有了前两篇博文的基础,相信大家对Flume Agent的内部结构已经有了个初步的了解,现在我们来详细介绍最常用的文件通道——File Channel,本篇博客主要介绍Eevnt是如何完成写到File Channel这一操作的。
上一篇: http://manzhizhen.iteye.com/blog/2298159
Channel是联系Source和Sink的桥梁,内存Memory Channel性能虽高,但对于日志数据处理这块,实时并不是第一重要的,几乎所有以日志作为数据源的数据分析都只能说是近乎实时的。对于大多数数据分析来说,日志丢失是不可忍受的,所以,现在线上使用最多的Channel,就是File Channel。在大多数系统的设计中,为了保证高吞吐量,都会允许一小部分数据损失(比如每隔几秒再进行刷盘操作,将缓冲区的数据写如磁盘文件),但File Channel没有这样设计,它通过在一次事务中提交多个Event来提高吞吐量,做到了只要事务被提交,那么数据就不会有丢失。但需要注意,Flume Channel是没有数据副本的,意味着如果磁盘损坏,那么数据就无法恢复了。
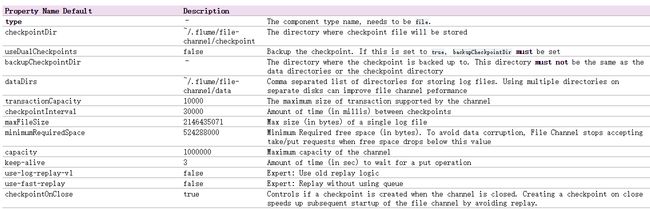
我们先来看看File Channel有哪些属性可以配置:
我们在来看看,在Flume Agent的配置文件中,File Channel是怎么配置的,见下图:
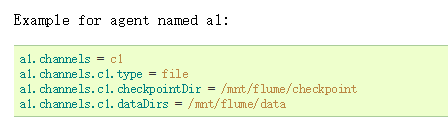
上图是官网中的截图,可以看到,图中设置了两个目录,第一个是检查点的目录(checkpointDir),第二个是数据的目录(dataDirs)。。那么,检查点是做什么用的?我们知道,在File Channel中,有一个内存队列来保存已被Source写入但还未被Sink消费的Event数据的指针,Event指针指向的就是Event在数据目录下数据文件中存放位置,所以,你很自然的就能想到检查点指的就是内存队列在某一稳定时刻的“快照”,而且每隔一段时间(checkpointInterval)File Channel会将内存队列持久化到磁盘文件,也就是我们配置的检查点目录下。为了保证内存队列“快照”的完整性,再将内存队列持久到磁盘文件时需要锁定内存队列,就是说此过程不Source不能写Channel,Sink也不能读Channel。你没猜错,上面的backupCheckpointDir就是检查点目录的备份目录,因为检查点文件是经常读写的,很容易在Flume Crash时导致文件损坏,所以如果要做到快速恢复,就可以给检查点配置一个复本。
从GitHub上下载Flume的源码,直接定位到flume-ng-channels模块,在该模块中,你肯定直接找到的是FileChannel.java类,在FileChannel中,我们看到了如下常见属性(省略了部分其他属性):
private Integer capacity = 0; private int keepAlive; protected Integer transactionCapacity = 0; private Long checkpointInterval = 0L; private long maxFileSize; private long minimumRequiredSpace; private File checkpointDir; private File backupCheckpointDir; private File[] dataDirs; private Log log; private final ThreadLocaltransactions = new ThreadLocal (); private boolean fsyncPerTransaction; private int fsyncInterval;
我接着看了下FileChannel的方法,发现大部分操作的实现是在上面的log属性中,于是,我点开了Log.java。用Eclipse的Ctrl+O的快捷键,我们直接预览Log类中的内部方法和属性,发现我们想要的都在里面,将Source将Event放入Channel肯定调用的是Log#put(long transactionID, Event event)方法,Sink从Channel取Event肯定调用的是Log#get(FlumeEventPointer pointer)方法等。如果直接看Log的这些方法,是不容易看明白它是怎么被调用,是被谁调用这些问题的,于是我们先直接从Source的角度来看Channel的Event写入过程。
每个Source都需要设置一个通道处理器(ChannelProcessor),写入Channel不是由Source来完成的,通道处理器用于暴露服务来将Event写入Channel,它是单线程的(Executors.newSingleThreadExecutor)。通道处理器写入Event的put操作有两种:processEvent和processEventBatch,分别用来写入单个Event和一次性批量写入多个Event,两个方法的内部处理过程都差不多。通道处理器将一个Event写入到Channel的整个过程包含5部分:1.将Event进行拦截器链进行过滤;2.通过通道选择器来选择该Event需要写入的哪些Channel;3.从Channel中获取一个事务;4.调用Channel的put方法将Event写入Channel;5.提交事务或回滚。其中如果某(批次)Event需要写入多个Channel,则步骤3-5是在for循环中执行的,可见,如果要将Event写入n个通道,则整个过程将产生n次事务操作。所以,纵观Source、Channel和Sink的实现,Channel的实现无疑是最重量级的。
咱们先看第1步,拦截器构造工厂(InterceptorBuilderFactory)将用户配置的拦截器组装成拦截器链,通道处理器将需要写入Channel的Event先放入拦截器链进行过滤,如果最后返回的Event不为空,说明没被过滤掉,拦截器不一定只是为了过滤Event,它还可以给Event的头部添加一些必要信息,比如数据的日志文件来源等。
第2步是确定该(批次)Event需要写入哪些Channel,这些Channel包括要求(required)的和可选(optional)的,要求的Channel是需要保证写入成功的(如果失败则会重试),可选的Channel只会尝试写入一次,不管失败与否。每个通道处理器实例都配置有一个通道选择器(ChannelSelector),通道处理器的构造器的入参就是通道选择器,Channel的选择就是由通道选择器来做的。通道选择器会对Event的头部信息来进行筛选,决定该Event需要写入到哪些Channel,具体配置可以参考官方文档,该部分不看代码也能明白其实现,所以通道选择器不做具体介绍了。
知道要写入哪些Channel后,通道抽利器将for循环遍历Channel列表将该(批次)Event依次放入Channel中,将该(批次)Event写入该Channel前,会先通过改Channel创建事务(步骤3),全部写入成功(步骤4)后将提交事务(步骤5,commit),否则会回滚(步骤5,rollback)并抛出异常。这将会有个潜在的问题,如果一个Event需要写入多个Channel,当写入其中某个Channel导致事务回滚时,由于在他之前的Channel已经写入成功了,所以当该(批次)Event再次被交给通道处理器时,上次那些已经成功写入Event的Channel将会被重复写入,这似乎是Flume设计的一个缺陷,所以只能下游的系统自己来处理重复消息了。写完要求(required)的Channel,将会继续将Event写入可选(optional)的Channel(如果配置了的话),写入可选的Event也是会开启事务的,但如果出错只会回滚但不会对外抛出异常。
咱们接着看第3步:从Channel中获取一个事务。在Flume中,Transaction接口定义了事务的四种状态(Started,Committed,RolledBack,Closed)和对应四种操作(begin,commit,rollback,close),将事务对象借助ThreadLocal来进行管理,便于跟踪和使用,但事务对象在Flume中不会重复使用,也就是说事务在提交或回滚后将会关闭,然后当重新从FileChannel中获取一个新的事务时,发现原有的事务时关闭状态时,将会新建一个。抽象事务原语类BasicTransactionSemantics实现了Transaction接口,增加了几个成员属性,最重要的就是初始化事务ID(initialThreadId)了,它在事务的构造方法中会记录创建它的线程ID,并在事务提供的所有操作之前都会通过initialThreadId来检查当前的线程是否是创建它的线程,如果不是则抛异常(
Preconditions.checkState(Thread.currentThread().getId() == initialThreadId, "XXX called from different thread than getTransaction()!");),。BasicTransactionSemantics在Transaction原有的基础上增加了put和take方法,并为这6种方法都添加了对应的do操作方法,而原方法的操作只是在为了在调用其do方法前做状态检查(如put将调用doPut,begin将调用doBegin等),于是,你一定想到了,从Channel中获取一个事务其实就是调用了它ThreadLocal属性(currentTransaction)的get方法来获取当前线程绑定的事务对象,没错,就是这样。由于每种通道的实现都不同,所以都需要自己去实现事务的具体细节,而文件通道File Channel的事务是由直接写在FileChannel类的静态内部类FileBackedTransaction来实现的。Channel可以设置最大的事务数量(transactionCapacity,默认10000),该数量不能超过通道的容量(当然也没必要超过,capacity,默认1000000),比如我们设置文件通道的最大事务数量是10000,表明Source往Channel写时最多能开启10000个事务,Sink从Channel中取Event时最多也能开启10000个事务。。
继续看第4步,即Source将Event写Channel。通道处理器将调用各自Channel中的put方法将一个Event写入Channel实例,而不用关心其具体细节。抽象通道原语类BasicChannelSemantics对事务进行了ThreadLocal包装(步骤3中已经说了,即 private ThreadLocal
@Override
public void put(Event event) throws ChannelException {
BasicTransactionSemantics transaction = currentTransaction.get();
Preconditions.checkState(transaction != null,
"No transaction exists for this thread");
transaction.put(event);
}这下又直接将实现细节交给了不同Channel事务类的实现。BasicTransactionSemantics是实现了Transaction接口的抽象类,我们来看下它的put实现:
protected void put(Event event) {
Preconditions.checkState(Thread.currentThread().getId() == initialThreadId,
"put() called from different thread than getTransaction()!");
Preconditions.checkState(state.equals(State.OPEN),
"put() called when transaction is %s!", state);
Preconditions.checkArgument(event != null,
"put() called with null event!");
try {
doPut(event);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new ChannelException(e.toString(), e);
}
} 可见,它直接调用的是doPut方法(步骤3提到过)。FileBackedTransaction为FileChannel的事务实现类,它实现了BasicTransactionSemantics,FileBackedTransaction中有两个FlumeEventPointer的双端队列:takeList和putList,用于存储一个事务中(Source)需要写入Channel或(Sink)需要从Channel读取的Event的指针,因为在Flume中,事务只包含Source写Channel或者Sink读Channel这两个操作中的一个,所以在实际情况中,takeList和putList有一个会为空。FileBackedTransaction的doPut实现中,先会去检查putList队列是否已经满了(putList.remainingCapacity() == 0),如果满了则直接抛异常,FileBackedTransaction中还有个queueRemaining的信号量类型(Semaphore),它由其构造函数传入,queueRemaining的许可数正好是File Channel的容量,所以它还会通过它检查File Channel是否还有剩余空间(queueRemaining.tryAcquire(keepAlive,TimeUnit.SECONDS)),如果你看过Flume官方文档中File Channel的属性配置,一定对keep-alive这个属性有过疑问,文档中对它的描述是:Amount of time (in sec) to wait for a put operation,即等候put操作的时间数量,默认值是3,所以,这时你就明白了,它就是刚才queueRemaining获取一个可用许可的等待的秒数(keepAlive),就是说,如果文件通道满了,它最多等它3秒,所以,当对于该File Channel来说,如果它的Sink消费消息的能力低于Source往Channel写入消息的能力,这个值可以稍微设置大点。当成功拿到写入许可后,它会调用Log对象来获取共享锁(log.lockShared()),它其实是检查点的读锁(checkpointReadLock.lock(),那什么是检查点呢?本文稍后会说)。当读锁获取到以后,它会调用Log的put方法(FlumeEventPointer ptr = log.put(transactionID, event);)来开始真正进入“写磁盘文件”的流程。我们现在来仔细瞅瞅log.put的过程,Log不是简单的将Event写入文件,它先对它进行了Put对象的包装,Put类除了包含一个Event的成员属性,还包含了事务ID(transactionID)和写顺序ID(logWriteOrderID),事务ID即通道获取的事务对象中的事务ID,而这个写顺序ID是由WriteOrderOracle.next()直接生成的,在单个Flume Agent实例中是唯一的。所以,Log是将Put对象写入到文件中。由于我们可以在File Channel中配置多个数据存储目录(dataDirs),之所以Flume让你配置多个数据目录,是为了提升并发写的能力,这也从侧面说明,“写”是个多线程操作。为了达到负载均衡,Log使用事务ID对dataDirs数量取模来决定写入哪个数据存储目录((int)Math.abs(transactionID % (long)logFiles.length());),每个数据目录其实是一个LogFileV3类的实例,当知道写入哪个数据目录后,将先检查该数据目录下面的文件是否还有足够的可供空间(代码中写死的15L*1000L,不可配,为什么会有这个空间,还有待稍后分析),如果有足够的可用空间,则直接调用LogFileV3的put方法,将Put对象写入磁盘文件中,写入时,还会对Put对象的ByteBuffer进行进一步包装,比如在前面加上ByteBuffer的长度(limit)等,写之前会记录当前数据文件指针的位置,即offset(getFileChannel().position()),写完(int wrote = getFileChannel().write(toWrite);)后,将该数据文件ID和offset一并返回(return Pair.of(getLogFileID(), offset);),便于后面追查记录位置。
这里第一次提到了数据文件ID一词,为了保证每个数据目录(dataDir)下数据文件的合理大小,当数据超过一个数据文件的最大容量时,Flume会自动在当前目录新建一个数据文件,为了区分同一个数据目录下的数据文件,Flume采用文件名加数字后缀的形式(比如log-1、log-2),其中的数字后缀就是数据文件ID,它由Log实例中的nextFileID属性来维护,它是原子整形,由于在Flume Agent实例中,一个File Channel会对应一个Log实例,所以数据文件ID是唯一的,即使你配置了多个数据目录。每个数据文件都有一个对应的元数据文件(MetaDataFile),它和数据文件在同一目录,命名则是在数据文件后面加上.meta,比如log-1对应的元数据文件是log-1.meta,其实就是将Checkpoint对象通过谷歌的Protos协议序列化到元数据文件中,Checkpoint存储了对应数据文件的诸多重要信息,比如版本、写顺序ID(logWriteOrderID)、队列大小(queueSize)和队列头索引(queueHead)等。元数据文件主要用于快速将数据文件的信息载入到内存中,即重播(replay)时使用,关于重播,请参考我的博文Flume快速入门(五)。
这种数据文件ID+位置的组合就是Event指针对象FlumeEventPointer,它有两个int属性,fileId(文件ID)和offset(位置偏移量)。当拿到FlumeEventPointer对象,说明Event已经写入磁盘缓冲区成功(还未强制刷盘)。接下来FileBackedTransaction.doPut需要将得到的FlumeEventPointer和事务ID临时存放到内存队列queue的inflightPuts属性中(queue.addWithoutCommit(ptr,transactionID);),之所以说临时存放,是因为事务还未提交,还不能直接将FlumeEventPointer放入queue的已提交数据容器backingStore中,不然就提前暴露给Sink了,这也方便区分哪些Event还未被真正提交,方便后面回滚。queue就是FlumeEventQueue的一个实例,对于File Channel来说,采用的是文件作为存储介质,突然的服务宕机重启不会带来数据丢失(没有刷盘的数据或磁盘损坏除外),但为了高效索引文件数据,我们得在内存保存写入到文件的Event的位置信息,前面说了,Event的位置信息可由FlumeEventPointer对象来存储,FlumeEventPointer是由FlumeEventQueue来管理的,FlumeEventQueue有两个InflightEventWrapper类型的属性:inflightPuts和inflightTakes,InflightEventWrapper是FlumeEventQueue的内部类,专门用来存储未提交Event(位置指针),这种未提交的Event数据称为飞行中的Event(in flight events)。因为这是往Channel的写操作,所以调用InflightEventWrapper的addEvent(Long transactionID,Long pointer)方法将未提交的数据保存在inflightPuts中(inflightEvents.put(transactionID, pointer);),注意,这里有个小细节,InflightEventWrapper的addEvent的第二个入参是Long类型的,而我们要保存的是FlumeEventPointer类型,所以,在FlumeEventPointer.toLong方法中,会将FlumeEventPointer的两个int属性合成一个long属性,以方便存储,方法如下:
public long toLong() {
long result = fileID;
result = (long)fileID << 32;
result += (long)offset;
return result;
}
这一步做完之后,写入Channel的操作就完成了,立马释放共享锁(log.unlockShared();)和信号量(queueRemaining.release();)。
我们看最后的第5步,事务提交或回滚,我们这里重点关注提交过程。大家知道,当一个事务提交后,Channel需要告知Source Event已经成功保存了,而Source需要通知写入源已经写入成功,即成功ACK.那么,事务提交的过程是不是很简单呢?其实不然,我们接着看。File Channel的事务提交过程由FileBackedTransaction.doCommit方法来完成,对于Source往Channel的写操作(putList的size大于0)来说,还是会先通过Log对象拿到检查点的共享锁(log.lockShared();),拿到共享锁后,将调用Log对象的commit方法,commit方法先将事务ID、新生成的写顺序ID和操作类型(这里是put)来构建一个Commit对象,该对象和上面步骤4提到过的Put对象类似,然后再将该Commit写入数据文件,至于是写入哪个数据目录下的文件,和当时写Put对象一样,有同样的事务ID来决定,这意味着,在一次事务操作中,一个Commit对象和对应的Put(如果是批次提交,则有多少个Event就有多少个Put)会被写入同一个数据目录下。当然,写入Commit对象到文件后并不需要保留其位置指针。做完这一步,将putList中的Event文件位置指针FlumeEventPointer对象依次移除并放入内存队列queue(FlumeEventQueue)的队尾部(while(!putList.isEmpty()){if(!queue.addTail(putList.removeFirst())){…),这样Sink才有机会从内存队列queue中索引要取的Event在数据目录中的位置,同时也保证了这批次的Event谁第一个写入的Event也将第一个被放入内存队列也将会第一个被Sink消费。当FlumeEventPointer被全部写入内存队列queue后,则需要将保存在queue.inflightPuts中的该事务ID移除(queue.completeTransaction(transactionID);),因为该事务不再处于“飞行中(in flight events)”了,于是,一个事务真正的被commit了。
有人会说,第5步也不复杂啊!如果我们回头想想,Event虽被写入了本地磁盘文件,Event的文件指针也被写入了内存队列,似乎是万无一失了,但这是一旦Flume被重启,会怎么样?对,内存队列FlumeEventQueue直接消失了!内存队列数据没了,文件指针也没了,你再也无法定位那些已经准备好的可以被Sink读取的Event在文件中的位置了!所以你立马想到了,我应该经常对内存队列做“备份”,没错,Flume也是会对内存队列做文件备份的,于是,检查点(checkpoint)的概念出现了!还记得Flume官方文档中File Channel中checkpointDir属性的设置了吗?它就是设置检查点文件存储的目录的。那什么时候会将内存队列备份到检查点文件呢?对于写Channel来说,就是步骤5中queue.addTail操作,这也是为什么步骤5我们没仔细分析该步骤的原因。其实,写检查点文件也是比较复杂的一个过程,因为它要保证写时效率,也要保证恢复时能将数据重新加载到内存队列中。
我们接下来继续分析第5步queue(FlumeEventQueue)中的addTail方法,在介绍该方法之前,我们来看看内存队列FlumeEventQueue中最重要的成员属性:backingStore,它是EventQueueBackingStore接口的实现,有兴趣的读者可以看看EventQueueBackingStoreFile类的实现。那么backingStore是用来做什么的呢?backingStore主要有两个作用,第一是保存已经提交了的Event位置指针,放在一个Map结构的overwriteMap属性中,另一个作用就是将已提交但还未来得及被消费的Event位置指针数据写入检查点文件,这是通过将检查点文件映射到一块虚拟内存中来完成的,这个虚拟内存结构就是backingStore的mappedBuffer属性,它是MappedByteBuffer类型。overwriteMap和mappedBuffer中的数据是不相交的,因为有个后台调度任务(默认30秒执行一次,最短能每1秒钟执行一次,该调度任务稍后会介绍)会定时将overwriteMap的数据一个一个写入mappedbuffer,每写一个Event指针就把该Event指针从overwriteMap中移除,所以overwriteMap + mappedbuffer几乎就可以说是内存队列中未被消费的全量Event指针数据。这下你就明白了,如果Sink想从File Channel取出一个Event来消费,FlumeEventQueue会先尝试从overwriteMap中取,如果找不到,就从mappedBuffer中取。当然,由于mappedBuffer是ByteBuffer,所以为了操作方便,在mappedBuffer之上建立了一个LongBuffer的视图,即backingStore的elementsBuffer属性(elementsBuffer = mappedBuffer.asLongBuffer();)。好了,回过头来,我们继续说addTail方法的实现,它主要分为如下几个步骤:
1.先检查backingStore的容量(backingStore的容量和File Channel的容量一致,这也保证了及时整个File Channel中的数据没被消费,内存队列也能完整备份到检查点文件中),如果满了则告知失败,返回false,这时候会打印错误日志,但不会抛异常,也不会影响整个事务的提交(为什么只是打印错误日志呢?因为Flume的作者认为这中情况不太可能发生,因为事务队列中保留了部分空余空间)。
2.还是老规矩,将Event指针对象FlumeEventPointer整合成一个long类型。
3.backingStore中有个属性logFileIDReferenceCounts,它是个Map结构,key为数据文件logFile的文件ID,value为该文件中还未被消费的Event指针计数器。于是需要将该Event指针所写的数据文件ID对应的计数器+1?大家有没有想过这是为什么?对,如果当某个logFile文件的计数器为0,表明该文件的Event全被Sink消费了,也就是说Flume可以在需要时删除该logFile及其相关的检查点或备份文件了。
4.backingStore有个int型的queueSize属性,用啦记录放入overwriteMap的Event指针数,于是,这一步是将queueSize和Event指针放入overwriteMap中。
5.queueSize+1.
6.backingStore还有个Set
经过这6步,内存队列FlumeEventQueue的addTail操作就完成了。
为了便于理解,这里用几张图来说明整个流程。
先看整体流程:

我们再来看看将Event写入数据文件的过程:
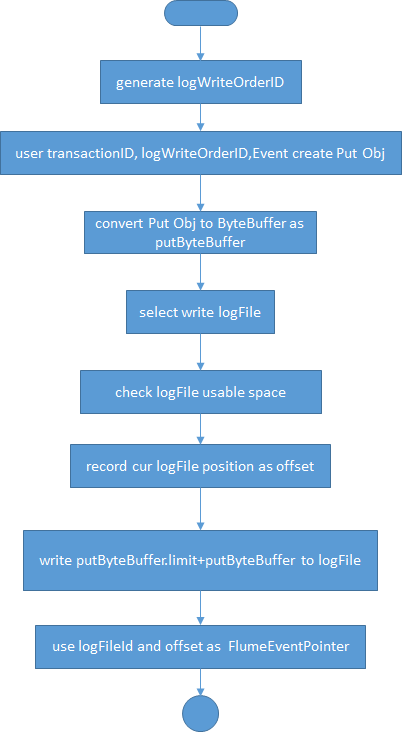
将Event写入数据文件后、Event指针放入FlumeEventQueue的已提交数据backingStore之前,会将事务ID和Event指针临时放入inflightPuts中,这一步很简单,感兴趣的读者可以看InflightEventWrapper#addEvent.