分布式算法 hash算法
分布式算法
一、Redis分布式算法原理
1.传统分布式算法。
a.jpg -- >hash(a.jpg)%3 --> 0/1/2 对应节点:0/1/2
假设有4个redis节点,20个数据(1-20):
| Redis0 |
4 |
8 |
12 |
16 |
20 |
| Redis1 |
1 |
5 |
9 |
13 |
17 |
| Redis2 |
2 |
6 |
10 |
14 |
18 |
| Redis3 |
3 |
7 |
11 |
15 |
19 |
注释:n%4 例如1%4 == 1放到redis1上
(2)5个redis节点
| Redis0 |
5 |
10 |
15 |
20 |
| Redis1 |
1 |
6 |
11 |
16 |
| Redis2 |
2 |
7 |
12 |
17 |
| Redis3 |
3 |
8 |
13 |
18 |
| Redis4 |
4 |
9 |
14 |
19 |
对比4个节点和5个节点:1、2、3、20数据存储的位置相同,就是说扩容一台redis之后,有4个数据能在原有位置找得到,其他存储位置变化了。
Redis0只有20命中
Redis1只有1命中
Redis2只有2命中
Redis3只有4命中
所有命中率为:4/20 = 20%
2.Consistenthashing一致性算法原理
一致性hash算法在1997年论文《Consistanthashing and random trees》中提出。
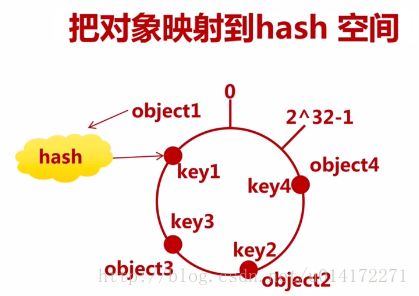
(1)环形hash空间。Value映射到32位的环形空间中。取值范围0到2^32-1。
四个object:object1~object4,hash函数计算之后key1~key4,key会落到环形空间(0~2^32-1)范围中。
(2)将cache映射到hash空间
基本思想:把对象和cache都映射到同一个hash数值空间中,并使用相同的hash算法。
Hash(cache A) =keyA Hash(cache B) = keyB
可以使用cache的机器地址,机器名作为hash输入,也可以引入更多因子例如端口号。
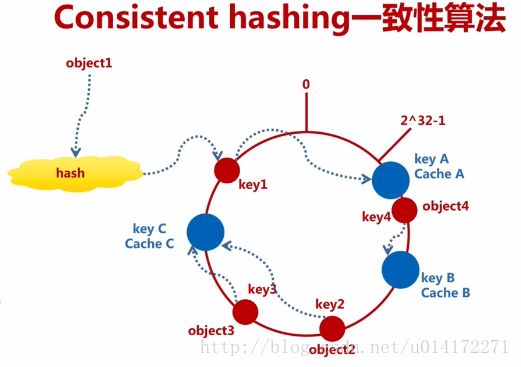
顺时针:key1存储到cacheA中,key2àcacheC,key3àCacheC,key4àcacheB中。
(3)移除cacheB,这样key4按照算法会映射到cacheC上。
移除会影响到CacheB与CacheA之间的数据节点。
(4)添加CacheD
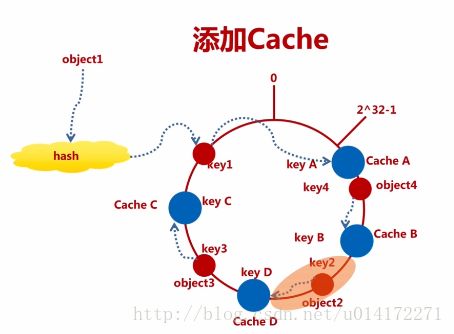
其会影响CacheD与CacheB之间的节点。
(5)理想与现实:
理想缓存节点分布十分均匀,但是现实是随机的。这样A就十分忙,B就最清闲。
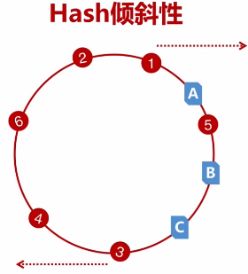
3.Hash倾斜性
由于hash倾斜性(顺时针存储到最近的cache节点),3,4,6,2,1都会存储到cacheA中,chacheC没有存储,5存储到ChacheB中。
引入虚拟节点解决这种倾斜性。
4.虚拟节点
数据节点Objece1,Objec2经过hash函数计算映射到虚拟节点v2,v5,再次hash计算之后映射到实际节点N1,N3。
蓝色A/B/C节点分配一个灰色A/B/C节点。数据节点3映射到虚拟chache节点A上,再hash映射到实际节点A上。
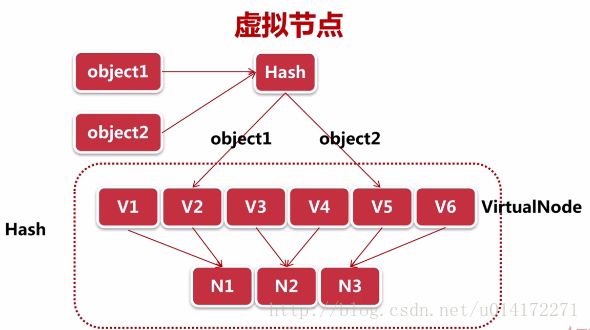
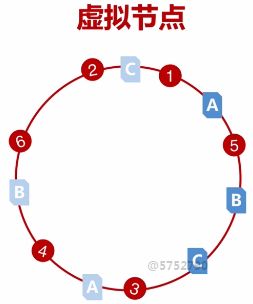
虚拟节点也存在hash倾斜性,合理分配真实节点和虚拟节点的比例。可以想一下,在两个真实节点之间分配有密密麻麻的虚拟节点,这样新增或者删除节点的影响会越来越小,也就是命中率会越来越高。
5.Consistent hashing命中率
(1-n/(n+m))*100% 服务器台数是n,新增服务器台数是M,当m特别多的时候,n/(n+m)越小,那么1-n/(n+m)会越来越小,那么命中率就会越来越高也就是说变动越来越少。一般设置100~500个虚拟节点来减少hash倾斜性。
二、Redis分布式环境配置
1.启动两个redis,端口一个6370,一个6380。同一使用redis配载文件启动。
三、Redis分布式服务端及客户端启动
./redis-server${redis[0-1]}的${redis.conf}
四、封装分布式Shard(分片) Redis API
1.ShardedJedis源码解析
2.封装RedisShardedPool
五、Redis分布式环境验证
六、集群和分布式概念讲解
1.集群 物理形态
2.分布式 工作形态