【今日CV 计算机视觉论文速览 第150期】Fri, 2 Aug 2019
今日CS.CV 计算机视觉论文速览
Fri, 2 Aug 2019
Totally 45 papers
?上期速览✈更多精彩请移步主页

Interesting:
?深度学习框架Chainer, Chainer是由日本PreferredNetworks公司推出的一套深度学习框架,支持各领域深度学习研究和应用开发的高性能实现。内部提供了与Numpy类似的API,通过CuPy来调用GPUs的运算能力,支持通用和动态图模型,并提供了计算机视觉和分布式训练的强大功能包。(from Preferred Networks, Inc, JP)
静态图与动态度的区别:

CuPy显卡加速工具包:
安装pip install chainer
一个简单的程序Demo:

# copy from:https://docs.chainer.org/en/stable/examples/cnn.html
import chainer.links as L
import chainer.functions as F
class LeNet5(Chain): #继成Chain类
def __init__(self):
super(LeNet5, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(
in_channels=1, out_channels=6, ksize=5, stride=1)
self.conv2 = L.Convolution2D(
in_channels=6, out_channels=16, ksize=5, stride=1)
self.conv3 = L.Convolution2D(
in_channels=16, out_channels=120, ksize=4, stride=1)
self.fc4 = L.Linear(None, 84)
self.fc5 = L.Linear(84, 10) #定义各种操作函数
def forward(self, x): #定义序列模型,前向传播函数
h = F.sigmoid(self.conv1(x))
h = F.max_pooling_2d(h, 2, 2)
h = F.sigmoid(self.conv2(h))
h = F.max_pooling_2d(h, 2, 2)
h = F.sigmoid(self.conv3(h))
h = F.sigmoid(self.fc4(h))
if chainer.config.train:
return self.fc5(h)
return F.softmax(self.fc5(h))
##-----------也可以直接调用Chain的API来使用----------##
import chainer.links as L
from functools import partial
class LeNet5(Chain):
def __init__(self):
super(LeNet5, self).__init__()
net = [('conv1', L.Convolution2D(1, 6, 5, 1))]
net += [('_sigm1', F.sigmoid)]
net += [('_mpool1', partial(F.max_pooling_2d, ksize=2, stride=2))]
net += [('conv2', L.Convolution2D(6, 16, 5, 1))]
net += [('_sigm2', F.sigmoid)]
net += [('_mpool2', partial(F.max_pooling_2d, ksize=2, stride=2))]
net += [('conv3', L.Convolution2D(16, 120, 4, 1))]
net += [('_sigm3', F.sigmoid)]
net += [('_mpool3', partial(F.max_pooling_2d, ksize=2, stride=2))]
net += [('fc4', L.Linear(None, 84))]
net += [('_sigm4', F.sigmoid)]
net += [('fc5', L.Linear(84, 10))]
net += [('_sigm5', F.sigmoid)]
with self.init_scope():
for n in net:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
self.layers = net #直接定义前传的操作序列
## 注,定义模型也可以使用Sequential的形式:https://docs.chainer.org/en/stable/reference/generated/chainer.Sequential.html#chainer.Sequential
def forward(self, x): #前向传播函数
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f(x)
if chainer.config.train:
return x
return F.softmax(x)
最后定义损失函数即可:
model = LeNet5()
# Input data and label
x = np.random.rand(32, 1, 28, 28).astype(np.float32)
t = np.random.randint(0, 10, size=(32,)).astype(np.int32)
# Forward computation
y = model(x) #预测结果
# Loss calculation
loss = F.softmax_cross_entropy(y, t) #交叉熵结果
Docs:https://docs.chainer.org/en/stable/
Website:https://chainer.org/
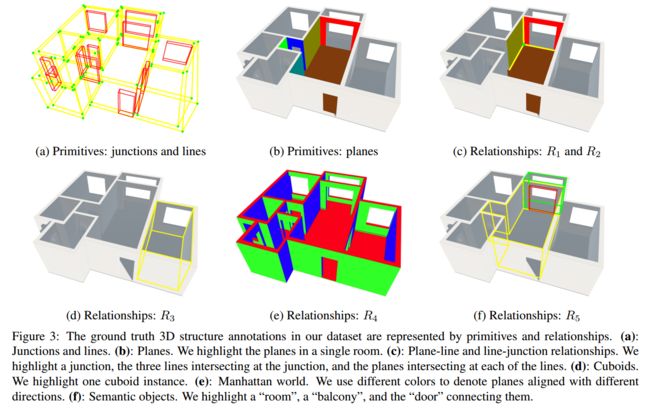
?Structured3D三维结构化数据集, 研究人员提出了一个大规模的逼真的撒那威结构标注数据集,适用于多种三维结果建模任务。研究人员使用大量的室内设计模型来抽取结构,并利用渲染引擎生成了高质量的图像。最后在合成数据集上进行了房屋布局估计任务来验证了数据集的有效性。数据集中包含了3500个场景的21835个房间,以及196k个渲染后的图像.(from 上海科技大学)
数据集中包含的结果,包括二维平面三维立体、节点、框架、平面、语义,以及各种光照条件下的信息和分割标签:

与已有数据集的比较:

数据集中的各种单元和对应关系,包括节点和线、平面、平面与线平面与节点的关系、六面体的实例、曼哈顿:
室内家装数据集的比较以及几种不同的全景数据集:


参考,一些现有的数据集,只针对一个或者几个角度,覆盖不全,规模不大:
(a) Plane [12] (b) Wireframe [9] © Cuboid [7]
(d) Room layout [33] (e) Floorplan [14]
(f) Abstracted 3D shape (wireframe [25] and cuboid [22])
2https://github.com/zouchuhang/LayoutNet
3https://github.com/sunset1995/HorizonNet
Planner 5d. https://planner5d.com.
曼哈顿场景,所有的平面都指向主方向xyz
Manhattan World Assumption
Manhattan-world stereo
Manhattan-World Stereo website
code:https://structured3d-dataset.org/
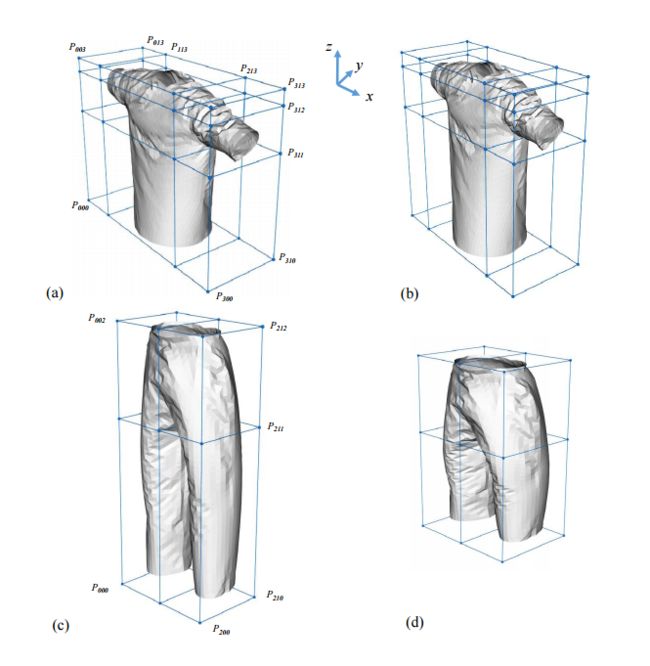
?基于RGB数据的多形态三维虚拟衣物建模, 这种方法不需要模特或者人体模型,只需要前景和背景两张图就可生成三维虚拟的衣服模型,适应模特、人体模型设置是平面铺开的各种场景。为了构建衣物模型,研究人员构建JFNet多任务模型同时预测衣物的标志点和图像中衣服的语义区域。预测出的语义点用于估计衣物大小、随后衣服的网格模型将基于大小信息进行变形得到最后的衣服状态模型、语义信息则用于抽取材质和颜色。 (from OPPO JD 北卡)

一些语义标记的样本(主要基于DeepLabV3+和孔卷积Atrous Spatial Pyramid Pool ,ASPP实现语义分割):

关键点和分割多任务检测的模型JFNet如下如所示,下半部分实现了低层信息的迭代优化应用,上半部则使用了多尺度:

文章中使用的T恤和裤子mesh模板,以及变形的过程:

最后得到的结果如下:
?++++DIODE室内室外深度数据集,包含rgb.deep和normal信息, 包含了上千个多场景的高精度稠密大深度测量数据,利用了多传感器进行多域测量,利用FARO Focus S350
scanner扫描和RGB数据。(from TTI–Chicago 芝加哥大学 北航)
数据包含了RGB、深度图以及法向量图:
ref:Matterport3D [2] and ScanNet [3] NYUv2 dataset [14] Make3D [13] KITTI [7].
采集设备法罗全站仪:

FARO™ S350 scanner:https://www.faro.com/products/construction-bim-cim/faro-focus/
http://www-news.uchicago.edu/releases/02/020326.toyota.shtml
丰田技术研究院at芝加哥大学:https://www.ttic.edu/
https://twitter.com/TTIC_Connect
Greg Shakhnarovich Group:https://ttic.uchicago.edu/~gregory/
https://ttic.uchicago.edu/~mostajabi/ https://ttic.uchicago.edu/~rluo/ http://xksteven.com/resources/CV/
dataset:https://ivasiljevic.github.io/
?批归一化与组归一化的系统性研究, 批归一化是深度学习中常用的正则化方法,每一个批中的统计上不确定性可以作为正则化,但特定的训练数据会损害任务的泛化性。组归一化GroupNormalization表现出了更好的性能,在归一化后使用了学习到的仿射变换来增加模型的表达能力。这些变换是可学习的条件计算函数。这篇文章的目的在于探索在组归一化中条件信息在什么位置起作用,并改进了模型的泛化性。研究人员在视觉问答、小样本学习和条件图像生成上进行了测试。(from 蒙特利尔大学等)
Daily Computer Vision Papers
| Two-Stream Video Classification with Cross-Modality Attention Authors Lu Chi, Guiyu Tian, Yadong Mu, Qi Tian 已知融合多模态信息能够有效地带来视频分类的显着改进。然而,到目前为止最流行的方法仍然只是在最后阶段融合每个流的预测分数。一个有效的问题是,是否存在一种更有效的融合信息交叉方式的方法。随着自然语言处理中注意机制的发展,计算机视觉领域出现了许多成功的应用。在本文中,我们提出了一种跨模态注意操作,它可以比两个流更有效地从其他模态获取信息。相应地,我们实现了一个名为CMA块的兼容块,它是我们提出的注意操作的包装器。 CMA可以插入许多现有架构中。在实验中,我们将我们的方法与广泛用于视频分类的两个流和非局部模型进行了全面的比较。所有实验都清楚地表明我们提出的方法具有很强的性能优势我们还通过可视化注意力图来分析CMA块的优势,该注意力图直观地显示了块如何帮助最终预测。 |
| Learning to Adapt Invariance in Memory for Person Re-identification Authors Zhun Zhong, Liang Zheng, Zhiming Luo, Shaozi Li, Yi Yang 这项工作考虑了人工重新识别的无监督域适应问题,其目的是将知识从源域转移到目标域。现有方法是减少域之间的域间移位的主要方法,然而这通常忽略了目标样本之间的关系。本文研究了目标域的域内变异,并提出了一个新的适应框架w.r.t.三种类型的潜在不变性,即范例不变性,相机不变性和邻域不变性。具体而言,引入示例性存储器来存储样本的特征,其可以有效且高效地实施对全局数据集的不变性约束。我们进一步提出基于图的正预测GPP方法来探索目标域的可靠邻域,其建立在存储器上并且在源样本上训练。实验表明,三个不变性属性对于有效的域自适应是必不可少的,2记忆在实现不变性学习中起着关键作用,并且在有限的额外计算成本的情况下提高了性能,3 GPP可以促进不变性学习,从而显着改善结果,我们的方法在三个ID大规模基准测试中产生了新的最新适应精度。 |
| ++基于点框架的三维分割A Unified Point-Based Framework for 3D Segmentation Authors Hungyueh Chiang, Yenliang Lin, Yuehcheng Liu, Winston H. Hsu 对于无结构和无纹理区域,3D点云分割仍然具有挑战性。我们提出了一种新的基于统一点的3D点云分割框架,可有效优化整个场景的像素级特征,几何结构和全局背景先验。通过将2D图像特征反投影到3D坐标中,我们的网络在统一的框架中学习2D纹理外观和3D结构特征。此外,我们在获得更好的预测之前研究全局背景。我们在ScanNet在线基准测试中评估我们的框架,并表明我们的方法优于几种最先进的方法。我们探索在3D重建场景中合成相机姿势以获得更高的性能。对特征组合和合成相机姿态的深入分析验证了来自不同模态的特征相互益处,并且密集的相机姿势采样进一步改善了分割结果。 |
| ++综述小样本生物图像分析A Survey on Deep Learning of Small Sample in Biomedical Image Analysis Authors Pengyi Zhang, Yunxin Zhong, Yulin Deng, Xiaoying Tang, Xiaoqiong Li 由于端到端学习框架和大规模标记样本的可用性,深度学习的成功已经被证明是用于计算机辅助生物医学图像分析的有前途的技术。然而,在许多生物医学图像分析的情况下,深度学习技术受到小样本学习SSL困境的困扰,主要是由于缺乏注释。为了更加实用于生物医学图像分析,在本文中,我们通过结合计算机视觉应用中相关技术的发展,调查了有助于减轻深度学习痛苦的关键SSL技术。为了加速基于深度学习技术的生物医学图像分析的临床应用,我们有意扩展该调查,以包括对临床决策重要的深度模型的解释方法。我们通过将关键SSL技术分为五类1解释技术,2种弱监督学习技术,3种转移学习技术,4种主动学习技术和5种涉及数据增强,领域知识,传统浅层方法和注意机制的各种技术来调查关键SSL技术。这些关键技术有望支持深度学习在临床生物医学图像分析中的应用,并进一步提高分析性能,特别是在没有大规模注释样本时。我们在演出中进行了演示 |
| +++室内外深图数据集DIODE: A Dense Indoor and Outdoor DEpth Dataset Authors Igor Vasiljevic, Nick Kolkin, Shanyi Zhang, Ruotian Luo, Haochen Wang, Falcon Z. Dai, Andrea F. Daniele, Mohammadreza Mostajabi, Steven Basart, Matthew R. Walter, Gregory Shakhnarovich 我们介绍了DIODE,这是一个包含数千种不同高分辨率彩色图像的数据集,具有精确,密集,长距离的深度测量。 DIODE Dense Indoor Outdoor DEpth是第一个包含一个传感器套件获得的室内和室外场景RGBD图像的公共数据集。这与仅关注一种域场景类型并使用不同传感器的现有数据集形成对比,使得跨域的泛化变得困难。 |
| Learning Densities in Feature Space for Reliable Segmentation of Indoor Scenes Authors Nicolas Marchal, Charlotte Moraldo, Roland Siegwart, Hermann Blum, Cesar Cadena, Abel Gawel 深度学习使语义分割和场景理解取得了显着进步。然而,引入新的元素(称为分布式OoD数据)会降低现有方法的性能,这些方法通常仅限于一组固定的类。这是一个问题,因为自主代理将不可避免地遇到各种各样的对象,所有这些对象在训练期间都不能包括在内。我们提出了一种在室内环境中区分任何物体前景与空建筑结构背景的新方法。我们使用归一化流来估计高维背景描述符的概率分布。因此,前景对象被检测为图像中的区域,对于该区域,对于背景分布,描述符不太可能。由于我们的方法没有明确地学习单个对象的表示,因此其性能在训练示例之外很好地概括。我们的模型产生了一种创新的解决方案,可以在室内场景中可靠地分割前景,从而为在人类环境中更安全地部署机器人开辟了道路。 |
| Moulding Humans: Non-parametric 3D Human Shape Estimation from Single Images Authors Valentin Gabeur, Jean Sebastien Franco, Xavier Martin, Cordelia Schmid, Gregory Rogez 在本文中,我们从单个RGB图像中解决了3D人体形状估计的问题。虽然卷积神经网络的最新进展已经为3D人体姿态估计提供了令人印象深刻的结果,但估计人的完整3D形状仍然是一个悬而未决的问题。基于模型的方法可以在布料人体下输出裸露的精确网格,但无法估计细节和未建模的元素,如头发或衣服。另一方面,非参数体积方法可以潜在地估计完整的形状,但实际上,它们受到输出网格分辨率的限制,并且不能产生详细的估计。在这项工作中,我们提出了一种非参数方法,它采用双深度图来表示人的3D形状,估计和组合可见深度图和隐藏深度图,以重建人体3D形状,就像用模具完成一样。通过2D深度图的这种表示允许具有比基于体素的体积表示低得多的尺寸的更高分辨率输出。此外,我们完全可导出的基于深度的模型允许我们以对抗方式有效地结合鉴别器,以提高3D输出的准确性和人性。我们对SURREAL和3D HUMANS进行了培训和定量验证,这是一种新的照片级真实数据集,由半合成内部视频和3D地面实况表面注释而成。 |
| ++基于Mask R-CNN图像中的人类融合与抽取Extract and Merge: Merging extracted humans from different images utilizing Mask R-CNN Authors Asati Minkesh, Kraisittipong Worranitta, Miyachi Taizo 从图像中的各种类型的对象中选择人物对象并将它们与其他场景合并是手动和照片编辑器的日常工作。虽然最近Adobe Photoshop发布了选择主题工具,它自动选择图像中的前景对象,但仍然需要单独进行精细的手动调整。在这项工作中,我们提出了一个利用Mask R CNN进行物体检测和遮罩分割的应用程序,它可以从多个图像中提取人体实例并将它们与新背景合并。此应用程序不会向Mask R CNN添加任何开销,以每秒5帧的速度运行。它可以从任意数量的图像或视频中提取人类实例,将它们合并在一起。我们还构建了代码以接受不同长度的视频作为输入,输出视频的长度将等于最长的输入视频。我们想要创建一个简单而有效的应用程序,它可以作为照片编辑的基础,并自动完成大部分时间的工作,因此,编辑人员可以更专注于设计部分。其他应用可以是在一张图片中将人们聚集在一起,来自不同图像的新背景,这些图像不能在一起。我们在两个不同的背景下展示单人和多人提取和放置。此外,我们正在展示一个单人提取的视频示例。 |
| +++三维语义场景补全Cascaded Context Pyramid for Full-Resolution 3D Semantic Scene Completion Authors Pingping Zhang, Wei Liu, Yinjie Lei, Huchuan Lu, Xiaoyun Yang 语义场景完成SSC旨在同时预测3D场景的体积占用和语义类别。它有助于智能设备理解周围场景并与之交互。由于高内存要求,当前方法仅产生低分辨率完成预测,并且通常丢失对象细节。此外,他们还忽略了多尺度空间背景,这对于3D推理起着至关重要的作用。为了解决这些问题,我们在这项工作中提出了一种新的深度学习框架,名为Cascaded Context Pyramid Network CCPNet,用于从单个深度图像中联合推断体积3D场景的占用和语义标签。提议的CCPNet通过级联上下文金字塔提高了标签的一致性。同时,基于低级特征,它使用Guided Residual Refinement GRR模块逐步恢复对象的精细结构。我们提出的框架具有三个突出的优点1它明确地模拟3D空间背景以提高性能2全分辨率3D体积通过结构保留细节生成3具有低内存要求的轻量级模型以良好的可扩展性捕获。大量实验表明,尽管采用单一视图深度图,我们提出的框架可以生成高质量的SSC结果,并且在合成的SUNCG和真实的NYU数据集上都优于最先进的方法。 |
| Central Similarity Hashing via Hadamard matrix Authors Li Yuan, Tao Wang, Xiaopeng Zhang, Zequn Jie, Francis EH Tay, Jiashi Feng 哈希已广泛用于高效的大规模多媒体数据检索。大多数现有方法从数据成对相似性中学习散列函数以生成二进制散列码。然而,在实践中我们发现仅从成对相似性的局部关系中学习不能捕获大规模数据的全局分布,这会降低所生成的哈希码的可辨别性并损害检索性能。为了克服这个限制,我们提出了一种新的全局相似性度量,称为emph中心相似性,以学习更好的散列函数。中心相似性学习的目标是鼓励类似数据对的哈希码接近公共中心,并且不同对的哈希码汇聚到汉明空间中的不同中心,这大大提高了检索精度。为了主要制定中心相似性学习,我们定义了一个新的概念,emph哈希中心,是一个散布在汉明空间中的点,彼此之间有足够的距离,并建议使用Hadamard矩阵构造高质量的哈希有效地集中。基于这些定义和设计,我们设计了一个新的哈希中心网络HCN,它通过优化中心相似性w.r.t来学习哈希函数。这些哈希中心。中心相似性学习和HCN是通用的,可以应用于图像和视频散列。用于图像和视频检索的广泛实验证明HCN可以针对类似数据对生成内聚哈希码,并且针对不相似对生成分散哈希码,并且在检索性能方面实现显着提升,即MAP在最新技术水平上的提升。代码在url中 |
| Efficient Machine Learning for Large-Scale Urban Land-Use Forecasting in Sub-Saharan Africa Authors Daniel Omeiza 城市化是发展中国家的普遍现象,如果不加以有效管理,就会带来严峻挑战。缺乏适当的规划和管理可能会导致城市织物侵入保留区或特殊区域,从而导致人口不可持续增加。无效的管理和规划通常会导致生活水平下降,交通事故和疾病媒介繁殖等物理危害变得普遍。为了支持城市规划者和决策者进行有效的规划和准确的决策,我们调查了撒哈拉以南非洲的城市土地利用情况。土地利用动态是当前自然资源管理和监测战略和政策的关键参数。关注内罗毕,我们使用基于补丁的预测的有效深度学习方法,按季度基于土地使用从2004年到2018年对区域进行分类。我们估算了这一时期内土地利用的变化,并使用自回归综合移动平均ARIMA模型,我们的结果预测了未来某个特定日期的土地利用。此外,我们提供标记的土地使用地图,这将有助于城市规划者。 |
| +基于彩色编码光圈的单图像深度估计Physical Cue based Depth-Sensing by Color Coding with Deaberration Network Authors Nao Mishima, Tatsuo Kozakaya, Akihisa Moriya, Ryuzo Okada, Shinsaku Hiura 彩色编码光圈CCA方法可以物理地测量来自单目相机的单次拍摄图像的物理提示给出的场景的深度。然而,它们容易受到真实场景中的实际镜头像差的影响,因为它们假定用于简化算法的理想镜头。在本文中,我们提出了基于物理线索的CCA摄影深度学习。为了解决实际的镜头像差问题,我们开发了一种深度去噪网络DDN,它还具有位置和颜色通道的自我关注机制,可以有效地学习镜头像差。此外,基于贝叶斯深度学习的新贝叶斯L1损失函数能够更准确地处理深度估计的不确定性。定量和定性比较表明我们的方法优于传统方法,包括真实的户外场景。此外,与长基线立体相机相比,所提出的方法在近距离处提供无误差深度图,因为在左和右相机之间没有盲点。 |
| +目标检测提升ScarfNet: Multi-scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection Authors Jin Hyeok Yoo, Seong Hyeon Park, Jun Won Choi 卷积神经网络CNN已经在对象检测方面取得了重大进展。为了检测各种尺寸的物体,物体检测器经常利用称为特征金字塔的多尺度特征图的层次结构,其易于通过CNN架构获得。然而,这些物体检测器的性能是有限的,因为底层特征图经历较少的卷积层,缺少捕获小物体特征所需的语义信息。为了解决这样的问题,已经提出了各种方法来增加用于物体检测的底层特征的深度。虽然大多数方法都是基于通过横向连接的自上而下路径生成附加特征,但我们的方法使用双向长短期记忆biLSTM直接融合多尺度特征图,以产生深度融合的语义。然后,通过渠道明智的关注模型将得到的语义信息重新分配到每个尺度的单个金字塔特征。我们将语义组合和细心的再分配特征网络ScarfNet与基线对象检测器集成,即更快的R CNN,单镜头多盒检测器SSD和RetinaNet。我们的实验表明,我们的方法优于现有的特征金字塔方法以及基线检测器,并在PASCAL VOC和COCO检测基准中实现了最先进的性能。 |
| ++人体关键点检测实现摔倒预测Falls Prediction Based on Body Keypoints and Seq2Seq Architecture Authors Minjie Hua, Yibing Nan, Shiguo Lian 本文提出了一种基于人体姿势预先预测跌倒事件的新方法。首先,检测并跟踪连续帧中的每个人。并提取它们的主体关键点,然后进行标准化以便以后处理。接下来,将观察到的每个人的关键点序列输入到序列中以对基于seq2seq的模型进行排序以预测未来的关键点序列,其用于跌倒分类以判断该人将来是否会摔倒。动作预测模块和跌倒分类器分别训练并共同调整。所提出的模型在Le2i数据集上进行评估,该数据集由191个视频组成,包括各种正常的日常活动和由演员执行的瀑布。使用那些直接使用RGB信息并且没有动作预测模块进行分类的算法进行对比实验。实验结果表明,该模型利用具有预先预测跌倒能力的人体关键点,提高了跌倒识别的准确性。 |
| ++图像风格迁移妆造和图片Content and Colour Distillation for Learning Image Translations with the Spatial Profile Loss Authors M. Saquib Sarfraz, Constantin Seibold, Haroon Khalid, Rainer Stiefelhagen 生成对抗网络已成为图像翻译问题的事实标准。为了成功地驱动这些模型,必须依赖于附加网络,例如鉴别器和/或感知网络。仅利用基于像素的损耗来训练这些网络通常不足以学习目标分布。在本文中,我们提出了一种计算源图像和目标图像之间直接损失的新方法,可以对形状内容和颜色样式进行适当的蒸馏。我们证明这在典型的图像到图像转换中很有用,这使我们能够在不依赖其他网络的情况下成功驱动发生器。我们在许多困难的图像转换问题上证明了这一点,例如图像到图像域映射,单图像超分辨率和照片逼真的化妆转移。我们的广泛评估显示了所提出的配方的有效性及其合成逼真图像的能力。代码发布 |
| ++金字塔去噪Pyramid Real Image Denoising Network Authors Yiyun Zhao, Zhuqing Jiang, Aidong Men, Guodong Ju 虽然深度卷积神经网络CNN已经显示出对特定噪声和去噪建模的非凡能力,但它们在现实世界的噪声图像上仍然表现不佳。主要原因是现实世界的噪音更加复杂和多样化。为了解决盲目去噪问题,本文提出了一种新颖的金字塔实像去噪网络PRIDNet,它包含三个阶段。首先,噪声估计阶段使用信道关注机制来重新校准输入噪声的信道重要性。其次,在多尺度去噪阶段,利用金字塔池来提取多尺度特征。第三,特征融合阶段采用内核选择操作自适应融合多尺度特征。在真实噪声照片的两个数据集上的实验表明,与定量测量和视觉感知质量相比,我们的方法与现有技术的降噪器相比可以实现竞争性能。 |
| Pseudo-Labeling Curriculum for Unsupervised Domain Adaptation Authors Jaehoon Choi, Minki Jeong, Taekyung Kim, Changick Kim 为了学习目标判别表示,使用伪标签是用于无监督域自适应的简单而有效的方法。然而,可能对学习目标表示产生不利影响的假伪标签的存在仍然是一项重大挑战。为了解决这个问题,我们提出了一种基于密度聚类算法的伪标签课程。由于具有高密度值的样本更可能具有正确的伪标签,因此我们利用这些子集在早期阶段训练我们的目标网络,并在后期利用具有低密度值的数据子集。我们可以逐步提高网络生成伪标签的能力,因此这些带有伪标签的目标样本可以有效地训练我们的模型。此外,我们提出了一个聚类约束来增强学习目标特征的判别力。我们的方法在Office 31,imageCLEF DA和Office Home三个基准上实现了最先进的性能。 |
| Visual Place Recognition for Aerial Robotics: Exploring Accuracy-Computation Trade-off for Local Image Descriptors Authors Bruno Ferrarini, Maria Waheed, Sania Waheed, Shoaib Ehsan, Michael Milford, Klaus D. McDonald Maier 视觉位置识别VPR是小型无人机无人机的一项基本但具有挑战性的任务。核心原因是极端视点变化,以及UAV上的有限计算能力,这限制了稳健但计算密集的现有VPR方法的适用性。在这种情况下,一种可行的方法是使用本地图像描述符来执行VPR,因为这些可以相对有效地计算,而不需要任何特殊硬件,例如GPU。然而,选择局部特征描述符并非易事,需要进行详细调查,因为在VPR准确度和所需的计算工作量之间存在折衷。为了填补这一研究空白,本文从准确性和计算角度检验了几种最先进的局部特征描述符的性能,特别是利用标准航空数据集的VPR应用。所呈现的结果证实,在资源受限硬件上执行VPR时,精度和计算工作之间的折衷是不可避免的。 |
| Convolutional Auto-encoding of Sentence Topics for Image Paragraph Generation Authors Jing Wang, Yingwei Pan, Ting Yao, Jinhui Tang, Tao Mei 图像段落生成是生成连贯故事的任务,通常是描述图像可视内容的段落。然而,问题并非微不足道,特别是当有多个描述性和多样性的要点被考虑用于段落生成时,这通常发生在真实图像中。一个有效的问题是如何从图像中封装值得提及的主题主题,然后将图像从一个主题描述到另一个主题,但整体上用连贯的结构描述。在本文中,我们提出了一种新的设计卷积自动编码CAE,它纯粹采用卷积和反卷积自动编码框架,用于图像的区域级特征的主题建模。此外,我们提出了一种架构,即CAE加长期短记忆,称为CAE LSTM,它新颖地集成了学习主题以支持段落生成。从技术上讲,CAE LSTM利用基于LSTM的两级段落生成框架和注意机制。段落级别LSTM捕获段落中的句子间依赖性,而句子级别LSTM生成一个以每个学习主题为条件的句子。对斯坦福图像段落数据集进行了大量实验,与现有技术方法相比,报告了优异的结果。更值得注意的是,CAE LSTM将CIDEr性能从20.93增加到25.15。 |
| +++结构化三维模型数据集Structured3D: A Large Photo-realistic Dataset for Structured 3D Modeling Authors Jia Zheng, Junfei Zhang, Jing Li, Rui Tang, Shenghua Gao, Zihan Zhou 最近,人们越来越关注开发基于学习的方法来检测和利用显着的半全局或全局结构,例如结,线,平面,长方体,光滑表面和所有类型的对称,用于3D场景建模和理解。然而,地面实况注释通常通过人工获得,由于大量的3D结构实例(例如,线段和诸如视点和遮挡的其他因素),这对于这样的任务尤其具有挑战性和低效率。在本文中,我们提出了一个新的合成数据集Structured3D,旨在为广泛的结构化3D建模任务提供具有丰富3D结构注释的大规模照片真实图像。我们利用数百万专业室内设计的可用性,并从中自动提取3D结构。我们使用业界领先的渲染引擎生成高质量图像。我们将合成数据集与真实图像结合使用,以训练深度神经网络进行房间布局估计,并展示基准数据集的改进性能。 |
| Generative Image Inpainting with Submanifold Alignment Authors Ang Li, Jianzhong Qi, Rui Zhang, Xingjun Ma, Kotagiri Ramamohanarao 图像修复旨在恢复损坏图像的缺失区域,其具有许多应用,例如图像恢复和对象移除。然而,当前基于GAN的生成修复模型没有明确地利用恢复的内容与其周围之间的结构或纹理一致性 |
| Single-Shot High Dynamic Range Imaging with Spatially Varying Exposures Considering Hue Distortion Authors Chihiro Go, Yuma Kinoshita, Sayaka Shiota, Hitoshi Kiya 我们提出了一种新颖的单次高动态范围成像方案,其具有考虑色调失真的空间变化的曝光SVE。使用SVE的单次成像使我们能够从单次拍摄图像中捕获多重曝光图像,因此可以生成高动态范围图像而不会产生重影伪影。但是,SVE图像具有一些像素,在这些像素处超出了相机传感器支持的范围。因此,生成的图像具有一些颜色失真,因此使用SVE的传统成像从未考虑过该范围限制的影响。为了克服这个问题,我们考虑从原始图像估计场景的正确色调,并提出一种方法,其具有用于校正RGB颜色空间中的恒定色调平面上的SVE图像的色调的估计色调信息。 |
| Scalable Place Recognition Under Appearance Change for Autonomous Driving Authors Anh Dzung Doan, Yasir Latif, Tat Jun Chin, Yu Liu, Thanh Toan Do, Ian Reid 对自动驾驶的位置识别的主要挑战是对由于短期(例如,天气,照明和长期季节,植被生长等)环境变化引起的外观变化具有鲁棒性。一种有前途的解决方案是不断累积图像以维持适当的条件样本,并将新的变化纳入场所识别决策。然而,这需要一种可在不断增长的数据集上扩展的位置识别技术。为此,我们提出了一种可以有效地重新训练和压缩的新颖的位置识别技术,使得新查询的识别可以利用包括最近变化的所有可用数据而不会遭受计算成本的可见增长。我们的方法的基础是一种基于隐马尔可夫模型的新型时间图像匹配技术。我们的实验表明,与现有技术相比,我们的方法对于自动驾驶的大规模位置识别具有更大的潜力。 |
| Curiosity-driven Reinforcement Learning for Diverse Visual Paragraph Generation Authors Yadan Luo, Zi Huang, Zheng Zhang, Jingjing Li, Yang Yang 视觉段落生成旨在从不同的角度自动描述给定的图像并以连贯的方式组织句子。在本文中,我们针对强化学习设置模式崩溃,延迟反馈以及策略网络的耗时预热,解决了此任务的三个关键挑战。通常,我们提出一种新颖的好奇心驱动的强化学习CRL框架,以共同增强所生成段落的多样性和准确性。首先,通过将段落字幕建模为长期决策过程并将状态转换的预测不确定性作为内在奖励进行建模,该模型被激励以记住精确但很少发现的上下文描述,而不是偏向于频繁的片段和通用模式。其次,由于评估的外在奖励仅在生成完整段落之前可用,我们通过考虑连续动作之间的相关性来估计其在时间差异学习的每个时间步骤的期望值。然后,通过衍生的好奇心模块产生的密集的内在奖励补充估计的外在奖励,以鼓励该政策充分探索行动空间并找到全局最优。第三,打折的模仿学习被整合用于从人类演示中学习,而无需预先单独执行耗时的预热。在Standford图像段落数据集上进行的大量实验证明了所提出方法的有效性和效率,与现有技术相比,性能提高了38.4。 |
| Multi-path Learning for Object Pose Estimation Across Domains Authors Martin Sundermeyer, Maximilian Durner, En Yen Puang, Zoltan Csaba Marton, Rudolph Triebel 我们介绍了一种可扩展的方法,用于对多个3D模型的模拟RGB视图一起训练的对象姿态估计。我们学习了对象视图的编码,它不仅描述了在训练期间看到的所有对象的方向,还可以关联未经训练的对象的视图。我们的单编码器多解码器网络使用我们表示多路径学习的技术进行训练。当编码器由所有对象共享时,每个解码器仅重建单个对象的视图。因此,不需要在潜在空间中分离不同实例的视图并且可以共享共同特征。生成的编码器可以很好地从合成数据到实际数据,以及各种实例,类别,模型类型和数据集。我们系统地研究了ModelNet40和T LESS数据集上的学习编码,它们的泛化能力和迭代细化策略。在T LESS,我们使用我们的6D对象检测管道(RGB和深度域)实现最先进的结果,在低得多的运行时间上优于无学习管道。 |
| ShapeCaptioner: Generative Caption Network for 3D Shapes by Learning a Mapping from Parts Detected in Multiple Views to Sentences Authors Zhizhong Han, Chao Chen, Yu Shen Liu, Matthias Zwicker 3D形状字幕在3D形状理解中是一个具有挑战性的应用。最近基于多视图的方法的字幕显示它们无法捕获3D形状的部分级特征。这导致人们倾向于关注的字幕中缺少详细的部分级别描述。为了解决这个问题,我们提出ShapeCaptioner,一个生成字幕网络,从多个视图中检测到的语义部分执行3D形状字幕。我们的新颖之处在于从三维形状分割中学习多视图中的零件检测知识,并传授这些知识,以便于学习从三维形状到句子的映射。具体来说,ShapeCaptioner使用我们新颖的零件类特定聚合来聚合在多个彩色视图中检测到的零件以表示3D形状,然后,使用序列来对模型进行排序以生成标题。我们的超越结果表明,ShapeCaptioner可以学习具有更详细部件特征的3D形状特征,以便于比以前的工作更好的3D形状字幕。 |
| 3D Virtual Garment Modeling from RGB Images Authors Yi Xu, Shanglin Yang, Wei Sun, Li Tan, Kefeng Li, Hui Zhou 我们提出了一种从照片构建3D虚拟服装模型的新方法。与之前需要人体模型或人体模型上的服装照片的方法不同,我们的方法可以在模型,人体模型或平坦表面上与服装的各种状态一起工作。为了构建完整的3D虚拟模型,我们的方法只需要两个图像作为输入,一个前视图和一个后视图。我们首先应用一个名为JFNet的多任务学习网络,共同预测时尚地标并将服装图像解析为语义部分。预测的界标用于估计服装的尺寸信息。然后,基于尺寸信息使模板服装网格变形以生成最终的3D模型。语义部分用于从输入图像中提取颜色纹理。我们的方法的结果可用于各种虚拟现实和混合现实应用程序。 |
| +小样本去噪Few-Shot Meta-Denoising Authors Leslie Casas, Gustavo Carneiro, Nassir Navab, Vasileios Belagiannis 我们研究了基于学习的去噪问题,其中训练集只包含少量干净和嘈杂的样本。减轻小训练集问题的解决方案是训练具有干净和合成噪声信号对的去噪模型,该信号由经验噪声先验产生,并且最终仅对可用的小训练集进行微调。虽然转学习很适合这个管道,但它并没有用有限的训练数据来概括。在这项工作中,我们提出了一种基于元学习的新训练方法,用于基于射击学习的几个去噪问题。我们的模型是使用已知的合成噪声模型进行元训练,然后使用小训练集进行微调,具有真实噪声,作为一些镜头学习任务。在元训练期间从合成数据中学习使我们能够生成无限数量的训练数据。我们的方法经验证明,在图像和1D信号的三个去噪评估中产生比监督学习和转移学习更准确的去噪结果。有趣的是,我们的研究提供了强有力的迹象,即元学习有可能成为去噪的主要学习算法。 |
| OCT Fingerprints: Resilience to Presentation Attacks Authors Tarang Chugh, Anil K. Jain 光学相干断层扫描OCT指纹技术提供丰富的深度信息,包括内部指纹乳头状交界处和汗腺外分泌腺,此外还可以对手指皮肤上的任何假层呈现攻击进行成像。与2D表面指纹扫描不同,横截面OCT深度剖面扫描提供的附加深度信息据称可以阻止指纹呈现攻击。我们基于深度卷积神经网络CNN开发和评估表示攻击检测器PAD。输入到CNN的数据是从使用THORLabs Telesto系列光谱域指纹读取器捕获的横截面OCT深度剖面扫描中提取的局部补片。所提出的方法在使用8种不同PA材料制造的3,413个真实和357 PA OCT扫描的数据库上实现了99.73 FDR为0.2的TDR。通过采用称为CNN Fixations的可视化技术,我们能够识别OCT扫描区域中对指纹PAD检测至关重要的区域。 |
| Simultaneous Iris and Periocular Region Detection Using Coarse Annotations Authors Diego R. Lucio, Rayson Laroca, Luiz A. Zanlorensi, Gladston Moreira, David Menotti 在这项工作中,我们建议使用粗略注释和两个众所周知的物体检测器YOLOv2和Faster R CNN同时检测虹膜和眼周区域。我们相信粗略注释可以用于基于虹膜和眼周区域的识别系统,因为手动注释训练图像需要更小的工程量。我们手动对来自可见VIS光谱的虹膜和眼周区域122K图像和来自近红外NIR光谱的38K图像进行粗略注释。通过首先应用虹膜分割CNN然后执行手动检查,半自动地生成NIR数据库中的虹膜注释。这些注释是针对11个众所周知的公共数据库3 NIR和8 VIS而设计的,这些数据库是为基于虹膜的识别问题而设计的,并且可供研究界公开使用。试验我们对这些数据库的建议,我们强调了两个结果。首先,更快的R CNN特征金字塔网络FPN模型报告的联盟IoU交叉口高于YOLOv2 91.86和85.30。第二,同时进行的虹膜和眼周区域的检测与单独进行的一样准确,但计算成本较低,即以一个为代价进行两项任务。 |
| An Empirical Study of Batch Normalization and Group Normalization in Conditional Computation Authors Vincent Michalski, Vikram Voleti, Samira Ebrahimi Kahou, Anthony Ortiz, Pascal Vincent, Chris Pal, Doina Precup 批量归一化已被广泛用于改进深度神经网络中的优化。虽然批量统计中的不确定性可以充当正则化器,但使用特定于训练集的这些数据集统计数据会损害某些任务的泛化。最近,已经提出了用于归一化神经网络中的特征激活的替代方法。其中,组标准化已显示产生类似,在一些领域甚至优于批次标准化的性能。所有这些方法在归一化操作之后利用学习的仿射变换来增加表示能力。条件计算中使用的方法将这些转换的参数定义为条件信息的可学习函数。在这项工作中,我们研究了与条件批量标准化相比,组标准化的条件公式是否以及在何处可以改善泛化。我们评估视觉问题回答,少数镜头学习和条件图像生成任务的表现。 |
| ++非刚体sfm Deep Non-Rigid Structure from Motion Authors Chen Kong, Simon Lucey 来自运动NRSfM算法的当前非刚性结构主要受限于图像的数量,以及它们可以处理的形状可变性的类型。这妨碍了NRSfM在视觉中的许多应用的实用性。在本文中,我们提出了一种新颖的深度神经网络,仅从一组2D图像坐标中恢复相机姿势和3D点。所提出的神经网络在数学上可解释为多层块稀疏字典学习问题,并且可以处理前所未有的规模和形状复杂性的问题。大量实验证明了我们的方法令人印象深刻的性能,我们在数量级上对所有可用的现有技术工作表现出卓越的精度和稳健性。我们进一步提出了一种基于网络权重的质量测量,它可以避免对3D地面实况的需求,以确定我们在重建中的信心。IKEA dataset,CMU Mocap dataset. |
| Image Captioning with Unseen Objects Authors Berkan Demirel, Ramazan Gokberk Cinbis, Nazli Ikizler Cinbis 在计算机视觉和自然语言处理的交叉点上,图像标题生成是一个长期存在且具有挑战性的问题。最近提出的许多方法在字幕方法中使用完全监督的对象识别模型。然而,这样的模型倾向于生成仅由识别模型预测的对象组成的句子,排除没有标记训练示例的类的实例。在本文中,我们提出了一个新的挑战性场景,其针对完全零镜头学习设置中的图像字幕问题,其目标是能够生成包含在训练期间未看到的对象的测试图像的标题。所提出的方法联合使用新颖的零射击物体检测模型和基于模板的句子生成器。我们的实验显示了COCO数据集的有希望的结果。 |
| DROGON: A Causal Reasoning Framework for Future Trajectory Forecast Authors Chiho Choi, Abhishek Patil, Srikanth Malla 我们提出了DROGON Deep RObust Goal Oriented轨道预测网络,通过考虑交通场景中车辆的行为意图来准确地进行车辆轨迹预测。我们的主要观点是,驾驶员的意图和行为之间的因果关系可以通过观察他们与环境的关系互动来推理。为了在因果推理中取得成功,我们构建了一个条件预测模型来预测目标导向轨迹,该模型通过以下阶段进行训练:关系推理,其中我们使用感知上下文ii来计算车辆的关系交互,以计算故意目标的概率分布基于推断的关系和iii因果推理,我们推断车辆的行为作为未来的位置以意图为条件。为了正确评估我们的方法的性能,我们提出了一个新的大型数据集,收集在道路交叉点与车辆的不同交互。实验证明了DROGON的功效,因为它始终优于现有技术。 |
| Deep Sensor Fusion for Real-Time Odometry Estimation Authors Michelle Valente, Cyril Joly, Arnaud de La Fortelle 摄像机和2D激光扫描仪相结合,能够提供低成本,重量轻和精确的解决方案,使其融合非常适合许多机器人导航任务。然而,正确的数据融合取决于传感器之间刚体变换的精确校准。在本文中,我们提出了第一个利用卷积神经网络CNN进行二维激光扫描仪和单色相机的测距估计的框架。 CNN的使用提供的工具不仅可以从两个传感器中提取特征,还可以融合和匹配它们,而无需在传感器之间进行校准。我们将里程计算估计转换为序数分类问题,以便在连续帧之间找到准确的旋转和平移值。真实道路数据集上的结果表明,融合网络实时运行,并且能够通过学习如何融合两种不同类型的数据信息来单独改进单个传感器的测距估计。 |
| GANs 'N Lungs: improving pneumonia prediction Authors Tatiana Malygina, Elena Ericheva, Ivan Drokin 我们提出了一种新方法来改善高度不平衡任务的深度学习模型性能。所提出的方法基于CycleGAN来实现平衡数据集。我们表明,使用GAN进行数据增强有助于提高肺炎二元分类任务的准确性,即使生成网络是在同一训练数据集上训练的。 |
| Quality Assessment of In-the-Wild Videos Authors Dingquan Li, Tingting Jiang, Ming Jiang 由于缺少参考视频和拍摄失真,野外视频的质量评估是一个具有挑战性的问题。对人类视觉系统的了解可以帮助建立野生视频中客观质量评估的方法。在这项工作中,我们展示了人类视觉系统的两个显着效果,即内容依赖和时间记忆效应,可用于此目的。我们提出了一种客观的无参考视频质量评估方法,将两种效应整合到深度神经网络中。对于内容依赖性,我们从预先训练的图像分类神经网络中提取特征以获得其固有的内容感知属性。对于时间记忆效应,长期依赖性,尤其是时间滞后,利用门控递归单元和主观启发的时间池层被集成到网络中。为了验证我们的方法的性能,分别在野生视频质量评估数据库KoNViD 1k,CVD2014和LIVE Qualcomm中公开获得三个实验。实验结果表明,我们提出的方法在SROCC,KROCC,PLCC和RMSE方面比第二好的方法VBLIINDS大大超过了五种最先进的方法,特别是12.39,15.71,15.45和18.09的整体性能改进,分别。此外,消融研究验证了内容感知特征和时间记忆效应建模的关键作用。我们的方法的PyTorch实现发布于 |
| A Framework for Depth Estimation and Relative Localization of Ground Robots using Computer Vision Authors Romulo T. Rodrigues, Pedro Miraldo, Dimos V. Dimarogonas, A. Pedro Aguiar 分散式架构内的3D深度估计和相对姿态估计问题是在需要多个视觉控制机器人之间协调的任务中出现的挑战性问题。深度估计问题旨在恢复环境的3D信息。相对定位问题包括通过感知彼此的姿势或共享关于感知环境的信息来估计两个机器人之间的相对姿势。针对这些问题的大多数解决方案使用一组离散数据而不考虑事件的时间顺序。本文以最近的连续估计结果为基础,提出了一个估计两个非完整车辆之间深度和相对姿态的框架。基本思想在于通过明确考虑安装在地面机器人上的摄像机的动态特性来估计点的深度,并且在计算机器人之间的相对姿势的滤波器中馈送两个摄像机观察到的3D点的估计。我们评估一组模拟场景的收敛性,并显示验证所提出的框架的实验结果。 |
| New Techniques for Graph Edit Distance Computation Authors David B. Blumenthal 由于它们能够对丰富的结构信息进行编码,因此标记的图形通常用于对各种对象(如图像,分子和化合物)进行建模。如果要在这些域上解决诸如聚类和分类之类的模式识别问题,则必须定义标记图的不相似性度量。广泛使用的度量是图形编辑距离GED,其直观地定义为必须应用于源图形以将其转换为目标图形的最小失真量。 GED的主要优点是其灵活性和对输入图之间的微小差异的敏感性。它的主要缺点是很难计算。 |
| Deep Kinematic Models for Physically Realistic Prediction of Vehicle Trajectories Authors Henggang Cui, Thi Nguyen, Fang Chieh Chou, Tsung Han Lin, Jeff Schneider, David Bradley, Nemanja Djuric 自驾车SDV具有提高交通安全的巨大潜力,并准备积极影响数百万人的生活质量。自动化技术的一个关键方面是理解和预测SDV周围车辆的未来运动。这项工作提出了一种基于深度学习的方法,用于对这种交通行为者进以前的工作没有明确地编码物理现实主义,而是依靠模型直接从数据中学习物理定律,可能导致不可思议的轨迹预测。为了解决这个问题,我们提出了一种方法,将AI的思想与物理接地的车辆运动模型无缝结合。通过这种方式,我们采用了两全其美的优势,将强大的学习模型与其输出的强大物理保证相结合。所提出的方法是通用的,适用于任何类型的学习方法。使用深度网络对大规模现实世界数据进行的大量实验强烈表明其优势,优于现有技术水平。 |
| Chainer: A Deep Learning Framework for Accelerating the Research Cycle Authors Seiya Tokui, Ryosuke Okuta, Takuya Akiba, Yusuke Niitani, Toru Ogawa, Shunta Saito, Shuji Suzuki, Kota Uenishi, Brian Vogel, Hiroyuki Yamazaki Vincent 神经网络的软件框架在深度学习方法的开发和应用中起着关键作用。在本文中,我们介绍了Chainer框架,该框架旨在提供灵活,直观和高性能的方法来实现研究人员和从业者所需的全方位深度学习模型。 Chainer使用图形处理单元通过CuPy提供熟悉的类似NumPy API的加速,通过“运行定义”支持Python中的通用和动态模型,还提供最新的计算机视觉模型以及分布式培训的附加软件包。 |
| DEDUCE: Diverse scEne Detection methods in Unseen Challenging Environments Authors Anwesan Pal, Carlos Nieto Granda, Henrik I. Christensen 近年来,为帮助人们进行日常活动而部署的服务机器人数量迅速增加。不幸的是,大多数这些机器人需要人工输入进行训练才能在室内环境中完成任务。成功的国内导航通常需要访问有关环境的语义信息,这可以在没有人工指导的情况下学习。在本文中,我们提出了一套DEDUCE多种scEne检测方法,这些方法采用了看不见的挑战环境算法,该算法结合了源自场景识别系统和物体探测器的深度融合模型。这里描述的五种方法已经在几个流行的近期图像数据集上进行了评估,以及通过多个移动平台获得的真实世界视频。最终结果显示了对现有技术的视觉位置识别系统的改进。 |
| ++基于稀疏激活梯度加速CNN训练Accelerating CNN Training by Sparsifying Activation Gradients Authors Xucheng Ye, Jianlei Yang, Pengcheng Dai, Yiran Chen, Weisheng Zhao 在卷积神经网络CNN训练的反向传播过程中,激活的梯度参与大多数计算。然而,一个重要的已知观察是这些梯度中的大多数接近零,对重量更新几乎没有影响。然后可以修剪这些梯度以在CNN训练期间实现高梯度稀疏度并降低计算成本。特别地,如果梯度低于由激活梯度的统计分布确定的阈值,我们将梯度随机地改变为零或阈值。我们还从理论上证明了采用上述激活梯度稀疏化方法可以保证CNN模型的训练收敛性。我们使用CIFAR 10,100和ImageNet数据集在AlexNet,MobileNet,ResNet 18,34,50,101,152上评估了我们的方法。实验结果表明,我们的方法可以大大降低计算成本,精度损失可忽略不计甚至精度提高。最后,我们详细分析了激活梯度稀疏性带来的好处。 |
| Sublinear Subwindow Search Authors Max Reuter, Gheorghe Teodor Bercea 我们提出了一种用于子窗口搜索的有效近似算法,该算法在次线性时间和内存中运行。应用于对象定位,与现有技术相比,该算法显着减少了运行时间和内存使用,同时保持了竞争准确度分数。算法的精度也随着矩阵的元素相似性的大小和空间相干性而缩放。因此,它非常适用于实时应用和一般的许多矩阵。 |
| ++边缘设备与机器学习,内涵有用链接资源 Machine Learning at the Network Edge: A Survey Authors M.G. Sarwar Murshed, Christopher Murphy, Daqing Hou, Nazar Khan, Ganesh Ananthanarayanan, Faraz Hussain 包括物联网的设备,例如传感器和小型相机,通常具有小的存储器和有限的计算能力。近年来,这种资源受限设备的激增导致了大量数据的产生。这些数据生成设备是机器学习应用程序的吸引人的目标,但由于其有限的计算能力而难以运行机器学习算法。它们通常将输入数据卸载到外部计算系统(例如云服务器)以进行进一步处理。机器学习计算的结果被传送回资源稀缺的设备,但这会延迟延迟,导致通信成本增加,并增加了隐私问题。因此,已经努力将附加的计算设备放置在网络的边缘,即靠近生成数据的IoT设备。在这样的边缘设备上部署机器学习系统通过允许在数据源附近执行计算来缓解上述问题。该调查描述了在计算机网络边缘部署机器学习的主要研究工作。 文章中有大量有用链接和性能对比,https://github.com/Cloudslab/EdgeLens,https://github.com/Microsoft/EdgeML,https://github.com/kunglab/ddnn。。。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com