这么设计实时数据平台,OLAP再也不是个事儿
春运的时候,12306会偶尔崩溃。其实,12306真的很厉害,对于它来说,几乎每天都是双11,但是它很少出现宕机的情况,架构的设计是一方面,我今天要讲的实时计算也是一方面。
前些时间我讲过BI,那么对于BI来说,稳定性最重要的一点就是实时计算。
一、相关概念背景
1、从现代数仓架构角度看实时数据平台
现代数仓由传统数仓发展而来,对比传统数仓,现代数仓既有与其相同之处,也有诸多发展点。首先我们看一下传统数仓(图1)和现代数仓(图2)的模块架构:
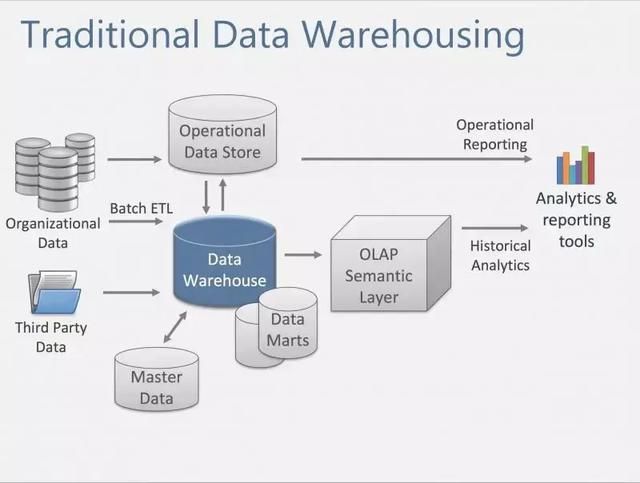
传统数仓
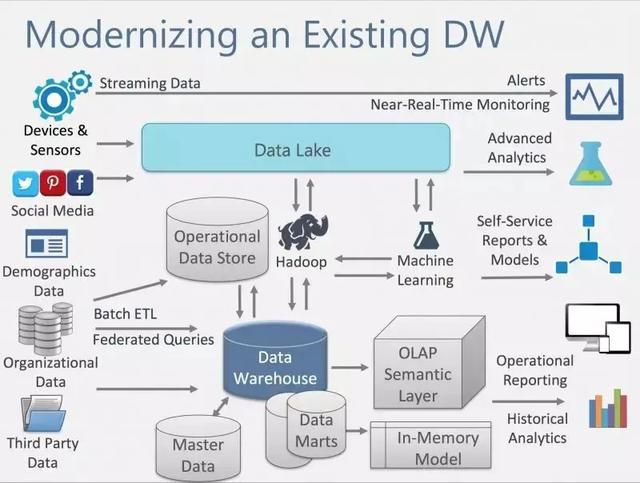
现代数仓
传统数仓大家都很熟悉,这里不做过多介绍,一般来说,传统数仓只能支持T+1天时效延迟的数据处理,数据处理过程以ETL为主,最终产出以报表为主。
现代数仓建立在传统数仓之上,同时增加了更多样化数据源的导入存储,更多样化数据处理方式和时效(支持T+0天时效),更多样化数据使用方式和更多样化数据终端服务。
现代数仓是个很大的话题,在此我们以概念模块的方式来展现其新的特性能力。
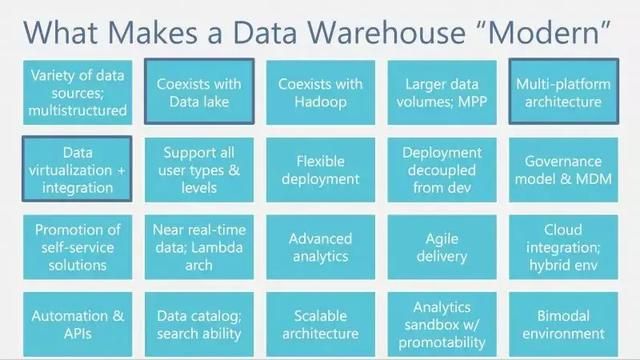
现代数仓之所以“现代”,是因为它有多平台架构、数据虚拟化、数据的近实时分析、敏捷交付方式等等一系列特性。
我们也在此总结提取了现代数仓的几个重要能力,分别是:
- 数据实时化(实时同步和流式处理能力)
- 数据虚拟化(虚拟混算和统一服务能力)
- 数据平民化(可视化和自助配置能力)
- 数据协作化(多租户和分工协作能力)
(1)数据实时化(实时同步和流式处理能力)
数据实时化,是指数据从产生(更新至业务数据库或日志)到最终消费(数据报表、仪表板、分析、挖掘、数据应用等),支持毫秒级/秒级/分钟级延迟(严格来说,秒级/分钟级属于准实时,这里统一称为实时)。
这里涉及到如何将数据实时的从数据源中抽取出来;如何实时流转;为了提高时效性,降低端到端延迟,还需要有能力支持在流转过程中进行计算处理;如何实时落库;如何实时提供后续消费使用。实时同步是指多源到多目标的端到端同步,流式处理指在流上进行逻辑转换处理。
但是我们要知道,不是所有数据处理计算都可以在流上进行,而我们的目的,是尽可能的降低端到端数据延迟,这里就需要和其他数据流转处理方式配合进行,后面我们会进一步讨论。
(2)数据虚拟化(虚拟混算和统一服务能力)
数据虚拟化,是指对于用户或用户程序而言,面对的是统一的交互方式和查询语言,而无需关注数据实际所在的物理库和方言及交互方式(异构系统/异构查询语言)的一种技术。用户的使用体验是面对一个单一数据库进行操作,但其实这是一个虚拟化的数据库,数据本身并不存放于虚拟数据库中。
虚拟混算指的是虚拟化技术可以支持异构系统数据透明混算的能力,统一服务指对于用户提供统一的服务接口和方式。
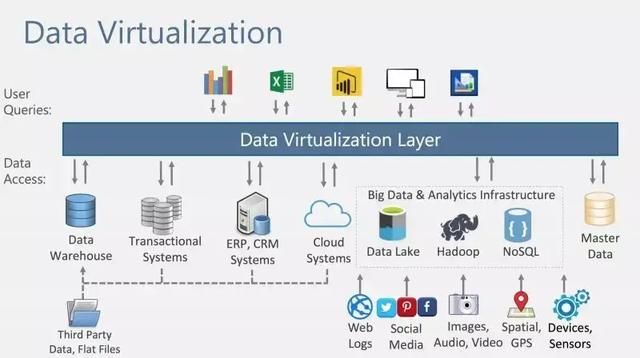
数据虚拟化
(3)数据平民化(可视化和自助配置能力)
普通用户(无专业大数据技术背景的数据从业人员),可以通过可视化的用户界面,自助的通过配置和SQL方式使用数据完成自己的工作和需求,并无需关注底层技术层面问题(通过计算资源云化,数据虚拟化等技术)。以上是我们对数据平民化的解读。
其中数据虚拟化和数据联邦本质上是类似技术方案,并且提到了自助BI这个概念,我前几天讲的FineBI就是国内自助BI的领军人物,和国外的Tableau齐名。
(4)数据协作化(多租户和分工协作能力)
技术人员应该多了解业务,还是业务人员应该多了解技术?这一直是企业内争论不休的问题。而我们相信现代BI是一个可以深度协作的过程,技术人员和业务人员可以在同一个平台上,发挥各自所长,分工协作完成日常BI活动。这就对平台的多租户能力和分工协作能力提出了较高要求,一个好的现代数据平台是可以支持更好的数据协作化能力的。
我们希望可以设计出一个现代实时数据平台,满足以上提到的实时化、虚拟化、平民化、协作化等能力,成为现代数仓的一个非常重要且必不可少的组成部分。
2、从典型数据处理角度看实时数据处理
典型的数据处理,可分为OLTP、OLAP、Streaming、Adhoc、Machine Learning等。这里给出OLTP和OLAP的定义和对比:
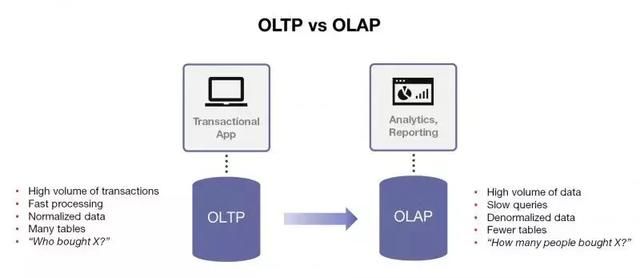
从某种角度来说,OLTP活动主要发生在业务交易库端,OLAP活动主要发生在数据分析库端。那么,数据是如何从OLTP库流转到OLAP库呢?如果这个数据流转时效性要求很高,传统的T+1批量ETL方式就无法满足了。
我们将OLTP到OLAP的流转过程叫Data Pipeline(数据处理管道),它是指数据的生产端到消费端之间的所有流转和处理环节,包括了数据抽取、数据同步、流上处理、数据存储、数据查询等。
这里可能会发生很复杂的数据处理转换(如重复语义多源异构数据源到统一Star Schema的转换,明细表到汇总表的转换,多实体表联合成宽表等)。如何支持实时性很高的Pipeline处理能力,就成了一个有挑战性的话题,我们将这个话题描述为“在线管道处理”(OLPP, Online Pipeline Processing)问题。
因此,本文所讨论的实时数据平台,希望可以从数据处理角度解决OLPP问题,成为OLTP到OLAP实时流转缺失的课题的解决方案。下面,我们会探讨从架构层面,如何设计这样一个实时数据平台。
二、架构设计方案
1、定位和目标
实时数据平台(Real-time Data Platform,以下简称RTDP),旨在提供数据端到端实时处理能力(毫秒级/秒级/分钟级延迟),可以对接多数据源进行实时数据抽取,可以为多数据应用场景提供实时数据消费。作为现代数仓的一部分,RTDP可以支持实时化、虚拟化、平民化、协作化等能力,让实时数据应用开发门槛更低、迭代更快、质量更好、运行更稳、运维更简、能力更强。
2、整体设计架构
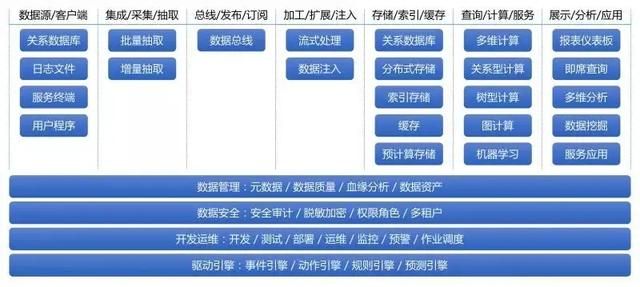
概念模块架构,是实时数据处理Pipeline的概念层的分层架构和能力梳理,本身是具备通用性和可参考性的,更像是需求模块。图6给出了RTDP的整体概念模块架构,具体每个模块含义都可自解释,这里不再详述。
下面我们会根据上图做进一步设计讨论,给出从技术层面的高阶设计思路。
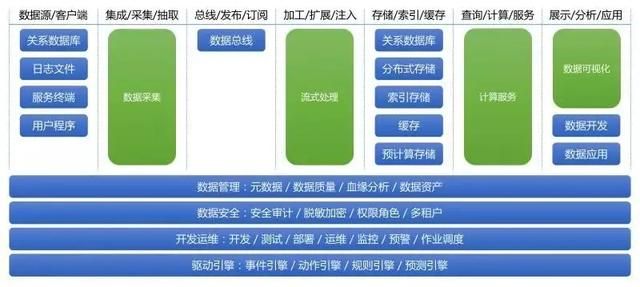
由图7可以看出,我们针对概念模块架构的四个层面进行了统一化抽象:
- 统一数据采集平台
- 统一流式处理平台
- 统一计算服务平台
- 统一数据可视化平台
同时,也对存储层保持了开放的原则,意味着用户可以选择不同的存储层以满足具体项目的需要,而又不破坏整体架构设计,用户甚至可以在Pipeline中同时选择多个异构存储提供支持。下面分别对四个抽象层进行解读。
(1)统一数据采集平台
统一数据采集平台,既可以支持不同数据源的全量抽取,也可以支持增强抽取。其中对于业务数据库的增量抽取会选择读取数据库日志,以减少对业务库的读取压力。平台还可以对抽取的数据进行统一处理,然后以统一格式发布到数据总线上。这里我们选择一种自定义的标准化统一消息格式UMS(Unified Message Schema)做为统一数据采集平台和统一流式处理平台之间的数据层面协议。
UMS自带Namespace信息和Schema信息,这是一种自定位自解释消息协议格式,这样做的好处是:
- 整个架构无需依赖外部元数据管理平台;
- 消息和物理媒介解耦(这里物理媒介指如Kafka的Topic, Spark Streaming的Stream等),因此可以通过物理媒介支持多消息流并行,和消息流的自由漂移。
平台也支持多租户体系,和配置化简单处理清洗能力。
(2)统一流式处理平台
统一流式处理平台,会消费来自数据总线上的消息,可以支持UMS协议消息,也可以支持普通JSON格式消息。同时,平台还支持以下能力:
- 支持可视化/配置化/SQL化方式降低流式逻辑开发/部署/管理门槛
- 支持配置化方式幂等落入多个异构目标库以确保数据的最终一致性
- 支持多租户体系,做到项目级的计算资源/表资源/用户资源等隔离
(3)统一计算服务平台
统一计算服务平台,是一种数据虚拟化/数据联邦的实现。平台对内支持多异构数据源的下推计算和拉取混算,也支持对外的统一服务接口(JDBC/REST)和统一查询语言(SQL)。由于平台可以统一收口服务,因此可以基于平台打造统一元数据管理/数据质量管理/数据安全审计/数据安全策略等模块。平台也支持多租户体系。
(4)统一数据可视化平台
统一数据可视化平台,加上多租户和完善的用户体系/权限体系,可以支持跨部门数据从业人员的分工协作能力,让用户在可视化环境下,通过紧密合作的方式,更能发挥各自所长来完成数据平台最后十公里的应用。
以上是基于整体模块架构之上,进行了统一抽象设计,并开放存储选项以提高灵活性和需求适配性。这样的RTDP平台设计,体现了现代数仓的实时化/虚拟化/平民化/协作化等能力,并且覆盖了端到端的OLPP数据流转链路。