【AI视野·今日CV 计算机视觉论文速览 第166期】Mon, 28 Oct 2019
AI视野·今日CS.CV 计算机视觉论文速览
Mon, 28 Oct 2019
Totally 47 papers
上期速览✈更多精彩请移步主页

Interesting:
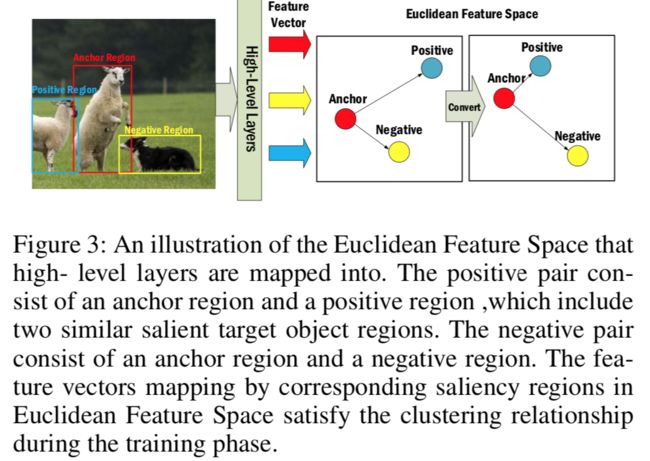
联合显著性检测,提出了一种从单张图像中检测出具有相似语义属性的物体显著性的的方法。比如从球场上检测出同一个队伍的人员,或者从分出不同毛色的相同动物 (from 武汉大学)


基于立体声的移动交通工具检测方法, 只需要利用立体声音数据和相机元数据即可在参考帧视频中定位运动目标的位置,而无需视频输入。(from mit)
, (from )
****Deep Image Blending一种优秀的图像融合方法, (from 宾夕法尼亚大学)
code:https://arxiv.org/pdf/1910.11495.pdf
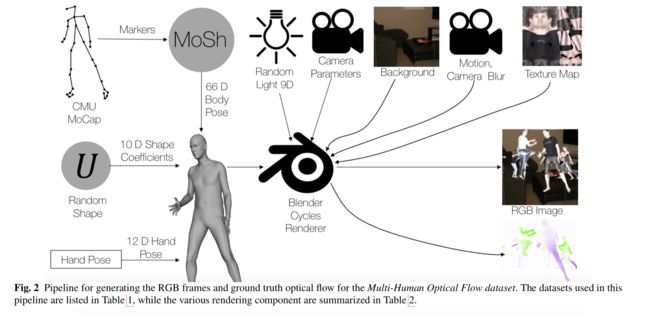
多人体光流学习, (from 马普研究所 德国)
基于blender进行数据合成的方法值得学习:

code:https://arxiv.org/pdf/1910.11667.pdf
ALET一个自然环境中工具检测数据和基线模型, (from 土耳其中东技术大学)

Daily Computer Vision Papers
| LPRNet: Lightweight Deep Network by Low-rank Pointwise Residual Convolution Authors Bin Sun, Jun Li, Ming Shao, Yun Fu 近年来,由于强大的计算设备(例如GPU),深度学习已变得流行。但是,将这些深度模型部署到资源有限的最终用户设备,智能电话或嵌入式系统是具有挑战性的。为了减少计算和内存成本,我们通过低秩逐点残差LPR卷积提出了一种新颖的轻量级深度学习模块,称为LPRNet。本质上,LPR的目标是在点向卷积中使用低秩逼近来进一步减小模块大小,同时将深度卷积作为残差模块来校正LPR模块。当低等级破坏卷积过程时,这一点至关重要。我们通过替换MobileNet和ShuffleNetv2中具有相同输入输出尺寸的模块来体现我们的设计。根据流行的基准进行的视觉识别任务(包括图像分类和面部对齐)的实验表明,与专注于模型压缩的最新深层模型相比,我们的LPRNet具有竞争优势,但Flops和内存成本显着降低。 |
| Learning to Track Any Object Authors Achal Dave, Pavel Tokmakov, Cordelia Schmid, Deva Ramanan 对象跟踪可以表示为在视频中找到合适的对象。我们观察到,用于类不可知跟踪的最新方法倾向于将重点放在发现部分上,但在很大程度上忽略了任务的对象部分,本质上是在滑动窗口中的框架上进行模板匹配。相反,特定类别的跟踪器严重依赖于特定类别对象检测器形式的对象先验。在这项工作中,我们将特定于类别的外观模型用于通用的对象。我们的方法可以将类别特定的对象检测器实时转换为类别不可知的特定对象检测器,即有效的跟踪器。此外,在测试时,可以将同一网络应用于检测和跟踪,从而为这两个任务提供统一的方法。我们使用外部数据,在两个最近的大规模跟踪基准OxUvA和GOT上获得了最先进的结果。通过简单地添加遮罩预测分支,我们的方法能够为被跟踪对象生成实例分割遮罩。尽管仅在第一帧上使用了盒级信息,但我们的方法仍输出高质量的蒙版,这是根据DAVIS 17视频对象分段基准进行评估的。 |
| An End-to-End Network for Co-Saliency Detection in One Single Image Authors Yuanhao Yue, Qin Zou, Hongkai Yu, Qian Wang, Song Wang 作为常见的视觉问题,单个图像内的共显着性检测没有引起足够的重视,但尚未得到很好的解决。现有方法通常遵循自下而上的策略来推断图像中的共显着性,其中首先使用诸如颜色和形状的视觉图元检测显着区域,然后将其分组并合并为同显性图。但是,在人类视觉中,自下而上和自上而下的策略结合在一起,以一种复杂的方式固有地感知了共显性。针对这一问题,本文提出了一种新型的端到端可训练网络,它包括一个骨干网和两个分支网。骨干网使用地面真相掩码作为显着性预测的自上而下的指导,而两个分支网为特征组织和聚类构建三元组提议,这促使网络以自下而上的方式对共同区域敏感。为了评估所提出的方法,我们构造了一个新的数据集,其中包含每张图像中的共同凸显的2,019张自然图像。实验结果表明,所提出的方法以28fps的运行速度达到了最先进的精度。 |
| Real-time Memory Efficient Large-pose Face Alignment via Deep Evolutionary Network Authors Bin Sun, Ming Shao, Siyu Xia, Yun Fu 由于近来的面部识别应用的激增,迫切需要以存储有效和实时的方式应用面部对准。但是,诸如姿势变化大和计算效率低等影响因素仍然阻碍了其广泛实施。为此,我们提出了一种与3D扩散堆贴图DHM集成的高效计算的深度演化模型。首先,我们引入一个稀疏的3D DHM来辅助极端姿势条件下的初始建模过程。然后,提取简单有效的CNN特征,并将其输入到递归神经网络RNN中进行进化学习。为了加速该模型,我们提出了一种有效的网络结构,以通过分解策略来加速进化学习过程。在三个流行的对齐数据库上进行的大量实验证明了所提出的模型优于现有技术的优势,尤其是在大摆姿势条件下。值得注意的是,我们模型的计算速度比CPU上的最新技术快10倍,而在GPU上则是14倍。我们还将讨论和分析我们的模型和未来研究工作的局限性。 |
| JRDB: A Dataset and Benchmark for Visual Perception for Navigation in Human Environments Authors Roberto Mart n Mart n, Hamid Rezatofighi, Abhijeet Shenoi, Mihir Patel, JunYoung Gwak, Nathan Dass, Alan Federman, Patrick Goebel, Silvio Savarese 我们展示了JRDB,这是一个从我们的社交移动操纵器JackRabbot收集的新颖数据集。数据集包括64分钟的多模式传感器数据,包括15 fps的立体声圆柱体360 circ RGB视频,两个Velodyne 16 Lidars的3D点云,两个Sick Lidars的线3D点云,音频信号,30 fps的RGBD视频,360 circ球形鱼眼镜头的图像和机器人车轮的编码器值。我们的数据集包括来自传统上代表性不足的场景(例如室内环境和行人区域)的数据,这些数据来自固定和导航机器人平台。该数据集已标注了超过230万个边界框,这些边界框分布在场景中的所有人周围的5个单独的摄像头中,以及180万个相关的3D长方体,总计超过3500个时间一致性轨迹。连同我们的数据集和注释,我们为2D和3D人员检测和跟踪启动了基准和指标。借助我们计划在将来进行进一步注释的数据集,我们希望为机器人自主导航以及人类环境中围绕社交机器人的所有感知任务领域的研究提供新的数据源和测试平台。 |
| Self-supervised Learning of Detailed 3D Face Reconstruction Authors Yajing Chen, Fanzi Wu, Zeyu Wang, Yibing Song, Yonggen Ling, Linchao Bao 在本文中,我们提出了一个端到端学习框架,用于从单个图像进行详细的3D人脸重建。我们的方法使用基于3DMM的粗略模型和UV空间中的位移图来表示3D面。与以前解决该问题的工作不同,我们的学习框架不需要监督使用传统方法计算的替代地面真实3D模型。相反,我们在学习过程中将输入图像本身用作监督。在第一阶段,我们将输入面部和渲染面部之间的光度损失和面部感知损失结合起来,以回归基于3DMM的粗略模型。在第二阶段,将输入图像和粗糙模型的回归纹理都展开到UV空间中,然后通过图像到图像转换网络发送以预测UV空间中的位移图。位移图和粗略模型用于渲染最终的详细人脸,该人又可以与原始输入图像进行比较,以作为第二阶段的光度损失。在UV空间中学习位移贴图的优点是,可以在展开过程中明确完成面部对齐,因此更容易从大量数据中学习面部细节。大量的实验证明了所提出的方法优于以前的工作。 |
| ClsGAN: Selective Attribute Editing Based On Classification Adversarial Network Authors Liu Ying, Heng Fan, Fuchuan Ni, Jinhai Xiang 归因编辑通过结合编码器,解码器结构和生成对抗网络,显示出令人瞩目的进步。但是,在生成图像的质量和属性转换方面仍然存在一些挑战。编码器解码器结构导致图像模糊,并且编码器解码器结构的跳跃连接削弱了属性传递能力。为了解决这些限制,我们提出了一个分类对抗模型Cls GAN,它可以在属性传递和生成的照片逼真的图像之间取得平衡。考虑到传输图像受使用跳过连接的原始属性的影响,我们引入了上卷积残差网络Tr resnet来从源图像和目标标签中选择性地提取信息。特别地,我们将其应用于属性分类对抗网络,以了解属性传递图像的缺陷,以指导生成器。最后,为了满足多模式的需求并提高重构效果,我们构建了包括内容和样式网络在内的两个编码器,并选择了源标签和样式网络输出之间的属性标签近似值。在CelebA数据集上进行的实验表明,图像在图像质量和传输准确性方面优于现有的现有模型。 Wikiart和季节性数据集上的实验表明,ClsGAN可以有效地实现样式转移。 |
| Gated Multi-layer Convolutional Feature Extraction Network for Robust Pedestrian Detection Authors Tianrui Liu, Jun Jie Huang, Tianhong Dai, Guangyu Ren, Tania Stathaki 随着深度卷积神经网络的发展,行人检测方法得到了显着改善。然而,如何可靠地检测大小和遮挡较大的行人仍然是一个具有挑战性的问题。在本文中,我们提出了一种门控多层卷积特征提取方法,该方法可以自适应地生成候选行人区域的判别特征。提出的门控特征提取框架由挤压单元,门控单元和级联层组成,分别执行多个CNN层的特征尺寸压缩,特征元素操纵和卷积特征组合。我们提出了两种不同的门模型,可以分别以通道明智的选择方式和空间明智的选择方式来操纵区域特征图。在具有挑战性的CityPersons数据集上进行的实验证明了该方法的有效性,尤其是在检测那些较小的人行道和被遮挡的行人时。 |
| Self-supervised Moving Vehicle Tracking with Stereo Sound Authors Chuang Gan, Hang Zhao, Peihao Chen, David Cox, Antonio Torralba 人类能够使用视觉和听觉线索来定位环境中的对象,并将来自多种模态的信息整合到一个共同的参考框架中。我们介绍了一种系统,该系统可以利用未标记的视听数据来学习在视觉参考系中定位移动车辆的对象,而在推理时仅使用立体声即可。由于手动注释音频和对象边界框之间的对应关系需要大量劳动,因此我们通过使用未标记视频中视频和音频流的共同出现作为一种自我监督的方式来实现此目标,而无需借助地面真理注释的收集。特别是,我们提出了一个由视觉老师网络和立体声学生网络组成的框架。在训练过程中,使用未标记的视频作为桥梁,将建立在完善的可视车辆检测模型中的知识转移到音频域。在测试时,立体声学生网络可以独立工作,仅使用立体声音频和摄像机元数据进行对象定位,而无需任何视觉输入。在新收集的Au Ditory Vehicle Tracking数据集上的实验结果证明,我们提出的方法优于几种基准方法。我们还证明,我们的交叉模式听觉定位方法可以在光线不足的情况下帮助移动车辆的视觉定位。 |
| ALET (Automated Labeling of Equipment and Tools): A Dataset, a Baseline and a Usecase for Tool Detection in the Wild Authors Fatih Can Kurnaz, Burak Hocao lu, Mert Kaan Y lmaz, dil S lo, Sinan Kalkan KOVAN Research Lab, Dept. of Computer Engineering, Middle East Technical University, Ankara, Turkey 在现实环境中与人类协作的机器人将需要能够检测可以使用和操纵的工具。但是,没有可用的数据集或研究可以解决实际环境中的这一挑战。在本文中,我们通过提供广泛的METU ALET数据集填补了这一空白,该数据集可用于检测农业,园艺,办公室,石工,车辆,木工和车间工具。这些场景对应于使用或不使用人工工具的复杂环境。我们考虑的场景为对象检测带来了一些挑战,包括工具的小规模,它们的铰接性质,遮挡,类间不变性等。此外,我们训练并比较了几种最先进的深度对象检测器,包括Faster R CNN,数据集上的YOLO和RetinaNet。我们观察到检测器很难检测到特别是小型工具或在视觉上与其他工具的零件相似的工具。反过来,这也支持了我们的数据集和论文的重要性。借助数据集,代码和训练有素的模型,我们的工作为进一步研究工具及其在机器人应用中的使用奠定了基础。 |
| Hierarchical Prototype Learning for Zero-Shot Recognition Authors Xingxing Zhang, Shupeng Gui, Zhenfeng Zhu, Yao Zhao, Ji Liu 零射击学习ZSL近年来受到了广泛的关注和成功,特别是在细颗粒物体识别,检索和图像字幕领域。 ZSL的关键是通过辅助语义原型(例如单词或属性向量)将知识从可见的类转移到看不见的类。但是,由于语义原型中包含非视觉组件,因此先前作品中广为学习的投影函数无法很好地概括。此外,ZSL最先进的方法很少考虑提供的原型和捕获的图像的不完整性。在本文中,我们提出了一种分层的原型学习公式,以提供一个名为HPL的系统解决方案来实现零击识别。具体来说,HPL能够通过分别在转导设置下学习视觉原型来在可见和不可见的类域上获得可分辨性。为了缩小两个领域的差距,我们进一步在视觉和语义空间中学习了可解释的超级原型。同时,通过最大化其结构一致性来进一步桥接两个空间。这不仅促进了视觉原型的代表性,而且减轻了语义原型信息的丢失。然后精心设计和展示了一组广泛的实验,表明与各种设置下的当前可用替代方案相比,HPL的效率和有效性显着提高。 |
| Learning Multi-Human Optical Flow Authors Anurag Ranjan, David T. Hoffmann, Dimitrios Tzionas, Siyu Tang, Javier Romero, Michael J. Black 众所周知,人的光流可用于分析人的行为。最近的光流方法专注于训练深度网络以解决该问题。但是,他们使用的训练数据并不涵盖人体运动的领域。因此,我们开发了一个多人光流数据集,并在此数据集上训练了光流网络。我们使用人体和运动捕捉数据的3D模型在单人和多人图像中合成逼真的流场。然后,我们训练光流网络,以从成对的图像中估计人流场。我们证明,经过训练的网络比对测试数据进行保留的顶级方法要准确得多,并且可以很好地推广到真实的图像序列。代码,训练有素的模型和数据集可供研究。 |
| Attend to the Difference: Cross-Modality Person Re-identification via Contrastive Correlation Authors Shizhou Zhang, Yifei Yang, Peng Wang, Xiuwei Zhang, Yanning Zhang 跨模态人员重新识别的问题由于其实际意义最近已引起越来越多的关注。受人类在比较两个相似对象时通常会注意差异的事实的启发,我们提出了一种双路径交叉模态特征学习框架,该框架保留了固有的空间狭窄并处理了输入的交叉模态图像对的差异。我们的框架由两个主要组成部分组成:保留公共空间网络DSCSN的双路径空间结构和对比相关网络CCN。前者将交叉模态图像嵌入到通用的3D张量空间中,而不会丢失空间结构,而后者通过动态比较输入图像对来提取对比特征。注意,为输入的RGB和红外图像生成的表示形式相互依赖。我们对两个公共可用的RGB IR ReID数据集SYSU MM01和RegDB进行了广泛的实验,我们提出的方法在完整和简化的评估模式下都大大优于最新算法。 |
| Reducing Domain Gap via Style-Agnostic Networks Authors Hyeonseob Nam, HyunJae Lee, Jongchan Park, Wonjun Yoon, Donggeun Yoo 深度学习模型通常无法在新的测试域上维持其性能。该问题已被视为深度学习在实际应用中的关键限制。导致域更改易受攻击的主要原因之一是该模型倾向于偏向图像样式(即纹理)。为了解决这个问题,我们建议使用样式不可知网络SagNets来鼓励模型将更多注意力放在图像内容上,即跨域共享的形状但忽略图像样式。 SagNets由三种新技术组成:样式对抗学习,样式融合和样式一致性学习,每种技术都阻止模型基于样式信息做出决策。结合一些其他培训技术和几种模型变体的集成,提出的方法在Visual Domain Adaptation 2019 VisDA 2019 Challenge的半监督域自适应任务中获得第一名。 |
| Learning to Localize Temporal Events in Large-scale Video Data Authors Mikel Bober Irizar, Miha Skalic, David Austin 我们在Youtube 8M Segments数据集中解决大规模视频数据中事件的时间定位。视频识别中的这一新兴领域可以使应用程序识别视频中特定事件发生的准确时间,这对视频搜索具有广泛的意义。为了解决这个问题,我们提出了两种单独的方法:1是在精巧的数据集上构建梯度增强决策树模型,2是基于帧级数据,视频级数据和本地化模型的深度学习模型的组合。这两种方法的组合在第三届Youtube 8M视频识别挑战赛中排名第五。 |
| Seeing What a GAN Cannot Generate Authors David Bau, Jun Yan Zhu, Jonas Wulff, William Peebles, Hendrik Strobelt, Bolei Zhou, Antonio Torralba 尽管生成式对抗网络GAN取得了成功,但模式崩溃仍然是GAN训练期间的一个严重问题。迄今为止,很少有工作集中在理解和量化模型丢弃的模式上。在这项工作中,我们在分发级别和实例级别都可视化了模式崩溃。首先,我们部署一个语义分割网络,以比较生成图像中分割对象的分布与训练集中的目标分布。统计上的差异揭示了GAN忽略的对象类。其次,给定已识别的遗漏对象类,我们直接可视化GAN的遗漏。特别是,我们通过GAN比较了各个照片及其近似反演之间的特定差异。为此,我们放宽了反演问题,并解决了将GAN层而非整个发生器反演的棘手问题。最后,我们使用此框架来分析在多个数据集上受训的几个最近的GAN,并确定它们的典型故障案例。 |
| Hardware-aware One-Shot Neural Architecture Search in Coordinate Ascent Framework Authors Li Lyna Zhang, Yuqing Yang, Yuhang Jiang, Wenwu Zhu, Yunxin Liu 为大量的硬件设计准确而有效的卷积神经体系结构具有挑战性,因为硬件设计是复杂而多样的。本文解决了神经架构搜索NAS中的硬件多样性挑战。与先前的将搜索算法应用在人为设计的小型搜索空间而不考虑硬件多样性的先前方法不同,我们提出了HURRICANE,该方法在更大的搜索空间上探索自动硬件感知的搜索,并在协调上升框架中采用多步搜索方案,以生成定制模型用于不同类型的硬件。在ImageNet上进行的大量实验表明,与三种类型的硬件上最先进的NAS方法相比,我们的算法始终可以达到更低的推理延迟,并且具有相似或更高的准确性。值得注意的是,HURRICANE在ImageNet上实现了76.63最高的1精度,而DSP的推理延迟仅为16.5 ms,与FBNet iPhoneX相比,其精确度提高了3.4倍,推理速度提高了6.35倍。对于VPU,与无代理移动设备相比,飓风实现的前1位准确性高出0.53倍,加速比提高了1.49倍。即使对于经过充分研究的移动CPU,与类似的推理延迟相比,飓风也比FBNet iPhoneX的top 1精度高1.63。与SinglePath Oneshot相比,飓风还平均减少了54.7的培训时间。 |
| CrevNet: Conditionally Reversible Video Prediction Authors Wei Yu, Yichao Lu, Steve Easterbrook, Sanja Fidler 应用分辨率保留块是在视频预测中最大化信息保留的一种常见做法,但是它们的高内存消耗极大地限制了其应用场景。我们提出CrevNet,这是一个条件可逆网络,它使用可逆架构来构建双射双向双向自动编码器及其互补的递归预测器。我们的模型具有在理论上保证的特性,即在特征提取过程中不会丢失任何信息,并且内存消耗和计算效率都大大降低。 |
| Metric Classification Network in Actual Face Recognition Scene Authors Jian Li, Yan Wang, Xiubao Zhang, Weihong Deng, Haifeng Shen 为了使面部特征更具区分性,最近提出了一些新模型。但是,几乎所有这些模型都使用传统的人脸验证方法,其中使用瓶颈层输出的特征执行余弦运算。但是,每个模型每次在不同的测试集上运行时都需要更改阈值。这对于实际场景中的应用非常不合适。在本文中,我们训练了一个验证分类器来对决策阈值进行归一化,这意味着可以直接获得结果而无需替换阈值。我们将模型称为验证分类器,该模型在由一个卷积层和六个完全连接的层组成的结构上获得最佳结果。为了测试我们的方法,我们对Wild LFW和Youtube Faces YTF中的Labeled Face进行了广泛的实验,相对误差减少量分别比传统方法减少了25.37和26.60。这些实验证实了验证分类器在人脸识别任务上的有效性。 |
| Progressive Unsupervised Person Re-identification by Tracklet Association with Spatio-Temporal Regularization Authors Qiaokang Xie, Wengang Zhou, Guo Jun Qi, Qi Tian, Houqiang Li 用于人员识别的现有方法Re ID主要基于监督学习,该学习需要在所有摄像机视图中进行大量手动标记的样本进行训练。由于在现实世界的Re ID应用中,很难在多个不相交的相机视图上详尽地标记丰富的身份,因此这种范例遭受了可伸缩性问题的困扰。为此,我们提出了一种由Tracklet关联时空时空正则化TASTR在野外对无监督人员Re ID进行渐进式深度学习的方法。在我们的方法中,我们首先通过自动人员检测和跟踪来收集每个摄像机中的小轨迹数据。然后,基于摄像机三元组构造来训练初始Re ID模型以进行人像学习。之后,基于人的视觉特征和时空约束,我们将跨摄像机轨迹小波关联以生成跨摄像机三重奏并更新Re ID模型。最后,通过改进的Re ID模型,可以更好地提取人的视觉特征,从而进一步促进跨相机轨迹的关联。重复执行最后两个步骤,以逐步升级Re ID模型。 |
| An End-to-End Foreground-Aware Network for Person Re-Identification Authors Yiheng Liu, Wengang Zhou, Jianzhuang Liu, Guojun Qi, Qi Tian, Houqiang Li 重新识别人员是跨多个监视摄像机视图识别感兴趣的行人的关键任务。在人员识别中,通常用从矩形图像区域提取的特征来代表行人,该矩形图像区域不可避免地包含场景背景,这会导致歧义以区分不同的行人并降低准确性。为此,我们提出了一种端到端的前景感知网络,通过学习用于人员重新识别的软掩码来将前景与背景区分开。在我们的方法中,除了将行人ID用作对前景的监视之外,我们还将每个行人图像的摄像机ID引入背景建模。前景分支和背景分支是协同优化的。通过呈现目标注意力损失,从前景分支提取的行人特征对背景变得更加不敏感,这极大地减少了改变背景对在不同摄像机视图之间匹配相同图像带来的负面影响。值得注意的是,与现有方法相比,我们的方法不需要任何其他数据集来训练人类地标检测器或用于定位背景区域的分割模型。在三个具有挑战性的数据集上进行的实验结果,即Market 1501,DukeMTMC reID和MSMT17,证明了我们方法的有效性。 |
| TRB: A Novel Triplet Representation for Understanding 2D Human Body Authors Haodong Duan, KwanYee Lin, Sheng Jin, Wentao Liu, Chen Qian, Wanli Ouyang 人体姿势和形状是2D人体的两个重要组成部分。但是,如何有效地在图像中表示这两者仍然是一个悬而未决的问题。在本文中,我们提出了人体TRB的三重态表示形式,它是一种紧凑的2D人体表示形式,其骨架关键点捕获了人体姿势信息,轮廓关键点包含了人体形状信息。 TRB不仅保留了骨架关键点表示的灵活性,而且还包含丰富的姿势和人体形状信息。因此,它有望提供更广阔的应用领域,例如人体形状编辑和条件图像生成。我们进一步介绍了TRB估算的挑战性问题,需要共同学习人体的姿势和形状。我们基于流行的2D姿态数据集LSP,MPII,COCO构建了几个大型TRB估计数据集。为了有效地解决TRB估计问题,我们提出了一种具有三项新颖技术的两分支网络TRB网络,即X结构Xs,方向卷积DC和成对映射PM,以强制进行多级消息传递以进行联合特征学习。我们在拟议的TRB数据集上评估了拟议的TRB网络和几种领先方法,并通过广泛的评估证明了我们方法的优越性。 |
| Team PFDet's Methods for Open Images Challenge 2019 Authors Yusuke Niitani, Toru Ogawa, Shuji Suzuki, Takuya Akiba, Tommi Kerola, Kohei Ozaki, Shotaro Sano 我们介绍了PFDet团队在Open Images Challenge 2019中使用的实例分割和对象检测方法。我们解决了庞大的数据集大小,巨大的类不平衡和联合注释。使用此方法,团队PFDet在实例分割和对象检测轨迹上分别获得了第三和第四名。 |
| RhythmNet: End-to-end Heart Rate Estimation from Face via Spatial-temporal Representation Authors Xuesong Niu, Hu Han, Shiguang Shan, Xilin Chen 心率HR是重要的生理信号,可反映人的身体和情绪状态。传统的HR测量通常依赖于接触监视器,这可能会带来不便和不适。近来,已经提出了一些用于从面部视频进行远程HR估计的方法,但是,大多数方法集中在控制良好的场景上,它们在诸如头部移动和照明不良的情况下被推广到受约束较小的场景中的能力尚不清楚。同时,缺乏大规模的人力资源数据库限制了深度模型用于远程人力资源估计的使用。在本文中,我们提出了端到端的RhythmNet,用于从面部进行远程HR估计。在RyhthmNet中,我们使用对来自多个ROI体积的HR信号进行编码的空间时态表示作为其输入。然后,将空间时间表示馈送到卷积网络中以进行HR估计。我们还考虑了通过门控循环单元GRU从视频序列中相邻HR测量的关系,并实现了有效的HR测量。此外,我们还建立了一个名为VIPL HR的大规模多模式HR数据库,可从以下网站获得 |
| A comparable study: Intrinsic difficulties of practical plant diagnosis from wide-angle images Authors Katsumasa Suwa, Quan Huu Cap, Ryunosuke Kotani, Hiroyuki Uga, Satoshi Kagiwada, Hitoshi Iyatomi 适用于广角图像的实用的自动植物病害检测和诊断,即在野外图像中包含来自固定位置相机的多片叶子,这对于大规模农场管理非常重要,可确保全球食品安全。然而,开发自动疾病诊断系统通常很困难,因为从实际领域标记可靠的疾病广角数据集非常费力。此外,训练数据和测试数据之间的潜在相似性会导致严重的模型过度拟合问题。在本文中,我们调查了将疾病诊断系统应用于实际农场捕获的广角黄瓜测试数据的不同场景时的性能变化,并提出了一种较好的诊断策略。我们证明,领先的对象识别技术(例如SSD和Faster R CNN)仅在与训练数据集81.5 84.1 F1分数相同的人群中收集的被诊断疾病病例的测试数据集上实现了出色的端到端疾病诊断性能,但是它F1分数完全不同的测试数据4.4 6.2严重恶化。相反,具有独立叶子检测和叶子诊断模型的两阶段系统获得了有希望的疾病诊断性能,其比看不见的目标数据集上的F1得分的端到端系统33.4 38.9高出6倍以上。我们还从视觉评估中确认了其效率,认为两个阶段的模型是合适的,是实际应用的合理选择。 |
| Toward an Automatic System for Computer-Aided Assessment in Facial Palsy Authors Diego L. Guarin, Yana Yunusova, Babak Taati, Joseph R Dusseldorp, Suresh Mohan, Joana Tavares, Martinus M. van Veen, Emily Fortier, Tessa A. Hadlock, Nate Jowett 重要性机器学习ML进行人脸界标定位的方法具有巨大的临床潜力,可以对人脸功能进行定量评估,因为它们可以对照片中的相关人脸度量进行高通量自动量化。但是,从研究环境到临床应用的转换需要重要的改进。目的开发一种用于在面神经麻痹患者的照片中准确定位面部标志的ML算法,并将其用作自动计算机辅助诊断系统的一部分。设计,设置和参与者将面部标志手动定位在从200名面瘫患者和10名对照中获得的八种表情的肖像照片中。使用该疾病特异性数据库训练了用于自动面部界标定位的新颖的ML模型。将模型输出与手动注释进行比较,并使用仅包含健康受试者的较大数据库对模型的输出进行训练。通过算法预测和手动注释之间的归一化均方根误差NRMSE评估模型的准确性。结果与健康对照NRMSE相比,当应用于患者时,公开可用的算法提供的结果较差,NRMSE为8.56 2.16 vs. 7.09 2.34,p 0.01。与使用数千张健康面部图像训练的模型相比,使用相对较少数量的患者照片1440训练的模型,我们发现临床人群的面部界标定位精度有了显着提高,NRMSE,6.03 2.43 vs. 8.56 2.16,p 0.01 。结论用少量临床图像训练地标检测模型可以显着改善临床人群正面照片中的地标检测性能。这些结果代表了针对面瘫的计算机辅助评估自动系统的第一步。 |
| Deep Image Blending Authors Lingzhi Zhang, Tarmily Wen, Jianbo Shi 图像合成是创建视觉内容的重要操作。在图像合成任务中,图像融合旨在通过轻轻地进行蒙版调整将对象从源图像无缝融合到目标图像。泊松图像融合是一种流行的方法,它可以在合成图像中增强梯度域的平滑度。然而,该方法仅考虑目标图像的边界像素,因此不能适应目标图像的纹理。此外,目标图像的颜色通常会渗入原始源对象太多,从而导致源对象内容的重大损失。我们提出一种泊松混合损失,该损失可以实现泊松图像混合的相同目的。另外,我们共同优化了拟议的泊松混合损失以及从深度网络计算出的样式和内容损失,并通过使用L BFGS求解器迭代更新像素来重建混合区域。在融合图像中,我们不仅平滑了融合边界的梯度域,还向融合区域添加了一致的纹理。用户研究表明,将对象放置在绘画和真实世界图像上时,我们的方法优于强大的基准以及最新的方法。 |
| Multimodal Image Outpainting With Regularized Normalized Diversification Authors Lingzhi Zhang, Jiancong Wang, Jianbo Shi 在本文中,我们研究仅给出很小的前景区域时就产生一组现实而多样的背景的问题。我们将此任务称为图像外包。这项任务的技术挑战是不仅要合成合理的图像输出,还要合成各种图像输出。传统的生成对抗网络会遭受模式崩溃的影响。尽管最近的方法建议相对于其潜在距离最大化或保留生成的样本之间的成对距离,但它们并未明确阻止崩溃的不同条件输入的不同样本。因此,我们提出了一种新的正则化方法,以鼓励条件合成中的多种采样。此外,我们提出了一种特征金字塔判别器,以提高图像质量。我们的实验结果表明,与CelebA人脸数据集和Cityscape场景数据集中的最新技术相比,我们的模型可以在不牺牲视觉质量的情况下生成更多种多样的图像。 |
| Heterogeneous Graph Learning for Visual Commonsense Reasoning Authors Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao 视觉常识推理任务旨在通过预测正确答案的能力引领研究领域解决认知水平的推理,同时提供令人信服的推理路径,从而产生三个子任务,即Q A,QA R和Q AR。在视觉和语言领域以及知识推理之间产生恰当的语义一致性以产生有说服力的推理路径方面,这带来了巨大的挑战。现有作品要么诉诸功能强大的端到端网络,即无法产生可解释的推理路径,要么仅探索视觉对象同质图的内部关系,而忽略了视觉概念和语言单词之间的跨域语义对齐。在本文中,我们提出了一种新的异构图学习HGL框架,该框架可无缝集成图内图和图间推理,以桥接视觉和语言领域。我们的HGL包括回答异质图VAHG模块的原始视野和回答异质图QAHG模块以交互地完善语义协议推理路径的双重问题。此外,我们的HGL集成了上下文投票模块,可利用远程视觉上下文进行更好的全局推理。在大规模的视觉常识推理基准上进行的实验表明,我们提出的模块在三个任务上的出色性能提高了Q A的5精度,QA R的3.5精度,Q AR的5.8 |
| Animal Detection in Man-made Environments Authors Abhineet Singh, Marcin Pietrasik, Gabriell Natha, Nehla Ghouaiel, Ken Brizel, Nilanjan Ray 自动检测已误入人类居住区的动物具有重要的安全和道路安全应用。本文尝试使用来自各种计算机视觉领域的深度学习技术(包括对象检测,跟踪,分割和边缘检测)解决此问题。在调整在基准数据集上训练的模型以用于实际部署时,可以在迁移学习中获得一些有趣的见解。提供了经验证据来证明检测器无法将其在自然栖息地中的动物训练图像推广到人造环境的部署场景。还提出了一种使用半自动合成数据生成进行领域特定训练的解决方案。提供了实验中使用的代码和数据,以促进该领域的进一步工作。 |
| Learning an Uncertainty-Aware Object Detector for Autonomous Driving Authors Gregory P. Meyer, Niranjan Thakurdesai 检测物体的能力是自动驾驶的核心部分。由于传感器噪声和数据不完整,无法完美检测和定位每个对象。因此,对于检测器而言,在每个预测中提供不确定量非常重要。为自主系统提供可靠的不确定性,可使车辆根据不确定性程度做出不同的反应。先前的工作通过预测对象边界框上的概率分布来估计检测中的不确定性。在这项工作中,我们提出了一种方法,通过考虑地面真实标记数据中的潜在噪声来提高学习概率分布的能力。我们提出的方法不仅提高了学习分布的准确性,而且还提高了对象检测性能。 |
| Learning eating environments through scene clustering Authors Sri Kalyan Yarlagadda, Sriram Baireddy, David G era. Carol J. Boushey, Deborah A. Kerr, Fengqing Zhu 众所周知,饮食习惯对健康有重大影响。尽管已经进行了许多研究来了解这种关系,但对饮食环境和健康之间的关系知之甚少。然而,世界各地的研究人员和卫生机构已经认识到饮食环境是改善饮食和健康的有希望的环境。在本文中,我们提出了一种图像聚类方法,该方法可从社区居住饮食研究期间捕获的进餐场合图像中自动提取进餐环境。具体来说,我们有兴趣了解一个人在哪种不同的环境中食用食物。我们的方法通过使用深度神经网络提取全局和局部尺度的特征来对图像进行聚类。由不同个体捕获的簇和图像的数量的变化使得这成为非常具有挑战性的问题。实验结果表明,与几种现有的聚类方法相比,我们的方法性能明显更好。 |
| ***Handheld Mobile Photography in Very Low Light Authors Orly Liba, Kiran Murthy, Yun Ta Tsai, Tim Brooks, Tianfan Xue, Nikhil Karnad, Qiurui He, Jonathan T. Barron, Dillon Sharlet, Ryan Geiss, Samuel W. Hasinoff, Yael Pritch, Marc Levoy 使用手机在低光下拍摄照片具有挑战性,并且几乎不会产生令人满意的结果。除了读取噪声和光子散粒噪声带来的物理限制外,这些相机通常是手持式的,具有小光圈和传感器,使用不易冷却的大量生产的模拟电子设备,通常用于拍摄移动的物体,例如儿童和儿童。宠物。在本文中,我们描述了一种用于在低至0.3 lux的光线下捕获干净,清晰,彩色照片的系统,在该系统中,人的视觉变得单色且模糊。为了使手持摄影机无需闪光灯照明,我们可以捕获,对齐和组合多个帧。我们的系统采用运动测光技术,该技术可使用运动量估计值(无论是由于握手还是运动物体引起的)来识别帧数和每帧曝光时间,从而将捕获的突发中的噪声和运动模糊最小化。我们使用专门针对高噪声图像的鲁棒对齐和合并技术来组合这些帧。为了确保在这种弱光下准确的色彩,我们采用了基于学习的自动白平衡算法。为了防止照片看起来像是在白天拍摄的照片,我们使用了色调映射技术,该技术的灵感来自幻觉绘画,以增加对比度,将阴影粉碎为黑色,并在黑暗中环绕场景。所有这些过程都是使用移动设备的有限计算资源执行的。新手摄影师可以使用我们的系统通过单次快门按下在几秒钟内生成可共享的照片,即使在昏暗的环境下,人也看不清。 |
| Surreal: Complex-Valued Deep Learning as Principled Transformations on a Rotational Lie Group Authors Rudrasis Chakraborty, Yifei Xing, Stella Yu 近年来,复杂的深度学习因其多功能性和捕获更多信息的能力而受到越来越多的关注。但是,缺乏明确定义的复杂价值操作仍然是进一步发展的瓶颈。在这项工作中,我们提出了一种利用加权Fr chet平均方法在复数空间上定义深度神经网络的几何方法。我们用数学方法证明了该算法的可行性。我们还定义了基本的构造块,例如卷积,非线性和针对复数空间量身定制的残差连接。为了证明我们提出的模型的有效性,我们在使用不到1个参数的同时,将我们的复杂价值网络与其在MSTAR分类任务中的最新技术进行了全面比较,并获得了更好的性能。 |
| Stabilizing DARTS with Amended Gradient Estimation on Architectural Parameters Authors Kaifeng Bi, Changping Hu, Lingxi Xie, Xin Chen, Longhui Wei, Qi Tian 差异化神经架构搜索已成为探索用于深度学习的架构的流行方法。尽管搜索效率具有很大的优势,但它经常会遇到稳定性较弱的问题,这使其无法应用于较大的搜索空间或灵活地适应不同的情况。本文研究了目前最流行的差分搜索算法DARTS,并指出了不稳定性的重要因素,这取决于它对建筑参数梯度的近似。在当前状态下,优化算法可能会收敛到另一点,这会导致重新训练过程中出现严重的准确性。在此分析的基础上,我们提出了一个利用网络参数优化的最优性的直接属性来计算体系结构梯度的修正术语。我们的方法在数学上保证了梯度估计遵循大致正确的方向,这导致搜索阶段收敛于合理的体系结构。实际上,我们的算法很容易实现,并且可以有效地添加到基于DARTS的方法中。在CIFAR和ImageNet上进行的实验表明,我们的方法具有较高的准确性,更重要的是,它使基于DARTS的方法能够探索以前从未研究过的更大的搜索空间。 |
| DR$\vert$GRADUATE: uncertainty-aware deep learning-based diabetic retinopathy grading in eye fundus images Authors Teresa Ara jo, Guilherme Aresta, Lu s Mendon a, Susana Penas, Carolina Maia, ngela Carneiro, Ana Maria Mendon a, Aur lio Campilho 糖尿病性视网膜病变DR分级对于确定患者的适当治疗和随访至关重要,但是筛查过程可能很烦人并且容易出错。深度学习方法已显示出作为计算机辅助诊断CAD系统的有希望的性能,但是它们的黑匣子行为阻碍了其临床应用。我们提出了DR vert GRADUATE,这是一种新颖的基于深度学习的DR评分CAD系统,它通过提供医学上可以解释的解释以及对该预测的不确定性的估计来支持其决策,从而使眼科医生可以衡量该决策应得到多少信任。我们在设计DR vert GRADUATE时考虑了DR分级问题的序数性质。一种基于多实例学习框架的新颖的高斯采样方法,使DR vert GRADUATE可以推断与解释图和预测不确定性相关的图像等级,而仅使用图像明智的标签进行训练。 DR vert GRADUATE在Kaggle训练集中进行了训练,并在多个数据集中进行了评估。在DR分级中,在五个不同的数据集中获得了介于0.71和0.84之间的二次加权Cohen s Kappa QWK。我们表明高QWK值发生在具有低预测不确定性的图像上,因此表明该不确定性是预测质量的有效度量。此外,质量差的图像通常会带来较高的不确定性,这表明不适合诊断的图像确实导致可信度较低的预测。此外,对不熟悉的医学图像数据类型的测试表明,DR vert GRADUATE可以进行离群值检测。注意图通常会突出显示感兴趣的区域以进行诊断。这些结果表明,DR vert GRADUATE作为DR严重度分级的第二意见系统具有巨大潜力。 |
| Contextual Imagined Goals for Self-Supervised Robotic Learning Authors Ashvin Nair, Shikhar Bahl, Alexander Khazatsky, Vitchyr Pong, Glen Berseth, Sergey Levine 强化学习为学习个人技能提供了一种吸引人的形式主义,而通用机器人系统必须能够掌握广泛的行为准则。我们可以让机器人自动提出和实践自己的行为,而不是学习大量技能,而是了解机器人在环境中可以执行的承受能力和行为,以便一旦有了新的知识就可以重新利用这些知识。任务由用户指挥在本文中,我们将在自我监督的目标条件强化学习的背景下研究该问题。在这种学习方式中的一个主要挑战是为了练习有用技能而设定目标的问题,机器人必须能够自主设定可行但多样的目标。当机器人的环境和可用对象发生变化时(如大多数开放世界设置中的情况一样),机器人必须仅向自身提出可以在当前设置下使用手边的对象完成的那些目标。先前的工作仅在单一环境中研究自我监督的目标条件RL,其中目标建议来自机器人的过去经验或生成的模型就足够了。在更多样化的环境中,这经常会导致无法实现的目标,并且正如我们通过实验表明的那样,这会阻止有效的学习。我们提出了一个条件目标设定模型,旨在提出可以从机器人当前状态可行的目标。我们证明,这可以使自我监督的目标以现实世界中原始图像的观察为基础,以政策学习为条件,从而使机器人能够操纵各种对象并将其推广到训练期间未看到的新对象。 |
| Learning Task-Oriented Grasping from Human Activity Datasets Authors Mia Kokic, Danica Kragic, Jeannette Bohg 我们建议利用现实世界中的人类活动RGB数据集来教授机器人em面向任务的抓图TOG。一方面,由于交互过程中包含手和对象的RGB D数据集通常缺少注释,这是由于手动获取它们而造成的。另一方面,RGB数据集通常带有标签注释,这些标签没有提供足够的信息来推断6D机器人抓握姿势。但是,它们包含对许多不同任务的各种对象进行掌握的示例。因此,与RGB D数据集相比,它们提供了更丰富的监管来源。我们提出了一个模型,该模型以RGB图像作为输入,并输出手的姿势和配置以及对象的姿势和形状。我们遵循的见解是,与相互独立地估计这些数量相比,共同估计手和物体的姿势可以提高准确性。定量实验表明,使用手部姿势信息训练对象姿态预测器,反之亦然,比没有此信息的训练更好。给定训练后的模型,我们处理RGB数据集以自动获取TOG模型的训练数据。该模型将对象点云和任务作为输入,并在给定任务的情况下输出适合抓取的区域。定性实验表明,我们的模型可以成功处理现实世界的数据集。用机器人进行的实验表明,该数据使机器人能够学习面向任务的对新颖对象的掌握。 |
| Mixing realities for sketch retrieval in Virtual Reality Authors Daniele Giunchi, Stuart james, Donald Degraen, Anthony Steed 用于虚拟现实VR的绘图工具使用户可以在虚拟环境本身内部对3D设计进行建模。这些工具采用基于桌面的界面中已知的素描和雕刻技术,并将其应用于基于手的控制器交互。尽管这些技术允许对基本形状进行空中草图绘制,但用户仍然难以创建详细而全面的3D模型。在我们的工作中,我们致力于通过增强基于草图的界面以及用于交互模型检索的支持系统,来支持用户设计周围的虚拟环境。通过草绘,沉浸式用户可以查询包含详细3D模型的数据库,并将其替换为虚拟环境。为了了解虚拟环境中的辅助素描,我们比较了素描交互的不同方法,即3D空中素描,虚拟平板电脑上的2D素描,固定虚拟白板上的2D素描和真实平板电脑上的2D素描。使用2D物理平板电脑,2D虚拟平板电脑,2D虚拟白板和3D空中草图。我们的结果表明,空中3D草图绘制被认为是搜索模型集合的一种更直观的方法,而物理设备的添加由于将其包含在虚拟环境中的复杂性而造成了混乱。虽然我们将工作视为椅子3D模型的检索问题,但是我们的结果可以外推到虚拟环境的其他草图绘制任务。 |
| A Simple Dynamic Learning Rate Tuning Algorithm For Automated Training of DNNs Authors Koyel Mukherjee, Alind Khare, Ashish Verma 在图像数据集上训练神经网络通常需要进行大量实验,以找到最佳学习率制度。特别是,在对抗训练或训练新合成模型的情况下,人们不会事先知道最佳学习率制度。我们提出了一种用于确定学习率轨迹的自动算法,该算法可跨数据集和模型进行自然训练和对抗训练,而无需任何特定于数据集模型的调整。它是一种独立的无参数自适应方法,无计算开销。我们从理论上讨论算法的收敛行为。我们从经验上广泛验证了我们的算法。我们的结果表明,在自然训练和对抗训练中,与文献中的SOTA基准相比,我们提出的方法Emph始终可达到最高的准确性。 |
| Deep 1D-Convnet for accurate Parkinson disease detection from gait Authors Imanne El Maachi, Guillaume Alexandre Bilodeau, Wassim Bouachir 诊断帕金森氏病是一项复杂的任务,需要评估几种运动和非运动症状。在诊断过程中,步态异常是医生应考虑的重要症状之一。然而,步态评估具有挑战性,并且依赖于临床医生的专业知识和主观性。在这种情况下,智能步态分析算法的使用可以帮助医师,以促进诊断过程。本文提出了一种基于深度学习技术的新型智能帕金森检测系统,用于分析步态信息。我们使用1D卷积神经网络1D Convnet来构建深度神经网络DNN分类器。所提出的模型处理来自脚传感器的18个1D信号,这些信号测量垂直地面反作用力VGRF。网络的第一部分包括与系统输入相对应的18个并行一维Convnet。第二部分是一个完全连接的网络,该网络连接一维Convnet的并置输出以获得最终分类。我们用帕金森病统一评分量表UPDRS对帕金森氏病的检测和疾病严重程度的预测进行了测试。我们的实验证明了该方法在基于步态数据的帕金森病检测中的高效性。该算法的准确率达98.7。据我们所知,这是帕金森步态识别开始表现的状态。此外,我们在帕金森病严重程度预测中达到了85.3的准确性。据我们所知,这是第一个基于UPDRS进行严重性预测的算法。我们的结果表明,该模型能够从步态数据中学习内在特征,并将其推广到看不见的受试者,这可能有助于临床诊断。 |
| Causal inference for climate change events from satellite image time series using computer vision and deep learning Authors Vikas Ramachandra 为了确定影响气候变化(如森林砍伐)的干预措施的处理效果,我们提出了一种使用卫星图像时间序列进行因果推理的方法。简而言之,目的是量化与气候相关的人为干预措施(如城市化)以及自然灾害(如飓风和森林火灾)的前后影响。作为一个具体的例子,我们专注于量化由于人为原因引起的林木覆盖率变化。所提出的方法包括以下步骤。首先,我们使用计算机视觉和机器学习深度学习技术来在每个时间段检测和量化随时间变化的林木覆盖水平。然后,我们查看此时间序列以识别变更点。接下来,我们使用贝叶斯结构因果模型并预测对事实的预测来估计预期的森林树木覆盖值。将其与干预后实际观察到的值进行比较,并且两个值的差异为我们提供了与非干预方案相比的干预效果,即如果没有干预,可能会发生的情况。作为一个特定的用例,我们分析了巴西在1993年结束的恶性通货膨胀事件干预之前和之后的森林砍伐水平94,针对巴西朗多尼亚附近的亚马逊雨林地区。对于这种森林砍伐用例,使用我们的因果推断框架可以帮助归因于归因于森林树木覆盖率变化的减少和由于人类在不同时间点的活动造成的森林砍伐率的提高。 |
| Human Action Recognition Using Deep Multilevel Multimodal (M2) Fusion of Depth and Inertial Sensors Authors Zeeshan Ahmad, Naimul Khan 多年来,人们已经提出了使用深度和惯性传感器数据的用于人类动作识别HAR的多模式融合框架。在大多数现有工作中,融合是在单个级别的功能级别或决策级别执行的,而缺少融合更好的分类所必需的丰富的中级功能的机会。为了解决这个缺点,在本文中,我们提出了三种新颖的深层多级多模式融合框架,以利用各个阶段的不同融合策略并利用多级融合的优势。在输入时,我们将深度数据转换为称为顺序前视图图像SFI的深度图像,并将惯性传感器数据转换为信号图像。通过使用Prewitt滤波器进行卷积,可以使每个输入模态,深度和惯性进一步变为多模态。在模态内创建模态,可以通过卷积神经网络CNN进一步提取互补和区分特征。对CNN进行每种形式的输入图像训练,以学习低级,高级和复杂功能。在提出的框架的不同阶段提取和融合学习到的特征,以结合区分性和补充性信息。这些高信息量的功能用作多类支持向量机SVM的输入。我们在三个公开的多模式HAR数据集(即UTD多模式人类行为数据集MHAD,Berkeley MHAD和UTD MHAD Kinect V2)上评估了提出的框架。实验结果表明,所提出的融合框架优于现有方法。 |
| Unified Multi-scale Feature Abstraction for Medical Image Segmentation Authors Xi Fang, Bo Du, Sheng Xu, Bradford J. Wood, Pingkun Yan 自动医学图像分割是医学图像分析的重要组成部分,在计算机辅助诊断中起着重要作用。例如,对肝脏进行定位和分割对肝癌的诊断和治疗非常有帮助。医学图像分割中的最新模型是编码器解码器体系结构的变体,例如全卷积网络FCN和UNet。1基于FCN的分割方法的主要重点是通过合并最新的CNN结构(例如ResNet2和DenseNet)进行网络结构工程。 3除了探索新的网络结构以有效地提取高级特征外,在FCN中并入用于多尺度图像特征提取的结构还有助于提高分割任务的性能。在本文中,我们设计了一种新的多尺度网络体系结构,该体系结构通过具有专用卷积路径的多尺度输入来有效地组合不同尺度的特征,从而更好地利用层次信息。 |
| HRL4IN: Hierarchical Reinforcement Learning for Interactive Navigation with Mobile Manipulators Authors Chengshu Li, Fei Xia, Roberto Martin Martin, Silvio Savarese 人类环境中最常见的导航任务需要辅助手臂交互,例如打开门,按下按钮并推开障碍物。这种类型的导航任务(我们称为交互式导航)要求使用具有操纵功能的移动操纵器移动基座。交互式导航任务通常是长期的,并且由纯导航,纯操纵及其组合的异构阶段组成。使用实施例的错误部分效率低下并且阻碍了进展。我们提出HRL4IN,这是一种用于交互式导航任务的新颖的层次RL体系结构。由于对子目标的时间扩展承诺,HRL4IN在长期任务中利用了HRL相对于平坦RL的勘探优势。与其他HRL解决方案不同,HRL4IN通过在任务的不同阶段的不同空间中创建子目标来处理交互式导航任务的异构性质。此外,HRL4IN选择实施例的不同部分用于每个阶段,从而提高了能源效率。我们在两种环境下,即2D网格世界环境和3D环境(具有物理仿真),针对平面PPO和最新的HRL算法HAC HAR4IN评估了HRL4IN。我们显示,HRL4IN在任务性能和能效方面明显优于其基准。有关更多信息,请访问: |
| Reconstruction of Undersampled 3D Non-Cartesian Image-Based Navigators for Coronary MRA Using an Unrolled Deep Learning Model Authors Mario O. Malav , Corey A. Baron, Srivathsan P. Koundinyan, Christopher M. Sandino, Frank Ong, Joseph Y. Cheng, Dwight G. Nishimura 目的利用展开的深度学习DL模型快速重建欠采样的3D非笛卡尔图像导航器iNAV,用于冠状动脉磁共振血管成像CMRA中的非刚性运动校正。 |
| Accurate Layerwise Interpretable Competence Estimation Authors Vickram Rajendran, William LeVine 在野外估计机器学习性能是一个重要且尚未解决的问题。在本文中,我们试图检查,理解和预测分类模型的点状能力。我们的贡献是双重的。首先,我们建立了统计上严格的能力定义,以概括分类器置信度的通用概念;其次,我们提出了ALICE准确的分层可解释的能力估计值,这是任何分类器的逐点能力估计器。通过考虑分布,数据和模型的不确定性,ALICE可以在常见故障情况下(例如类不平衡数据集,分布数据集不足和训练不足的模型)凭经验显示准确的能力估计。我们的贡献使我们能够准确地预测给定任何输入和误差函数的任何分类模型的能力。我们将我们的分数与模型置信度和信任度分数等最先进的置信度估计值进行比较,并在诸如DIGITS,CIFAR10和CIFAR100的数据集上显示出优于这些方法的能力预测方面的显着改进。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com