lua string库 字符串 用法详解
lua string库 字符串 用法详解
- 注:string库中所有的函数都不会直接修改原字符串,只返回新结果。
- 加[,]的参数指缺省,即可有可无,
string.len (s)
接收一个字符串,返回其长度。 空串 “” 的长度为 0 。 内嵌零也统计在内
string.len("abc") -- 返回:3
string.len("a\000bc\000") -- 返回:5以上只支持英文,utf8 中文字符长度 详情请见下一章”强大的匹配模式”
local _, count = string.gsub("中文utf8", "[^\128-\193]", "") -- count = 6或lua自带的utf8支持(5.3版本)
utf8.len (s [, i [, j]])
返回字符串 s 中 从位置 i 到 j 间 (包括两端) UTF-8 字符的个数。 默认的 i 为 1 ,默认的 j 为 -1 。 如果它找到任何不合法的字节序列, 返回假值加上第一个不合法字节的位置。
string.byte (s [, i [, j]])
返回字符 s[i], s[i+1], … ,s[j] 的内部数字编码。 i 的默认值是 1 ; j 的默认值是 i。 数字编码没有必要跨平台。
string.byte("abcABC", 1, 6) -- 返回:97 98 99 65 66 67string.char (···)
接收零或更多的整数。 返回和参数数量相同长度的字符串。 其中每个字符的内部编码值等于对应的参数值。
string.char(97, 98, 99) -- 返回:abcstring.lower (s)
大写转小写
string.lower("ABc") -- 返回:abcstring.upper (s)
小写转大写
string.upper("ABc") -- 返回:ABCstring.rep (s, n [, sep])
返回 n 个字符串 s 以字符串 sep 为分割符连在一起的字符串。 默认的 sep 值为空字符串(即没有分割符)。 如果 n 不是正数则返回空串。
string.rep("wzz", 3, ",") -- 返回:wzz,wzz,wzzstring.reverse (s)
返回字符串 s 的翻转串。
string.reverse("abc") -- 返回:"cba"string.sub (s, i [, j])
返回 s 的子串, 该子串从 i 开始到 j 为止; i 和 j 都可以为负数。负数,取从字符串后面算起, 如果开始位置在结束位置的后面,则返回空串
string.sub("abcABC", 1, -2) -- 返回:abcAB
string.sub("abcABC", -3) -- 返回:ABCstring.gsub (s, pattern, repl [, n])
将字符串 s 中,所有的(或是在 n 给出时的前 n 个) pattern 都替换成 repl ,并返回其副本。
repl 可以是字符串、表、或函数。
gsub 还会在第二个返回值返回一共发生了多少次匹配。
如果 repl 是一个字符串,那么把这个字符串作为替换品。 字符 % 是一个转义符: repl 中的所有形式为 %d 的串表示 第 d 个捕获到的子串,d 可以是 1 到 9 。 串 %0 表示整个匹配。 串 %% 表示单个 %。
如果 repl 是张表,每次匹配时都会用第一个捕获物作为键去查这张表。
如果 repl 是个函数,则在每次匹配发生时都会调用这个函数。 所有捕获到的子串依次作为参数传入。
任何情况下,模板中没有设定捕获都看成是捕获整个模板。
如果表的查询结果或函数的返回结果是一个字符串或是个数字, 都将其作为替换用串; 而在返回 false 或 nil 时不作替换 (即保留匹配前的原始串)。
string.gsub("hello1 world2", "(%a+)", "%1 %1")
-- 理解:(%a+)会捕获到hello1中的hello,赋值给%1,此时"%1 %1"即成了"hello hello",
-- 替换过去就成了"hello hello1",后面字符同样理解,共匹配2次
-- 所以结果返回:hello hello1 world world2 2
-- 下面请自行理解,有益健康, 更多祥情,请看 "强大的匹配模式"
1. string.gsub("hello world", "%w+", "%0 %0", 1)
2. string.gsub("hello world", "%a+", "%0 %0", 1)
3. string.gsub("hello world from Lua", "(%a+)%s*(%a+)", "%2 %1")
4. string.gsub("4+5 = $return 4+5$", "%$(.-)%$", function (s) return load(s)() end)
local t = {name="lua", version="5.3"}
5. string.gsub("$name-$version.tar.gz", "%$(%w+)", t)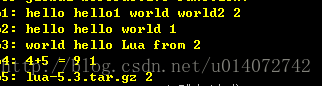
string.find (s, pattern [, init [, plain]])
查找第一个字符串 s 中匹配到的 pattern 。
如果找到一个匹配,find 会返回 s 中关于它起始及终点位置的索引; 否则,返回 nil。
第三个可选数字参数 init 指明从哪里开始搜索; 默认值为 1 ,同时可以是负值。
第四个可选参数 plain为 true 时, 关闭模式匹配机制。 此时函数仅做直接的 “查找子串”的操作, 而 pattern 中没有字符被看作魔法字符。 注意,如果给定了 plain ,就必须写上 init 。
如果在模式中定义了捕获,捕获到的若干值也会在两个索引之后返回。
string.find("8Abc%a23", "bc") -- 返回:3 4
string.find("8Abc%a23", "%a") -- 返回:2 2
string.find("8Abc%a23", "(%a)") -- 返回:2 2 A
string.find("8Abc%a23", "(%a)", 4) -- 返回:4 4 c
string.find("8Abc%a23", "%a", 1, true) -- 返回:5 6string.match (s, pattern [, init])
在字符串 s 中找到第一个能用 pattern 匹配到的部分。 如果能找到,match 返回其中的捕获物;
否则返回 nil 。
如果 pattern 中未指定捕获, 返回整个 pattern 捕获到的串。
第三个可选数字参数 init 指明从哪里开始搜索; 它默认为 1 且可以是负数。
string.match("abc123ABC456", "%a+%d+") -- 返回:abc123
string.match("abc123ABC456", "(%a+)%d+") -- 返回:abc
string.match("abc123ABC456", "(%a+)%d+", -5) -- 返回:BCstring.gmatch (s, pattern)
返回一个迭代器函数。
每次调用这个函数都会继续以 pattern 对 s 做匹配,并返回所有捕获到的值。
如果 pattern 中没有指定捕获,则每次捕获整个 pattern。
local s = "hello world from Lua"
for w in string.gmatch(s, "%a+") do
print(w)
end输出如下:

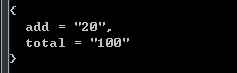
local t = {}
local s = "add=20, total=100"
for k, v in string.gmatch(s, "(%w+)=(%d+)") do
t[k] = v
endt表如下:
string.format (formatstring, ···)
返回不定数量参数的格式化版本, 格式化串为第一个参数(必须是一个字符串)。
格式化字符串遵循 C 函数 sprintf 的规则。
不同点在于选项 *, h, L, l, n, p 不支持, 另外还增加了一个选项 q
(注:可以用“..”连接字符串达到需要格式化后的字符串,“..”消耗较小)
- 常用转义符:
%s - 接受一个字符串并按照给定的参数格式化该字符串
%q - 接受一个字符串并将其转化为可安全被Lua编译器读入的格式
%d, %i - 接受一个数字并将其转化为有符号的整数格式(十进制数格式)
%u - 接受一个数字并将其转化为无符号整数格式
%f - 接受一个数字并将其转化为浮点数格式
%c - 接受一个数字,并将其转化为ASCII码表中对应的字符
%o - 接受一个数字并将其转化为八进制数格式
%x - 接受一个数字并将其转化为十六进制数格式,使用小写字母
%X - 接受一个数字并将其转化为十六进制数格式,使用大写字母
%e - 接受一个数字并将其转化为科学记数法格式,使用小写字母e
%E - 接受一个数字并将其转化为科学记数法格式,使用大写字母E
%g(%G) - 接受一个数字并将其转化为%e(%E,对应%G)及%f中较短的一种格式
为进一步细化格式, 可以在%号后添加参数. 参数将以如下的顺序读入:
1. 符号: +或- 默认情况下只有负数显示符号,可以加上+让正数显示+号
2. 占位符: 0, 即指定了字串宽度时,长度不足用0代补. 不填时的默认占位符是空格.
3. 对齐标识: 在指定了字串宽度时, 默认为右对齐, 增加-号可以改为左对齐.
4. 宽度数值
5. 小数位数/字串裁切: 在宽度数值后增加的小数部分n, 若后接f(浮点数转义符, 如%6.3f)则设定该浮点数的小数只保留n位, 若后接s(字符串转义符, 如%5.3s)则设定该字符串只显示前n位.
在这些参数的后面则是上述所列的转义码类型(c, d, i, f, …)
-- 看起来东西好像不少,其实结合例子来看,花上几分钟即可
print(string.format("1:%04d-%02d-%02d", 2017, 01, 12))
print(string.format("2:%s %q", "Hello", "Lua!"))
print(string.format("3:%%c:%c", 97))
print(string.format("4:%+04d", 11.2))
print(string.format("5:%f/%0.2f/%.2f/%6.2f/%06.2f", 12, 12, 12, 12, 12))
print(string.format("6:%e, %E", math.pi, math.pi))
print(string.format("7:%d, %i, %u", -10, -10, -10))
print(string.format("8:%o, %x, %X", -10, -10, -10))
print(string.format("9:%c", 83))
print(string.format("10:%+04d", 11.2))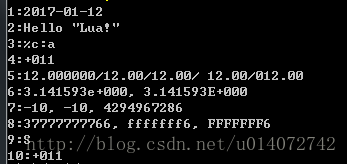
print("默认右对齐:\n" .. string.format("%6d\n%+06d\n%06d", 10, 20, 30))
print("改为左对齐:\n" .. string.format("%-6d\n%-+6d\n%-+06d", 10, 20, 30))
– 改为左对齐时,若用占位符0补位,格式化后显示的数字不付要求,故将0转为空格(本来+30,用0补位就成了+30000)
(以下几个没用过)
string.dump (function [, strip])
返回包含有以二进制方式表示的(一个 二进制代码块 )指定函数的字符串
string.packsize (fmt)
返回以指定格式用 string.pack 打包的字符串的长度。 格式化字符串中不可以有变长选项 ‘s’ 或 ‘z’
string.unpack (fmt, s [, pos])
返回以格式 fmt 打包在字符串 s (参见 string.pack) 中的值。 选项 pos(默认为 1 )标记了从 s 中哪里开始读起。 读完所有的值后,函数返回 s 中第一个未读字节的位置。