【AI视野·今日CV 计算机视觉论文速览 第169期】Fri, 22 Nov 2019
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 22 Nov 2019
Totally 56 papers
上期速览✈更多精彩请移步主页

Interesting:
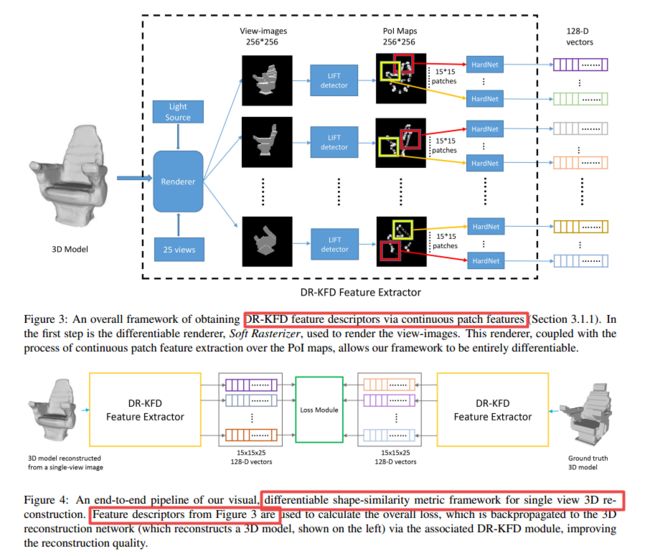
DR-KFD用于三维重建的可差分视觉度量方法, 在对于形状的多视角渲染下,对三维形状和图像空间视觉的差异来度量重建的效果。同时基于MSE开发了一种可差分的图像空间距离,从概率关键点图中计算得到。这种可差分的视觉形状度量方法可以方便的插入现有的重建网络中去,代替目标空间中Chamfer和测地线距离等度量,优化生成结果的视觉效果和结构保真度。(from 西蒙弗雷泽大学 加拿大)
下图展示了使用这种度量训练的结果由于Chamfer distance的结果:

现有方法主要使用测地线和Chamfer距离作为度量:

抽取描述子和计算损失的过程:

训练出的效果更好:

基于巨像素的复杂场景的单目三维重建, 在相机和拍摄对象同时都在移动时候,需要建立有效的对应关系来构建三维模型。研究人员假设场景可以被近似为一系列逐片的平面小单元,每个平面具有自己的刚体运动,在帧之间的的动态变换尽可能的满足刚体变换。这就将对场景的建模问题简化为对一系列刚体平面结构及其刚体运动的建模。基于对场景的图割实现小平面单元分割,将这一问题进一步转化为了一个类似三维拼图的任务,将对应的片元拼接在正确的三维位置,使得边界结构更为连续。(from 澳大利亚国立)


重建出的深度图效果很好,由于video-popup的方法:

基于边界上的边界点检测来实现场景文本检测, 通过检测边界点来检测和校正文本。(from 华中科技大学和阿里巴巴 AAAI)


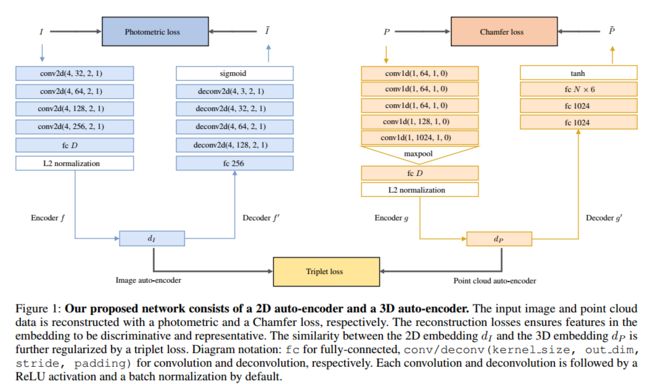
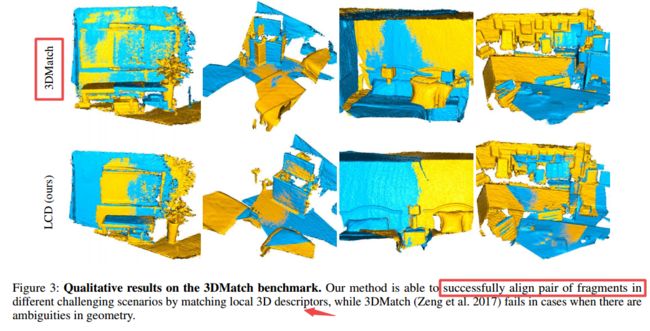
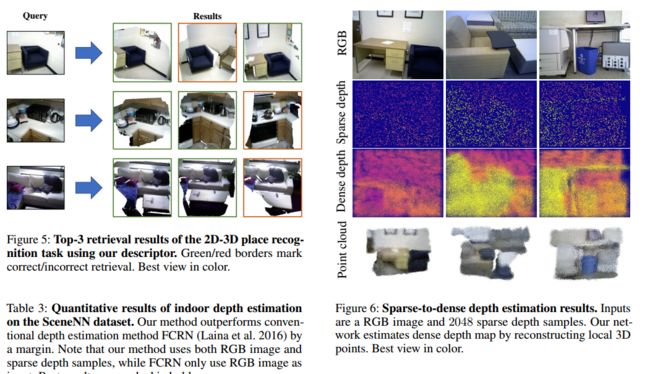
LCD学习二维图像与三维点云间的跨域描述子, 可用于图像检索、三维匹配、二维三维匹配检索、稀疏深度稠密估计。(from 新加坡技术设计 斯坦福 东京大学)
学习从图像中定位声源, (from KAIST)


CCGAN基于分类驱动的图像去雾网络模型, (from 北京交通大学)

与相关方法的比较:
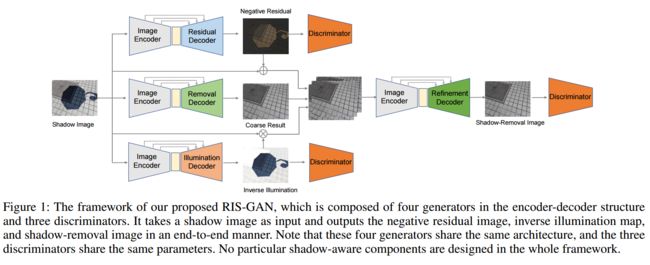
RIS-GAN利用残差和照明关系通过生成对抗来移除图像中的阴影, (from 武汉科技大学)
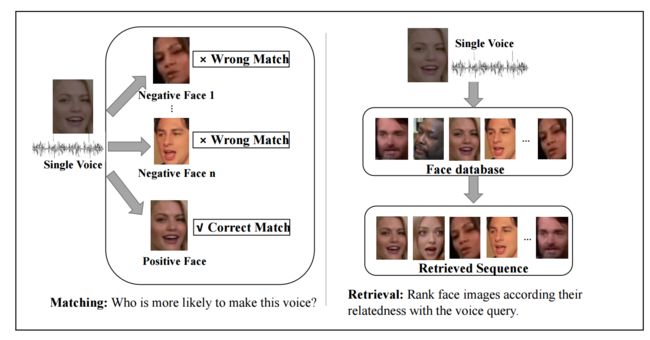
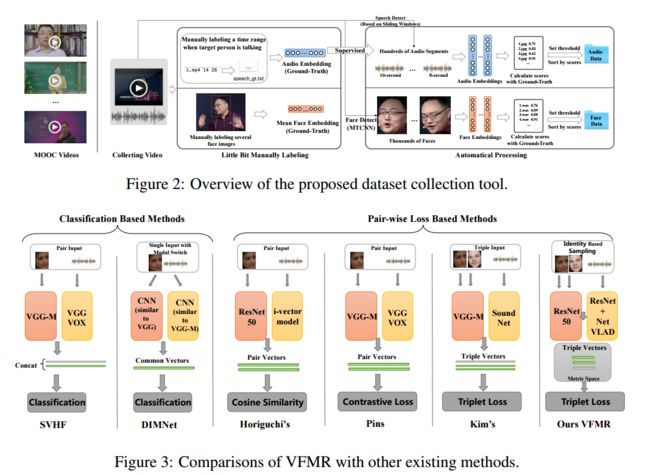
人脸和声音的相关检索方法, 通过声音来检索对应的人脸,包括声音人脸匹配和声音人脸检索。(from 人民大学)
通过卫星图像识别受损建筑,包括了一系列自然灾害后的卫星数据集可以从表格中查看 (from CMU)

code:https://github.com/DIUx-xView/xview2-baseline/
眼部识别数据库和应用综述, (from Federal University of Parana, Curitiba, Brazil)
文章中的表格总结了一系列相关数据集和方法,可以进一步查阅:


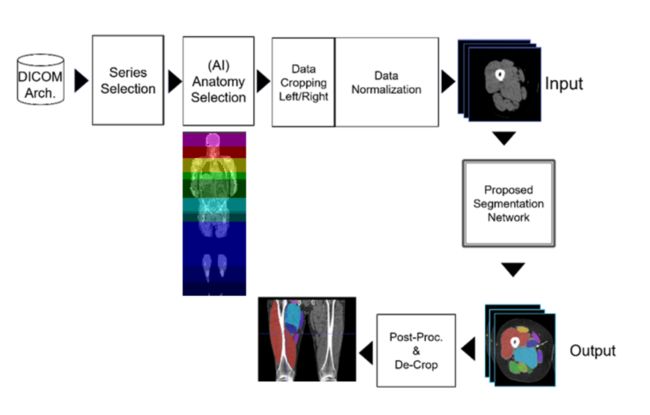
腿部肌肉横截面的语义分割, (from GE 医疗)


Daily Computer Vision Papers
| Adversarial Examples Improve Image Recognition Authors Cihang Xie, Mingxing Tan, Boqing Gong, Jiang Wang, Alan Yuille, Quoc V. Le 对抗性示例通常被视为对ConvNets的威胁。在这里,我们提出了一个相反的观点对抗性示例,如果以正确的方式加以利用,可以用来改进图像识别模型。我们建议使用AdvProp,这是一种增强型对抗训练方案,可以将对抗性示例作为其他示例,以防止过度拟合。我们的方法的关键是针对对抗性示例使用单独的辅助批处理规范,因为它们与常规示例具有不同的基础分布。 |
| AdaFilter: Adaptive Filter Fine-tuning for Deep Transfer Learning Authors Yunhui Guo, Yandong Li, Liqiang Wang, Tajana Rosing 训练有素的深度神经网络模型越来越多。但是,仍不清楚如何有效地将这些模型用于新任务。转移学习旨在将知识从源任务转移到目标任务,是解决此问题的有效方法。精调是用于深度神经网络的一种流行的转移学习技术,其中对预训练模型的参数进行几轮训练,以使其适应新任务。尽管它很受欢迎,但在本文中,我们显示出微调存在几个缺点。我们提出了一种称为AdaFilter的自适应微调方法,该方法仅选择经过预训练的模型中的卷积滤波器的一部分,以根据每个示例进行优化。我们使用循环门控网络根据前一层的激活选择性地微调卷积滤波器。我们对7个公共图像分类数据集进行了实验,结果表明,AdaFilter可以将标准微调的平均分类误差降低2.54。 |
| Unsupervised Domain Adaptation by Optical Flow Augmentation in Semantic Segmentation Authors Oluwafemi Azeez 生成现实生活中的图像标签非常昂贵,并且现实生活中的图像与模拟图像之间存在领域差距,因此在后者上训练的模型无法适应前者。解决此问题可以完全消除完全标记现实生活数据集的需要。类均衡的自我训练是尝试减小领域差距的现有技术之一。此外,使用流图增强RGB在简单的语义分割中具有改进的性能,并且跨域保留了几何形状。因此,通过用密集的光流图来增强图像,可以改善语义分割中的域自适应。 |
| Learning to Localize Sound Sources in Visual Scenes: Analysis and Applications Authors Arda Senocak, Tae Hyun Oh, Junsik Kim, Ming Hsuan Yang, In So Kweon 视觉事件通常在我们的日常生活中伴随着声音。但是,这些机器能否仅通过像人类一样观察来学习视觉场景和声音之间的关联以及对声源进行定位?为了研究其经验可学习性,在本文中,我们首先提出一种新颖的无监督算法,以解决声音定位问题视觉场景中的资源。为了实现这一目标,开发了一种利用注意力机制处理每个模式的两流网络结构,用于声源定位。网络自然显示场景中的本地化响应,而无需人工注释。此外,还开发了一个新的声源数据集用于性能评估。但是,我们的经验评估表明,在某些情况下,无监督方法会得出错误的结论。因此,我们表明,由于众所周知的相关性和因果不匹配误解,如果没有人类先验知识就无法解决这个错误的结论。为解决此问题,由于两流网络的一般体系结构,我们可以通过简单的修改将网络扩展到受监管的和半监管的网络设置。我们表明,即使有少量监督(即半监督设置)也可以有效纠正错误结论。此外,我们展示了学习的音频和视觉嵌入在交叉模式内容对齐方面的多功能性,并将该算法扩展到了一个新的应用中,即基于声效的360度视频中基于摄像机显像的自动平移。 |
| Ocular Recognition Databases and Competitions: A Survey Authors Luiz A. Zanlorensi, Rayson Laroca, Eduardo Luz, Alceu S. Britto Jr., Luiz S. Oliveira, David Menotti 虹膜和眼周区域作为生物特征的用途已得到广泛研究,这主要是由于虹膜特征的奇异性以及当图像分辨率不足以提取虹膜信息时眼周区域的使用。除了提供有关个人身份的信息之外,还可以探索从这些特征中提取的特征,以获得其他信息,例如个人性别,吸毒的影响,隐形眼镜的使用,欺骗等。这项工作对为眼识别而创建的数据库进行了调查,详细介绍了它们的协议以及如何获取它们的图像。我们还将描述和讨论最流行的眼识别竞赛,重点介绍提交的算法,该算法仅使用虹膜特征并融合虹膜和眼周区域信息即可达到最佳效果。最后,我们描述了将深度学习技术应用于眼识别的一些相关作品,并指出了新的挑战和未来的方向。考虑到存在大量的眼科数据库,并且每个数据库通常都是针对特定问题而设计的,因此我们认为这项调查可以对眼科生物识别技术的挑战提供广泛的概述。 |
| Synthesizing Visual Illusions Using Generative Adversarial Networks Authors Alexander Gomez Villa, Adrian Mart n, Javier Vazquez Corral, Jes s Malo, Marcelo Bertalm o 视觉幻觉对于视觉科学家来说是非常有用的工具,因为它们使他们能够更好地探查视觉系统的极限,阈值和错误。在这项工作中,我们介绍了第一个使用人工神经网络ANN生成新颖视觉幻觉的框架。它采用生成对抗网络的形式,具有视觉幻觉生成器和两个区分模块,一个用于诱导者背景,另一个用于确定候选者是否确实是一个幻觉。该模型的一般性可以通过合成不同类型的错觉来说明,并通过心理物理实验进行验证,这些实验证实了我们的人工神经网络的输出确实是人类观察者的视觉错觉。除了合成可能有助于视觉研究人员的新视觉幻觉之外,所提出的模型还具有开辟新方法来研究人工神经网络与人类视觉感知之间异同的潜力。 |
| Knowledge Graph Transfer Network for Few-Shot Recognition Authors Riquan Chen, Tianshui Chen, Xiaolu Hui, Hefeng Wu, Guanbin Li, Liang Lin 很少有镜头学习旨在从很少的样本中学习新颖的类别,给定一些基本类别并具有足够的训练样本。这项任务的主要挑战是,新颖的类别容易受对象的颜色,纹理,形状或背景背景即特异性支配,这在给定的少数训练样本中是不同的,但在相应类别中并不常见,请参见图1。幸运的是,我们发现传递相关的基于类别的信息可以帮助学习新颖的概念,从而避免新颖性概念被特异性支配。此外,在不同类别之间合并语义相关性可以有效地规范此信息传递。在这项工作中,我们以结构化知识图的形式表示语义相关性,并将该图集成到深度神经网络中,以通过新颖的知识图转移网络KGTN促进少量镜头学习。具体地,通过用对应类别的分类器权重初始化每个节点,学习传播机制以通过图自适应地传播节点消息,以探索节点交互并将基本类别的分类器信息转移到新类别的分类器信息。与目前的领先竞争对手相比,在ImageNet数据集上进行的广泛实验显示出显着的性能改进。此外,我们构建了一个涵盖较大规模类别(即6,000个类别)的ImageNet 6K数据集,并且对该数据集进行的实验进一步证明了我们提出的模型的有效性。 |
| All You Need Is Boundary: Toward Arbitrary-Shaped Text Spotting Authors Hao Wang, Pu Lu, Hui Zhang, Mingkun Yang, Xiang Bai, Yongchao Xu, Mengchao He, Yongpan Wang, Wenyu Liu 近来,旨在同时从混乱图像中检测和识别文本的端到端文本点播在计算机视觉中引起了越来越多的兴趣。与将文本检测描述为边界框提取或实例分割的现有方法不同,我们在每个文本实例的边界上定位一组点。通过这些边界点的表示,我们建立了一个简单而有效的方案来端到端识别文本,可以读取任意形状的文本。在包括ICDAR2015,TotalText和COCO Text在内的三个具有挑战性的数据集上进行的实验表明,该方法在场景文本检测和端到端文本识别任务方面始终领先于最新技术。 |
| Learning Spatial Fusion for Single-Shot Object Detection Authors Songtao Liu, Di Huang, Yunhong Wang 金字塔形特征表示法是解决对象检测中尺度变化挑战的常用方法。然而,对于基于特征金字塔的单发检测器而言,不同特征尺度之间的不一致是主要限制。在这项工作中,我们提出了一种新颖的数据驱动的金字塔特征融合策略,称为自适应空间特征融合ASFF。它学习了空间过滤冲突信息以抑制不一致性的方法,从而改善了特征的尺度不变性,并引入了几乎免费的推理开销。借助ASFF策略和可靠的YOLOv3基线,我们在MS COCO数据集上实现了最佳的速度精度折衷,在60 FPS时报告了38.1 AP,在45 FPS时报告了42.4 AP,在29 FPS时报告了43.9 AP。该代码位于 |
| Quantization Networks Authors Jiwei Yang, Xu Shen, Jun Xing, Xinmei Tian, Houqiang Li, Bing Deng, Jianqiang Huang, Xiansheng Hua 尽管深度神经网络非常有效,但其高昂的计算和存储成本严重挑战了其在便携式设备上的应用。结果,将全精度神经网络转换为低位宽整数版本的低位量化一直是活跃而有前途的研究主题。现有方法将网络的低位量化公式化为近似或优化问题。基于近似的方法面临梯度失配问题,而基于优化的方法仅适用于量化权重,并且可能在训练阶段引入较高的计算成本。在本文中,我们提出了一种新的观点,即通过将低位量化公式化为可量化的非线性函数称为量化函数,来解释和实现神经网络量化。可以以无损且端到端的方式学习所提出的量化函数,并以简单统一的方式对神经网络的任何权重和激活进行工作。在图像分类和目标检测任务方面的大量实验表明,我们的量化网络优于现有方法。我们相信,提出的方法将为神经网络量化的解释提供新的见识。我们的代码位于 |
| Heuristic Black-box Adversarial Attacks on Video Recognition Models Authors Zhipeng Wei, Jingjing Chen, Xingxing Wei, Linxi Jiang, Tat Seng Chua, Fengfeng Zhou, Yu Gang Jiang 我们研究了在黑盒设置中攻击视频识别模型的问题,其中模型信息未知,对手只能进行查询以检测预测的前1类及其概率。与对图像的黑匣子攻击相比,攻击视频更具挑战性,因为视频的高维性使搜索视频中的对抗性扰动的计算成本高得多。为了克服这一挑战,我们提出了一种启发式黑匣子攻击模型,该模型仅在选定的帧和区域上产生对抗性扰动。更具体地说,提出了一种基于启发式的算法来测量视频中每个帧对生成对抗性示例的重要性。基于帧的重要性,所提出的算法启发式搜索帧的子集,其中所生成的对抗示例具有较强的对抗攻击能力,同时保持摄动低于给定范围。此外,为了进一步提高攻击效率,我们建议仅在所选帧的显着区域上生成扰动。以这种方式,所产生的扰动在时间和空间域上都是稀疏的。对UCF 101数据集和HMDB 51数据集攻击两种主流视频识别方法的实验结果表明,所提出的启发式黑盒对抗攻击方法可以显着降低计算成本,并导致针对非目标攻击的查询数量减少28多个两个数据集。 |
| TEINet: Towards an Efficient Architecture for Video Recognition Authors Zhaoyang Liu, Donghao Luo, Yabiao Wang, Limin Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, Tong Lu 效率是设计用于动作识别的视频体系结构中的重要问题。 3D CNN见证了从视频进行动作识别方面的显着进步。但是,与2D卷积相比,3D卷积经常引入大量参数,并导致高计算量。为了缓解这个问题,我们提出了一个有效的时间模块,称为时间增强和交互TEI模块,可以将其插入由TEINet表示的现有2D CNN中。 TEI模块通过解耦通道相关性和时间交互的建模,提供了一种学习时间特征的不同范例。首先,它包含运动增强模块MEM,该模块将增强运动相关的功能,同时抑制无关的信息(例如背景)。然后,它引入了一个时间交互模块TIM,以通道方式补充了时间上下文信息。这两个阶段的建模方案不仅能够灵活有效地捕获时间结构,而且对于模型推断也是有效的。我们进行了广泛的实验以验证TEINet在几个基准上的有效性,例如Something Something V1 V2,Kinetics,UCF101和HMDB51。我们提出的TEINet可以在这些数据集上实现良好的识别精度,但仍然保持较高的效率。 |
| MSD: Multi-Self-Distillation Learning via Multi-classifiers within Deep Neural Networks Authors Yunteng Luan, Hanyu Zhao, Zhi Yang, Yafei Dai 随着神经网络的发展,越来越多的深度神经网络被用于各种任务中,例如图像分类。但是,由于巨大的计算开销,这些网络无法应用于移动设备或其他低延迟场景。为了解决这个难题,提出了多出口卷积网络以允许通过早期出口使用相应的分类器进行更快的推断。这些网络利用复杂的设计来提高提前退出的准确性。但是,幼稚地训练多出口网络可能会损害深度神经网络的性能准确性,因为早期出口分类器始终会干扰特征生成过程。 |
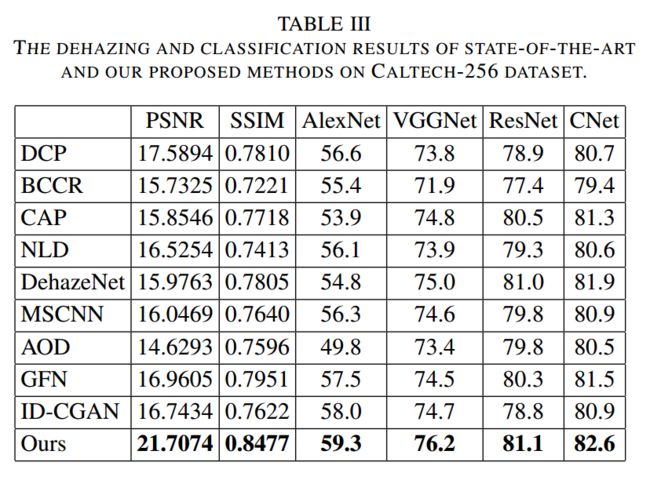
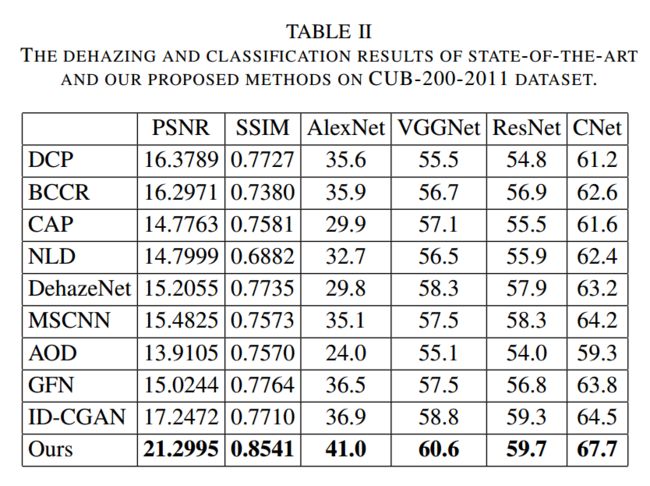
| Classification-driven Single Image Dehazing Authors Yanting Pei, Yaping Huang, Xingyuan Zhang 大多数现有的除雾算法通常使用手工特征或基于卷积神经网络CNN的方法来使用像素级均方误差MSE损失生成清晰的图像。所生成的图像通常具有更好的视觉吸引力,但对于高水平的视觉任务(例如:图像分类。在本文中,我们研究了解决此问题的新观点。我们不仅要确保仅在基于像素的度量标准(例如峰值信噪比PSNR)上实现良好的定量性能,还应确保已解模糊的图像本身不会降低诸如图像分类之类的高级视觉任务的性能。为此,我们提出了一个统一的CNN架构,该架构包括三个部分:除雾子网DNet,分类驱动的条件生成对抗网络子网CCGAN和与图像分类相关的分类子网CNet,在视觉吸引力和图像分类。我们对两个具有挑战性的细粒度和对象分类CUB 200 2011和Caltech 256的基准数据集进行了全面的实验。实验结果表明,在图像除雾指标和分类精度方面,该方法优于许多最新的单一图像除雾方法。 |
| ChartNet: Visual Reasoning over Statistical Charts using MAC-Networks Authors Monika Sharma, Shikha Gupta, Arindam Chowdhury, Lovekesh Vig 尽管通过深度学习实现了感知准确性的改善,但是将精确的视觉感知与推理能力结合在一起的开发系统仍然极具挑战性。从可访问性的角度来看,特定的应用领域是基于统计图(如条形图和饼图)进行推理的领域。为此,我们使用MAC网络将统计图上的推理问题公式化为分类任务,以从通用答案的预定义词汇表中给出答案。此外,我们通过用回归层代替分类层来定位图像上存在的文本答案,从而增强了MAC网络的能力,从而为图表提供了开放式问题的特定答案。我们称其为ChartNet网络,并证明其在预测词汇量和词汇答案之外的功效。为了测试我们的方法,我们生成了我们自己的统计图图像数据集和相应的问题答案对。结果表明,在对这些问题进行推理时,ChartNet始终优于其他最新技术,并且可能是包含统计图表图像的应用程序的可行候选人。 |
| Gliding vertex on the horizontal bounding box for multi-oriented object detection Authors Yongchao Xu, Mingtao Fu, Qimeng Wang, Yukang Wang, Kai Chen, Gui Song Xia, Xiang Bai 目标检测近来已取得实质性进展。然而,广泛采用的水平边界框表示不适用于无处不在的面向对象,例如航空图像和场景文本中的对象。在本文中,我们提出了一个简单而有效的框架来检测多方位的对象。我们没有直接使四个顶点回归,而是在每个对应的侧面上滑动水平边界框的顶点,以准确地描述多方位的对象。具体来说,我们回归了四个长度比,以表征每个相对侧的相对滑动偏移。这可以促进偏移学习并且避免定向对象的顺序标签点的混乱问题。为了进一步解决几乎水平物体的混乱问题,我们还基于物体与其水平边界框之间的面积比引入了一个倾斜因子,指导每个物体的水平或定向检测的选择。我们将这五个额外的目标变量添加到快速R CNN的回归头中,这需要可忽略的额外计算时间。大量的实验结果表明,该方法在没有花哨的情况下,在多个多方向物体检测基准上均具有优异的性能,包括航空图像中的物体检测,场景文本检测,鱼眼图像中的行人检测。 |
| An End-to-End Audio Classification System based on Raw Waveforms and Mix-Training Strategy Authors Jiaxu Chen, Jing Hao, Kai Chen, Di Xie, Shicai Yang, Shiliang Pu 音频分类可以区分不同的声音,这对于日常生活中的智能应用很有帮助。但是,这仍然是一项艰巨的任务,因为音频剪辑中的声音事件可能是多个甚至重叠的。本文介绍了一种基于原始波形和混合训练策略的端到端音频分类系统。与已在现有研究中广泛使用的人工设计功能相比,原始波形包含更完整的信息,并且更适合于多标签分类。以原始波形为输入,我们的网络由ResNet结构的两个变体组成,可以学习判别式表示。为了探索中间层中的信息,在我们的模型中应用了具有注意力结构的多级预测。此外,我们设计了一种混合训练策略,以打破由训练数据量引起的性能限制。实验表明,该音频分类系统在音频集数据集上的平均精度为37.2。在不使用额外训练数据的情况下,我们的系统超出了最新的多层次注意模型。 |
| Empirical Autopsy of Deep Video Captioning Frameworks Authors Nayyer Aafaq, Naveed Akhtar, Wei Liu, Ajmal Mian 基于当代深度学习的视频字幕遵循编码器-解码器框架。在编码器中,使用2D 3D卷积神经网络CNN提取视觉特征,并将这些特征的转换版本传递给解码器。解码器使用单词嵌入和语言模型将视觉功能映射到自然语言字幕。由于其复合特性,编码器解码器管道为其每个组件提供了多种选择的自由度,例如CNN模型,特征转换,单词嵌入和语言模型等的选择。组件选择会对整个视频产生巨大影响字幕性能。但是,当前的文献对此没有任何系统的研究。本文通过对每个主要组件在当代视频字幕制作流程中所起的作用进行了首次全面的实证分析,从而填补了这一空白。我们通过改变视频字幕框架的组成部分来进行广泛的实验,并量化仅通过选择组件就可以实现的性能提升。我们使用流行的MSVD数据集作为测试平台,并证明在不对管道本身进行重大更改的情况下,通过仔细选择组成组件可以显着提高性能。这些结果有望为视频字幕快速发展的方向提供指导,为将来的研究提供指导。 |
| Voice-Face Cross-modal Matching and Retrieval: A Benchmark Authors Chuyuan Xiong, Deyuan Zhang, Tao Liu, Xiaoyong Du 可以从算法上学习人的声音和面部之间的交叉模式关联,这可以使很多应用受益。该问题可以定义为语音面部匹配和检索任务。最近,在这些任务上已经引起了很多研究关注。但是,这项研究仍处于早期阶段。基于随机元组挖掘的测试方案往往具有较低的测试置信度。小规模数据集无法评估模型的泛化能力。各种任务的绩效指标很少。需要为此问题建立基准。本文首先提出了一个基于综合研究的框架,用于语音人脸匹配和检索。它通过针对不同任务的各种性能指标以及对大型数据集的高测试置信度来实现最先进的性能,可以将其用作后续研究的基准。在此框架中,提出了语音锚定的L2范数约束度量空间,并使用基于CNN的网络和度量空间中的三重态损失学习了交叉模态嵌入。使用这种策略,嵌入学习过程可以更加有效。还分析了框架的不同网络结构和模型的跨语言传输能力。其次,构建了具有来自中国人的115万张面部数据和0.29M音频数据的语音面部数据集,并开发了一种方便且质量可控的数据集收集工具。本文的数据集和源代码将与本文一起发布。 |
| LCD: Learned Cross-Domain Descriptors for 2D-3D Matching Authors Quang Hieu Pham, Mikaela Angelina Uy, Binh Son Hua, Duc Thanh Nguyen, Gemma Roig, Sai Kit Yeung 在这项工作中,我们提出了一种新颖的方法来学习2D图像和3D点云匹配的本地跨域描述符。我们提出的方法是一个双自动编码器神经网络,它将2D和3D输入映射到共享的潜在空间表示中。我们显示,与从2D和3D域中的单个训练中获得的那些相比,共享嵌入中的此类本地跨域描述符更具区分性。为了促进培训过程,我们通过从公开可用的RGB D场景中收集了约140万个2D 3D对应关系,其中包含各种照明条件和设置,从而建立了一个新的数据集。我们的描述符是在3D主要实验中进行评估的:2D 3D匹配,跨域检索以及稀疏到密集深度估计。实验结果证实了我们的方法的鲁棒性及其竞争优势,不仅在解决跨域任务方面,而且在能够泛化解决唯一的2D和3D任务方面。我们的数据集和代码在url上公开发布 |
| Simultaneous Implementation Features Extraction and Recognition Using C3D Network for WiFi-based Human Activity Recognition Authors Liu Yafeng, Chen Tian, Liu Zhongyu, Zhang Lei, Hu Yanjun, Ding Enjie 人们对行为的认识引起了越来越多的关注。已经开发了许多技术来表达人类行为的特征,例如图像,基于骨骼的信息和信道状态信息CSI。其中,由于CSI易于安装且对光线的要求不高,因此在某些特殊场合受到了越来越多的关注。但是,CSI信号与人为行为之间的关系非常复杂,必须做一些初步的工作才能使CSI功能易于计算机理解。如今,许多工作已从基于CSI的功能动作分解为两个部分。一部分用于特征提取和降维,另一部分用于时间序列问题。他们中的一些人甚至省略了这两个部分的工作之一。因此,当前的识别系统的准确性远远不能令人满意。在本文中,我们提出了一种新的基于深度学习的方法,即C3D网络和具有注意力机制的C3D网络,用于使用CSI信号进行人体动作识别。这种网络可以同时从空间卷积和时间卷积中提取特征,并且通过该网络可以同时实现上述基于CSI的人类动作识别的两个部分。整个算法结构得到简化。实验结果表明,与某些基准方法相比,我们提出的C3D网络能够对所有活动实现最佳识别性能。 |
| Relation Network for Person Re-identification Authors Hyunjong Park, Bumsub Ham 人员重新识别reID旨在从通常由多个摄像机捕获的一组图像中检索感兴趣的人的图像。最近的reID方法表明,即使在缺少身体部位的情况下,利用描述身体部位的局部特征以及人像本身的全局特征也可以提供可靠的特征表示。但是,不考虑身体部位之间的关系而直接使用各个部位级别的特征,会使在相应部位具有相似属性的不同人的区分身份变得混乱。为了解决这个问题,我们为人reID提出了一个新的关系网络,该网络考虑了各个身体部位与其余部位之间的关系。我们的模型使单个零件级别特征也合并了其他身体部位的部分信息,从而使其更具区分性。我们还介绍了一种全局对比池GCP方法,以获得人像的全局特征。我们建议对GCP使用对比功能,以补充常规的最大和平均合并技术。我们证明了我们的模型在Market1501,DukeMTMC reID和CUHK03数据集上的表现优于最新技术,证明了我们的方法在区分人物表示上的有效性。 |
| Image Aesthetics Assessment using Multi Channel Convolutional Neural Networks Authors Nishi Doshi, Gitam Shikhenawis, Suman K Mitra 图像美学评估是研究的新兴领域之一。域根据图像对用户观看的愉悦度的基础将图像分类为类别。在本文中,重点是将图像分为高质量图像和低质量图像。深度卷积神经网络用于对图像进行分类。代替仅使用原始图像作为输入,还使用图像的不同作物和显着性图作为所提出的多通道CNN体系结构的输入。在广泛使用的AVA数据库上报告的实验表明,与现有方法相比,美学评估性能有所提高。 |
| Furnishing Your Room by What You See: An End-to-End Furniture Set Retrieval Framework with Rich Annotated Benchmark Dataset Authors Bingyuan Liu, Jiantao Zhang, Xiaoting Zhang, Wei Zhang, Chuanhui Yu, Yuan Zhou 了解室内场景已引起计算机视觉界的极大兴趣。但是,很少有作品专注于对场景中家具的理解,并且也缺乏大规模的数据集来推动这一领域的发展。在本文中,我们首先通过呈现DeepFurniture来填补空白,DeepFurniture是一个注释丰富的大型室内场景数据集,包括24k室内图像,170k家具实例和20k唯一家具标识。在数据集上,我们引入了一个新的基准,即家具集检索。给定室内照片作为输入,该任务需要检测所有家具实例并搜索匹配的一组家具标识。为了解决这一艰巨的任务,我们提出了一个基于功能和上下文嵌入的框架。它包含3个主要贡献:1引入了带有附加基于蒙版的分类器的改进蒙版RCNN模型,以更好地利用蒙版信息来缓解家具检测环境中的遮挡问题。 2提出了一种多任务样式的暹罗网络来训练特征嵌入模型以进行检索,该模型由一个由自聚类伪属性监督的分类子网和一个用于估计输入对是否匹配的验证子网组成。 3为了在室内设计中建模家具实体之间的关系,采用上下文嵌入模型对检索结果进行重新排序。广泛的实验证明了每个模块和整个系统的有效性。 |
| xBD: A Dataset for Assessing Building Damage from Satellite Imagery Authors Ritwik Gupta, Richard Hosfelt, Sandra Sajeev, Nirav Patel, Bryce Goodman, Jigar Doshi, Eric Heim, Howie Choset, Matthew Gaston 我们将介绍xBD,这是一个新的大规模数据集,可用于人道主义援助和灾难恢复研究的变更检测和建筑物损坏评估的发展。自然灾害响应需要对受灾地区受损建筑物的准确了解。当前的应对策略要求在灾难发生后24 48小时内亲自评估损失。利用航空影像结合计算机视觉算法来评估损害并减少对人类生命的潜在危险存在巨大的潜力。与多个灾难响应机构合作,xBD通过建筑物多边形,损坏级别的序号标签以及相应的卫星元数据,提供了各种灾难事件之前和之后的卫星图像。此外,数据集还包含边界框和针对诸如火,水和烟等环境因素的标签。 xBD是迄今为止最大的建筑物损坏评估数据集,包含45,362公里的图像上标2上的850,736个建筑物注释。 |
| Controversial stimuli: pitting neural networks against each other as models of human recognition Authors Tal Golan, Prashant C. Raju, Nikolaus Kriegeskorte 不同的科学理论可以做出类似的预测。要在理论之间进行判断,我们必须设计理论可以做出不同预测的实验。在这里,我们考虑将深度神经网络作为人类视觉识别模型进行比较的问题。为了有效地确定哪些模型可以更好地解释人类的反应,我们合成了有争议的刺激图像,其中不同的模型会产生不同的反应。我们测试了九种不同的模型,这些模型采用了不同的体系结构和识别算法,包括判别模型和生成模型,所有模型都经过训练可以识别MNIST数字图像集中的手写数字。我们合成了有争议的刺激,以最大程度地提高模型之间的分歧。人类受试者观察了数百个此类刺激,并判断了每个图像中每个手指出现的可能性。我们量化了每个模型预测人类判断的准确性。我们发现,学习每一类图像的分布的生成模型比学会直接从图像映射到标签的鉴别模型更好地预测了人为判断。表现最佳的模型是基于变分自动编码器的综合分析生成模型。但是,基于高斯核密度估计的更简单的生成模型的性能也优于每个判别模型。没有一个候选模型可以完全解释人类的反应。我们讨论有争议的刺激作为实验范式的优点和局限性,以及它们如何在对抗性示例上进行概括和改进,以探讨模型与人类感知之间的差异。 |
| Semantic Hierarchy Emerges in Deep Generative Representations for Scene Synthesis Authors Ceyuan Yang, Yujun Shen, Bolei Zhou 尽管生成对抗网络GAN在图像合成方面取得了成功,但对于在深层生成表示中学习到的网络以及如何由随机噪声构成照片逼真的图像,仍然缺乏足够的了解。在这项工作中,我们表明,高度结构化的语义层次结构作为变异因子出现,用于从最先进的GAN模型(如StyleGAN和BigGAN)的生成表示中合成场景。通过在不同的抽象级别上使用广泛的语义来探查分层表示,我们能够量化激活和输出图像中出现的语义之间的因果关系。这样的量化可以识别出GAN所学习到的人类可以理解的变异因素,以构成场景。定性和定量结果表明,由GAN使用分层智能代码学习的生成表示专门用于合成不同的层次语义,早期的层倾向于确定空间布局和配置,中间的层控制分类对象,后面的层最后渲染场景属性以及配色方案。识别出这样一组可操纵的潜在变化因子有助于语义场景的操纵。 |
| EnAET: Self-Trained Ensemble AutoEncoding Transformations for Semi-Supervised Learning Authors Xiao Wang, Daisuke Kihara, Jiebo Luo, Guo Jun Qi 深度神经网络已成功应用于许多实际应用中。但是,这些成功很大程度上依赖于大量标记数据,而这些数据的获取成本很高。最近,已经提出了自动编码转换AET和MixMatch并分别实现了无监督和半监督学习的最新技术成果。在本研究中,我们训练自动编码转换EnAET的集合,以通过对空间和非空间转换进行解码,基于嵌入表示从标记和未标记的数据中学习。这将EnAET与传统的半监督方法区分开来,后者侧重于通过未标记和已标记示例的不同模型来提高预测一致性和置信度。相比之下,我们建议探讨在一系列丰富的变革下,自我监督表征在半监督学习中的作用。在CIFAR 10,CIFAR 100,SVHN和STL10上的实验结果表明,所提出的EnAET在很大程度上优于现有的半监督方法。特别是,我们将提出的方法应用于极具挑战性的场景,每类仅包含10张图像,并表明EnAET在CIFAR 10上的错误率可以达到9.35,在SVHN上的错误率可以达到16.92。此外,与使用具有相同网络体系结构的所有标记数据的完全监督学习相比,EnAET可获得最佳结果。具有较小网络的CIFAR 10,CIFAR 100和SVHN的性能甚至比基于较大网络的监督学习方法的技术水平更具竞争力。我们还设置了一个新的性能记录,在CIFAR 10上的错误率为1.99,在STL10上的错误率为4.52。代码和实验记录在以下位置发布 |
| Consensus-based Optimization for 3D Human Pose Estimation in Camera Coordinates Authors Diogo C Luvizon, Hedi Tabia, David Picard 3D人体姿势估计通常被视为相对于根部关节估计3D姿势的任务。或者,在本文中,我们提出了一种在相机坐标系中的3D人体姿势估计方法,该方法允许2D带注释的数据和3D姿势的有效组合,以及直接的多视图综合。为此,我们将问题投射到了不同的角度,即在图像平面中以像素为单位预测3D姿势,并以毫米为单位估算绝对深度。基于此,我们提出了一种基于共识的优化算法,用于未经校准的图像的多视图预测,该算法需要单个单眼训练程序。我们的方法改进了众所周知的3D人体姿势数据集的最新技术,在最常见的基准测试中将预测误差降低了32。此外,我们还报告了绝对姿势位置误差的结果,单眼估计的平均误差为80mm,多视角的平均误差为51mm。 |
| Multi-Label Classification with Label Graph Superimposing Authors Ya Wang, Dongliang He, Fu Li, Xiang Long, Zhichao Zhou, Jinwen Ma, Shilei Wen 图片或视频始终包含多个对象或动作。由于深度学习技术的迅速发展,已经证明了多标签识别可以实现相当不错的性能。最近,利用图卷积网络GCN来提高多标签识别的性能。然而,标签相关建模的最佳方法是什么,以及如何借助标签系统意识来改善特征学习仍不清楚。在本文中,我们从以下两个方面提出一种标签图叠加框架,以改进为多标签识别而开发的常规GCN CNN框架。首先,通过将基于统计共现信息构建的标签图叠加到根据标签知识先验而构建的图中,对标签相关性进行建模,然后将多层图卷积应用于最终的叠加图上以进行标签嵌入抽象。其次,我们建议利用整个标签系统的嵌入来更好地学习表示。详细地,在浅层,中间层和深层添加GCN和CNN之间的横向连接,以将标签系统的信息注入到主干CNN中,以在特征学习过程中识别标签。在MS COCO和Charades数据集上进行了广泛的实验,表明我们提出的解决方案可以大大提高识别性能,并获得最新的识别性能。 |
| Unsupervised Object Segmentation with Explicit Localization Module Authors Weitang Liu, Lifeng Wei, James Sharpnack, John D. Owens 在本文中,我们提出了一种新颖的体系结构,该体系结构基于图像重建质量来迭代发现和分割场景的对象。与其他方法不同,我们的模型使用一个显式的定位模块,该模块基于每次迭代的像素级重建质量对场景的对象进行定位,其中较简单的对象往往在较早的迭代中会得到更好的重建,因此首先被分割出来。我们证明,我们的本地化模块可以提高细分质量,尤其是在具有挑战性的背景下。 |
| FLNet: Landmark Driven Fetching and Learning Network for Faithful Talking Facial Animation Synthesis Authors Kuangxiao Gu, Yuqian Zhou, Thomas Huang 会说话的人脸合成已在基于外观或基于扭曲的方法中得到广泛研究。以前的作品大多利用单张脸图像作为来源,并通过融合他人的面部特征来生成新颖的面部动画。但是,可能无法真实,稳定地合成可能隐藏在源图像中的某些眼睛或牙齿等面部区域。在本文中,我们提出了一种具有里程碑意义的两流网络,以生成忠实的面部表情动画,其中从多个源图像(而不是单个图像)创建,保存和传输更多面部细节。具体来说,我们提出了一个由学习和获取流组成的网络。提取子网直接学习从五个具有明显标志性意义的源图像集中地扭曲和融合面部区域,而学习管道则从训练面部空间渲染面部器官以进行补偿。与基线算法相比,大量实验表明,该方法在定量和定性方面均具有较高的性能。代码在 |
| REVAMP$^2$T: Real-time Edge Video Analytics for Multi-camera Privacy-aware Pedestrian Tracking Authors Christopher Neff, Mat as Mendieta, Shrey Mohan, Mohammadreza Baharani, Samuel Rogers, Hamed Tabkhi 本文介绍了REVAMP 2 T,用于多摄像机隐私感知的行人跟踪的实时边缘视频分析,它是基于分散式情境感知构建的用于隐私保护的端到端集成IoT系统。 REVAMP 2 T提出了新颖的算法和系统构造,以将深度学习和视频分析推向物联网设备(即摄像机)之后。在算法方面,REVAMP 2 T提出了一个统一的集成计算机视觉管道,用于跨多个摄像机的检测,重新识别和跟踪,而无需存储流数据。同时,它避免了面部识别,并在运行时基于行人的关键特征来跟踪和重新识别行人。在物联网系统方面,REVAMP 2 T提供了基础架构,以最大限度地利用边缘硬件,协调全球通信,并为分布式物联网网络提供系统范围的重新识别,而无需使用个人身份信息。对于结果和评估,本文还提出了一个新指标Accuracy cdot Efficiency,用于基于准确性,性能和功率效率对物联网系统进行实时视频分析的整体评估。 REVAMP 2 T比现有技术高出13倍之多。 |
| Object-Guided Instance Segmentation for Biological Images Authors Jingru Yi, Hui Tang, Pengxiang Wu, Bo Liu, Daniel J. Hoeppner, Dimitris N. Metaxas, Lianyi Han, Wei Fan 生物图像的实例分割对于研究对象的行为和属性至关重要。对象的聚类,遮挡和粘附问题等挑战使实例分割成为一项不平凡的任务。当前的无盒实例分割方法通常依赖于本地像素级别信息。由于缺乏全局对象视图,因此这些方法容易出现过度分割或分割不足的情况。相反,基于盒子的实例分割方法将对象检测合并到分割中,从而在识别各个实例中表现更好。在本文中,我们提出了一种新的基于盒子的实例分割方法。主要地,我们从它们的中心点定位对象边界框。随后,在分割分支中重用对象功能,作为在RoI修补程序中分离群集实例的指南。通过实例归一化,该模型能够恢复目标对象的分布并抑制相邻附加对象的分布。因此,在保留目标对象详细信息的同时,所提出的模型在分割聚类对象方面表现出色。所提出的方法在三个生物数据集的细胞核,植物表型数据集和神经细胞上达到了最先进的性能。 |
| Localized Compression: Applying Convolutional Neural Networks to Compressed Images Authors Christopher A. George, Bradley M. West 我们解决了将现有卷积神经网络CNN架构应用于压缩图像的挑战。现有的CNN架构将图像表示为具有指定尺寸的像素强度矩阵,该所需尺寸通过降级或裁剪来实现。降级和裁剪很吸引人,因为结果也是图像,但是,产生替代压缩表示的算法可以产生更好的分类性能。此压缩算法不必是可逆的,但必须与CNN的操作兼容。因此,此问题与将压缩的CNN应用于未压缩的图像的深入研究的问题相对应,当CNN部署到尺寸,重量和功率受限的SWaP设备时,这一问题引起了极大的兴趣。我们引入了局部压缩,即降级的一般化,其中将原始图像分为多个块,然后使用基于采样或基于随机矩阵的技术将每个块压缩为较小的大小。通过将压缩块的大小与CNN卷积区域的大小对齐,可以使局部压缩与任何CNN体系结构兼容。我们的实验结果表明,局部压缩比通过降级到等效分辨率所实现的分类精度高约1 2。 |
| Active Learning for Deep Detection Neural Networks Authors Hamed H. Aghdam, Abel Gonzalez Garcia, Joost van de Weijer, Antonio M. L pez 绘制对象边界框(即标记数百万个图像)的成本过高。例如,以常规的城市图像标记行人平均可能需要35秒。主动学习旨在通过仅选择能提高检测网络准确性的信息图像来降低标记成本。在本文中,我们提出了一种基于卷积神经网络进行目标检测器主动学习的方法。我们提出了一种新的图像级别评分流程,可以对未标记图像进行自动选择排名,这明显优于传统分数。所提出的方法可以应用于视频和静止图像集。在前一种情况下,时间选择规则可以补充我们的评分过程。作为一个相关的用例,我们广泛研究了我们的方法在行人检测任务中的性能。总体而言,实验表明,所提出的方法比随机选择方法具有更好的性能。我们的代码可在以下位置公开获得 |
| ID-aware Quality for Set-based Person Re-identification Authors Xinshao Wang, Elyor Kodirov, Yang Hua, Neil M. Robertson 基于集合的人员身份识别SReID是一个匹配问题,旨在验证两个集合是否具有相同的身份ID。现有的SReID模型通常会为每个图像生成一个特征表示,并将它们聚合起来以将其表示为单个嵌入。但是,由于不完善的跟踪检测系统或过分适合琐碎的图像,不可避免地会受到噪声,语义上低质量的图像的干扰。在这项工作中,我们提出了一个基于ID感知质量的新颖而简单的解决方案,该质量可测量由其ID信息指导的图像的感知和语义质量。具体来说,我们提出了一种ID感知嵌入,该嵌入由两个关键组件组成1特征学习注意,旨在通过专注于中等硬图像来学习鲁棒的图像嵌入。这样可以防止过度拟合到琐碎的图像,并减轻离群值的影响。 2特征融合的重点是融合图像嵌入在集合中以获得集合级嵌入。它忽略了嘈杂的信息,并更加注意区分图像以聚集更多区分信息。在四个数据集上的实验结果表明,尽管我们的方法简单,但其性能却优于最新方法。 |
| SINet: Extreme Lightweight Portrait Segmentation Networks with Spatial Squeeze Modules and Information Blocking Decoder Authors Hyojin Park, Lars Lowe Sj sund, Nicolas Monet, YoungJoon Yoo, Nojun Kwak 设计轻巧且健壮的人像分割算法是各种面部应用程序的重要任务。但是,该问题已被视为对象分割问题的子集,并且在语义分割字段中处理较少。显然,人像分割有其独特的要求。首先,由于人像分割是在许多现实应用程序的整个过程中进行的,因此需要极其轻巧的模型。其次,此域中没有任何公共数据集包含足够数量的具有无偏统计的图像。为了解决第一个问题,我们引入了新的极其轻量级的肖像分割模型SINet,其中包含一个信息阻止解码器和空间压缩模块。信息阻塞解码器使用置信度估计来恢复局部空间信息,而不会破坏全局一致性。空间压缩模块使用多个接收场来处理图像中各种大小的一致性。为了解决第二个问题,我们提出了一种简单的方法来创建其他人像分割数据,从而可以提高EG1800数据集的准确性。在对EG1800数据集的定性和定量分析中,我们证明了我们的方法优于各种现有的轻量级细分模型。我们的方法将参数数量从2.1M减少到86.9K,减少了95.9,同时保持了与现有肖像分割方法相比1的精度。我们还显示了我们的模型已在具有100.6 FPS的真实移动设备上成功执行。此外,我们证明了我们的方法可用于Cityscape数据集上的常规语义分割。该代码可在https github.com上找到。HYOJINPARK ExtPortraitSeg |
| Superpixel Soup: Monocular Dense 3D Reconstruction of a Complex Dynamic Scene Authors Suryansh Kumar, Yuchao Dai, Hongdong Li 这项工作解决了根据图像对复杂动态场景进行密集3D重建的任务。解决此任务的主要思想是由一系列步骤组成,并且取决于执行过程中多个管道的成功。为了克服现有算法的这种局限性,我们提出了一种统一的方法来解决这个问题。我们假设动态场景可以由许多分段的平面近似,其中每个平面都具有其自身的刚性运动,并且两个帧之间的场景全局变化尽可能地严格于ARAP。因此,我们的动态场景模型简化为平面结构和这些局部平面结构的刚性运动。使用场景的平面过度分割,我们将此任务简化为解决3D拼图难题。因此,该任务归结为正确组装每个刚性零件,以构造一个3D形状,该形状符合在ARAP假设下的场景几何形状。此外,我们表明,我们的方法为透视投影下的运动提供了一种有效的解决方案,以解决结构固有的尺度模糊性。我们提供了一些基准数据集的广泛实验结果和评估。与竞争方法的定量比较显示了最先进的性能。 |
| Third-Person Visual Imitation Learning via Decoupled Hierarchical Controller Authors Pratyusha Sharma, Deepak Pathak, Abhinav Gupta 我们研究了一种通用的设置,用于从演示中学习,以构建一个代理,该代理可以通过仅从第三人称视角观看人类演示的单个视频来在看不见的场景中操纵新对象。为了实现此目标,我们的代理商不仅应学会了解所展示的第三方视频在上下文中的意图,而且应在其环境配置中执行预期的任务。我们的中心见解是在学习过程中通过将实现目标的任务与如何执行控制器分离开来,明确地实施这种结构。我们提出了一种分层设置,其中高级模块学习以第三人称视频演示为条件的一系列第一人称子目标,而低级控制器则预测实现这些子目标的动作。我们的代理根据原始图像观察结果进行操作,而无需访问完整的状态信息。我们在使用Baxter的真实机器人平台上显示结果,以完成将物体倒入盒子中的操作任务。项目视频和代码在 |
| Single Image Super Resolution based on a Modified U-net with Mixed Gradient Loss Authors Zhengyang Lu, Ying Chen 单图像超分辨率SISR是从单个低分辨率图像推断出高分辨率图像的任务。由于计算机视觉领域中深度卷积神经网络的发展,超分辨率的最新研究取得了长足的进步。现有的超分辨率重建方法在均方误差MSE准则中具有较高的性能,但是大多数方法都无法重建具有形状边缘的图像。为了解决这个问题,提出了由MSE和加权平均梯度误差组成的混合梯度误差,并将其作为损失函数应用于改进的U网。修改后的U net删除每个块中的所有批处理归一化层和卷积层之一。该操作减少了参数数量,因此加快了重建速度。与现有的图像超分辨率算法相比,该重建方法具有更好的性能和时间消耗。实验表明,具有混合梯度损耗的改进型U网网络体系结构在三个图像数据集SET14,BSD300和ICDAR2003上产生了高水平的结果。代码可在线获得。 |
| Segmenting Medical MRI via Recurrent Decoding Cell Authors Ying Wen, Kai Xie, Lianghua He 编码器解码器网络由于其在层次特征融合中的出色表现而常用于医学图像分割。然而,用于特征解码和空间恢复的扩展路径在融合来自不同层的特征图时并未考虑长期依赖性,并且通用编码器解码器网络未充分利用多模态信息来提高网络鲁棒性,尤其是对于分段而言医学MRI。在本文中,我们提出了一种新颖的特征融合单元,称为递归解码单元RDC,该单元利用卷积RNN来存储解码阶段中来自先前各层的长期上下文信息。还提出了一种基于RDC的编码器解码器网络,称为卷积循环解码网络CRDN,用于分割多模态医学MRI。 CRDN采用CNN骨干对图像特征进行编码,并通过一系列RDC对其进行分层解码,以获得最终的高分辨率得分图。在BrainWeb,MRBrainS和HVSMR数据集上进行的评估实验表明,引入RDC可以有效提高分割精度并减小模型大小,并且所提出的CRDN具有医学MRI中对图像噪声和强度不均匀性的鲁棒性。 |
| Heart Segmentation From MRI Scans Using Convolutional Neural Network Authors Shakeel Muhammad Ibrahim, Muhammad Sohail Ibrahim, Muhammad Usman, Imran Naseem, Muhammad Moinuddin 心脏是人体的重要器官之一。即使在很短的时间间隔内,心脏的轻微功能障碍也可能致命,因此,有效监测其生理状态对于患有心血管疾病的患者至关重要。在最近的过去,已经提出了各种计算机辅助医学成像系统来分割感兴趣的器官。但是,对于使用MRI进行心脏分割,仅提出了几种方法各有各的优点和缺点。为了在这一研究领域的进一步发展,我们分析了磁共振图像的自动心脏分割方法。该分析基于深度学习方法,该方法以逐片的方式处理完整的MR扫描,以预测心脏区域所需的掩模。我们设计了两个编码器-解码器类型的全卷积神经网络模型 |
| Data Proxy Generation for Fast and Efficient Neural Architecture Search Authors Minje Park 由于神经结构搜索NAS的最新进展,它在为特定任务设计最佳网络方面广受欢迎。尽管在许多基准测试和竞赛中都显示出令人鼓舞的结果,但NAS在搜索高维体系结构设计空间时仍然受到苛刻的计算成本的困扰,而当我们要使用大规模数据集时,这个问题变得更加严重。如果我们能够为NAS提供可靠的数据代理,那么NAS方法的效率就会相应提高。我们制作数据代理的基本观察结果是,特定数据集中的每个示例对NAS流程都有不同的影响,并且从相对准确度排名的角度来看,大多数示例都是多余的,我们在制作数据代理时应保留这些示例。我们提出了一种系统的方法,从这种相对准确度排名的角度衡量每个示例的重要性,并根据训练和测试示例的统计数据制作可靠的数据代理。我们的实验表明,即使使用10到20倍的数据代理,我们仍可以保持所有可能的网络配置之间几乎相同的相对准确度排名。 |
| Large-scale Multi-view Subspace Clustering in Linear Time Authors Zhao Kang, Wangtao Zhou, Zhitong Zhao, Junming Shao, Meng Han, Zenglin Xu 在过去的几年中已经提出了许多多视图子空间聚类MVSC方法。研究人员设法从不同的角度提高聚类的准确性。然而,许多现有技术的MVSC算法通常具有二次或什至三次复杂度,效率低下并且固有地难以大规模应用。在大数据时代,计算问题变得至关重要。为了填补这一空白,我们提出了一种具有线性阶复杂度的大规模MVSC LMVSC算法。受到锚定图概念的启发,我们首先为每个视图学习一个较小的图。然后,设计一种新颖的方法来集成这些图,以便我们可以在较小的图上实现光谱聚类。有趣的是,事实证明我们的模型也适用于单视图场景。在各种大型基准数据集上进行的大量实验证明了我们的方法相对于最新的聚类方法的有效性和效率。 |
| Band-limited Training and Inference for Convolutional Neural Networks Authors Adam Dziedzic, John Paparrizos, Sanjay Krishnan, Aaron Elmore, Michael Franklin 卷积层是神经网络架构的核心构建块。通常,卷积滤波器适用于输入数据的整个频谱。我们在训练过程中人为地限制了这些滤波器和数据的频谱,称为频带限制。频域约束适用于前馈和反向传播步骤。在实验上,我们观察到卷积神经网络的CNN对此压缩方案具有弹性,结果表明CNN学会了利用低频分量。特别是,我们发现1个有限频带训练可以有效地控制资源使用GPU和内存2个有限频带训练的模型保留了较高的预测精度,而3个不需要修改现有的训练算法或神经网络体系结构即可使用,这与其他压缩方案不同。 |
| NaMemo: Enhancing Lecturers' Interpersonal Competence of Remembering Students' Names Authors Guang Jiang, Mengzhen Shi, Ying Su, Pengcheng An, Yunlong Wang 用学生的名字称呼学生可以帮助老师与学生建立融洽的关系,从而促进他们的课堂参与。但是,这种基本而有效的技能对于大学讲师而言尤其是亚洲大学中的讲师具有挑战性,他们在日常教学中不得不处理有时超过100组的大型活动。为了增强讲师与人之间互动的能力,我们开发了NaMemo,这是一种基于专用计算机视觉算法的实时名称指示系统。本文介绍了其设计和可行性研究,结果表明参与教师和学生的接受程度似乎合理。我们还向学生揭示了对滥用或滥用该系统(例如检查出勤率)的担忧。总之,我们讨论了设计中的机遇和风险,并详细说明了后续计划,深入实施,以进一步评估NaMemo对学与教的影响,并探讨包括隐私注意事项在内的设计含义。 |
| DeepLABNet: End-to-end Learning of Deep Radial Basis Networks with Fully Learnable Basis Functions Authors Andrew Hryniowski, Alexander Wong 从完全连接的神经网络到卷积神经网络,神经网络内的学习参数已主要降级为线性参数,例如卷积滤波器。非线性函数(例如激活函数)在很大程度上得以保留,近年来几乎没有例外,参数较少,整个训练过程都是静态的,并且设计变化有限。径向基函数RBF网络被深度学习社区广泛忽略,除了网络中的线性参数之外,它还提供了一种有趣的机制来学习更复杂的非线性激活函数。但是,由于难以将RBF以易于处理且稳定的方式集成到更复杂的深度神经网络架构中,因此对RBF网络的兴趣随着时间的流逝而减弱。在这项工作中,我们提出了一种新颖的方法,该方法能够以自动且易于处理的方式,通过具有完全可学习的激活基础功能的端到端学习深度RBF网络。我们证明了在深度神经网络中启用可学习的激活基础函数的方法(我们将其称为DeepLABNet)是在复杂网络体系结构中自动激活函数学习的有效工具。 |
| Semantic Segmentation of Thigh Muscle using 2.5D Deep Learning Network Trained with Limited Datasets Authors Hasnine Haque, Masahiro Hashimoto, Nozomu Uetake, Masahiro Jinzaki 目的我们提出了一个2.5D深度学习神经网络DLNN,以将大腿肌肉自动分类为11类,并在使用有限的数据集训练时评估其在2D和3D DLNN上的分类准确性。可以根据疾病进展对大腿肌肉体积变化进行操作员不变的定量评估。资料和方法回顾性数据集由从CT DICOM图像中裁剪出来的48个大腿电视组成。将裁剪后的体积与股骨轴对齐,并以2毫米体素间距重新采样。提议的2.5D DLNN由三个分别用轴向,冠状和矢状肌切片训练的2D U网组成。表决算法用于组合U Nets的输出以创建最终分段。 2.5D U Net在装有38台电视的PC上进行了培训,其余10台电视用于评估大腿内10个类别的分割精度。左大腿和右大腿的结果分割均被裁剪为原始CT体积空间。最后,比较了建议的DLNN和2D 3D U Net的分割精度。结果所有类别的平均分割DSC分数准确性为2.5D U Net为91.18,平均表面距离ASD准确性为0.84 mm。我们发现,在使用相同数据集训练时,2D U Net的平均DSC分数比2.5D U Net的平均分数低3.3,而3D U Net的DSC分数比2.5D U Net的平均DSC分数低2.5。结论我们以合理的准确度实现了大腿肌肉更快的计算效率和自动分割为11类的效果。能够随着疾病的进展定量评估肌肉萎缩。 |
| DR-KFD: A Differentiable Visual Metric for 3D Shape Reconstruction Authors Jiongchao Jin, Akshay Gadi Patil, Hao Richard Zhang 我们提倡使用差异视觉形状指标来训练用于3D重建的深度神经网络。我们引入了一种度量标准,该度量标准通过测量可从形状分别渲染的多视图图像之间的视觉图像空间差异来比较两个3D形状。此外,我们根据根据比较图像的概率关键点图计算出的Hard Net特征定义的均方误差,开发出可微分的图像空间距离。我们的差分视觉形状度量可以轻松插入各种重建网络中,从而取代对象空间畸变度量(例如倒角或地球移动距离),从而优化网络权重以产生具有更好的结构保真度和视觉质量的重建结果。我们使用独立于我们的新指标的众所周知的视觉形状指标进行检索和分类任务,并通过感知研究在主观上进行客观展示。 |
| RIS-GAN: Explore Residual and Illumination with Generative Adversarial Networks for Shadow Removal Authors Ling Zhang, Chengjiang Long, Xiaolong Zhang, Chunxia Xiao 残留图像和照度估计已被证明对图像增强非常有帮助。在本文中,我们提出了一个通用且新颖的框架RIS GAN,该框架使用创世对抗网络探索残差和光照以去除阴影。结合粗略阴影去除图像,可以使用估计的负残留图像和逆照明图来生成间接阴影去除图像,以将粗略阴影去除结果以粗略到精细的方式细化为细无阴影图像。设计了三个鉴别器,以与相应的地面真实信息相比较,共同区分预测的负残留图像,阴影去除图像和逆照明图是真实的还是伪造的。据我们所知,我们是第一个探索残留物和照明以去除阴影的人。我们在两个基准数据集(即SRD和ISTD)上评估了我们提出的方法,尽管我们的发生器中没有设计任何特别的阴影感知组件,但广泛的实验表明我们提出的方法可实现优于现有技术的性能。 |
| Feature Extraction in Augmented Reality Authors Jekishan K. Parmar, Ankit Desai 增强现实AR用于与现实世界相关的各种应用程序。本文首先描述了AR的特点和基本服务。简介部分还提到了有关虚拟现实VR和AR的简要历史。然后,描述了AR Technologies及其工作流程,其中包括完整的AR流程,包括图像采集,特征提取,特征匹配,几何验证和关联信息检索等阶段。特征提取是AR的本质,因此本文提供了其详细信息。 |
| AssemblyNet: A large ensemble of CNNs for 3D Whole Brain MRI Segmentation Authors Pierrick Coup , Boris Mansencal, Micha l Cl ment, R mi Giraud, Baudouin Denis de Senneville, Vinh Thong Ta, Vincent Lepetit, Jos V. Manjon 使用深度学习DL进行全脑分割是一项非常具有挑战性的任务,因为与可用的训练图像相比,解剖标记的数量非常多。为了解决这个问题,以前的DL方法提出使用单个卷积神经网络CNN或几个独立的CNN。在本文中,我们提出了一种基于大量CNN处理不同重叠大脑区域的新颖合奏方法。受议会决策系统的启发,我们提出了一个名为AssemblyNet的框架,该框架由两个U Nets程序集组成。这样的议会制度能够处理复杂的决定,看不见的问题并迅速达成共识。 AssemblyNet引入了相邻U网之间的知识共享,由第二个大会以更高的分辨率修改了程序,以完善第一个大会的决定,并通过多数表决获得了最终决定。在我们的验证过程中,AssemblyNet与诸如U Net,Joint标签融合和SLANT之类的最新方法相比,具有竞争优势。此外,我们研究了扫描重新扫描的一致性以及该方法对疾病影响的鲁棒性。这些经验证明了AssemblyNet的可靠性。最后,我们展示了使用半监督学习来改善我们方法的性能的兴趣。 |
| Data Augmentation Revisited: Rethinking the Distribution Gap between Clean and Augmented Data Authors Zhuoxun He, Lingxi Xie, Xin Chen, Ya Zhang, Yanfeng Wang, Qi Tian 数据增强已被广泛用作改善泛化的有效方法,尤其是在训练深度神经网络时。最近,研究人员提出了一些密集的数据增强技术,这些技术确实提高了准确性,但是我们注意到,这些方法增强数据还导致干净数据和增强数据之间存在相当大的差距。在本文中,我们从分析的角度重新审视了这个问题,为此,我们分别使用经验风险和广义误差这两个术语来估计预期风险的上限。我们对作为规则化的数据增强有了一定的了解,这突出了主要功能。结果,数据扩充显着降低了泛化误差,但同时导致了更高的经验风险。假设数据增强可以帮助模型收敛到一个更好的区域,则该模型可以受益于通过简单方法(即,使用较少的增强数据来精炼在完全增强的数据上训练的模型)实现的较低的经验风险。我们的方法在一些标准的图像分类基准上获得了一致的精度增益,并且该增益转移到了对象检测上。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com