第十四记·HBase与MapReduce的集成整合与常用操作
XY个人记
在实际工作中我们对HBase的操作大多数都是与MapReduce共同进行业务操作,HBase 最大的特点之一就是可以紧密的与Hadoop的MapReduce框架集成。在HBase 中没有提供更好的二级索引的方式,在操作数据过程中,如果使用scan进行全表扫描,会极大的降低HBase的效率。
在HBase的官网上关联MapReduce(http://hbase.apache.org/book.html#mapreduce)中讨论在HBase中使用MapReduce的具体配置步骤。此外,还讨论了HBase和MapReduce作业之间的其他交互和问题。最后,讨论了层叠,MapReduce的另一种API。
HBase和MapReduce集成的集中模式:
1、从HBase读取数据 ---> 此过程将HBase的数据作为map的输入
2、将数据写入到HBase ---> 将HBase作为reduce的输出
3、从HBase中读,再写入到HBase中 ---> 一般多用数据迁移
第十六记·Java操作MapReduce对HBase表进行数据迁移
在HBase中提供了运行MapReduce的jar包:hbase-server-1.2.1.jar
那我们运行这个HBase提供的jar,会发现有如下错误
$ bin/yarn jar ../hbase-1.2.1/lib/hbase-server-1.2.1.jar Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/filter/Filter
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2570)
at java.lang.Class.getMethod0(Class.java:2813)
at java.lang.Class.getMethod(Class.java:1663)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.(ProgramDriver.java:59)
at org.apache.hadoop.util.ProgramDriver.addClass(ProgramDriver.java:103)
at org.apache.hadoop.hbase.mapreduce.Driver.main(Driver.java:42)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.filter.Filter 以上命令是在hadoop中运行的hbase的jar包,说明在hadoop下没有相关HBase的支持,缺少hbase相关的jar包
解决方案
1、将所有的hbase的jar包放到Hadoop运行环境变量中
配置环境变量HBASE_HOME、HADOOOP_HOME、HADOOP_CLASSPATH
【HADOOP_CLASSPATH默认加载的是share/hadoop下的所有jar包的依赖】
注:这种方式,可能会产生jar包冲突的情况
2、将Hadoop需要的hbase的jar包放到Hadoop运行环境变量中
运行bin/hbase mapredcp查看jar包【cp不是copy的意思,是classpath的意思,包含了hbase的jar包地址】
需要将这些添加到classpath中
首先声明环境变量
export HBASE_HOME=/opt/apps/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:`$HBASE_HOME/bin/hbase mapredcp`
a.【永久生效可以写在profile里】
b.【可以将查出来的jar全部贴过来,但是会很乱,可以通过命令加载进来`bin/hbase mapredcp`】
我选择更改profile文件,将下面代码添加到文件 /etc/profile 中
#HBase & MapReduce
export HBASE_HOME=/opt/modules/apache/hbase-1.2.1
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:`$HBASE_HOME/bin/hbase mapredcp`重启 source /etc/profile
运行成功后,一些相关命令的试用:

CellCounter: 统计有多少cell
completebulkload: 将hfile的文件数据加载
copytable: 从一个集群中拷贝到另一个集群中
export: 将表导出到HDFS
import: Import data written by Export.
importtsv: 导入一个tsv的文件数据
rowcounter: 统计rowkey
verifyrep:比较两个不同集群中的表的数据
等等
基本使用:rowcounter 统计hbaseAPI:tapi的rowkey
$ bin/yarn jar ../hbase-1.2.1/lib/hbase-server-1.2.1.jar rowcounter hbaseAPI:tapi可以查看下8088页面

发现会跑一个MapReduce 但是只有输入是没有输出的。但是在控制台是可以看到输出结果的,如图
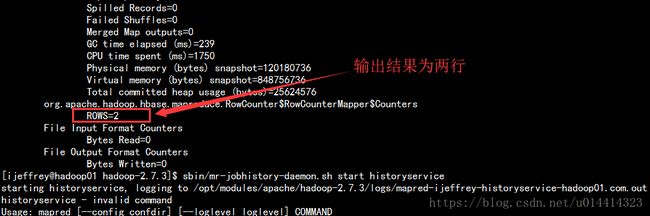
Java操作MapReduce对HBase进行数据迁移(第十六记·Java操作MapReduce对HBase表进行数据迁移)
hbase importTSV工具(将一个TSV格式文件导入到表中)
TSV文件格式(制表符分隔)
创建一个文件importTSV并上传到hdfs
20180723 jeffrey15 16 beijing bsc
20180724 jeffrey14 16 beijing bsc
20180725 jeffrey13 16 beijing bsc
20180726 jeffrey12 16 beijing bsc
20180727 jeffrey11 16 beijing bsc
20180728 jeffrey0 16 beijing bsc
20180729 jeffrey9 16 beijing bsc
20180720 jeffrey8 16 beijing bsc
20180719 jeffrey7 16 beijing bsc
20180718 jeffrey6 16 beijing bsc
20180717 jeffrey5 16 beijing bsc
20180716 jeffrey4 16 beijing bsc
20180715 jeffrey3 16 beijing bsc
20180714 jeffrey2 16 beijing bsc
20180713 jeffrey1 16 beijing bsc创建表:'stu_importTSV'
create 'stu_importTSV', 'f1','f2','f3'运行: importtsv
bin/yarn jar ../hbase-1.2.1/lib/hbase-server-1.2.1.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,f1:name,f2:age,f3:addr,f1:desaddr stu_importTSV /importTSV/stu_out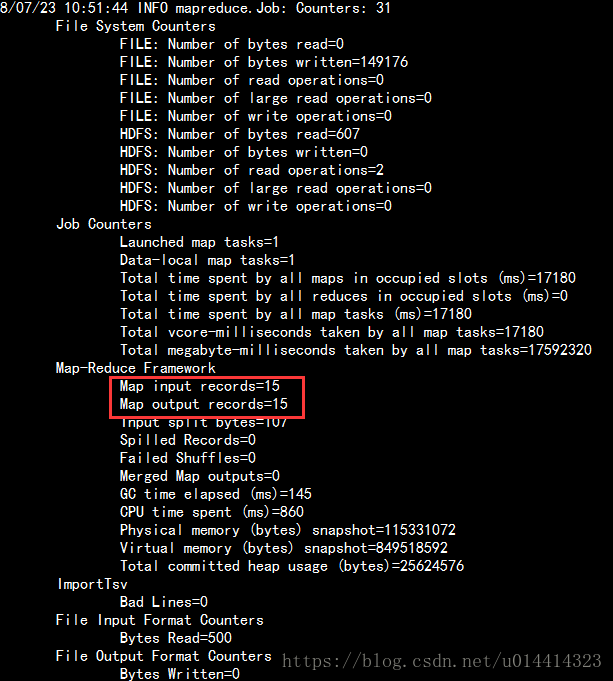
hbase(main):027:0> scan 'stu_importTSV' 查看导入成功
CSV文件格式(逗号分隔的),'-Dimporttsv.separator=|' 指定分隔符,默认是以tab分隔
创建文件stu_out2 修改为“,”分隔符,并上传到HDFS
$ bin/hdfs dfs -put /opt/datas/stu_out2 /importTSV 建表 'stu_import'
create 'stu_import', 'f1','f2','f3'运行jar:
bin/yarn jar ../hbase-1.2.1/lib/hbase-server-1.2.1.jar importtsv -Dimporttsv.separator=, -Dimporttsv.columns=HBASE_ROW_KEY,f1:name,f2:age,f3:addr,f1:desaddr stu_import /importTSV/stu_out2
bulkload方式导入数据
原理:利用HBase数据按照HFile格式存储在HDFS的原理,使用Mapreduce直接生成HFile格式文件后,RegionServers再将HFile文件移动到相应的Region目录下
运行一个MR转换为Hfile,将Hfile导入hbase表中
第一步:转换为Hfile -Dimporttsv.bulk.output=/testHfile
stu_out是以制表符分隔
bin/yarn jar ../hbase-1.2.1/lib/hbase-server-1.2.1.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,f1:name,f2:age,f3:addr,f1:desaddr -Dimporttsv.bulk.output=/testHfile stu_import /importTSV/stu_out
此操作会跳过写入memstore 的过程,直接转换成storeFile文件
 在stu_import中并不存在新的storeFile,下面我们做complete的操作
在stu_import中并不存在新的storeFile,下面我们做complete的操作

第二步:将Hfile导入到hbase表中 completebulkload
$ bin/yarn jar ../hbase-1.2.1/lib/hbase-server-1.2.1.jar completebulkload /testHfile stu_import
执行completebulkload 不会跑mr当再次刷新testHfile的时候发现storeFile消失【相当于hdfs上做了移动文件的操作】

而原来的文件会移动到HBase中,而数据在HBase中也是存在两份数据的,一份被打上了一个修改后的标记,这就需要我们进行storeFile的合并操作

第二步像hive的load加载,IO消耗比较低,减少了client和节点之间的RPC通信
将批量的文件先转换为Hfile,可以批量导入hbase中 【底层还是封装好的java程序】
执行合并 storeFile:
major_compact 'stu_import'storeFile合并成为一个

数据分割:
首先做一下切分前后的对比
切分前:stu_import在HDFS上的数据:

切分前:stu_import在HBase中的数据:

然后执行
split 'stu_import','0180720' #根据rowkey做切分点切分后:stu_import在HDFS上的数据:
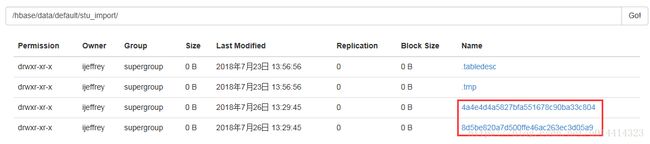
切分后:stu_import在HBase中的数据:

缺点:由于BulkLoad是绕过了Write to WAL,Write to MemStore及Flush to disk的过程,所以并不能通过WAL来进行一些复制数据的操作
优点:
1.导入过程不占用Region资源
2.能快速导入海量的数据
3.节省内存
JAVA通过bulkload方式导入数据
代码位置: 第十七记·Java操作HBase进行Bulkload方法导入数据