文本分类系列(1):textcnn及其pytorch实现
文本分类系列(1):TextCNN及其pytorch实现
文本分类系列(2):TextRNN及其pytorch实现
textcnn
- 原理:核心点在于使用卷积来捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
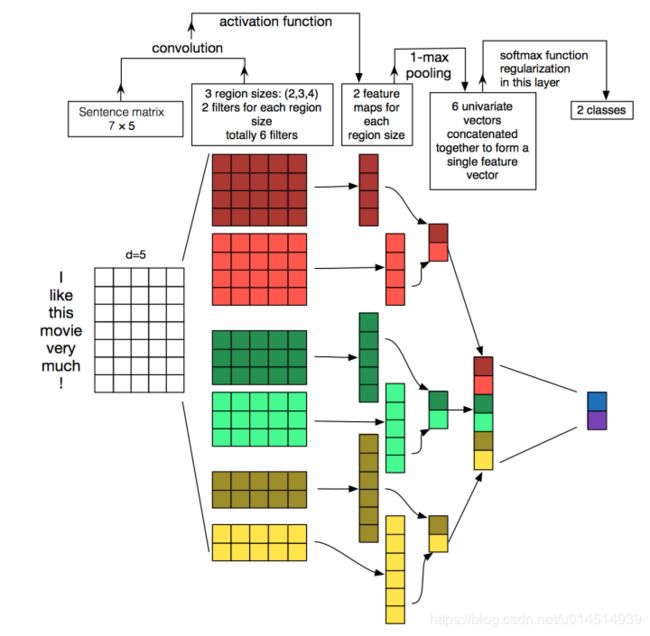
- textcnn详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过不同 filter_size的一维卷积层(这里是2,3,4),每个filter_size 有filter_num(这里是2)个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
- 特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量(fine_tune)。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
- 一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
- Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
pytorch代码实现,具体见https://github.com/WoBruceWu/text-classification/tree/master/text-cnn
textcnn网络(含具体注释)
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self, args):
super(TextCNN, self).__init__()
self.args = args
label_num = args.label_num # 标签的个数
filter_num = args.filter_num # 卷积核的个数
filter_sizes = [int(fsz) for fsz in args.filter_sizes.split(',')]
vocab_size = args.vocab_size
embedding_dim = args.embedding_dim
self.embedding = nn.Embedding(vocab_size, embedding_dim)
if args.static: # 如果使用预训练词向量,则提前加载,当不需要微调时设置freeze为True
self.embedding = self.embedding.from_pretrained(args.vectors, freeze=not args.fine_tune)
self.convs = nn.ModuleList(
[nn.Conv2d(1, filter_num, (fsz, embedding_dim)) for fsz in filter_sizes])
self.dropout = nn.Dropout(args.dropout)
self.linear = nn.Linear(len(filter_sizes)*filter_num, label_num)
def forward(self, x):
# 输入x的维度为(batch_size, max_len), max_len可以通过torchtext设置或自动获取为训练样本的最大=长度
x = self.embedding(x) # 经过embedding,x的维度为(batch_size, max_len, embedding_dim)
# 经过view函数x的维度变为(batch_size, input_chanel=1, w=max_len, h=embedding_dim)
x = x.view(x.size(0), 1, x.size(1), self.args.embedding_dim)
# 经过卷积运算,x中每个运算结果维度为(batch_size, out_chanel, w, h=1)
x = [F.relu(conv(x)) for conv in self.convs]
# 经过最大池化层,维度变为(batch_size, out_chanel, w=1, h=1)
x = [F.max_pool2d(input=x_item, kernel_size=(x_item.size(2), x_item.size(3))) for x_item in x]
# 将不同卷积核运算结果维度(batch,out_chanel,w,h=1)展平为(batch, outchanel*w*h)
x = [x_item.view(x_item.size(0), -1) for x_item in x]
# 将不同卷积核提取的特征组合起来,维度变为(batch, sum:outchanel*w*h)
x = torch.cat(x, 1)
# dropout层
x = self.dropout(x)
# 全连接层
logits = self.linear(x)
return logits
# forward的另外一种写法
# x = self.embedding(x)
# x = x.unsqueeze(1)
# x = [F.relu(conv(x)).squeeze(3) for conv in self.convs]
# x = [F.max_pool1d(item, item.size(2)).squeeze(2) for item in x]
# x = torch.cat(x, 1)
# x = self.dropout(x)
# logits = self.fc(x)
# return logits
关于数据预处理
- 使用torchtext库来进行文本处理,包括以下几个部分:
- 分词:torchtext使用jieba分词器作为tokenizer
- 去停用词:加载去停用词表,并在data.Field中设置
- text = data.Field(sequential=True, lower=True, tokenize=tokenizer, stop_words=stop_words)
- 文本长度padding:如果需要设置文本的长度,则在data.Field中设置fix_length,否则torchtext自动将文本长度处理为最大样本长度
- 词向量转换:torchtext能自动建立word2id和id2word两个索引,并将index转换为对应词向量,如果要加载预训练词向量,在build_vocab中设置即可
import jieba
from torchtext import data
import re
from torchtext.vocab import Vectors
def tokenizer(text): # create a tokenizer function
regex = re.compile(r'[^\u4e00-\u9fa5aA-Za-z0-9]')
text = regex.sub(' ', text)
return [word for word in jieba.cut(text) if word.strip()]
# 去停用词
def get_stop_words():
file_object = open('data/stopwords.txt')
stop_words = []
for line in file_object.readlines():
line = line[:-1]
line = line.strip()
stop_words.append(line)
return stop_words
def load_data(args):
print('加载数据中...')
stop_words = get_stop_words() # 加载停用词表
'''
如果需要设置文本的长度,则设置fix_length,否则torchtext自动将文本长度处理为最大样本长度
text = data.Field(sequential=True, tokenize=tokenizer, fix_length=args.max_len, stop_words=stop_words)
'''
text = data.Field(sequential=True, lower=True, tokenize=tokenizer, stop_words=stop_words)
label = data.Field(sequential=False)
text.tokenize = tokenizer
train, val = data.TabularDataset.splits(
path='data/',
skip_header=True,
train='train.tsv',
validation='validation.tsv',
format='tsv',
fields=[('index', None), ('label', label), ('text', text)],
)
if args.static:
text.build_vocab(train, val, vectors=Vectors(name="/brucewu/projects/pytorch_tutorials/chinese_text_cnn/data/eco_article.vector"))
args.embedding_dim = text.vocab.vectors.size()[-1]
args.vectors = text.vocab.vectors
else: text.build_vocab(train, val)
label.build_vocab(train, val)
train_iter, val_iter = data.Iterator.splits(
(train, val),
sort_key=lambda x: len(x.text),
batch_sizes=(args.batch_size, len(val)), # 训练集设置batch_size,验证集整个集合用于测试
device=-1
)
args.vocab_size = len(text.vocab)
args.label_num = len(label.vocab)
return train_iter, val_iter
参考:
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
- https://github.com/bigboNed3/chinese_text_cnn