隔符之前的字符串,如count为正则从左边开始截取,如果为负则从右边开始截取 |
| string | translate(string | char | varchar input, string | char | varchar from, string | char | varchar to) | 将input出现在from中的字符串替换成to中的字符串 如:translate(“MOBIN”,”BIN”,”M”)=”MOM” |
| string | trim(string A) | 将字符串A前后出现的空格去掉 |
| binary | unbase64(string str) | 将64位的字符串转换二进制值 |
| string | upper(string A) ucase(string A) |
将字符串A中的字母转换成大写字母 |
| string | initcap(string A) | 将字符串A转换第一个字母大写其余字母的字符串 |
| int | levenshtein(string A, string B) | 计算两个字符串之间的差异大小 如:levenshtein(‘kitten’, ‘sitting’) = 3 |
| string | soundex(string A) | 将普通字符串转换成soundex字符串 |
9.2.7 数据脱敏函数(2.1.0新增)
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| string | mask(string str[, string upper[, string lower[, string number]]]) | 默认大写字母转化为’X’,小写字母转换为’x’,数字转换为“n”。通过参数可以修改掩码,例如:mask(“abcd-EFGH-8765-4321”, “U”, “l”, “#”) 返回”llll-UUUU-####-####”. |
| string | mask_first_n(string str[, int n]) | 转换方式同上默认处理,只处理前n个字符。mask_first_n(“1234-5678-8765-4321”, 4)返回”nnnn-5678-8765-4321” |
| string | mask_last_n(string str[, int n]) | 同上,但只处理最后n个字符 |
| string | mask_show_first_n(string str[, int n]) | 只显示前n个字符,其他同上 |
| string | mask_show_last_n(string str[, int n]) | 只显示最后n个字符,其他同上 |
| string | mask_hash(string | char | varchar str) | 返回str的哈希值,可以用于表连接 |
9.2.8 其他函数
9.2.8.1 函数列表
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| varies | java_method(class, method[, arg1[, arg2..]]) | 同反射 |
| varies | reflect(class, method[, arg1[, arg2..]]) | 同反射 |
| int | hash(a1[, a2…]) | 返回参数的哈希值 |
| string | current_user() | 返回当前用户 |
| string | current_database() | 返回当前数据库 |
| string | md5(string/binary) | 返回MD5(128位校验码) |
| string | sha1(string/binary) sha(string/binary) |
返回SHA-1摘要 |
| bigint | crc32(string/binary) | 返回CRC |
| string | sha2(string/binary, int) | 返回SHA-2,参数2: 224, 256, 384, 512, 或 0(=256)中的一个,表示SHA-224, SHA-256, SHA-384, SHA-512。base64(aes_encrypt(‘ABC’, ‘1234567890123456’)) = ‘y6Ss+zCYObpCbgfWfyNWTw==’. |
| binary | aes_encrypt(input string/binary, key string/binary) | AES加密,key的长度必须是128、192或256位。aes_decrypt(unbase64(‘y6Ss+zCYObpCbgfWfyNWTw==’), ‘1234567890123456’) = ‘ABC’. |
| binary | aes_decrypt(input binary, key string/binary) | AES解密 |
| string | version() | 返回Hive版本(2.1.0) |
9.2.8.2 xpath
用于解析XML,javax.xml.xpath的封装。基于XPath 1.0。
XPath
XPathUDF
9.2.8.3 get_json_object
| 字符 | 含义 |
|---|---|
| & | 根 |
| . | 子 |
| [] | 数组下标 |
| * | []的通配符 |
9.3 内置聚合函数(UDAF)
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| BIGINT | count(*) | 统计总行数,包括含有NULL值的行 |
| BIGINT | count(expr) | 统计提供非NULL的expr表达式值的行数 |
| BIGINT | count(DISTINCT expr[, expr…]) | 统计提供非NULL且去重后的expr表达式值的行数 |
| DOUBLE | sum(col) sum(DISTINCT col) |
求指定列的和 |
| DOUBLE | avg(col) avg(DISTINCT col) |
求指定列的平均值 |
| DOUBLE | min(col) | 求指定列的最小值 |
| DOUBLE | max(col) | 求指定列的最大值 |
| DOUBLE | variance(col) var_pop(col) |
求指定列数值的方差 |
| DOUBLE | var_samp(col) | 求指定列数值的样本方差 |
| DOUBLE | stddev_pop(col) | 求指定列数值的标准偏差 |
| DOUBLE | stddev_samp(col) | 求指定列数值的样本标准偏差 |
| DOUBLE | covar_pop(col1, col2) | 求指定列数值的协方差 |
| DOUBLE | covar_samp(col1, col2) | 求指定列数值的样本协方差 |
| DOUBLE | corr(col1, col2) | 返回两列数值的相关系数 |
| DOUBLE | percentile(BIGINT col, p) | 返回数值区域的百分比数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| array |
percentile(BIGINT col, array(p1 [, p2]…)) | 返回数值区域的一组百分比值分别对应的数值点。0<=P<=1,否则返回NULL,不支持浮点型数值 |
| DOUBLE | percentile_approx(DOUBLE col, p [, B]) | 求近似的第pth个百分位数,p必须介于0和1之间,返回类型为double,但是col字段支持浮点类型。参数B控制内存消耗的近似精度,B越大,结果的准确度越高。默认为10,000。当col字段中的distinct值的个数小于B时,结果为准确的百分位数 |
| array |
percentile_approx(DOUBLE col, array(p1 [, p2]…) [, B]) | 功能和上述类似,之后后面可以输入多个百分位数,返回类型也为array |
| array |
histogram_numeric(col, b) | 以b为基准计算col的直方图信息。 |
| array | collect_set(col) | 返回无重复记录 |
| array | collect_list(col) | 返回记录list |
| INTEGER | ntile(INTEGER x) | 用于将分组数据按照顺序切分成n片,返回当前切片值 |
9.4 内置Table-Generating函数(UDTF)
9.4.1 函数列表
| 返回类型 | 函数名 | 描述 |
|---|---|---|
| N rows | explode(ARRAY) | 每行对应数组中的一个元素 |
| N rows | explode(MAP) | 每行对应每个map键-值,其中一个字段是map的键,另一个字段是map的值 |
| 无 | inline(ARRAY |
将结构体数组提取出来并插入到表中 |
| array | explode(array\ a) | 对于a中的每个元素,将生成一行且包含该元素 |
| tuple | json_tuple(jsonStr, k1, k2, …) | 从一个JSON字符串中获取多个键并作为一个元组返回,与get_json_object不同的是此函数能一次获取多个键值 |
| tuple | parse_url_tuple(url, p1, p2, …) | 返回从URL中抽取指定N部分的内容,参数url是URL字符串,而参数p1,p2,….是要抽取的部分,这个参数包含HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO, QUERY:\ |
| N rows | posexplode(ARRAY) | 与explode类似,不同的是还返回各元素在数组中的位置 |
| N rows | stack(INT n, v_1, v_2, …, v_k) | 把v_1, v_2, …, v_k转换成N行,每行有M/N个字段,其中n必须是个常数 |
限制:
1. SELECT里面不能有其它字段;
2. 不能嵌套;
3. 不支持GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY。
9.5 GROUPing与SORTing
函数的别名不能用于group by或sort by,例如下面例子
select f(col) as fc, count(*) from table_name group by fc;有两种变通方法:
1. 使用子查询;
2. 在group by或sort by中使用函数。
9.6 自定义函数
9.6.1 步骤
- 继承UDF、UDAF或UDTF,实现特定方法;
- 将写好的类打包为jar。例如hive-demo.jar;
- 进入Hive外壳环境中,利用add jar /home/zkpk/doc/hive/hive-demo.jar注册该jar文件;
- 为该类起别名,create temporary function mylength as ‘com.whut.StringLength’; 注意,只是会话临时定义。
- 使用mylength。
9.6.2 UDF
操作单个数据行,产生单个数据行;
package com.zw.hive.w4;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
*
* 计算src中包含word的个数
*
*
* UDF是作用于单个数据行,产生一个数据行;
* 用户必须要继承UDF,且必须至少实现一个evalute方法,该方法并不在UDF中
* 但是Hive会检查用户的UDF是否拥有一个evalute方法
*
*
* Created by zhangws on 16/8/27.
*/
public class CountSpecifyWordUDF extends UDF {
/**
* 计算src中包含word的个数
* @param src src
* @param word word
* @return counter
*/
public int evaluate(String src, String word) {
try {
int counter=0;
if (!src.contains(word)) {
return 0;
}
int pos;
while((pos = src.indexOf(word)) != -1){
counter++;
src = src.substring(pos + word.length());
}
return counter;
} catch (Exception e) {
return 0;
}
}
}9.6.3 UDAF
操作多个数据行,产生一个数据行。
编写通用型UDAF需要两个类:解析器和计算器。
9.6.3.1 解析器
负责UDAF的参数检查,操作符的重载以及对于给定的一组参数类型来查找正确的计算器。继承AbstractGenericUDAFResolver。
package com.zw.hive.w4.udaf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
/**
* 计算分组中的最大值(获取计算器)
*
*
* add jar /home/zkpk/doc/hive-demo.jar;
* CREATE TEMPORARY FUNCTION collectList AS 'com.zw.hive.w4.udaf.CollectListUDAFResolver';
*
*
* 数据准备(udaf_demo_data_1)
* 1,a
* 1,a
* 1,b
* 2,c
* 2,d
* 2,d
* 创建表
create external table hive_udaf_data_1 (
id int,
value string
)
comment 'UDAF演示表'
row format delimited fields terminated by ','
stored as textfile location '/hw/hive/udaf/1';
*
* 加载数据
* load data local inpath '/home/zkpk/doc/hive/udaf_demo_data_1' overwrite into table hive_udaf_data_1;
*
* 执行SQL
* SELECT id, collectList(value) FROM hive_udaf_data_1 GROUP BY id;
*
*
*
* Created by zhangws on 16/9/18.
*/
public class CollectListUDAFResolver extends AbstractGenericUDAFResolver {
/**
* 返回计算器
*
* @param parameters
*
* @return
*
* @throws SemanticException
*/
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters)
throws SemanticException {
if (parameters.length != 1) {
throw new UDFArgumentTypeException(parameters.length - 1, "Exactly one argument is expected.");
}
if (parameters[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentTypeException(0, "Only primitive type arguments are accepted.");
}
return new CollectListUDAFEvaluator();
}
}9.6.3.2 计算器
计算器实现具体的计算逻辑,需要继承GenericUDAFEvaluator抽象类。
计算器有4种模式,由枚举类GenericUDAFEvaluator.Mode定义:
public static enum Mode {
PARTIAL1, //从原始数据到部分聚合数据的过程(map阶段),将调用iterate()和terminatePartial()方法。
PARTIAL2, //从部分聚合数据到部分聚合数据的过程(map端的combiner阶段),将调用merge() 和terminatePartial()方法。
FINAL, //从部分聚合数据到全部聚合的过程(reduce阶段),将调用merge()和 terminate()方法。
COMPLETE //从原始数据直接到全部聚合的过程(表示只有map,没有reduce,map端直接出结果),将调用merge() 和 terminate()方法。
}; 计算器必须实现的方法:
1、getNewAggregationBuffer():返回存储临时聚合结果的AggregationBuffer对象。
2、reset(AggregationBuffer agg):重置聚合结果对象,以支持mapper和reducer的重用。
3、iterate(AggregationBuffer agg,Object[] parameters):迭代处理原始数据parameters并保存到agg中。
4、terminatePartial(AggregationBuffer agg):以持久化的方式返回agg表示的部分聚合结果,这里的持久化意味着返回值只能Java基础类型、数组、基础类型包装器、Hadoop的Writables、Lists和Maps。
5、merge(AggregationBuffer agg,Object partial):合并由partial表示的部分聚合结果到agg中。
6、terminate(AggregationBuffer agg):返回最终结果。
通常还需要覆盖初始化方法ObjectInspector init(Mode m,ObjectInspector[] parameters)。
示例
package com.zw.hive.w4.udaf;
import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.*;
import org.apache.hadoop.io.Text;
import java.util.Collections;
import java.util.List;
import java.util.Map;
/**
* 实现按分组中元素的出现次数降序排序,并将每个元素的在分组中的出现次数也一起返回,格式为:[data1, num1, data2, num2, ...]
*
* Created by zhangws on 16/9/19.
*/
public class CollectListUDAFEvaluator extends GenericUDAFEvaluator {
protected PrimitiveObjectInspector inputKeyOI;
protected StandardListObjectInspector loi;
protected StandardListObjectInspector internalMergeOI;
/**
*
*
* m:
* PARTIAL1 和 COMPLETE 时, parameters为原始数据;
* PARTIAL2 和 FINAL 时, parameters仅为部分聚合数据(只有一个元素)
*
* PARTIAL1 和 PARTIAL2 时, terminatePartial方法的返回值;
* FINAL 和 COMPLETE 时, terminate方法的返回值.
*
*
*
* @param m 模式
* @param parameters 数据参数
*
* @return
*
* @throws HiveException
*/
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);
if (m == Mode.PARTIAL1) { // 从原始数据到部分聚合数据的过程(map阶段),将调用iterate()和terminatePartial()方法。
inputKeyOI = (PrimitiveObjectInspector) parameters[0];
return ObjectInspectorFactory.getStandardListObjectInspector(
ObjectInspectorUtils.getStandardObjectInspector(inputKeyOI));
} else {
if (parameters[0] instanceof StandardListObjectInspector) {
internalMergeOI = (StandardListObjectInspector) parameters[0];
inputKeyOI = (PrimitiveObjectInspector) internalMergeOI.getListElementObjectInspector();
loi = (StandardListObjectInspector) ObjectInspectorUtils.getStandardObjectInspector(internalMergeOI);
return loi;
} else {
inputKeyOI = (PrimitiveObjectInspector) parameters[0];
return ObjectInspectorFactory.getStandardListObjectInspector(
ObjectInspectorUtils.getStandardObjectInspector(inputKeyOI));
}
}
}
static class MkListAggregationBuffer extends AbstractAggregationBuffer {
List结果
1 ["a","2","b","1"]
2 ["d","2","c","1"]9.6.4 UDTF
操作一个数据行,产生多个数据行一个表作为输出。
- 继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
- UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
- 初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
- 最后close()方法调用,对需要清理的方法进行清理。
示例:
将字符串(key1:20;key2:30;key3:40)按照分好拆分行按照冒号拆分列进行展示。
package com.zw.hive.w4.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
/**
*
*
* 1. 继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
* 2. UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
* 3. 初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;
* 如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
* 4. 最后close()方法调用,对需要清理的方法进行清理。
* 5. 代码实例,实现的功能比较简单,将字符串(key1:20;key2:30;key3:40)按照分好拆分行按照冒号拆分列进行展示。
*
*
*
*
* hive-demo.jar放到${HIVE_HOME}/auxli目录下
* CREATE TEMPORARY FUNCTION explode_map AS 'com.zw.hive.w4.udtf.ExplodeMapUDTF';
*
* 准备数据(hive_udtf_demo_data_1)
* key1:20;key2:30;key3:40
*
create external table udtf_demo_data_1 (
value string
);
* 加载数据
* load data local inpath '/home/zkpk/doc/hive/udtf_demo_data_1' overwrite into table udtf_demo_data_1;
*
* SELECT explode_map(value) AS (col1,col2) from udtf_demo_data_1;
*
*
*
* Created by zhangws on 16/9/18.
*/
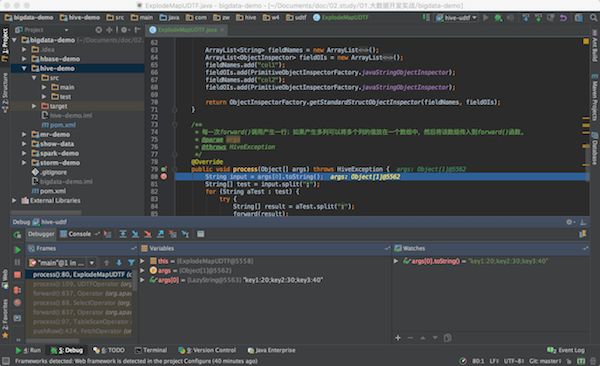
public class ExplodeMapUDTF extends GenericUDTF {
/**
* 返回UDTF的返回行的信息(返回个数,类型)
* @param args
* @return
* @throws UDFArgumentException
*/
@Override
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
}
if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("ExplodeMap takes string as a parameter");
}
ArrayList fieldNames = new ArrayList();
ArrayList fieldOIs = new ArrayList();
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("col2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
/**
* 每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
* @param args
* @throws HiveException
*/
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
String[] test = input.split(";");
for (String aTest : test) {
try {
String[] result = aTest.split(":");
forward(result);
} catch (Exception e) {
// nothing
}
}
}
/**
* 对需要清理的方法进行清理。
* @throws HiveException
*/
@Override
public void close() throws HiveException {
}
} 结果
hive> CREATE TEMPORARY FUNCTION explode_map AS 'com.zw.hive.w4.udtf.ExplodeMapUDTF';
OK
Time taken: 0.02 seconds
hive> SELECT explode_map(value) AS (col1,col2) from udtf_demo_data_1;
OK
key1 20
key2 30
key3 409.6.5 添加自定义函数的jar文件
使用add path/test.jar
缺点是每次启动Hive的时候都要新加入。配置hive-site.xml加入
<property> <name>hive.aux.jars.pathname> <value>file:///jarpath/all_new1.jar,file:///jarpath/all_new2.jarvalue> property>在${HIVE_HOME}中创建文件夹auxlib,然后将自定义jar文件放入该文件夹中。
9.6.6 调试
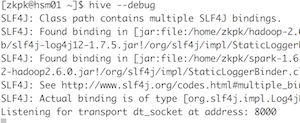
以debug模式启动Cli,${HIVE_HOME}/bin/hive –debug。进程会监听在8000端口等待调试连接。如果想更改监听端口,可以修改配置文件:
${HIVE_HOME}bin/ext/debug.sh 。在Eclipse中, 选择Debug configurations->Remote Java Application,填好Host和Port,并选中包含UDF的工程,确定。
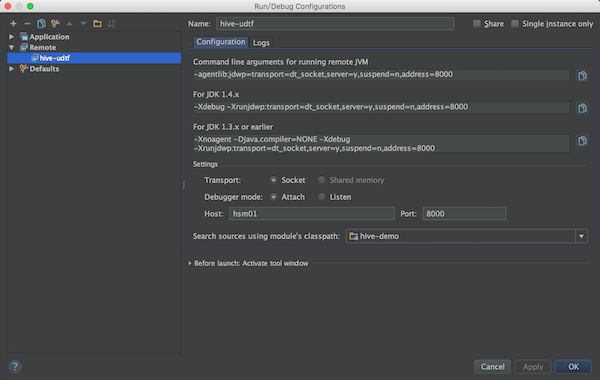
在idea中,选择Remote,修改host与port,确定。

9.6.7 参考
Hive通用型自定义聚合函数(UDAF)
HIVE自定义函数之UDF,UDAF和UDTF
Hive自定义UDF和聚合函数UDAF
Hive中添加自定义udf udaf udtf等函数的jar文件的三种方法
idea Intellij 远程调试java程序
9.7 参考
Hive2.0函数大全(中文版)
Hive 随谈(六)– Hive 的扩展特性
10 Locks
Hive 并发模型
Hive 使用陷阱(Lock table) 排查过程
Hive 表被锁定,无法删除表
11 Authorization
基于SQL标准的Hive授权
hive权限控制
hive权限管理
12 Hive HPL/SQL
在Hive中实现存储过程–HQL/SQL
Hive存储过程HQL/SQL(一)–hplsql命令行
13 Hive Configuration Properties
Hive Configuration Properties
14 参考
官方文档
Hive基本操作
Hive相关
Hive中数据的加载和导出