【今日CV 计算机视觉论文速览 第108期】Tue, 30 Apr 2019
今日CS.CV 计算机视觉论文速览
Tue, 30 Apr 2019
Totally 91 papers
?上期速览✈更多精彩请移步主页

Interesting:
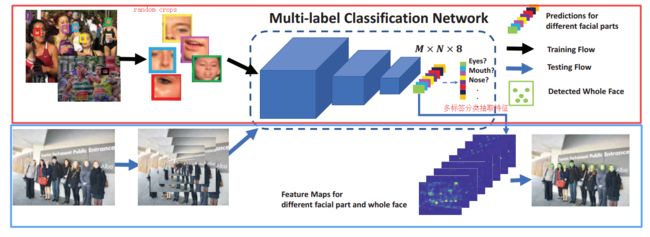
?scGAN自拍照片卡通风格化, 研究人员提出了一种将自拍卡通化的风格化方法。利用注意力对抗网络强调脸部特征并忽视低层次细节信息。首先通过cycle架构来训练非配对数据,随后利用三个不同了loss来训练。其中全局变化loss用于强化边缘和肖像的内容特征、注意力循环损失用于强调面部精细结构、感知损失用于消除人工痕迹提高鲁棒性。。(from 京东研究院)

模型架构:

不同方法的比较:

不同风格的结果:

dataset:cartoon portraits dataset包含了卡通、手绘、水彩图像。来自谷歌关键词搜索woman portrait3524
?***TextCohesion检测任意形状的文字, 这种方法包含了五个关键部分,文字骨架和4个方向像素区域。其中文字骨架用于粗略定出文字的位置、形状大小,随后从四个方向来精调文字的区域和边缘。随后还利用了置信度分数来提出想文字的其他符号。在Total-Text and SCUT-CTW1500 上分别实现了84.6 and 86.3 的准确率。(from 浙大)

文本骨架用于提出假阳性,方向性像素用于更鲁棒的文字抽取:
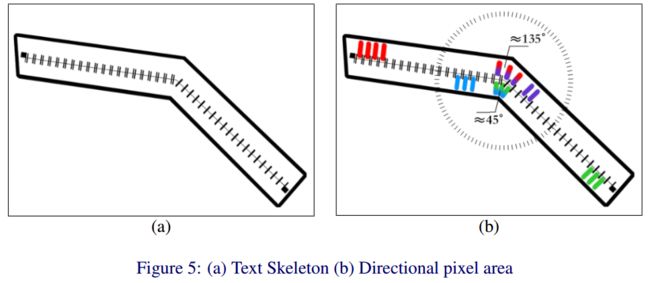
不同数据集(SynthText [6] CDAR2019 [23] TotalText [2] CTW1500 [43] )及结果:


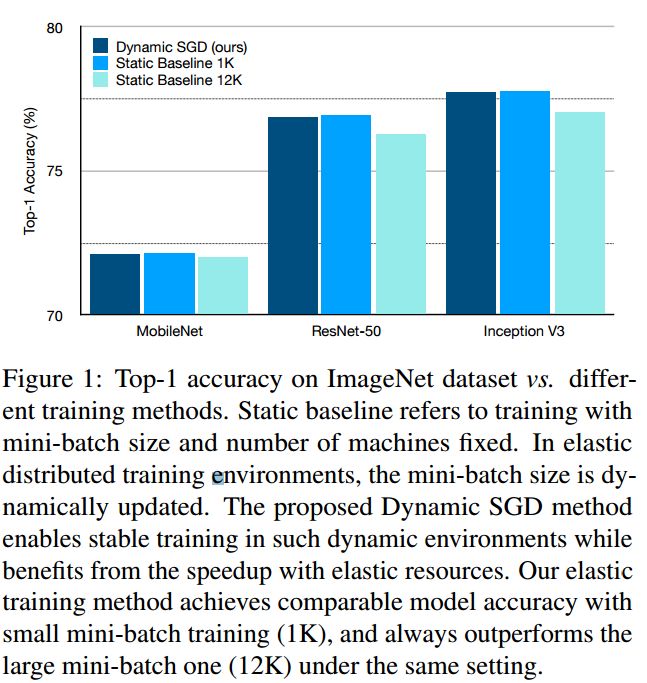
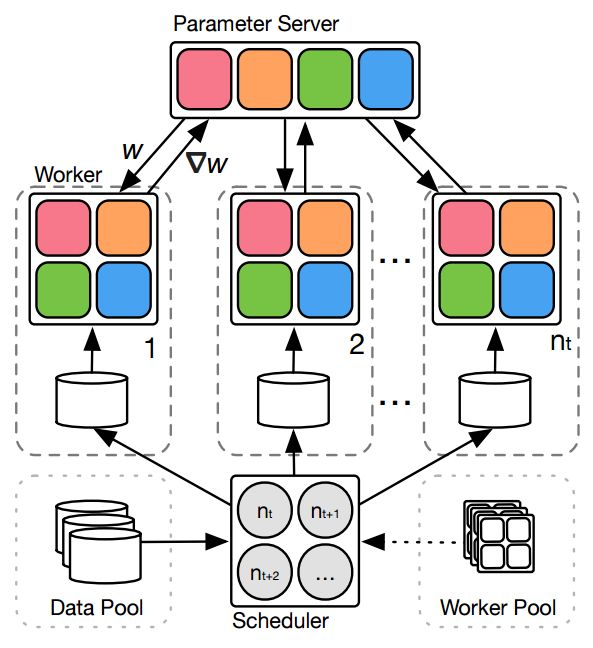
?用于弹性分布式计算的动态mini-batch SGD, 弹性分布式计算用于各种不同任务、不同需求的机器学习任务十分重要。但目前大规模minibatch用于弹性框架上会出现性能下降,主要来源于随机动量估计中的噪声随时间累计,并会在batchsize变化时出现之后效应。研究人员提出了随时间平滑调整学习率来减轻噪声动量估计的影响。这种动态SGD方法实现了从8GPUs到128GPUs稳定的表现。研究人员还提供了对于线性学习率优化和随机动量效应的理论分析。(from Amazon Web Services)
?移动端高速人脸识别, 研究人员观察到级联神经网络中最主要的瓶颈在于候选框提出阶段,所有图像金字塔都需要通过网络进行计算。所以研究人员通过全局和局部的特征来减小了图像金字塔的深度,从而实现了提速。(from 南加州大学 三星研究院)
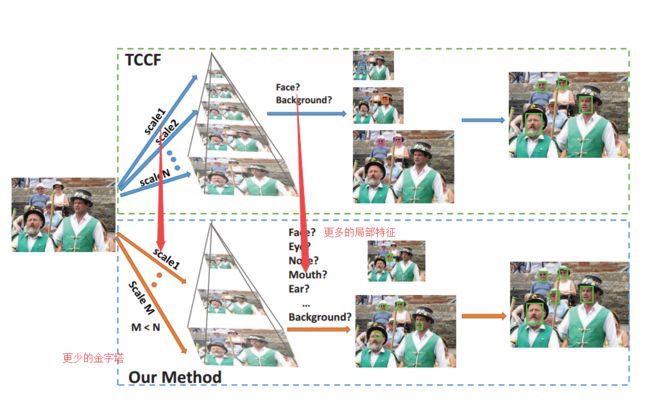
全局用于处理face,局部用于处理脸部特征并推测出脸的位置。
速度:三星S8的CPU 1280*720,最小人脸100,scaling factor 0.25----8~10fps.
dataset:WIDER-face and FDDB
?DADA-2000, 基于驾驶员的注意力构建了注意力和事故标注的数据集,包含了来自54种不同事故2000个视频段中658476帧,包括了不同场景 (highway, urban, rural, and tunnel), 不同天气(sunny, rainy and snowy) 不同光照(daytime and nighttime)。同时构建了驾驶员的扫视路径和撞击图,以预测事故发生的前兆。(from 长安大学)

数据集中的事故分类关系:
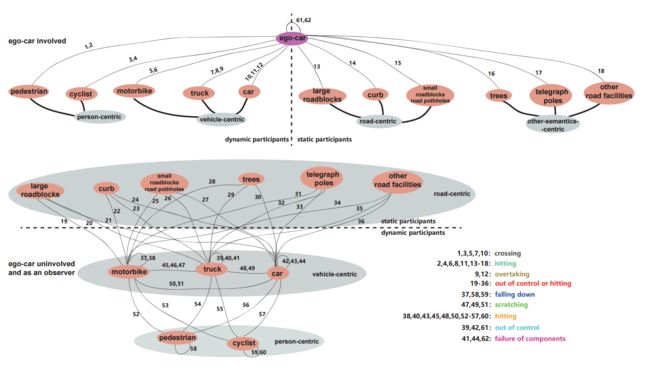
ref:DR(eye)VE project and newly emerged Berkeley DeepDrive Attention (BDD-A) database
?IsMo-GAN,基于对抗学习从二维图像进行三维非刚体重建, 通过光照、相机位姿和阴影实现250Hz的重建(from 凯泽斯劳滕大学 DFKI 马普信息研究所)
2D图像输入(前景分离)后生成点云,随后判别器进行表面正则化。下半部分显示了在纹理不同情况下实现的三维重建效果。

三个部分的网络模型:

一些结果:


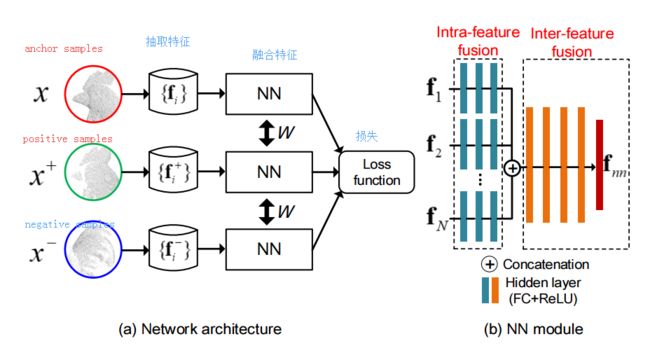
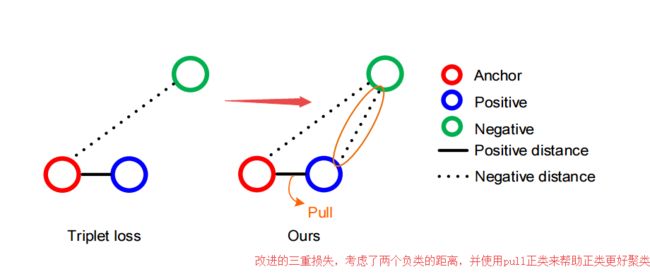
?**基于局部几何特征融合的三维刚体数据配准, 提出了一种同时融合低级和高级几何特征的3D刚体匹配方法。与先前利用线性操作不同的是,本文提出了更为紧致和具有可变性的表示,并可以通过神经网络在三重架构的欧式空间下进行优化。神经网络基于改进的三重损失函数进行训练,可以充分利用三重关系。这种描述子更为轻量化并具有旋转不变性。(from 华中科技)
模型架构和对应的NN模块结构如下:
损失示意图:
训练过程:

一些配准的结果:
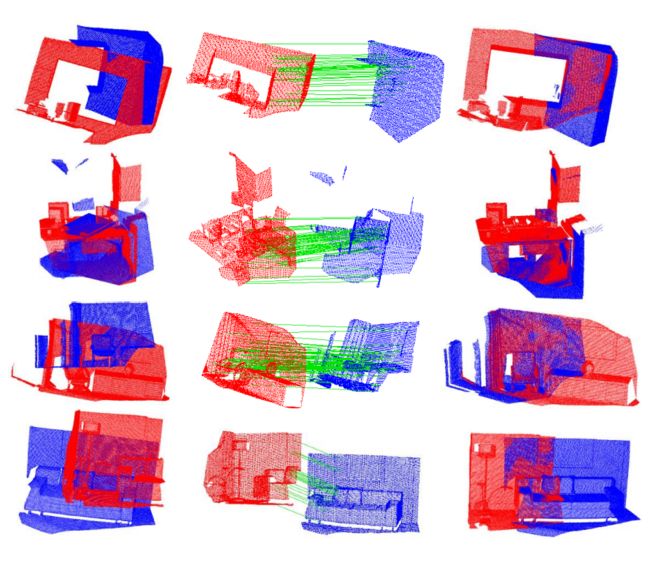
dataset:U3M [23],U3OR [52, 53],BMR [6].Aug ICL-NUIM [55],SceneNN
Daily Computer Vision Papers
| Style Transfer by Relaxed Optimal Transport and Self-Similarity Authors Nicholas Kolkin, Jason Salavon, Greg Shakhnarovich 样式转移算法努力使用另一种图像的样式呈现一个图像的内容。我们提出了基于松弛最优传输和自相似性的样式转移STROTSS,一种新的基于优化的样式转移算法。我们扩展我们的方法以允许用户指定点对点或区域到区域控制样式图像和输出之间的视觉相似性。这种指导可用于实现特定的视觉效果或纠正由无约束的样式转移所产生的错误。为了将我们的方法与先前的工作进行定量比较,我们进行了大规模的用户研究,旨在评估样式转移算法中各种设置的样式内容权衡。我们的结果表明,对于任何所需的内容保存水平,我们的方法提供比以前的工作更高质量的程式化。代码可在 |
| Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation Authors Xin Chen, Lingxi Xie, Jun Wu, Qi Tian 最近,可微分搜索方法在降低神经结构搜索的计算成本方面取得了重大进展。但是,这些方法通常报告在评估搜索的体系结构或将其传输到另一个数据集时的准确性较低。这可以说是由于搜索和评估方案中的架构深度之间存在巨大差距。在本文中,我们提出了一种有效的算法,它允许搜索的体系结构的深度在训练过程中逐渐增长。这带来了两个问题,即较重的计算开销和较弱的搜索稳定性,我们分别使用搜索空间近似和正则化来解决。通过在单个GPU上显着缩短7小时的搜索时间,我们的方法在代理数据集CIFAR10或CIFAR100以及目标数据集ImageNet上实现了最先进的性能。代码可在 |
| End-to-end Cloud Segmentation in High-Resolution Multispectral Satellite Imagery Using Deep Learning Authors Giorgio Morales, Alejandro Ram rez, Joel Telles 由于卫星可以捕获的地理和云层种类繁多,因此在高分辨率卫星图像中分割云是一项艰巨而具有挑战性的任务。因此,它需要自动化和优化,特别是对于经常处理大量卫星图像的人,例如政府机构。在这个意义上,这项工作的贡献是双重的我们提出CloudPeru2数据集,包括22,400个512x512像素的图像及其各自的手绘云蒙版,以及使用卷积神经网络的云端对端分割方法的提议网络CNN基于Deeplab v3架构。测试集的结果准确度为96.62,精度为96.46,特异度为98.53,灵敏度为96.72,优于对比方法。 |
| DeepHMap++: Combined Projection Grouping and Correspondence Learning for Full DoF Pose Estimation Authors Mingliang Fu, Weijia Zhou 近年来,用卷积神经网络CNN估计对象实例的6D姿势已经受到相当多的关注。根据是否使用中间线索,相关文献可大致分为两大类直接方法和两级管道。对于后者,在第一阶段由CNN回归中间线索,例如3D对象坐标,语义关键点或虚拟控制点而不是姿势参数。然后可以通过利用这些中间线索构造的对应约束来解决对象姿势。在本文中,我们专注于两阶段管道的后处理,并提出结合两个学习概念,用于在一侧的挑战性场景投影分组和另一方面的对应学习下估计对象姿势。我们首先采用基于局部补丁的方法来预测投影热图,其表示3D边界框角的投影的置信度分布。然后提出投影分组模块以从每层热图中去除冗余的局部最大值。不是直接将2D 3D对应馈送到透视n点PnP算法,而是从局部最大值及其对应邻域对多个对应假设进行采样并且由对应评估网络对其进行排序。最后,选择具有较高置信度的对应来确定对象姿势。对三个公共数据集的广泛实验表明,所提出的框架优于几种最先进的方法。 |
| Solo or Ensemble? Choosing a CNN Architecture for Melanoma Classification Authors F bio Perez, Sandra Avila, Eduardo Valle 卷积神经网络CNN为计算机视觉提供了卓越的结果,包括医学图像分析。随着可用架构的数量不断增加,选择一个架构并不明显。现有技术表明,在执行转移学习时,ImageNet上的CNN架构的性能与它们在目标任务上的性能密切相关。我们在ISIC Challenge 2017数据集中创建的5组分组中评估了超过9种CNN结构的黑素瘤分类声明,以及3种重复测量,产生了135种模型。我们发现的相关性开始时比现有技术报道的相关性要小得多,并且当我们仅考虑表现最佳的网络不受控制的滋扰时,即完全消失,即分裂和随机性克服任何分析的因素。在可能的情况下,黑色素瘤分类的最佳方法仍然是创建多个模型的集合。我们比较了两种选择,用于选择哪些模型在高质量库中随机选取哪些模型,而使用验证集来确定首先选择哪些模型。对于小型合奏,我们发现第二种方法略有优势,但发现随机选择也具有竞争力。虽然我们在本文中的目的不是为了最大限度地提高性能,但我们很容易达到AUC,与2017年ISIC挑战赛的第一名相当。 |
| A New Method for Atlanta World Frame Estimation Authors Yinlong Liu, Alois Knoll, Guang Chen 在本文中,我们通过考虑垂直方向和水平方向之间的关系,提出了一种新的亚特兰大帧估计方法。与以前的解决方案不同,我们的方法不能同时解决所有方向。相反,它按顺序估计方向。具体地说,我们的方法首先全局搜索mathbb S 2中的垂直方向,然后估计一维中的水平方向。因此,每个子问题的维数都很低,可以有效地解决。换句话说,随着水平方向的数量增加,我们的方法的运行时间不会大大增加。通过对合成数据和现实数据进行测试,验证了我们方法的优势。 |
| Capturing human categorization of natural images at scale by combining deep networks and cognitive models Authors Ruairidh M. Battleday, Joshua C. Peterson, Thomas L. Griffiths 人类分类是心理学中认知建模最重要和最成功的目标之一,但数十年的竞争模型的开发和评估取决于一小组简单的人工实验刺激。在这里,我们将这种建模范式扩展到自然图像领域,揭示了刺激表征在分类中所起的关键作用及其对人们如何形成类别的结论的影响。将分类的心理模型应用于自然图像需要两个显着的进步。首先,我们进行了第一次人体分类的大规模实验研究,涉及来自10个非重叠对象类别的10,000个自然图像的超过500,000个人类分类判断。其次,我们通过探索当前有监督和无监督的深度和浅层机器学习方法的最佳方法,解决了在认知模型中表示高维图像的传统瓶颈。我们发现选择足够表达,数据驱动的表示对于捕获人类分类至关重要,并且使用这些表示允许表示具有抽象原型的类别的简单模型优于基于更复杂的基于记忆的分类示例,其在使用较少自然主义刺激的研究中占主导地位。 。 |
| Deep Fitting Degree Scoring Network for Monocular 3D Object Detection Authors Lijie Liu, Jiwen Lu, Chunjing Xu, Qi Tian, Jie Zhou 在本文中,我们建议学习单眼三维物体检测的深度拟合度评分网络,旨在最终得出建议与对象之间的拟合度。与大多数使用严格约束来获得3D定位的单眼框架不同,我们的方法通过测量投影的3D建议与对象之间的视觉拟合程度来实现高精度定位。我们首先使用基于锚的方法回归对象的维度和方向,以便可以构建合适的3D提议。我们提出FQNet,它可以仅基于2D线索推断3D提议和对象之间的3D IoU。因此,在检测过程中,我们在3D空间中对大量候选进行采样,并将这些3D边界框单独投影到2D图像上。通过简单地以FQNet的输出3D IoU得分的形式探索提案和对象之间的空间重叠,可以挑选出最佳候选者。 KITTI数据集上的实验证明了我们框架的有效性。 |
| DeLiO: Decoupled LiDAR Odometry Authors Queens Maria Thomas, Oliver Wasenm ller, Didier Stricker 大多数LiDAR测距算法通过以插入方式估计旋转和平移来估计两个连续帧之间的变换。在本文中,我们提出了解耦LiDAR测距仪DeLiO,它首次将旋转估计完全与平移估计解耦。特别地,通过从输入点云提取表面法线并在单位球上跟踪它们的特征图案来估计旋转。使用此旋转,点云未旋转,因此底层变换是纯粹的平移,可以使用线云方法轻松估算。对KITTI数据集进行评估,并将结果与现有技术算法进行比较。 |
| PCA-RECT: An Energy-efficient Object Detection Approach for Event Cameras Authors Bharath Ramesh, Andres Ussa, Luca Della Vedova, Hong Yang, Garrick Orchard 我们提出了第一个基于事件的,基于事件的节能方法,用于使用事件相机进行物体检测和分类。与传统的基于帧的相机相比,选择事件相机导致微秒的高时间分辨率,低功耗几百mW和宽动态范围120dB作为吸引人的特性。然而,基于事件的对象识别系统在准确性方面远远落后于基于帧的对象。为此,本文提出了一种基于事件的特征提取方法,该方法通过在图像帧上累积局部活动然后将主成分分析PCA应用于归一化邻域来设计。随后,我们通过利用特征表示的低维度来提出用于有效特征匹配的回溯自由k d树机制。另外,所提出的k d树机制允许特征选择以在硬件资源被限制以实现维度减少时获得较低维度的字典表示。因此,所提出的系统可以在现场可编程门阵列FPGA器件上实现,从而导致高性能超过资源比。所提出的系统在用于对象分类的基于真实世界事件的数据集上进行测试,显示出优越的分类性能以及与现有技术算法的相关性。此外,我们在有限的训练数据和地面实况注释的非受控照明条件下,在实验室环境中验证了物体检测方法和实时FPGA性能。 |
| Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition Authors Maosen Li, Siheng Chen, Xu Chen, Ya Zhang, Yanfeng Wang, Qi Tian 最近,骨架数据的动作识别在计算机视觉中引起了很多关注。以前的研究主要基于固定的骨架图,仅捕获关节之间的局部物理依赖性,这可能会错过隐式关节相关性。为了捕获更丰富的依赖关系,我们引入了一种称为A链接推理模块的编码器解码器结构,以直接从动作捕获特定于行为的潜在依赖关系,即动作链接。我们还扩展现有的骨架图以表示更高阶的依赖性,即结构链接。将这两种类型的链接组合成广义骨架图,我们进一步提出动作结构图卷积网络AS GCN,其将动作结构图卷积和时间卷积堆叠为基本构建块,以学习用于动作识别的空间和时间特征。将未来的姿势预测头与识别头并行添加,以帮助通过自我监督捕获更详细的行动模式。我们使用两个骨架数据集NTU RGB D和Kinetics在动作识别中验证AS GCN。与现有技术方法相比,所提出的AS GCN实现了持续的大的改进。作为副产品,AS GCN还展示了未来姿势预测的有希望的结果。 |
| MSDC-Net: Multi-Scale Dense and Contextual Networks for Automated Disparity Map for Stereo Matching Authors Zhibo Rao, Mingyi He, Yuchao Daia, Zhidong Zhua, Bo Lia, Renjie He 立体图像的视差预测对于计算机视觉应用是必不可少的,包括自动驾驶,3D模型重建和物体检测。为了预测准确的视差图,我们提出了一种新的深度学习架构,用于从一对称为MSDC Net的整流立体图像中检测视差图。我们的MSDC Net包含两个模块多尺度融合2D卷积和多尺度残差3D卷积模块。多尺度融合2D卷积模块利用潜在的多尺度特征,通过Dense Net提取和融合不同尺度特征。多尺度残差3D卷积模块从由多尺度融合2D卷积模块聚合的成本体积中学习不同尺度几何上下文。在Scene Flow和KITTI数据集上的实验结果表明,我们的MSDC Net明显优于非遮挡区域中的其他方法。 |
| The Mutex Watershed and its Objective: Efficient, Parameter-Free Image Partitioning Authors Steffen Wolf, Alberto Bailoni, Constantin Pape, Nasim Rahaman, Anna Kreshuk, Ullrich K the, Fred A. Hamprecht 图像分割或没有语义的分割是将图像分解成不同的片段或等效地检测闭合轮廓的任务。大多数先前的工作要么需要种子,每个部分一个或一个阈值,要么将任务规划为多核相关聚类,即NP难题。在这里,我们提出了一种用于签名图分区的贪心算法,即Mutex Watershed。与种子流域不同,该算法不仅可以容纳有吸引力的,而且还可以容纳令人厌恶的线索,使其能够找到先前未指定数量的段而无需显式种子或可调阈值。我们还证明了这种简单的算法解决了全局最优性的一个目标函数,它与多核相关聚类整数线性规划公式密切相关。该算法是确定性的,实现起来非常简单,并且具有经验上的线性复杂性。当呈现来自深度神经网络的短距离吸引力和长距离排斥线索时,Mutex Watershed为竞争性ISBI 2012 EM分割基准提供了目前已知的最佳结果。 |
| Forward Vehicle Collision Warning Based on Quick Camera Calibration Authors Yuwei Lu, Yuan Yuan, Qi Wang 前方车辆碰撞警告FCW是自动驾驶车辆最重要的功能之一。在此过程中,车辆检测和距离测量是核心组件,需要精确的定位和估算。在本文中,我们通过聚合单眼距离测量和精确的车辆检测,提出了一种简单但有效的前方车辆碰撞预警框架。为了获得前方车辆距离,使用了仅需要三个物理点来校准相关摄像机参数的快速摄像机校准方法。对于前方车辆检测,提出了一种将校准结果视为距离先验的多尺度检测算法,以提高精度。在我们建立的真实场景数据集中进行了密集的实验,结果证明了所提出的框架的有效性。 |
| Tracking as A Whole: Multi-Target Tracking by Modeling Group Behavior with Sequential Detection Authors Yuan Yuan, Yuwei Lu, Qi Wang 基于视频的车辆检测和跟踪是智能交通系统ITS最重要的组成部分之一。当谈到道路交叉口时,由于车辆之间的堵塞和复杂的相互作用,问题变得更加困难。为了获得精确的检测和跟踪结果,在这项工作中,我们提出了一种新的跟踪检测框架。在检测阶段,我们提出了一个顺序检测模型来处理严重的闭塞。在跟踪阶段,我们对组行为进行建模,以处理具有重叠和模糊的复杂交互。本文的主要贡献是双重的1形状先验在序贯检测模型中被用来解决拥挤场景中的遮挡。 2在交通场景中定义交通力以模拟群体行为,并且它可以帮助处理车辆之间的复杂交互。我们评估了在路口实际监控视频上提出的方法,并且性能证明了我们方法的有效性。 |
| TextCohesion: Detecting Text for Arbitrary Shapes Authors Weijia Wu, Jici Xing, Hong Zhou 在本文中,我们提出了一种名为TextCohesion的像素智能检测器,用于场景文本检测,尤其适用于任意形状的检测器。 TextChohesion将文本实例拆分为5个关键组件,即文本框架和四个方向像素区域。这些组件易于处理,而不是直接控制整个文本实例。我们还引入了置信度评分机制来过滤掉与文本类似的字符。我们的方法可以集中整合文本上下文,甚至可以在非常复杂的背景下掌握线索。在具有挑战性的基准测试中的实验证明,我们的TextCohesion明显优于最先进的方法,并且它在Total Text和SCUT CTW1500上分别实现了84.6和86.3的F度量。 |
| Inner-Imaging Convolutional Networks Authors Yang Hu, Guihua Wen, Mingnan Luo, Dan Dai, Wenming Cao, Zhiwen Yu 尽管计算机视觉取得了巨大成功,但深度卷积网络仍然存在严重的计算成本和冗余。虽然以前的工作通过增强滤波器的多样性来解决这个问题,但是它们忽略了卷积网络内部结构中的互补性和完整性。在此设置中,我们提出了一种新颖的内部成像架构,它允许通道之间的关系满足上述要求。具体来说,我们使用卷积核来组合滤波器信号点,以同时模拟组内和组间关系。因此,我们不仅增加了渠道的多样性,而且明确地增强了互补性和完整性。我们提出的架构重量轻,易于实现,以提高建模效率和性能。我们在CIFAR,SVHN和ImageNet上进行了大量实验,并验证了我们的内部成像架构的有效性,其中剩余网络作为主干。 |
| Context-Aware Zero-Shot Learning for Object Recognition Authors Eloi Zablocki, Patrick Bordes, Benjamin Piwowarski, Laure Soulier, Patrick Gallinari 零镜头学习ZSL旨在通过利用辅助知识(如语义表示)对未标记的对象进行分类。先前方法的限制是仅对象的固有属性,例如,在他们的背景下,例如他们的视觉外观被考虑在内。图像中的周围对象将被忽略。遵循直观的原则,即对象倾向于在某些上下文中而不是在其他上下文中找到,我们提出了一种新的且具有挑战性的方法,即上下文感知的ZSL,它以新的方式利用语义表示来模拟对象在给定内容中出现的条件可能性上下文。最后,通过对Visual Genome进行的大量实验,我们发现上下文信息可以显着改善标准ZSL方法,并且对不平衡类具有鲁棒性。 |
| DADA-2000: Can Driving Accident be Predicted by Driver Attention? Analyzed by A Benchmark Authors Jianwu Fang, Dingxin Yan, Jiahuan Qiao, Jianru Xue, He Wang, Sen Li 驾驶员注意力预测目前正成为安全驾驶研究界的焦点,例如DR eye VE项目和新出现的Berkeley DeepDrive Attention BDD A数据库在危急情况下。在安全驾驶中,一项重要任务是尽早预测即将发生的事故。 BDD A意识到这个问题并且在实验室中引起了驾驶员的注意,因为这些场景很少见。然而,BDD A关注的是没有遇到实际事故的危急情况,只是面对驾驶员注意预测任务,没有事故预测的紧密步骤。与此形成对比的是,我们探索驾驶员眼睛捕捉多种事故的观点,构建一个比以往更加多样化和更大的视频基准,驾驶员注意力和驾驶事故注释同时命名为DADA 2000,其中有2000个视频在54种事故中拥有约658,476帧的剪辑。这些剪辑是人群采集和捕获的高速公路,城市,乡村和隧道,天气晴朗,多雨和白天和夜晚的光线条件。对于驾驶员注意力表示,我们收集固定地图,扫视扫描路径和聚焦时间。事故由其类别,夹子中的事故窗口和碰撞对象的空间位置注释。在分析的基础上,我们得到了本文中问题的定量和肯定答案。 |
| A Personalized Affective Memory Neural Model for Improving Emotion Recognition Authors Pablo Barros, German I. Parisi, Stefan Wermter 最近的情绪识别模型强烈依赖于有监督的深度学习解决方案来区分一般情绪表达。然而,当识别在线和个性化的面部表情时,例如,对于特定于人的情感理解,它们是不可靠的。在本文中,我们提出了一个基于条件对抗自动编码器的神经模型,以学习如何表示和编辑一般情绪表达。然后,我们建议将需要时增长的网络作为个性化的情感记忆来学习情绪表达的个性化方面。当在野生数据集中对textit进行评估时,我们的模型在情感识别方面实现了最先进的性能。此外,我们的实验包括消融研究和神经可视化,以解释我们的模型的行为。 |
| Detecting inter-sectional accuracy differences in driver drowsiness detection algorithms Authors Mkhuseli Ngxande, Jule Raymond Tapamo, Michael Burke 卷积神经网络CNN已成功应用于广泛的领域,包括数据挖掘,对象检测和业务。 CNN的优势在Alex Krizhevsky的突破之后,通过将一般图像分类任务中获得的错误率从26.2急剧降低到15.4来显示出改进。在道路安全方面,CNN已广泛应用于交通标志,障碍物检测和车道偏离检查的检测。此外,CNN已被用于监控驾驶模式的数据挖掘系统,并在适当时推荐休息时间。本文介绍了驾驶员睡意检测系统,并通过突出检测深色皮肤驾驶员面部的问题,表明这些技术的应用存在潜在的社会挑战。在非洲环境中,这是一个特别重要的挑战,那里有更多皮肤黝黑的司机。不幸的是,公开可用的数据集通常在不同的文化背景下被捕获,因此不包括所有种族,这可能导致错误的检测或种族偏见的模型。这项工作评估了在常用驾驶员睡意检测数据集上训练卷积神经网络模型并对专门为更广泛的表示选择的数据集进行测试时获得的性能。结果表明,使用公开数据集训练的模型遭受过度拟合的广泛影响,并且可能表现出种族偏见,如通过在更具代表性的数据集上进行测试所示。我们提出了一种新颖的可视化技术,可以帮助识别可能存在歧视的人群,使用主成分分析PCA生成按相似性排序的面部网格,并将这些与模型精度叠加相结合。 |
| Beauty Learning and Counterfactual Inference Authors Tao Li 这项工作通过利用用户实验和照片真实图像编辑的最新进展展示了一种新的因果发现方法,展示了识别因果因素和反事实地理解复杂系统的潜力。我们以美容学习问题为例,几个世纪以来一直在形而上学讨论并被证明存在,可量化,并且可以通过我们最近的论文中的深层模型学习,其中我们利用自然图像生成器结合用户研究来推断从面部语义学到美容结果的因果效应,其结果也与现有的实证研究一致。我们期望拟议的框架可以更广泛地应用于因果推理。 |
| Computational Attention System for Children, Adults and Elderly Authors Onkar Krishna, Kiyoharu Aizawa, Go Irie 现有的计算机视觉注意系统的重点是基本上模拟和理解成人视觉注意系统的概念。因此,很少考虑观察者年龄对场景观察行为的影响。本研究定量分析了三种不同类型的自然图像,人造图像和分形图像在场景观察期间凝视着陆的年龄相关差异。不同年龄组的观察者已经显示出与所观看图像的类别无关的不同场景观看趋势。从结果中得出了一些有趣的观察结果。首先,用于人造数据集的凝视着陆显示,尽管儿童观察者更多地关注场景前景,即附近的位置,但是老年观察者倾向于探索场景背景,即场景中更远的位置。考虑到这一结果,本文提出了一个框架来定量测量不同年龄组的深度偏差趋势。其次,定量分析结果显示,儿童表现出最低的探索行为水平,但在年龄组和不同的场景类别中表现出最高的中心偏向倾向。第三,个体间相似性指标显示,与所有场景类别的其他成年人相比,成人与儿童和老年人的凝视一致性显着降低。最后,这些分析结果因此被用于开发独立于图像类型的更准确的年龄适应显着性模型。预测准确性表明,我们的模型更适合于收集的属于不同年龄组的观察者的眼睛凝视数据,而不是现有模型。 |
| Catch Me If You Can Authors Antoine Viscardi, Casey Juanxi Li, Thomas Hollis 随着签名识别的进步在2个错误率上达到了新的性能平台,研究替代方法很有意思。本文详述的方法着眼于使用变分自动编码器VAE来学习真实签名的潜在空间表示。然后,这用于传递未标记的签名,使得VAE仅成功地重建真实的签名。该潜在空间表示和重建损失随后由随机森林和kNN分类器用于预测。随后,确定并分析VAE解开和后塌陷的可能性。最终结果表明,虽然这种方法的表现不如现有的替代方案,但进一步的工作可能会将其用作未来模型的整体的一部分。 |
| Crowd Management in Open Spaces Authors Tauseef Ali, Ahmed B. Altamimi 人群分析和管理是确保公共安全和保障的一个具有挑战性的问题。为此目的,已经提出了许多技术来解决各种问题。然而,这些技术的泛化能力是有限的,因为忽略了人群的密度从低到高变化的事实,这取决于观察的场景。我们提出了基于功能强大的方法来处理人群安全和人身安全问题。我们使用基准数据集评估了我们的方法,并提供了详细信息分析。 |
| Talk Proposal: Towards the Realistic Evaluation of Evasion Attacks using CARLA Authors Cory Cornelius, Shang Tse Chen, Jason Martin, Duen Horng Chau 在本次演讲中,我们描述了我们的内容保护攻击对象检测器,ShapeShifter,并演示如何在现实场景中评估此威胁。我们将介绍如何使用CARLA(一种逼真的城市驾驶模拟器)来创建这些场景,以及我们如何使用ShapeShifter生成针对这些场景的内容保护攻击。 |
| AnonymousNet: Natural Face De-Identification with Measurable Privacy Authors Tao Li, Lei Lin 随着每天从社交媒体和各种类型的摄像机生成数十亿个人图像,安全性和隐私性受到前所未有的挑战。虽然已经进行了大量的尝试,但是现有的面部图像识别技术要么在照片现实中不足,要么无法在质量和数量上平衡隐私和可用性,即,它们无法回答反事实问题,例如现在是私人的,它是多么私密,它可以更私密在本文中,我们提出了一个名为AnonymousNet的新框架,努力系统地解决这些问题,平衡可用性,并以自然和可衡量的方式增强隐私。该框架包括四个阶段的面部属性估计,面向隐私度量的面部混淆,定向自然图像合成和对抗性扰动。我们不仅在图像质量和属性预测准确性方面实现了现状,我们也首次证明面部隐私是可测量的,可以分解,因此可以以照片逼真的方式进行操作以满足不同的要求和应用场景。实验进一步证明了所提出框架的有效性。 |
| Multiple receptive fields and small-object-focusing weakly-supervised segmentation network for fast object detection Authors Siyang Sun 对象检测在各种视觉应用中起着重要作用。然而,探测器的精度和速度通常是矛盾的。快速检测器精确度降低的一个主要原因是难以检测小物体。为了解决这个问题,我们提出了一个多感受野和小物体聚焦弱监督分割网络MRFSWSnet来实现快速物体检测。在MRFSWSnet中,多个感受野块MRF用于关注物体及其相邻背景的不同空间位置,具有不同的权重,以增强特征的可辨性。另外,为了提高小物体检测的精度,将小物体聚焦弱监督分割模块(仅关注小物体而非所有物体)集成到检测网络中进行辅助训练,以提高小物体检测的精度。大量实验表明我们的方法对PASCAL VOC和MS COCO检测数据集的有效性。特别是,对于300x300的较低分辨率版本,MRFSWSnet在VOC2007测试中达到80.9 mAP,每帧的推理速度为15毫秒,这是实时检测器中最先进的检测器。 |
| Deep Learning Based Automatic Video Annotation Tool for Self-Driving Car Authors N.S.Manikandan, K.Ganesan 在自动驾驶汽车中,异物检测,物体分类,车道检测和物体跟踪被认为是关键模块。最近,使用实时视频,人们想要叙述安装在我们车辆中的摄像机拍摄的场景。为了有效地实现该任务,广泛使用深度学习技术和自动视频注释工具。在本文中,我们比较了每个模块可用的各种技术,并使用适当的指标选择其中的最佳算法。对于物体检测,考虑YOLO和Retinanet 50,并且基于平均精度mAP选择最佳的一个。对于对象分类,我们考虑VGG 19和Resnet 50,并选择基于低错误率和良好准确性的最佳算法。对于车道检测,比较Udacity s Finding Lane Line和基于深度学习的LaneNet算法,并选择能够准确识别给定车道的最佳车道用于实施。就目标跟踪而言,我们比较了Udacity的对象检测和跟踪算法以及基于深度学习的深度排序算法。基于在许多帧中跟踪相同对象并预测对象移动的准确性,选择最佳算法。与人类注释器相比,我们的自动视频注释工具精确到83。我们考虑了一个分辨率为1035 x 1800像素的530帧视频。平均每帧约有15个物体。我们的注释工具在基于CPU的系统中消耗43分钟,在基于GPU的中级系统中消耗2.58分钟来处理所有四个模块。但同一个视频花了近3060分钟让一位人类注释者在给定视频中叙述场景。因此,我们声称我们提出的自动视频注释工具在GPU系统中相当快1200次且准确。 |
| Everyone is a Cartoonist: Selfie Cartoonization with Attentive Adversarial Networks Authors Xinyu Li, Wei Zhang, Tong Shen, Tao Mei 自拍和卡通是我们日常生活中广泛呈现的两种流行的艺术形式。尽管在图像翻译风格化方面取得了很大进步,但是很少有技术专注于自拍卡通化,因为卡通图像通常包含艺术抽象,例如,大的平滑区域和夸张,例如大的精致眉毛。在本文中,我们通过提出自拍漫画生成对抗网络scGAN来解决这个问题,该主要使用细心的对抗网络AAN来强调特定的面部区域并忽略低级细节。更具体地说,我们首先设计一个类似于体系结构的循环,以便使用不成对数据进行训练然后我们从不同方面设计三个损失。总变异损失用于突出卡通肖像中的重要边缘和内容。增加了周到的周期性损失,以更加强调眼睛等精致的面部区域。此外,还包括感知损失以消除伪像并提高我们方法的稳健性。实验结果表明,我们的方法能够产生不同的卡通风格,并且优于许多最先进的方法。 |
| State Classification of Cooking Objects Using a VGG CNN Authors Kyle Mott 在机器学习中,机器人知道对象的状态并识别特定的期望状态是非常重要的。这是可以使用卷积神经网络解决的图像分类问题。在本文中,我们将讨论使用VGG卷积神经网络识别烹饪对象的状态。我们将讨论激活函数,优化器,数据增强,层添加和其他不同版本的体系结构的使用。本文的结果将用于确定VGG卷积神经网络的替代方案,以提高准确性。 |
| Converting a Common Document Scanner to a Multispectral Scanner Authors Zohaib Khan, Faisal Shafait, Ajmal Mian 我们建议构建一个原型扫描仪,用于捕获文档的多光谱图像。通过断开其内部光源并连接包括窄带发光二极管LED的外部多光谱光源来修改标准片状馈送扫描器。通过用不同的LED连续照射扫描仪光导并捕获文档的扫描来扫描文档。该系统是便携式的,可用于验证质疑文件,支票,收据和纸币的潜在应用。 |
| EV-Action: Electromyography-Vision Multi-Modal Action Dataset Authors Lichen Wang, Bin Sun, Joseph Robinson, Taotao Jing, Yun Fu 多模态人体运动分析是一个关键且有吸引力的研究课题。大多数现有的多模态动作数据集仅提供视觉模态,例如RGB,深度或低质量骨架数据。在本文中,我们引入了一个名为EV Action数据集的新的大规模数据集。它包括RGB,深度,肌电图EMG和两种骨架模态。与其他人相比,我们的数据集有两个主要的改进1我们部署了一个动作捕捉系统,以获得高质量的骨架模态,提供更全面的运动信息,包括骨架,轨迹和加速度,具有更高的准确性,采样频率和更多的骨架标记。 2我们包括EMG模态。虽然EMG被用作生物力学领域的有效指标,但它在多媒体,计算机视觉和机器学习领域尚未得到很好的探索。据我们所知,这是第一个具有EMG模态的动作数据集。在本文中,我们将介绍EV Action数据集的详细信息。提出了一种基于EMG的动作识别的简单而有效的框架。此外,我们为每种模式提供最先进的基线。当涉及EMG时,这些方法实现了相当大的改进,并且它证明了EMG模态在人类行动分析任务中的有效性。我们希望这个数据集可以为信号处理,多媒体,计算机视觉,机器学习,生物力学和其他跨学科领域做出重大贡献。 |
| Self-Supervised Flow Estimation using Geometric Regularization with Applications to Camera Image and Grid Map Sequences Authors Sascha Wirges, Johannes Gr ter, Qiuhao Zhang, Christoph Stiller 我们提出了一种自我监督的方法,用于在自动驾驶领域中使用完全卷积神经网络来估计相机图像和顶视图网格图序列中的流量。我们通过在假定静态环境的情况下添加表示运动一致性的正则化器来扩展用于自监督光流估计的现有方法。然而,由于这个假设违反了其他移动交通参与者,我们还估计了一个掩模来扩展这种正规化。向运动一致性添加正则化可以提高收敛性和流量估计精度。此外,我们通过我们从运动遮罩得到的遮罩来缩放由于空间流量不一致引起的误差。由于静态和动态环境之间的更好分离,这提高了流量急剧变化的区域的准确性。我们将我们的方法应用于来自摄像机图像序列的光流估计,验证测距估计并建议使用所生成的运动掩模迭代地增加光流估计精度的方法。最后,我们基于基于网格图序列的KITTI测距和跟踪基准来提供定量和定性结果。我们表明,在应用运动和空间一致性正则化时,我们可以提高准确性和收敛性。 |
| Region homogeneity in the Logarithmic Image Processing framework: application to region growing algorithms Authors Guillaume Noyel IPRI, SIGPH iPRI , Michel Jourlin IPRI 为了创建对光照变化具有鲁棒性的图像分割方法,研究了图像区域的两个新的均匀性标准。两者都是使用对数图像处理LIP框架定义的,该框架的法则模拟照明变化。第一个标准估计LIP添加剂的均匀性,并基于LIP加性定律。理论上,它对照相机曝光时间或光源强度变化引起的照明变化不敏感。第二个是LIP乘法同质性标准,它基于LIP乘法定律,并且对由于物体厚度或不透明度的变化引起的变化不敏感。然后将每个标准应用于Revol和Jourlin的1997区域生长方法,该方法基于图像区域的同质性。因此,区域生长方法对于每个标准特定的照明变化是稳健的。在模拟和实际图像上呈现光照变化的实验证明了标准对这些变化的稳健性。与基于图像组件树的现有技术方法相比,我们的方法更加健壮。这些结果为照明不受控制或部分控制的众多应用开辟了道路。 |
| An Ensemble of Neural Networks for Non-Linear Segmentation of Overlapped Cursive Script Authors Amjad Rehman 精确的字符分割是提高光学字符识别OCR精度的唯一解决方案。在草书中,重叠字符是字符分割过程中的严重问题,因为使用传统的线性分割策略将字符从其判别部分中剥夺。因此,非线性分割是避免字符部分丢失和增强字符脚本识别准确性的最大需要。本文提出了一种改进的手写罗马字体重叠字符非线性分割方法。所提出的技术由基于字符的几何特征的一系列启发式规则组成,以在草书脚本字中定位可能的非线性字符边界。然而,为了提高效率,启发式方法与训练的集合神经网络验证策略集成,用于验证字符边界。因此,基于集合神经网络投票,保留正确的边界并且移除不正确的边界。最后,基于验证的有效分割点,字符被非线性地分段。为了公平比较,对CEDAR基准数据库进行了实验。实验结果比现有技术中报道的传统线性字符分割技术好得多。与单个神经网络相比,集合神经网络在提高字符分割精度方面起着至关重要的作用。 |
| A dual branch deep neural network for classification and detection in mammograms Authors Ran Bakalo, Jacob Goldberger, Rami Ben Ari 在本文中,我们提出了一种新的深度学习架构,用于乳房X线照片中异常的联合分类和定位。我们首先假设一个弱监督的设置,并提出一种新的方法,用数据驱动的决策。这个新颖的网络结合了两个学习分支与区域级别分类和区域排名。网络将图像的全局分类提供为多个类,例如恶性,良性或正常。我们的方法进一步使异常的定位成为全乳房X线照片分辨率中的全局类判别区域。接下来,我们将此方法扩展为半监督设置,该设置使用新颖的体系结构和多任务目标函数来接合一小组本地注释。我们介绍了本地注释对包括本地化在内的多种绩效指标的影响,以评估病变注释工作的成本效益。我们的评估是通过一个大型多中心乳腺摄影数据集进行的,该数据集包含3,000个乳房X线照片以及各种发现。实验结果证明了该方法相对于先前弱监督策略的能力和优势,以及半监督学习的影响。我们表明,仅针对5个图像的注释可以显着提高性能。 |
| Robust object extraction from remote sensing data Authors Sophie Crommelinck, Mila Koeva, Michael Ying Yang, George Vosselman 在过去的几十年中,对象轮廓的提取一直是一个研究课题。尽管在摄影测量,遥感和计算机视觉方面取得了进展,但由于物体和数据的复杂性,这项任务依然具有挑战性。通过公开可用的基准数据集和评估框架来促进对象提取方法的开发。已经研究了性能评估的许多方面。本研究收集了文献中的最佳实践,将各个方面放在一个评估框架中,并展示了它对绘制对象轮廓的案例研究的有用性。评估框架包括五个维度,即对分辨率,输入,位置,参数和应用程序变化的稳健性。提供了调查这些维度的示例,以及用于定性分析的准确度度量。这些措施包括时间效率和关于定量完整性和空间正确性的基于线的准确度评估程序。应用评估框架的描述方法以前已经引入,并且在本研究中得到了实质性的改进。 |
| X-Ray CT Reconstruction of Additively Manufactured Parts using 2.5D Deep Learning MBIR Authors Amirkoushyar Ziabari, Michael Kirka, Vincent Paquit, Philip Bingham, Singanallur Venkatakrishnan 在本文中,我们提出了一种深度学习算法,以快速获得AM部件的高质量CT重建。特别是,我们建议使用要制造的零件的CAD模型,引入典型缺陷并模拟XCT测量。这些模拟测量使用FBP在计算上进行简单处理,但会产生噪声图像和MBIR技术。然后,我们在这些噪声和高质量3D体积上训练2.5D深度卷积神经网络4,认为2.5D深度学习MBIR 2.5D DL MBIR,以学习快速,非线性映射功能。 2.5D DL MBIR以2.5D方案重建3D体积,其中每个切片从FBP输入的多个输入切片重建。在这个训练有素的系统中,我们可以对实际零件进行一小组测量,使用FBP和2.5D DL MBIR的组合对其进行处理。使用GPU可以快速执行这两个步骤,从而产生实时算法,以与标准技术一样快速地实现MBIR的高质量。直观地,由于CAD模型通常可用于要制造的零件,因此这提供了强大的约束,之前可以利用该约束来改进重建。 |
| The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision Authors Jiayuan Mao, Chuang Gan, Pushmeet Kohli, Joshua B. Tenenbaum, Jiajun Wu 我们提出了神经符号概念学习者NS CL,这是一个学习视觉概念,单词和句子语义解析的模型,而不对他们中的任何一个进行明确的监督,我们的模型通过简单地查看图像和阅读成对的问题和答案来学习。我们的模型构建了一个基于对象的场景表示,并将句子翻译成可执行的符号程序。为了弥合两个模块的学习,我们使用神经符号推理模块,在潜在的场景表示上执行这些程序。类似于人类概念学习,感知模块基于所参考对象的语言描述来学习视觉概念。同时,学习的视觉概念有助于学习新单词和解析新句子。我们使用课程学习来指导搜索图像和语言的大型构图空间。大量实验证明了我们的模型在学习视觉概念,单词表示和句子语义分析方面的准确性和有效性。此外,我们的方法允许容易地推广到新的对象属性,组合,语言概念,场景和问题,甚至新的程序域。它还支持应用程序,包括视觉问答和双向图像文本检索。 |
| Casting Geometric Constraints in Semantic Segmentation as Semi-Supervised Learning Authors Sinisa Stekovic, Friedrich Fraundorfer, Vincent Lepetit 我们提出了一种简单而有效的方法来学习从RGB D序列中分割新的室内场景在一个数据集上训练的现有技术方法,即使与SUNRGB D数据集一样大,在应用于不属于该数据集的图像时也可能表现不佳由于数据集偏差,数据集是计算机视觉中的常见现象。为了使语义分割在实践中更有用,我们学习通过利用SUNRGB D的几何约束和随时可用的训练数据,从序列中分割新的室内场景而无需手动注释。因此,我们可以从颜色中稳健地分割这些场景的新图像。仅供参考。为了有效地利用几何约束来达到我们的目的,我们建议将这些约束转换为半监督术语,这强制要求对不同图像中相同3D位置的投影预测相同的类。我们证明了这种方法产生了一种简单但非常强大的方法,它可以仅使用SUNRGB D的注释来注释ScanNet序列和我们自己的序列。 |
| Meta Anti-spoofing: Learning to Learn in Face Anti-spoofing Authors Chenxu Zhao, Yunxiao Qin, Zezheng Wang, Tianyu Fu, Hailin Shi 面部反欺骗对于人脸识别系统的安全性至关重要。以前,大多数方法将面部反欺骗制定为监督学习问题以检测各种预定义的呈现攻击PA。然而,新的攻击方法不断发展,产生新形式的欺骗面以破坏现有的探测器。这要求研究人员收集大量样本以训练分类器以检测新的攻击,这通常是昂贵的并且导致后来新进化的攻击样本保持小规模。或者,我们将面部反欺骗定义为一些针对不断演变的新攻击的镜头学习问题,并通过名为Meta Face Anti spoofing Meta FAS的元学习提出一种新颖的面部反欺骗方法。 Meta FAS通过训练分类器来解决上述问题,如何学习如何通过几个例子来检测欺骗面。为了评估所提议方法的有效性,我们提出了一系列基于公共数据集文本的评估基准,例如: ,OULU NPU,SiW,CASIA MFSD,Replay Attack,MSU MFSD,3D MAD和CASIA SURF,并且所提出的方法显示出其对比方法的优越性能。 |
| Self-Attention Capsule Networks for Image Classification Authors Assaf Hoogi, Brian Wilcox, Yachee Gupta, Daniel L. Rubin 我们提出了一种新的图像分类架构,称为自注意胶囊网络SACN。 SACN是第一个将自注意机制作为胶囊网络CapsNet中的整合层的模型。虽然自注意机制选择要关注的更主要的图像区域,但CapsNet仅分析这些区域内的相关特征及其空间相关性。在卷积层中提取特征。然后,自注意层学习基于特征分析来抑制不相关的区域,并突出显示对特定任务有用的显着特征。然后将注意力图输入CapsNet主层,然后是分类层。 SACN提出的模型旨在使用相对较浅的CapsNet架构来减少计算负荷,并通过使用自注意模块显着改善结果来补偿缺少更深的网络。除了自然的MNIST和SVHN之外,所提出的Self Attention CapsNet架构在五个不同的数据集上进行了广泛的评估,主要是在三种不同的医疗集上。该模型能够比基线CapsNet更好地分类具有多样化和复杂背景的图像及其补丁。因此,提议的Self Attention CapsNet显着提高了不同数据集内和跨不同数据集的分类性能,并且不仅在分类准确性方面而且在稳健性方面优于基线CapsNet。 |
| HOG feature extraction from encrypted images for privacy-preserving machine learning Authors Masaki Kitayama, Hitoshi Kiya 在本文中,我们提出了一种从加密到压缩EtC图像的HOG直方图的提取方法,用于隐私保护机器学习,其中EtC图像是通过基于块的加密方法加密的图像,该方法用于具有JPEG压缩的EtC系统,以及HOG是用于计算机视觉的特征描述符,用于对象检测和图像分类。最近,云计算和机器学习已经在许多领域得到普及。然而,由于提供商的不可靠性和一些事故,云计算对最终用户具有严重的隐私问题。因此,我们提出了一种新的基于块的HOG特征提取方法,并且所提出的方法使我们能够在某些条件下执行任何机器学习算法而没有任何影响。在实验中,所提出的方法应用于人脸图像识别问题下,使用两种分类器线性支持向量机SVM,高斯SVM,来证明其有效性。 |
| Automatic extrinsic calibration between a camera and a 3D Lidar using 3D point and plane correspondences Authors Surabhi Verma, Julie Stephany Berrio, Stewart Worrall, Eduardo Nebot 本文提出了一种自动方法,用于获取相机和具有低至16个光束的3D激光雷达之间的外部校准参数。我们使用棋盘作为参考来获得两个传感器框架中感兴趣的特征。通过利用电路板的几何形状,自动从激光雷达点云提取校准板中心点和法向矢量。摄像机图像中的相应特征是从摄像机的外在矩阵获得的。我们解释了选择这些功能的原因,以及为什么它们与其他可能性相比更加强大。为了获得最佳外部参数,我们选择遗传算法来解决高度非线性状态空间。在定义3D实验区域相对于激光雷达的边界以及真实的板尺寸之后,该过程是自动化的。此外,假设相机本质上是校准的。我们的方法需要至少3个棋盘格姿,并且通过使用真实世界和模拟特征评估我们的算法来证明校准精度。 |
| Attribute Guided Unpaired Image-to-Image Translation with Semi-supervised Learning Authors Xinyang Li, Jie Hu, Shengchuan Zhang, Xiaopeng Hong, Qixiang Ye, Chenglin Wu, Rongrong Ji 不成对的图像到图像翻译UIT专注于使用不成对的数据在不同的域之间翻译图像,由于其实际使用而受到越来越多的研究关注。然而,现有的UIT方案缺乏监督训练的需要,以及缺乏编码域信息。在本文中,我们提出了一个名为AGUIT的属性引导UIT模型来解决这两个挑战。 AGUIT考虑了UIT的多模态和多域任务以及一种新颖的半监督设置,这也适用于表示解散和输出的精细控制。特别是,AGUIT受益于两倍1它通过将标记数据的属性转换为未标记数据,然后通过循环一致性操作重建未标记数据,采用新颖的半监督学习过程。 2它将图像表示分解为域不变内容代码和域特定样式代码。重新设计的样式代码将图像样式嵌入到从标准高斯分布和域标签分布中绘制的两个变量中,这有助于由于两个变量的连续性而对翻译进行精细控制。最后,我们为UIT模型引入了一个新的挑战,即解开转移,它采用解缠结的表示来转换与训练集较少相关的数据。大量实验证明了AGUIT相对于现有技术模型的能力。 |
| LeGR: Filter Pruning via Learned Global Ranking Authors Ting Wu Chin, Ruizhou Ding, Cha Zhang, Diana Marculescu 过滤器修剪已经证明对于学习资源受限的卷积神经网络CNN是有效的。然而,用于资源约束的过滤器修剪的现有方法具有一些限制其妨碍其有效性和效率的限制。当搜索满足CNN的约束时,先验方法要么改变优化目标要么采用具有启发式参数化的局部搜索算法,这是次优的,特别是在低资源状态下。从效率的角度来看,搜索满足CNN的约束的先前方法通常是昂贵的。在这项工作中,我们提出了被称为LeGR的学习全球排名,它在上述两个方面改进了现有技术。受理论分析的启发,LeGR被参数化以学习关于过滤器规范的分层仿射变换以构建学习的全局排名。通过全局排名,可以有效地完成各种约束级别的资源约束过滤器修剪。我们进行了广泛的实证分析,以证明所提算法与ResNet和MobileNetV2网络在CIFAR 10,CIFAR 100,Bird 200和ImageNet数据集上的有效性。代码公开于 |
| Unsupervised Feature Learning for Point Cloud by Contrasting and Clustering With Graph Convolutional Neural Network Authors Ling Zhang, Zhigang Zhu 为了减少收集和注释大规模点云数据集的成本,我们提出了一种无监督学习方法,通过使用部分对比和对象聚类与深度图神经网络GNN来学习未标记点云3D对象数据集的特征。在对比度学习步骤中,3D对象数据集中的所有样本被切割成两部分并放入零件数据集中。然后训练对比度学习GNN ContrastNet以验证来自零件数据集的两个随机采样部分是否属于同一对象。在聚类学习步骤中,将经过训练的ContrastNet应用于原始3D对象数据集中的所有样本,以提取用于将样本分组为聚类的特征。然后训练另一个用于聚类学习ClusterNet的GNN来预测所有训练样本的聚类ID。对比学习迫使ContrastNet学习对象的高级语义特征,但可能忽略低级特征,而ClusterNet通过训练发现通过使用集群ID发现可能属于相同语义类别的对象来提高学习特征的质量。我们已经进行了大量实验来评估拟议的点云分类任务框架。所提出的无监督学习方法获得了与使用更复杂的网络结构的现有技术无监督学习方法相当的性能。这项工作的代码可以通过公开获得 |
| Deferred Neural Rendering: Image Synthesis using Neural Textures Authors Justus Thies, Michael Zollh fer, Matthias Nie ner 现代计算机图形管道可以以非凡的视觉质量合成图像,但是,它需要定义良好的高质量3D内容作为输入。在这项工作中,我们探索了不完美3D内容的使用,例如,从具有噪声和不完整表面几何的照片度量重建获得,同时仍然旨在产生照片逼真的渲染。为了解决这个具有挑战性的问题,我们引入了Deferred Neural Rendering,这是一种新的图像合成范例,它将传统的图形管道与可学习的组件相结合。具体来说,我们提出神经纹理,它是作为场景捕捉过程的一部分训练的学习特征地图。与传统纹理类似,神经纹理作为地图存储在3D网格代理之上,但是,高维特征图包含更多信息,可以通过我们新的延迟神经渲染管道进行解释。神经纹理和延迟神经渲染器都是端到端训练,即使原始3D内容不完美,我们也可以合成逼真的图像。与传统的黑盒2D生成神经网络相比,我们的3D表示使我们能够明确控制生成的输出,并允许广泛的应用领域。例如,我们可以合成记录的3D场景的时间一致的视频重新渲染,因为我们的表示固有地嵌入在3D空间中。这样,可以利用神经纹理以实时速率在静态和动态环境中相干地重新渲染或操纵现有视频内容。我们在新视图合成,场景编辑和面部重演的几个实验中展示了我们的方法的有效性,并与利用标准图形管道以及传统生成神经网络的现有技术方法进行了比较。 |
| Domain Agnostic Learning with Disentangled Representations Authors Xingchao Peng, Zijun Huang, Ximeng Sun, Kate Saenko 无监督模型转移有可能极大地提高深度模型对新域的普遍性。然而,目前的文献假设将目标数据分离成不同的域称为先验的。在本文中,我们提出了域不可知学习DAL的任务如何将知识从标记的源域转移到来自任意目标域的未标记数据为了解决这个问题,我们设计了一种新的Deep Adversarial Disentangled Autoencoder DADA,能够从中解析域特定的特征。阶级认同。我们通过实验证明,当目标域标签未知时,DADA在几个图像分类数据集上导致最先进的性能。 |
| An approach to image denoising using manifold approximation without clean images Authors Rohit Jena 图像恢复已成为众多领域中广泛研究的课题。随着深度学习的出现,许多当前的算法被更灵活和更健壮的算法所取代。深度网络已经在各种任务中表现出令人印象深刻的性能,例如盲目去噪,图像增强,去模糊,超分辨率,修复等。大多数这些基于学习的算法在训练过程中使用大量干净的数据。然而,在医学图像处理的某些应用中,人们可能无法访问大量干净的数据。在本文中,我们提出了一种去噪方法,即通过在训练期间仅使用噪声图像将噪声数据推到干净的数据流形附近来尝试学习去噪过程。此外,我们使用感知损失术语和迭代细化步骤来进一步细化干净的图像而不会丢失重要的特征。 |
| Classification and Detection in Mammograms with Weak Supervision via Dual Branch Deep Neural Net Authors Ran Bakalo, Rami Ben Ari, Jacob Goldberger 生成专家注释的高成本对医学成像中的监督机器学习方法提出了很大的限制。弱监督方法可以为这种纠结提供解决方案。在这项研究中,我们提出了一种新的深度学习架构,用于乳房X线照片的多类分类,根据其包含异常的严重程度,在图像上只有一个全局标记。建议的方案进一步允许以全分辨率定位不同类型的发现。新方案包含一个双重分支网络,它将区域级别分类与区域排名相结合。我们在大型多中心乳腺摄影数据集上评估我们的方法,包括具有各种异常的sim 3,000乳房X线照片,并证明了所提出的方法优于先前的弱监督策略的优点。 |
| RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion Authors Muhammad Sarmad, Hyunjoo Jenny Lee, Young Min Kim 我们提出RL GAN Net,其中强化学习RL代理提供对生成对抗性网络GAN的快速且稳健的控制。我们的框架应用于点云形状完成,通过控制GAN将嘈杂的部分点云数据转换为高保真完成形状。虽然GAN不稳定且难以训练,但我们通过在潜在空间表示上训练GAN来避免问题,其中空间表示与原始点云输入相比减小,2使用RL代理来查找到GAN的正确输入生成最适合当前不完整点云输入的形状的潜在空间表示。建议的管道可以完美地完成具有大量缺失区域的点云。据我们所知,这是第一次尝试训练RL代理来控制GAN,这有效地学习了从GAN的输入噪声到点云的潜在空间的高度非线性映射。 RL代理取代了复杂优化的需要,从而使我们的技术实时化。此外,我们证明我们的管道可用于提高缺少数据的点云的分类准确性。 |
| Synthetic Data Generation and Adaption for Object Detection in Smart Vending Machines Authors Kai Wang, Fuyuan Shi, Wenqi Wang, Yibing Nan, Shiguo Lian 本文提出了一种改进的合成图像生成和自适应方案,用于训练深度卷积神经网络CNN,以在智能自动售货机中执行目标检测任务。虽然生成合成数据已被证明对于在监督学习方法中补充训练数据是有效的,但是仍然存在用于生成与复杂真实场景的虚拟图像类似并且最小化冗余训练数据的虚拟图像的挑战。为了解决这些问题,我们考虑模拟放置在虚拟场景中的杂乱对象和用于捕获数据生成过程中整个场景的扭曲的广角摄像机,并使用精心设计的生成网络对生成的图像进行后处理它们更像真实的图像。已经进行了各种实验来证明使用所生成的虚拟图像来提高具有有限的实际训练数据的现有数据集的检测精度的效率以及将训练的网络应用于在新环境中收集的数据集的概括能力。 |
| 3D Dynamic Point Cloud Denoising via Spatio-temporal Graph Modeling Authors Qianjiang Hu, Zehua Wang, Wei Hu, Xiang Gao, Zongming Guo 可访问的深度感测和3D激光扫描技术的普及使得能够方便地获取3D动态点云,其提供运动中任意形状的物体的有效表示。然而,由于硬件,软件或其他原因,动态点云经常受到噪声的干扰。虽然已经提出了许多用于静态点云去噪的方法,但尚未在文献中研究动态点云去噪。因此,我们基于所提出的空间时间图建模来解决该问题,利用帧内相似性和帧间一致性。具体来说,我们首先在图上表示点云序列,并通过定义的补丁上的时空高斯马尔可夫随机场对其进行建模。然后,对于每个目标补丁,我们提出最大后验估计,并通过频谱图理论提出相应的似然和先验函数,利用其在同一帧内的相似补丁和前一帧中的相应补丁。这导致了我们的问题公式,它共同优化了潜在的动态点云和时空图。最后,我们提出了一种有效的补丁构造算法,类似的相应补丁搜索,帧内和帧间图形构造,以及通过交替最小化来优化我们的问题公式。实验结果表明,该方法优于现有技术静态点云去噪方法的逐帧去噪。 |
| Robust subspace clustering by Cauchy loss function Authors Xuelong Li, Quanmao Lu, Yongsheng Dong, Dacheng Tao 子空间聚类是探索高维数据的低维子空间的问题。通过遵循基于谱聚类的方法的模型来设计现有技术方法。这些方法非常注重学习表示矩阵以构造合适的相似矩阵,并忽略噪声项对子空间聚类的影响。然而,实际数据总是被噪声污染,并且噪声通常具有复杂的统计分布。为了缓解这个问题,本文提出了一种基于Cauchy损失函数CLF的子空间聚类方法。特别地,它使用CLF来惩罚噪声项以抑制实际数据中混合的大噪声。这是因为CLF的影响函数具有上限,其可以减轻单个样本(尤其是具有大噪声的样本)对估计残差的影响。此外,我们在理论上证明了我们提出的方法的分组效果,这意味着高度相关的数据可以组合在一起。最后,对五个真实数据集的实验结果表明,我们提出的方法优于几种典型的聚类方法。 |
| X-Ray Image Compression Using Convolutional Recurrent Neural Networks Authors Asif Shahriyar Sushmit, Shakib Uz Zaman, Ahmed Imtiaz Humayun, Taufiq Hasan 随着数字健康革命的出现,每天都在生成,存储和处理大量临床数据。这使得存储和检索大量医疗保健数据,尤其是高分辨率医学图像尤其具有挑战性。因此,医学图像的有效图像压缩在当今的医疗信息系统中起着至关重要的作用,特别是在远程放射学中。在这项工作中,提出了一种基于卷积递归神经网络RNN Conv的X射线图像压缩方法。所提出的架构可以在部署期间提供可变压缩率,同时它要求每个网络仅针对特定维度的X射线图像进行一次训练。该模型使用多级池方案,该方案学习用于有效压缩的上下文特征。我们在美国国立卫生研究院NIH ChestX ray8数据集上进行图像压缩实验,并将所提出的体系结构的性能与最先进的基于RNN的技术和JPEG 2000进行比较。实验结果描述了所提出的改进的压缩性能。结构相似性指数SSIM和峰值信噪比PSNR指标。据我们所知,这是首次报道使用深度卷积RNN进行医学图像压缩的评估。 |
| Spatio-Temporal Filter Adaptive Network for Video Deblurring Authors Shangchen Zhou, Jiawei Zhang, Jinshan Pan, Haozhe Xie, Wangmeng Zuo, Jimmy Ren 由于相机抖动,物体运动和深度变化等引起的空间变化模糊,视频去模糊是一项具有挑战性的任务。现有方法通常估计模糊视频中的光流以对准连续帧或近似模糊核。然而,当估计的光流不准确时,它们倾向于产生伪影或者不能有效地去除模糊。为了克服单独的光流估计的限制,我们提出了一个用于在统一框架中进行对齐和去模糊的空间时间滤波器自适应网络STFAN。所提出的STFAN将前一帧的模糊和恢复图像以及当前帧的模糊图像作为输入,并动态地生成用于对准和去模糊的空间自适应滤波器。然后,我们提出了一种新的滤波器自适应卷积FAC层,以将前一帧的去模糊特征与当前帧对齐,并从当前帧的特征中去除空间变化模糊。最后,我们开发了一个重建网络,它利用两个变换特征的融合来恢复清晰的帧。基准数据集和现实世界视频的定量和定性评估结果表明,所提出的算法在准确性,速度和模型大小方面对现有技术方法表现出良好的效果。 |
| Translate-to-Recognize Networks for RGB-D Scene Recognition Authors Dapeng Du, Limin Wang, Huiling Wang, Kai Zhao, Gangshan Wu 交叉模态转移有助于增强用于场景识别的模态特定判别力。为此,本文提出了一个统一的框架,用于整合交叉模态翻译和模态特定识别的任务,称为翻译识别网络TRecgNet。具体而言,翻译和识别任务共享相同的编码器网络,这允许在翻译的帮助下明确地规范识别任务的训练,从而提高其最终的泛化能力。对于翻译任务,我们将解码器模块放置在编码器网络的顶部,并使用新的分层语义丢失进行优化,而对于识别任务,我们使用基于编码器特征嵌入的线性分类器,其训练由标准的交叉熵损失。此外,我们的TRecgNet允许利用大量未标记的RGB D数据来训练转换任务,从而提高编码器网络的表示能力。根据经验,我们验证这种新的半监督设置能够进一步提高识别网络的性能。我们在两个RGB D场景识别基准NYU Depth v2和SUN RGB D上进行实验,证明TRecgNet实现了与现有技术方法相比的卓越性能,特别是仅基于单一模态的识别。 |
| Hierarchical Recurrent Neural Network for Video Summarization Authors Bin Zhao, Xuelong Li, Xiaoqiang Lu 利用视频帧或子视频之间的时间依赖性对于视频摘要的任务非常重要。实际上,RNN擅长时态依赖建模,并且在许多基于视频的任务(例如视频字幕和分类)中实现了压倒性的性能。然而,RNN不足以处理视频摘要任务,因为传统的RNN(包括LSTM)只能处理短视频,而摘要任务中的视频通常持续时间较长。为了解决这个问题,我们提出了一种用于视频摘要的分层递归神经网络,本文称为H RNN。具体地说,它具有两层,其中第一层用于编码从原始视频剪切的短视频子镜头,并且每个子镜头的最终隐藏状态被输入到第二层,用于计算其作为关键子拍摄的置信度。与传统的RNN相比,H RNN更适合于视频摘要,因为它可以利用帧间的长时间依赖性,同时,计算操作也大大减少。两个流行数据集的结果,包括Combined数据集和VTW数据集,已经证明所提出的H RNN优于现有技术。 |
| Weighted Dark Channel Dehazing Authors Zhu Mingzhu, He Bingwei, Liu Jiantao 在基于暗通道的方法中,局部常数假设被广泛用于使算法可逆。它不可避免地引入缺陷,因为假设不能完全避免深度不连续,同时覆盖足够的像素。不幸的是,由于先验的限制,其仅确认暗物质的存在但没有指定它们的位置或可能性,因此在精修中没有保真度测量可用,因此缺陷被校正或过度校正。在本文中,我们比暗通道理论更深入地克服了这个问题。我们将暗通道的概念分为暗像素和局部常数假设,然后基于新的权重图控制有问题的假设。通过这样的努力,我们的方法显示出质量的显着提高并具有竞争速度。最后,我们表明该方法对初始传输估计非常鲁棒,并且可以通过提供更好的暗像素位置来改进。 |
| Collage Inference: Tolerating Stragglers in Distributed Neural Network Inference using Coding Authors Krishna Giri Narra, Zhifeng Lin, Ganesh Ananthanarayanan, Salman Avestimehr, Murali Annavaram 云计算平台提供的MLaaS ML即服务产品近来越来越受欢迎。预先训练的机器学习模型部署在云上以支持基于预测的应用和服务。为了实现更高的吞吐量,通过在不同机器上同时运行模型的多个副本来提供传入请求。分布式推理中的落后节点的发生率是一个重要问题,因为它可能会增加推理延迟,违反服务的SLO。在本文中,我们提出了一种新的编码推理模型来处理分布式图像分类中的落后者。我们提出改进的单镜头物体检测模型,Collage CNN模型,以有效地提供必要的弹性。拼贴CNN模型拍摄通过组合多个图像作为其输入形成的拼贴图像,并在一次拍摄中执行多图像分类。我们使用来自标准图像分类数据集的图像生成自定义训练拼贴,并训练模型以实现高分类准确性。在云中部署Collage CNN模型,我们证明与基于复制的方法相比,第99百分位延迟可以减少1.45倍至2.46倍,并且不会影响预测准确性。 |
| Human-Centered Emotion Recognition in Animated GIFs Authors Zhengyuan Yang, Yixuan Zhang, Jiebo Luo 作为表达情感的直观方式,动画图形交换格式GIF图像已广泛用于社交媒体。大多数先前关于自动GIF情感识别的研究未能有效利用GIF的独特属性,这可能会限制识别性能。在这项研究中,我们证明了人类相关信息在GIF中的重要性,并通过提出的Keypoint Attended Visual Attention Network KAVAN进行以人为中心的GIF情感识别。该框架由面部注意模块和分层段时间模块组成。面部注意模块利用GIF内容与人物角色之间的强关系,并以人脸为中心提取帧级视觉特征。然后提出分层段LSTM HS LSTM模块以更好地学习全局GIF表示。我们提出的框架优于MIT GIFGIF数据集的最新技术水平。此外,面部注意模块提供可靠的面部区域掩模预测,这提高了模型的可解释性。 |
| Non-Local Context Encoder: Robust Biomedical Image Segmentation against Adversarial Attacks Authors Xiang He, Sibei Yang, Guanbin Li , Haofeng Li, Huiyou Chang, Yizhou Yu 基于深度卷积神经网络的生物医学图像分割的最新进展CNN引起了人们的广泛关注。但是,它对敌对样本的脆弱性不容忽视。本文是第一个发现所有基于CNN的生物医学图像分割模型对对抗性扰动敏感的文章。这限制了这些方法在安全关键生物医学领域的部署。在本文中,我们发现可以利用生物医学图像中的全局空间依赖性和全局上下文信息来抵御对抗性攻击。为此,提出非局部上下文编码器NLCE来模拟短距离和长距离空间依赖性并且编码全局上下文以通过频道注意来加强特征激活。 NLCE模块增强了非本地上下文编码网络NLCEN的稳健性和准确性,NLCEN通过NLCE模块学习强大的增强金字塔特征表示,然后在不同级别上集成信息。对肺和皮肤病变分割数据集的实验已经证明,NLCEN优于任何其他最先进的生物医学图像分割方法以抵抗对抗性攻击。此外,可以应用NLCE模块来提高其他基于CNN的生物医学图像分割方法的稳健性。 |
| Unsupervised and Unregistered Hyperspectral Image Super-Resolution with Mutual Dirichlet-Net Authors Ying Qu, Hairong Qi, Chiman Kwan 高光谱图像HSI提供丰富的光谱信息,有助于成功改善众多计算机视觉任务。然而,它只能以图像空间分辨率为代价来实现。高光谱图像超分辨率HSI SR通过将低分辨率LR HSI与携带更高空间分辨率HR的多光谱图像MSI融合来解决该问题。所有现有的HSI SR方法都需要LR HSI和HR MSI进行良好的登记,并且HR HSI的重建精度在很大程度上依赖于不同模态的配准精度。本文利用HSI SR的未知问题域,无需多模态注册。鉴于未注册的LR HSI和HR MSI具有重叠区域,我们设计了一种独特的无监督学习结构,通过相同的编码器将两个未注册的模态投影到同一统计空间中。进一步采用互信息MI来捕获来自携带空间信息及其原始输入的两个模态的表示之间的非线性统计依赖性。通过最大化MI,可以很好地表征不同模态之间的空间相关性以进一步减少光谱失真。协作l 2,1范数被用作重建误差而不是更常见的l 2范数,从而可以尽可能准确地恢复各个像素。通过这种设计,网络允许从未注册的图像中提取相关的光谱和空间信息,从而更好地保留光谱信息。所提出的方法被称为未注册和无监督的相互Dirichlet Net u 2 MDN。使用基准HSI数据集的广泛实验结果证明了与现有技术相比u 2 MDN的优越性能。 |
| Improved Conditional VRNNs for Video Prediction Authors Lluis Castrejon, Nicolas Ballas, Aaron Courville 预测视频序列的未来帧是具有挑战性的生成建模任务。有希望的方法包括概率潜变量模型,如变分自动编码器。虽然VAE可以处理不确定性并模拟多种可能的未来结果,但它们倾向于产生模糊的预测。在这项工作中,我们认为这是不合适的表现。为了解决这个问题,我们建议增加潜在分布的表现力并使用更高容量的可能性模型。我们的方法依赖于潜在变量的层次结构,它定义了一系列灵活的先验和后验分布,以便更好地模拟未来序列的概率。我们通过一系列消融实验验证了我们的建议,并将我们的方法与现有技术的潜变量模型进行了比较。我们的方法在三个不同数据集中的几个指标下表现良好。 |
| IsMo-GAN: Adversarial Learning for Monocular Non-Rigid 3D Reconstruction Authors Soshi Shimada, Vladislav Golyanik, Christian Theobalt, Didier Stricker 用于来自单眼2D图像的非刚性3D表面回归的大多数现有方法需要在多个帧上的对象模板或点轨迹作为输入,并且仍然远离实时处理速率。在这项工作中,我们提出Isometry Aware Monocular Generative Adversarial Network IsMo GAN是一种从单个图像直接进行3D重建的方法,在轻量级合成数据集上以对抗方式训练变形模型。 IsMo GAN在不同照度,相机姿势,纹理和超过250 Hz的阴影下,从真实图像重建表面。在多个实验中,它在重建精度,运行时间,对未知表面的推广以及对遮挡的鲁棒性方面始终优于多种方法。与现有技术相比,我们将重建误差减少了10 30,包括无纹理的情况,我们的表面定性地表现出更少的人工制品。 |
| A Novel Dual-Lidar Calibration Algorithm Using Planar Surfaces Authors Jianhao Jiao, Qinghai Liao, Yilong Zhu, Tianyu Liu, Yang Yu, Rui Fan, Lujia Wang, Ming Liu 多个激光雷达普遍用于移动车辆,以提供广阔的视野以增强定位和感知系统的性能。然而,由于扫描点中的特征对应性不能总是提供足够的约束,因此多个激光雷达的精确校准是具有挑战性的。为了解决这个问题,现有方法需要场景中的固定校准目标或仅依赖于附加传感器。在本文中,我们提出了一种新方法,可以在没有这些限制的情出现在周围环境中的三个线性独立的平面表面用于找到对应关系。开发了两个组件以确保外部参数被找到用于初始化的闭合形式求解器和用于通过最小化非线性成本函数来细化的优化器。仿真和实验结果证明了我们的校准方法的高精度,旋转和平移误差分别小于0.05rad和0.1m。 |
| Fast Infant MRI Skullstripping with Multiview 2D Convolutional Neural Networks Authors Amod Jog, P. Ellen Grant, Joseph L. Jacobson, Andre van der Kouwe, Ernesta M. Meintjes, Bruce Fischl, Lilla Z llei 颅骨剥离被定义为从全头磁共振图像MRI中分割脑组织的任务。它是神经图像处理管道中的关键组件。下游可变形配准和全脑分割性能高度依赖于准确的颅骨剥离。由于头部和大脑在该年龄范围内的显着大小和形状可变性,因此对于婴儿年龄范围0 18个月的头部MRI图像来说,颅骨剥离是特别具有挑战性的任务。婴儿脑组织的发育也会随着时间的推移改变T 1加权图像的对比度,使得一致的颅骨剥离成为一项艰巨的任务。用于成人脑MRI头部剥离的现有工具不具备处理这些变化的能力,并且需要专门的婴儿MRI头颅剥离算法。在本文中,我们描述了一种监督的头部剥离算法,该算法利用三个训练的完全卷积神经网络CNN,每个算法分别在轴向,冠状和矢状视图中分割2D T 1加权切片。三个视图中的三个概率分割是线性融合和阈值化以产生最终的大脑掩模。我们将我们的方法与现有的成人和婴儿头颅剥皮算法进行了比较,并显示了基于Dice重叠度量平均Dice为0.97的手动标记的地面实况数据集的显着改善。对多个未标记数据集进行标签融合实验表明,我们的方法是一致的,故障模式较少。此外,我们的方法计算速度非常快,NVidia P40 P100 Quadro 4000 GPU上每张图像的运行时间为30秒。 |
| Learning to Fuse Local Geometric Features for 3D Rigid Data Matching Authors Jiaqi Yang, Chen Zhao, Ke Xian, Angfan Zhu, Zhiguo Cao 本文介绍了一种简单但非常有效的数据驱动方法,用于融合3D级刚性数据匹配的低级和高级局部几何特征。通常通过融合来自各种视点或子空间的低级特征来生成独特的几何描述符,或通过利用多个高级特征来增强几何特征匹配。在先前的工作中,它们通常通过诸如串联和最小池化的线性操作来执行。我们表明,通过在三重框架下优化神经网络NN模型可以实现更紧凑和独特的表示,该模型在欧几里德空间中非线性地融合局部几何特征。 NN模型通过改进的三元组损失函数进行训练,该函数完全利用三元组内的所有成对关系。此外,我们的方法的融合描述符也与原始数据的深度学习描述符竞争,同时更轻量级和旋转不变。在具有各种数据模态和应用上下文的四个标准数据集上的实验结果证实了我们的方法在特征匹配和几何配准方面的优势。 |
| Accelerating Proposal Generation Network for \\Fast Face Detection on Mobile Devices Authors Heming Zhang, Xiaolong Wang, Jingwen Zhu, C. C. Jay Kuo 在过去的几十年中,人脸检测是一个广泛研究的问题。最近,通过深度神经网络已经实现了显着的改进,然而,由于其有限的计算能力和存储器,将这些技术直接应用于移动设备仍然是具有挑战性的。在这项工作中,我们提出了一个用于实时人脸检测的提议生成加速框架。更具体地说,我们采用流行的级联卷积神经网络CNN作为基础,然后将我们的加速方法应用于基本框架,以加快模型推理时间。我们的观点是,该框架的计算瓶颈来自提案生成阶段,其中密集图像金字塔的每个级别必须通过网络。在这项工作中,我们通过利用全局和局部面部特征(即全局面部和面部部分)来减少图像金字塔等级的数量。公共基准测试WIDER face和FDDB的实验结果表明,与现有技术相比,它具有令人满意的性能和更快的速度。与速度更快的艺术状态相当的准确性。 |
| ARCHANGEL: Tamper-proofing Video Archives using Temporal Content Hashes on the Blockchain Authors Tu Bui, Daniel Cooper, John Collomosse, Mark Bell, Alex Green, John Sheridan, Jez Higgins, Arindra Das, Jared Keller, Olivier Thereaux, Alan Brown 我们为ARCHANGEL提供了一种新颖的分布式分类帐系统,用于确保数字视频档案的长期完整性。首先,我们描述了一种新颖的深度网络架构,用于计算紧凑的时间内容哈希来自音频视频流的TCH,持续时间为几分钟或几小时。我们的TCH对意外或恶意内容修改篡改敏感,但对用于编码视频的编解码器不变。这是必要的,因为档案馆要求随着时间的推移格式化移动视频以确保将来可访问性。其次,我们描述了如何通过分布在多个独立档案中的权限区块链证明来保护TCH和用于推导它们的模型。我们报告了ARCHANGEL在联合王国,爱沙尼亚和挪威的国家政府档案参与的试验部署中的效力。 |
| Discovering Common Change-Point Patterns in Functional Connectivity Across Subjects Authors Mengyu Dai, Zhengwu Zhang, Anuj Srivastava 本文研究人类大脑功能连通性FC中的变化点,并寻找在相同外部刺激下多个受试者共同的模式。 FC涉及当大脑简单地休息或执行任务时跨越不同脑区域的fMRI反应的相似性。虽然FC的动态性质被广泛接受,但本文开发了一种正式的统计测试,用于找到与FC相关的时间序列中的变化点。它通过对称正定矩阵表示短期连通性,并在该空间上使用黎曼度量来开发用于检测这种矩阵的时间序列中的变化点的图形方法。它还提供了检测到的变化点之间的静止子间隔的估计FC的图形表示。此外,它使用测试统计量的时间对齐,将其视为随时间变化的实际值函数,以消除受试者间的变异性并发现跨受试者的共同变化点模式。使用来自Human Connectome Project HCP数据库的数据来说明该方法用于多个主题和任务。 |
| Recurrent Embedding Aggregation Network for Video Face Recognition Authors Sixue Gong, Yichun Shi, Anil K. Jain, Nathan D. Kalka 循环网络已成功分析时态数据,并已广泛用于视频分析。然而,对于视频人脸识别,其中在大规模数据上训练的基础CNN已经提供了辨别特征,使用长期短期存储器LSTM(一种流行的循环网络),用于特征学习可能导致过度拟合并且降低性能。我们提出了一种用于设置人脸识别的Recurrent Embedding Aggregation Network REAN。与LSTM相比,REAN可以抵抗过度拟合,因为它只学习如何聚合预先训练好的嵌入而不是从头开始学习表示。与质量感知聚合方法相比,REAN可以利用上下文信息来规避冗余视频帧引入的噪声。三个公共领域视频人脸识别数据集IJB S,YTF和PaSC的实证结果表明,所提出的REAN明显优于天真的CNN LSTM结构和质量感知聚合方法。 |
| 3D-SIC: 3D Semantic Instance Completion for RGB-D Scans Authors Ji Hou, Angela Dai, Matthias Nie ner 本文着重于从一个场景的不完整的RGB D扫描完成语义实例的任务,我们的目标是检测构成场景的各个对象实例并共同推断它们的完整对象几何。这使得扫描场景的语义上有意义的分解成单独的,完整的3D对象。 3D场景的这种语义实例完成为实现与场景的有意义的交互开辟了许多新的可能性,例如对于虚拟或机器人代理。我们提出了3D SIC,一种新的端到端3D卷积神经网络,它不是单独考虑3D语义实例分割和扫描完成,而是联合学习检测对象实例并预测其完整几何结构,与独立处理这些任务相比,可以获得明显更好的性能。 3D SIC利用联合颜色几何特征学习和完全卷积3D网络来有效地推断大规模3D扫描的语义实例完成。我们的方法以交互速率运行,在30米25米空间范围的场景上花费几秒推断时间。对于语义实例完成的任务,我们还在实际扫描数据上引入了一个新的语义实例完成基准,在mAP 0.5中我们的替代方法超过15。 |
| Relevant features for Gender Classification in NIR Periocular Images Authors Ignacio Viedma, Juan Tapia, Andres Iturriaga, Christoph Busch 来自NIR图像的大多数性别分类方法都使用了虹膜信息。最近的工作已经探索了整个眼周虹膜区域的使用,这令人惊讶地取得了更好的效果。这表明,性别分类的最相关信息并不像预期的那样位于虹膜中。在这项工作中,我们分析和展示了在眼周NIR图像中描述性别的最相关特征的位置,并评估其影响其分类。实验表明,眼周区域比虹膜区域包含更多的性别信息。我们提取了几个特征强度,纹理和形状,并使用XgBoost算法根据其相关性对它们进行分类。使用最相关的功能时,支持向量机和九个集成分类器用于测试性别准确性。当使用位于眼周区域的4,000个特征时获得最佳分类结果89.22。进行了完整的眼周虹膜图像与虹膜闭塞图像的其他实验。获得的性别分类率分别为84.35和85.75。我们还通过新的数据库UNAB Gender为最新技术做出贡献。从结果来看,我们建议只关注虹膜的周围区域。这使我们能够从NIR眼周图像中实现更快的性别分类。 |
| Unsupervised Data Augmentation Authors Qizhe Xie, Zihang Dai, Eduard Hovy, Minh Thang Luong, Quoc V. Le 尽管取得了成功,深度学习仍然需要大型标记数据集才能成功。数据增加在减少对更多标记数据的需求方面显示出很大的希望,但到目前为止,它主要应用于监督环境并获得有限的收益。在这项工作中,我们建议在半监督学习环境中将数据增强应用于未标记的数据。我们的方法,名为Unsupervised Data Augmentation或UDA,鼓励模型预测在未标记的示例和增强的未标记示例之间保持一致。与以前使用随机噪声(如高斯噪声或辍学噪声)的方法不同,UDA有一个小的转折,因为它利用了最先进的数据增强方法产生的更难和更逼真的噪声。即使标记集非常小,这种小扭曲也会导致六种语言任务和三种视觉任务的实质性改进。例如,在IMDb文本分类数据集中,仅有20个标记示例,UDA优于在25,000个标记示例上训练的现有技术模型。在标准的半监督学习基准测试中,CIFAR 10包含4,000个示例,SVHN包含1,000个示例,UDA优于所有先前的方法,并且将现有技术方法的错误率降低了30多个,分别从7.66到5.27,从3.53降低到2.46。 UDA也适用于具有大量标记数据的数据集。例如,在ImageNet上,使用130万额外的未标记数据,与AutoAugment相比,UDA将前5个准确度从78.28 94.36提高到79.04 94.45。 |
| Adversarial Training for Free! Authors Ali Shafahi, Mahyar Najibi, Amin Ghiasi, Zheng Xu, John Dickerson, Christoph Studer, Larry S. Davis, Gavin Taylor, Tom Goldstein 对抗训练,其中网络训练对抗的例子,是抵御强大攻击的对抗性攻击的少数防御之一。遗憾的是,产生强大对抗性示例的高成本使标准对抗训练对像ImageNet这样的大规模问题不切实际。我们提出了一种算法,通过循环更新模型参数时计算的梯度信息,消除了生成对抗性示例的开销成本。我们的免费对抗训练算法在CIFAR 10和CIFAR 100数据集上实现了最先进的稳健性,与自然训练相比,其成本可以忽略不计,并且比其他强大的对抗训练方法快7到30倍。使用具有4个P100 GPU的单个工作站和2天的运行时间,我们可以为大规模ImageNet分类任务训练一个强大的模型,该任务可以保持40个准确性以抵抗PGD攻击。 |
| TileGAN: Synthesis of Large-Scale Non-Homogeneous Textures Authors Anna Fr hst ck, Ibraheem Alhashim, Peter Wonka 我们在给出许多输入图像并且需要大规模输出的设置中解决纹理合成的问题。我们建立在最近的生成对抗网络上,并在本文中提出了两个扩展。首先,我们提出了一种算法,用于组合在较小分辨率上训练的GAN的输出,以产生几乎没有边界伪影的大规模似真的纹理图。其次,我们提出了一个用户界面来实现艺术控制。我们的定量和定性结果展示了由高达数百万像素组成的合成高分辨率地图的生成。 |
| A Deep-Learning Algorithm for Thyroid Malignancy Prediction From Whole Slide Cytopathology Images Authors David Dov, Shahar Ziv Kovalsky, Jonathan Cohen, Danielle Elliott Range, Ricardo Henao, Lawrence Carin 我们考虑从超高分辨率全幻灯片细胞病理学图像预测甲状腺恶性肿瘤。我们提出了一种基于深度学习的算法,其灵感来自细胞病理学家诊断幻灯片的方式。该算法识别诊断相关的图像区域并将它们分配给局部恶性分数,然后将其纳入全局恶性肿瘤预测中。我们讨论了基于深度学习的方法与多实例学习MIL之间的关系,并通过使用监督程序从整个幻灯片中提取相关区域来描述它如何偏离传统的MIL方法。对我们算法的分析进一步揭示了与假设检验的密切关系,假设检验与甲状腺细胞病理学的独特特征一起,使我们能够设计出改进的培训策略。我们进一步提出了用于同时预测甲状腺恶性肿瘤的序数回归框架和作为正则化器的有序诊断评分,这进一步改善了网络的预测。实验结果表明,该算法优于多种竞争方法,实现了与人类专家相媲美的性能。 |
| Self Training Autonomous Driving Agent Authors Shashank Kotyan, Danilo Vasconcellos Vargas, Venkanna U 从本质上讲,驾驶是马尔可夫决策过程,非常适合强化学习范式。在本文中,我们提出了一种新的代理人,它学会驾驶车辆而无需任何人工辅助。我们使用强化学习和进化策略的概念来训练我们的代理人在2D模拟环境中。我们的模型架构通过在自动编码器中引入差异图像超越了世界模型。这种在自动编码器中的差异图像的新颖参与使得潜在空间相对于车辆的运动更好地表示,并且帮助自主代理更有效地学习如何驾驶车辆。结果表明,与原始结构相比,我们的方法所需的总代理数减少了96个,每代代理减少了87.5个代,减少了70代,减少了90个,同时实现了与原始结构相同的精度。 |
| Registration of retinal images from Public Health by minimising an error between vessels using an affine model with radial distortions Authors Guillaume Noyel IPRI, SIGPH iPRI , R Thomas, S Iles DESW , G Bhakta DESW , A Crowder DESW , D. Owens, P. Boyle IPRI, SIGPH iPRI 为了估计由亲和力和两个径向畸变构成的眼底图像的配准模型,我们引入了基于血管之间误差的估计标准。在1中,我们通过最小化特征点之间的误差来估计该模型。在本文中,使用从我们的模型推导出的重叠区域边界的圆和椭圆方程来选择检测到的血管。我们的方法成功地将271对中的96对记录在主要使用不同摄像机获取的公共卫生数据集中。这比我们先前的方法1更好,并且优于其他三种现有技术方法。在公开可用的数据集上,我们仍然比参考方法更好地注册图像。 |
| Multi-scale Microaneurysms Segmentation Using Embedding Triplet Loss Authors Mhd Hasan Sarhan, Shadi Albarqouni, Nassir Navab, Abouzar Eslami 深度学习技术最近被用于眼底图像分析和糖尿病视网膜病变检测。微动脉瘤是糖尿病视网膜病变进展的重要指标。我们介绍了一种两阶段深度学习方法,用于微动脉瘤分割,使用多种输入量表,选择性采样和嵌入三联体丢失。模型首先在两个尺度上进行分割,然后使用分类模型细化分割。为了增强分类模型的判别力,我们将三重嵌入损失与选择性采样程序结合起来。定量评估模型以评估分割性能并定性地分析模型预测。与完全卷积神经网络相比,这种方法引入了30.29的相对改进。 |
| Current Trends in Eye Tracking Research in Mathematics Education: A PME Literature Review Authors Achim J. Lilienthal, Maike Schindler 眼动追踪ET是一种研究方法,对数学教育研究MER越来越感兴趣。本文旨在提供文献综述,特别关注该技术,ET设备和数学教育中使用的分析方法的兴趣演变。为了捕捉当前状态,我们关注过去十年中PME(一个专门针对MER的主要会议)的会议记录中发表的论文。我们确定社区中使用的兴趣,方法和分析方法的趋势,并讨论可能的未来发展。 |
| Mixture of Pre-processing Experts Model for Noise Robust Deep Learning on Resource Constrained Platforms Authors Taesik Na, Minah Lee, Burhan A. Mudassar, Priyabrata Saha, Jong Hwan Ko, Saibal Mukhopadhyay 由于功率预算不断减少,对边缘设备的深度学习需要节能运行。数据采集期间的故意低质量数据可延长电池寿命,低成本传感器产生的自然噪声会降低目标输出的质量,从而阻碍边缘设备采用深度学习。为了克服这些问题,我们提出简单而有效的预处理专家MoPE模型混合处理各种图像失真,包括低分辨率和噪声图像。我们还建议使用经过对侧训练的自动编码器作为噪声图像的预处理专家。我们评估了我们提出的各种机器学习任务的方法,包括MS COCO 2014数据集上的对象检测,MOT Challenge数据集上的多个对象跟踪问题,以及UCF 101数据集上的人类活动分类。实验结果表明,该方法在不影响清晰图像精度的情况下,在噪声下实现了更好的检测,跟踪和活动分类精度。与基线对象检测网络相比,我们提出的MoPE的开销在内存和计算方面分别为0.67和0.17。 |
| Attentive Adversarial Learning for Domain-Invariant Training Authors Zhong Meng, Jinyu Li, Yifan Gong 对抗域不变训练ADIT证明在抑制声学建模中的域可变性的影响方面是有效的,并且已经导致自动语音识别ASR中的性能改善。在ADIT中,辅助域分类器从深度神经网络DNN声学模型中获取相同加权的深度特征,并且通过优化对抗性损失函数来训练以改善其域不变性。在这项工作中,我们提出了一个细心的ADIT AADIT,其中我们使用注意机制推进域分类器,以根据它们在域分类中的重要性自动加权输入深度特征。通过这种细心的重新加权,AADIT可以专注于对域变异性更敏感的语音成分的域规范化,并生成具有改进的域不变性和与ADIT相比的Senone判别性的深度特征。最重要的是,注意块仅作为DNN声学模型的外部组件,不参与ASR,因此AADIT可用于改进任何DNN架构的声学建模。更一般地,相同的方法可以通过辅助鉴别器改进任何对抗性学习系统。在CHiME 3数据集上进行评估,AADIT分别在多条件模型和强ADIT基线上实现了13.6和9.3的相对WER改进。 |
| Conditional Teacher-Student Learning Authors Zhong Meng, Jinyu Li, Yong Zhao, Yifan Gong 已经证明,教师学生T S学习对于诸如领域适应和模型压缩等各种问题是有效的。 T S学习的一个缺点是,教师模型并不总是完美的,偶尔会以后验概率的形式产生错误的指导,误导学生模型的性能欠佳。为了克服这个问题,我们提出了一种条件性T S学习方案,其中聪明的学生模型选择性地选择教师模型或基于教师是否能够正确预测基本事实的地面真实标签。与两种知识源的幼稚线性组合不同,当教师模型的预测是正确的时,条件学习专门与教师模型接触,否则回到基本事实。因此,学生模型能够有效地从老师那里学习,甚至可能超过老师。我们研究了关于CHiME 3数据集上的两个任务领域适应和微软短消息听写数据集上的说话人适应的建议学习方案。所提出的方法相对于用于环境适应的T S学习和用于说话者自适应的说话者无关模型分别实现9.8和12.8相对字错误率降低。 |
| TMIXT: A process flow for Transcribing MIXed handwritten and machine-printed Text Authors Fady Medhat, Mahnaz Mohammadi, Sardar Jaf, Chris G. Willcocks, Toby P. Breckon, Peter Matthews, Andrew Stephen McGough, Georgios Theodoropoulos, Boguslaw Obara 处理大型文档在许多领域都具有重要意义,尤其是在犯罪调查和防御领域,在这些领域中,组织可能会被提供大量需要在有限时间内处理的扫描文档。然而,就扫描文档的卷和需要处理的页面的复杂性而言,这个问题更加严重。通常包含许多不同的元素,每个元素都需要被处理和理解。文本识别是这个过程的主要任务,通常取决于文本的类型,可以手写或机器打印。因此,在决定要应用的识别方法之前,识别涉及文本类别的在先分类。如果文档包含手写和机器打印文本,则这将带来更具挑战性的任务。在这项工作中,我们提供了一个通用的流程,用于在包含混合手写和机器打印文本的扫描文档中进行文本识别,而无需事先对文本进行分类。我们使用几个开源图像处理和文本识别包1实现了所提出的流程。评估是使用IAM手写数据库中的专门开发的变体进行的,我们对包含打印和手写文本的页面的平均转录精度接近80。 |
| Analysis of Confident-Classifiers for Out-of-distribution Detection Authors Sachin Vernekar, Ashish Gaurav, Taylor Denouden, Buu Phan, Vahdat Abdelzad, Rick Salay, Krzysztof Czarnecki 只有当输入数据来自分布中的训练分布时,才能信任经过判别训练的神经分类器。因此,检测出分布OOD样本对于避免分类错误非常重要。在用于图像分类的OOD检测的背景下,最近的方法之一提出通过最小化分布样本中的标准交叉熵损失并且最小化低密度区域中OOD样本的预测分布之间的KL偏差来训练称为置信分类器的分类器。分布和均匀分布最大化输出的熵。因此,如果样品具有低置信度或高熵,则可以将样品检测为OOD。在本文中,我们从理论上和实验上分析了这个设置。我们得出结论,由此产生的自信分类器仍然会对远离分布的OOD样本产生任意高的置信度。我们建议通过为OOD样本添加显式拒绝类来训练分类器。 |
| Missing MRI Pulse Sequence Synthesis using Multi-Modal Generative Adversarial Network Authors Anmol Sharma, Ghassan Hamarneh 磁共振成像MRI越来越多地用于评估,诊断和计划各种疾病的治疗。在单次扫描中以MR脉冲序列的形式在不同对比中可视化组织的能力为医生提供了有价值的见解,并且使得自动化系统能够执行下游分析。然而,诸如禁止扫描时间,图像损坏,不同采集协议或对某些对比材料过敏的许多问题可能妨碍为患者获取多个序列的过程。这给医生和自动化系统带来了挑战,因为缺失序列提供的补充信息会丢失。在本文中,我们提出了生成性对抗性网络GAN的变体,其能够利用多个可用序列中包含的冗余信息,以便为患者扫描生成一个或多个缺失序列。所提出的网络被设计为多输入多输出网络,其组合来自所有可用脉冲序列的信息,隐含地推断缺少哪些序列,并在单个正向通路中合成丢失的序列。我们在具有四个序列的两个脑MRI数据集上演示和验证我们的方法,并且显示所提出的方法在任何可能的情况下同时合成所有缺失序列的适用性,其中四个序列中的一个,两个或三个可能缺失。我们将我们的方法与竞争的单峰和多模态方法进行比较,并表明我们在数量和质量上都表现优异。 |
| Dynamic Mini-batch SGD for Elastic Distributed Training: Learning in the Limbo of Resources Authors Haibin Lin, Hang Zhang, Yifei Ma, Tong He, Zhi Zhang, Sheng Zha, Mu Li 随着对深度学习算法的训练能力和数据中心中计算资源的快速增长的需求的增加,期望动态地调度不同的分布式深度学习任务以最大化资源利用并降低成本。在这个过程中,不同的任务可能在不同的时间接收不同数量的机器,我们称之为弹性分布式训练。尽管最近在大型小批量分布式训练中取得了成功,但这些方法很少在弹性分布式训练环境中进行测试,并且当我们相对于批量大小立即线性调整学习速率时,我们的实验中的性能会降低。我们观察到的一个困难是随机动量估计中的噪声随着时间的推移而累积,并且当批量大小改变时将具有延迟效应。因此,我们建议随着时间的推移平滑地调整学习率以减轻噪声动量估计的影响。我们在图像分类,目标检测和语义分割方面的实验表明,我们提出的动态SGD方法在将GPU的数量从8变为128时实现了稳定的性能。我们还提供了关于线性学习速率调度的最优性和理论的理论。随机动量。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pixels.com