capsule系列之Dynamic Routing Between Capsules
文章目录
- 1.背景
- 2.什么是capsule
- 3.capsule原理和结构
- 3.1.capsule结构
- 3.2.Dynamic Routing 算法
- 3.3.小部件
- 3.3.1.为耦合系数(coupling coefficients)
- 3.3.1.b_ij权值更新
- 3.3.2.squashing
- 4.CapsNet模型介绍
- 4.1.层次结构
- 4.2.损失函数
- 4.3.关于Digit层权值共享
- 5.源码解析
- 6.相关讨论
- 7.capsule相关论文
- 参考文献
capsule在出现之后就除了Hinton老爷子的两个版本之外,还有例如Investigating Capsule Networks with Dynamic Routing for Text Classification这样的新作,可见capsule的很多理念都是work的,因为打算好好拜读几篇paper,做一个系列,深刻理解capsule。
本篇文章我觉得确实还是有难度的,作为一篇笔记博客,为了能够比较透彻的理解,在原文基础上参考了很多的文章,并添加了相关自己的理解,参考文献会在最后章节详细列出。
论文下载地址:zsweet github
1.背景
一个新的事物出现,必然以藏着以往事物的缺陷,那么capsule因何而生呢?
在讲胶囊网络之前,首先我们回顾一下我们熟悉的CNN:
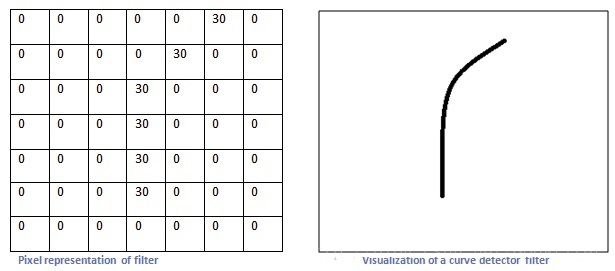
CNN做了什么事情呢? 假设这里有一个卷积核(左图),除了曲线轨迹上的值很大,其他的值都是零,所以这个卷积核对旁边这种曲线(右图)就有很高的输出,也就是说对这种曲线有很高的识别,而对其他的曲线类型输出就低。
所以比如图像分类中,一旦卷积核检测到了类似于眼睛啊、鼻子啊、嘴巴啊这种特征;从数学角度上说就,相关卷积核对鼻子、眼睛等卷积出来的值很大,那么与人脸相关的神经元就相当兴奋,最后将图像分类到人脸这一类。
所以这就导致了一个问题。如图,右边那张眼睛、鼻子、嘴巴都有了,当然我们的CNN也相当兴奋的将它归于人脸。
这就就暴露了CNN的问题:
- 组件的朝向和空间上的相对关系对它来说不重要,它只在乎有没有特征。
- CNN还有一个问题,那就是池化层。Hinton自己就说过:最大池化层表现的如此优异是一个巨大的错误,是一场灾难。诚然,从网络设计上来说,池化层不仅减少了参数,还可以避免过拟合。但是,它的确抛弃了一些信息,比如位置信息。
再比如说,下面这张图,尽管拍摄的角度不同,但你的大脑可以轻易的辨识这些都是同一对象,CNN却没有这样的能力。它不能举一反三,它只能通过扩大训练的数据量才能得到相似的能力。

2.什么是capsule
现在网上有关于capsule多数翻译成胶囊,但是我觉太缺乏学术性,知乎上的
云梦居客(文章里有详细的ppt和录播视频)大佬把它称作“矢量神经元”或者“张量神经元”,我觉得比较合适,但是很多人可能又没听说过这种说法,所以还是直接称之为capsule吧!(懒癌犯了…)
论文中说道,capsule是一个实体,那实体又是什么?一般是指能够独立存在的、作为一切属性的基础和万物本原的东西(百度百科)。capsule就是一个完整概念单元的封装,能够表征不同属性。
这次Capsule盛宴的特色是“vector in vector out”,取代了以往的“scaler in scaler out”,也就是神经元的输入输出都变成了向量,从而算是对神经网络理论的一次革命。然而真的是这样子吗?难道我们以往就没有做过“vector in vector out”的任务了吗?有,而且多的是!NLP中,一个词向量序列的输入,不就可以看成“vector in”了吗?这个词向量序列经过RNN/CNN/Attention的编码,输出一个新序列,不就是“vector out”了吗?在目前的深度学习中,从来不缺乏“vector in vector out”的案例,因此显然这不能算是Capsule的革命。
Capsule的革命在于:它提出了一种新的“vector in vector out”的传递和权重更新方案,并且这种方案在很大程度上是可解释的。
那最后,什么是capsule?
其实,只要把一个向量当作一个整体来看,它就是一个capsule。 你可以这样理解:神经元就是标量,胶囊就是向量,就这么粗暴!Hinton的理解是:每一个胶囊表示一个属性,而胶囊的向量则表示这个属性的“标架”。也就是说,我们以前只是用一个标量表示有没有这个特征(比如有没有羽毛),现在我们用一个向量来表示,不仅仅表示有没有,还表示“有什么样的”(比如有什么颜色、什么纹理的羽毛),如果这样理解,就是说在对单个特征的表达上更丰富了。
说到这里,我感觉有点像NLP中的词向量,以前我们只是用one hot来表示一个词,也就是表示有没有这个词而已。现在我们用词向量来表示一个词,显然词向量表达的特征更丰富,不仅可以表示有没有,还可以表示哪些词有相近含义。词向量就是NLP中的“胶囊”?这个类比可能有点牵强,但我觉得意思已经对了。
3.capsule原理和结构
在论文中,Geoffrey Hinton 介绍 Capsule 为:「Capsule 是一组神经元,其输入输出向量表示特定实体类型的实例化参数(即特定物体、概念实体等出现的概率与某些属性)。我们使用输入输出向量的长度表征实体存在的概率,向量的方向表示实例化参数(即实体的某些图形属性)。同一层级的 capsule 通过变换矩阵对更高级别的 capsule 的实例化参数进行预测。当多个预测一致时(本论文使用动态路由使预测一致),更高级别的 capsule 将变得活跃。」
Capsule 中的神经元的激活情况表示了图像中存在的特定实体的各种性质。这些性质可以包含很多种不同的参数,例如姿势(位置,大小,方向)、变形、速度、反射率,色彩、纹理等等。而输入输出向量的长度表示了某个实体出现的概率,所以它的值必须在 0 到 1 之间。
3.1.capsule结构
下面我们来看看capsule的结构。
Capsule针对着“层层递进”的目标来设计的,我们先来看一张整体的capsule结构图,更好理解:
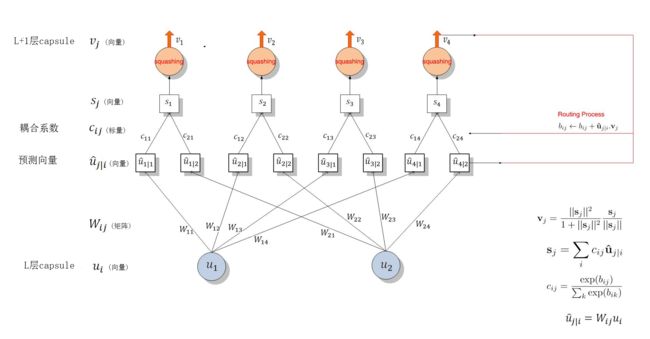
上图展示了Capsule整体结构:Capsule层级结构与动态 Routing 的过程。
其中最下面的层级 u i u_i ui共有两个 Capsule 单元,该层级传递到下一层级 v j v_j vj 共有四个 Capsule。
capsule的运行流程大致如下:
- u 1 u_1 u1 和 u 2 u_2 u2 是一个向量,即含有一组神经元的 Capsule 单元,它们分别与不同的权重 W i j W_{ij} Wij(同样是向量,更准确来说是矩阵)相乘得出 u ^ j ∣ i \widehat {u}_{j|i} u j∣i。例如 u 1 u_1 u1 与 W 12 W_{12} W12 相乘得出预测向量 u ^ 2 ∣ 1 \widehat{u}_{2|1} u 2∣1。通过改变W_{ij}的维度也可以起到降维的作用?
- 预测向量和对应的「耦合系数」 c i j c_{ij} cij 相乘并传入特定的后一层 Capsule 单元得到 s j s_j sj。不同 Capsule 单元的输入 s j s_j sj 是所有可能传入该单元的加权和,即所有可能传入的预测向量与耦合系数的乘积和。
- 将向量 s j s_j sj投入到「squashing」非线性函数就能得出后一层 Capsule 单元的输出向量 v j v_j vj。
- 利用该输出向量 v j v_j vj 和对应预测向量 u ^ j ∣ i \widehat{u}_{j|i} u j∣i 的乘积更新耦合系数 c i j c_{ij} cij,这样的迭代更新不需要应用反向传播。
其实capsule就是一个向量版的全连接层,与传统的全连接对比如下:

关于capsule的构建过程,我觉得苏建林的这篇文章说的挺好的,不愧是数学出身的大佬,大家可以拜读一下。
3.2.Dynamic Routing 算法
按照 Hinton 的思想,找到最好的处理路径就等价于正确处理了图像,所以在 Capsule 中加入 Routing 机制可以找到一组系数 c i j c_{ij} cij,它们能令预测向量 u ^ j ∣ i \widehat{u}_{j|i} u j∣i 最符合输出向量 v j v_j vj,即最符合输出的输入向量,这样我们就找到了最好的路径。
从上面的capsule结果和运行过程可以看出,为了求 v j v_j vj需要先求 c i j c_{ij} cij,可是为了求 c i j c_{ij} cij又需要知道 v j v_j vj,这不是个鸡生蛋、蛋生鸡的问题了吗?
之前了解过EM算法的小伙伴应该有印象,可以说是特别像了,所以分类聚类虽有本质的区别,可是还是相通的啊,关于EM算法可以参考我之前的文章从最大似然到EM算法浅解
那怎么办呢?
这就需要像EM一样通过迭代的方式了,在这里起个名字叫“动态路由”(Dynamic Routing),它能够根据自身的特性来更新(部分)参数,从而初步达到了Hinton的放弃梯度下降的目标。具体的过程就是:为了得到各个vj,一开始先让它们全都等于ui的均值,然后反复迭代就好。说白了,输出是输入的聚类结果,而聚类通常都需要迭代算法,这个迭代算法就称为“动态路由”。
至于这个动态路由的细节,其实是不固定的,取决于聚类的算法,比如关于Capsule的新文章《MATRIX CAPSULES WITH EM ROUTING》就使用了Gaussian Mixture Model来聚类。
本文给出的动态路由过程如下:

这里解释下,怎么又冒出一个 b i j b_{ij} bij来?其实 c i j c_{ij} cij就是通过对 b i j b_{ij} bij进行softmax得来的,你可以把它看成一个东西,只不过 b i j b_{ij} bij是规格化了的。
Dynamic Routing的过程可以总结为:
对于所有在 l l l 层的 Capsule i 和在 l + 1 l+1 l+1 层的 Capsule j,先初始化 b i j b_{ij} bij 等于零。然后迭代 r 次,每次先根据 b i b_i bi 计算 c i c_i ci,然后在利用 c i j c_{ij} cij 与 u ^ j ∣ i \widehat {u}_{j|i} u j∣i 计算 s j s_j sj 与 v j v_j vj。利用计算出来的 v j v_j vj 更新 b i j b_{ij} bij 以进入下一个迭代循环更新 c i j c_{ij} cij。该 Routing 算法十分容易收敛,基本上通过 3 次迭代就能有不错的效果。
3.3.小部件
上面从上而下讲完了capule结构和routing过程,但是有些小的结构(我成为小部件)没有详述,这里整理一下。
3.3.1.为耦合系数(coupling coefficients)
c i j c_{ij} cij系数由动态 Routing 过程迭代地更新与确定。Capsule i 和后一层级所有 Capsule j间的耦合系数和为 1,即如图3-1-1中, c 11 + c 12 + c 13 + c 14 = 1 c_{11}+c_{12}+c_{13}+c_{14}=1 c11+c12+c13+c14=1。此外,该耦合系数由「routing softmax」决定,且 softmax 函数中的 l o g i t s b i j logits\ b_{ij} logits bij 初始化为 0,耦合系数 c i j c_{ij} cij 的 softmax 计算方式为:
c i j = e x p ( b i j ) ∑ k e x p ( b i k ) c_{ij} = \frac{exp(b_{ij})}{\sum _k exp(b_{ik})} cij=∑kexp(bik)exp(bij)
我们可以通过测量后面层级中每一个 Capsule j 的当前输出 v j v_j vj 和 前面层级 Capsule i 的预测向量间的一致性,然后借助该测量的一致性迭代地更新耦合系数。本论文简单地通过内积度量这种一致性,即:
a i j = v j ⋅ u ^ j ∣ i a_{ij} = v_j \cdot \widehat{u}_{j|i} aij=vj⋅u j∣i
然后用 a i j a_{ij} aij来间接更新 c i j c_{ij} cij (下面详述)
这里可以认为 v j v_j vj实际上就是各个 u ^ i \widehat {u}_i u i的某个聚类中心(这里苏建林说的是和 u i u_i ui,我觉得不妥),这里的 a i j a_{ij} aij可以看做是和聚类中心的距离,从而返过来更新 c i j c_{ij} cij
3.3.1.b_ij权值更新
上面说到了通过 b i j b_{ij} bij求softmax来得到 c i j c_{ij} cij,那么这个 b i j b_{ij} bij怎么得到呢?前面也提到了,通过 v j v_j vj和 u ^ j ∣ i \widehat u_{j|i} u j∣i的内积结果来更新。具体是:
b i j ← b i j + u ^ j ∣ i ⋅ v j b_{ij} \leftarrow b_{ij} + \widehat u_{j|i} \cdot \mathbf v_j bij←bij+u j∣i⋅vj
但是这为什么呢?为什么能这么更新呢?
看下面这张图:
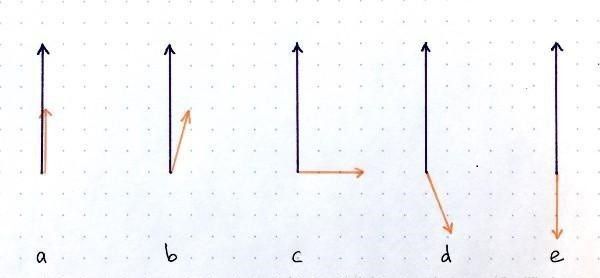
点积运算接收两个向量,并输出一个标量。对于给定长度但方向不同的的两个向量而言,点积有下列几种情况:正值、零、负值。故当 u ^ j ∣ i \widehat u_{j|i} u j∣i和 v j \mathbf v_j vj的相乘结果为正时,代表两个向量指向的方向相似,b更新结果变大,那么耦合系数就高,说明该 u ^ j ∣ i \widehat u_{j|i} u j∣i和 v j \mathbf v_j vj十分匹配。相反,若是 u ^ j ∣ i \widehat u_{j|i} u j∣i和 v j \mathbf v_j vj相乘结果为负,b更新结果变小,那么耦合系数就小,说明不匹配。通过迭代确定C,也就等于确定了一条路线,这条路线上胶囊神经元的模都特别大,路线的尽头就是那个正确预测的胶囊。
根据论文描述,b的迭代更新次数取值为3比较好。
3.3.2.squashing
可以看到在从 s j s_j sj得到 v j v_j vj时进行了非线性激活和scale,那这个函数又是怎么来的呢?为什么用这个函数呢?
文章开篇我们引用过Hinton老爷子的话,使用输入输出向量的长度表征实体(特征)的概率(也可以称为可以称为是特征的“显著程度”,这就好解释了,模长越大,这个特征越显著。),所以需要对 s j s_j sj向量进行归一化,也就是压缩,将他的模长压缩到0-1之间,才能表征概率。
Hinton选取的压缩方案是:
(3) s q u a s h ( x ) = ∥ x ∥ 2 1 + ∥ x ∥ 2 x ∥ x ∥ squash(\boldsymbol{x})=\frac{\Vert\boldsymbol{x}\Vert^2}{1+\Vert\boldsymbol{x}\Vert^2}\frac{\boldsymbol{x}}{\Vert\boldsymbol{x}\Vert}\tag{3} squash(x)=1+∥x∥2∥x∥2∥x∥x(3)
其中 x / ∥ x ∥ \boldsymbol{x}/\Vert\boldsymbol{x}\Vert x/∥x∥是很好理解的,就是将模长变为1,那么前半部分怎么理解呢?为什么这样选择?事实上,将模长压缩到0~1的方案有很多,比如:
tanh ∥ x ∥ , 1 − e − ∥ x ∥ , ∥ x ∥ 1 + ∥ x ∥ \tanh \Vert\boldsymbol{x}\Vert, \quad 1-e^{-\Vert\boldsymbol{x}\Vert}, \quad \frac{\Vert\boldsymbol{x}\Vert}{1+\Vert\boldsymbol{x}\Vert} tanh∥x∥,1−e−∥x∥,1+∥x∥∥x∥
等等,并不确定Hinton选择目前这个方案的思路。也许可以每个方案都探索一下?事实上,实验中发现,选择
s q u a s h ( x ) = ∥ x ∥ 2 0.5 + ∥ x ∥ 2 x ∥ x ∥ squash(\boldsymbol{x})=\frac{\Vert\boldsymbol{x}\Vert^2}{0.5+\Vert\boldsymbol{x}\Vert^2}\frac{\boldsymbol{x}}{\Vert\boldsymbol{x}\Vert} squash(x)=0.5+∥x∥2∥x∥2∥x∥x
效果要好一点。这个函数的特点是在模长很接近于0时起到放大作用,而不像原来的函数那样全局都压缩。
然而,一个值得思考的问题是:如果在中间层,那么这个压缩处理是不是必要的呢?因为已经有了后面说的动态路由在里边,因此即使去掉squash函数,网络也已经具有了非线性了,因此直觉上并没有必要在中间层也引入特征压缩,正如普通神经网络也不一定要用sigmoid函数压缩到0~1。我觉得这个要在实践中好好检验一下。(这里再下面讲的CapNet里面中间层也用了该函数)
4.CapsNet模型介绍
4.1.层次结构
Hinton 等人实现了一个简单的 CapsNet 架构,该架构由两个卷积层和一个全连接层组成,其中第一个为一般的卷积层,第二个卷积相当于为 Capsule 层做准备,并且该层的输出为向量,所以它的维度要比一般的卷积层再高一个维度。第三层才是真正意义上的capsule,通过向量的输入与 Routing 过程等构建出 10 个 v j v_j vj向量,每一个向量的长度都直接表示某个类别的概率。

第一层就是一个常规的conv layer,第一个卷积层使用了 256 个 9×9 卷积核,步幅为 1,且使用了 ReLU 激活函数。该卷积操作应该没有使用 Padding,输出的张量才能是 20×20×256。此外,CapsNet 的卷积核感受野使用的是 9×9,相比于其它 3×3 或 5×5 的要大一些,这个能是因为较大的感受野在 CNN 层次较少的情况下能感受的信息越多。这两层间的权值数量应该为 9×9×256+256=20992。
按照原文的意思,这层的主要作用就是先在图像pixel上做一次局部特征检测,然后才送给capsule。至于为何不从第一层就开始使用capsule提取特征?当然,MNIST是灰度图,每个pixel是一个标量,每个pixel看作低层capsule的输出 u i u_i ui的话,就不符合capsule输入输出都是vector的要求(不考虑标量是长度为1的vector这个情况,那将退化成现在的CNN模式)。
第二个卷积层开始为 Capsule 层的输入而构建相应的张量结构。我们可以从上图看出第二层卷积操作后生成的张量维度为 6×6×8×32,那么我们该如何理解这个张量呢?云梦居客在知乎上给出了一个十分形象且有意思的解释,如前面章节所述,如果我们先考虑 32 个(32 channel)9×9 的卷积核在步幅为 2 的情况下做卷积,那么实际上得到的是传统的 6×6×32 的张量,即等价于 6×6×1×32。
因为传统卷积操作每次计算的输出都是一个标量,而 PrimaryCaps 的输出需要是一个长度为 8 的向量,因此传统卷积下的三维输出张量 6×6×1×32 就需要变化为四维输出张量 6×6×8×32。如下所示,其实我们可以将第二个卷积层看作对维度为 20×20×256 的输入张量执行 8 次不同权重的 Conv2d 操作(其实可以设置*8的filter number,等效),每次 Conv2d 都执行带 32 个 9×9 卷积核、步幅为 2 的卷积操作。
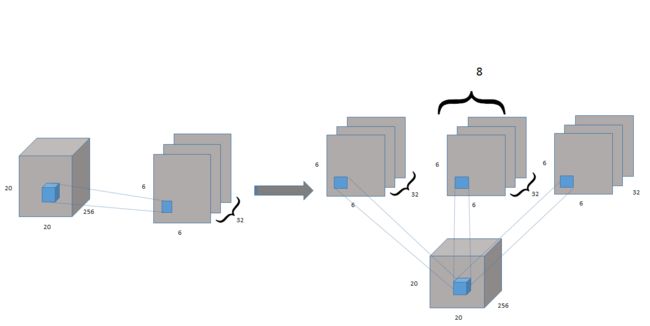
相当于上图中左面8个并行,从上可知 PrimaryCaps 就相当于一个深度为 32 的普通卷积层,只不过每一层由以前的标量值变成了长度为 8 的向量。
第三层 DigitCaps 在第二层输出的向量基础上进行传播与 Routing 更新,可以说是真正的capsule。第二层共输出 6×6×32=1152 个向量,每一个向量的维度为 8,即第 i 层共有 1152 个 Capsule 单元。而第三层 j 有 10 个标准的 Capsule 单元,每个 Capsule 的输出向量有 16 个元素。前一层的 Capsule 单元数是 1152 个,那么 w i j w_{ij} wij 将有 1152×10 个,且每一个 w i j w_{ij} wij的维度为 8×16。当 u i u_i ui 与对应的 w i j w_{ij} wij 相乘得到预测向量后,我们会有 1152×10 个耦合系数 c i j c_{ij} cij,对应加权求和后会得到 10 个 16×1 的输入向量。将该输入向量输入到「squashing」非线性函数中求得最终的输出向量 v j v_j vj,其中 v j v_j vj 的长度就表示识别为某个类别的概率。
4.2.损失函数
我们该如何构建损失函数,并根据该损失函数迭代地更新整个网络?前面我们耦合系数 c_ij 是通过一致性 Routing 进行更新的,他并不需要根据损失函数更新,但整个网络其它的卷积参数和 Capsule 内的 W_ij 都需要根据损失函数进行更新。一般我们就可以对损失函数直接使用标准的反向传播更新这些参数,而在原论文中,作者采用了 SVM 中常用的 Margin loss,该损失函数的表达式为:
L c = T c m a x ( 0 , m + − ∣ ∣ v c ∣ ∣ ) 2 + λ ( 1 − T c ) m a x ( 0 , ∣ ∣ v c ∣ ∣ − m − ) 2 L_c = T_c max(0,m^+ - ||\mathbf v_c||)^2 + \lambda(1-T_c) max(0,||\mathbf v_c||-m^-)^2 Lc=Tcmax(0,m+−∣∣vc∣∣)2+λ(1−Tc)max(0,∣∣vc∣∣−m−)2
其中 c 是分类类别, T c T_c Tc 为分类的指示函数(也就是groundtruthc ,存在为 1,c 不存在为 0), m + m^+ m+ 为上边界, m − m^- m− 为下边界。此外, v c \mathbf v_c vc 的模即向量的 L2 距离。
这里paper还通过重构即我们希望利用预测的类别重新构建出该类别代表的实际图像,例如我们前面部分的模型预测出该图片属于一个类别,然后后面重构网络会将该预测的类别信息重新构建成一张图片。也就是在最后的 v c \mathbf v_c vc后面接了几个全连接层进行预测,并将这一过程的损失函数通过计算 FC Sigmoid 层的输出像素点与原始图像像素点间的欧几里德距离而构建。Hinton 等人还按 0.0005 的比例缩小重构损失,以使它不会主导训练过程中的 Margin loss。
因为这一部分我觉得可迁移能力比较差,所以不详细说了(其实也没啥可说的),可详参paper
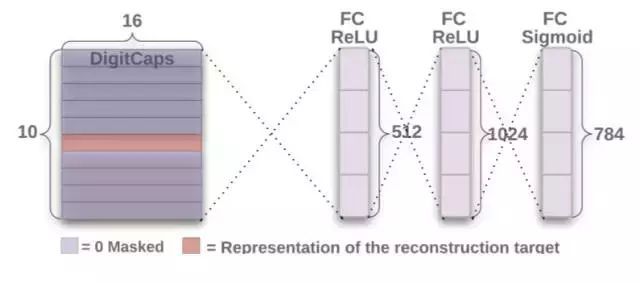
4.3.关于Digit层权值共享
贸然多出这么一节来有点突兀,但是我实在觉得capsule里面的这个仿射参数有点多,也就是这里的 W i j W_{ij} Wij,在原版的文章中,他的维度应该 l l l_layer_capsule_number* l l l_plus1_layer_capsule_number* l l l_layer_capsule_vector_len* l l l_plus1_layer_capsule_vector_len,相当于全连接层,并且还需要把 l l l层的vector的维度(8)升到 l + 1 l+1 l+1的维度(16),所以参数是很多的。
所以能不能共享参数呢,也就变成了卷积的形式,我也从网上看到了苏建林的文章,并且还给出了代码(赞!),详细的代码地址可参考苏建林capsule第36-49行源码。
if self.share_weights:
self.W = self.add_weight(name='capsule_kernel',
shape=(
1,
input_dim_capsule,
self.num_capsule * self.dim_capsule
),
initializer='glorot_uniform',
trainable=True)
else:
input_num_capsule = input_shape[-2]
self.W = self.add_weight(name='capsule_kernel',
shape=(
input_num_capsule,
input_dim_capsule,
self.num_capsule * self.dim_capsule
),
initializer='glorot_uniform',
trainable=True)
5.源码解析
这里提供几分我觉得比较靠谱的源码,源码比较简单,更明了:
- ML-Tutorial-Experiment juputer的版本,最简单,没有之一
- 苏建林capsule
- 云梦居客
6.相关讨论
capsule出来之后还是有不少观点和争论的,网上的很多说法都有,但是这些问题可以给自己带来启发,也希望能激发自己更多思考。


关于苏剑林的一些一些讨论
7.capsule相关论文
- Matrix capsules with EM Routing
可参考文章“Understanding Matrix capsules with EM Routing (Based on Hinton’s Capsule Networks)” - Investigating Capsule Networks with Dynamic Routing for Text Classification
可参考文章基于Capsule Networks的文本分类
参考文献
- 先读懂CapsNet架构然后用TensorFlow实现,这应该是最详细的教程了 博主推荐
- 如何看待Hinton的论文《Dynamic Routing Between Capsules》 讨论区
- CapsNet ——胶囊网络原理
- 深度神经网络简述与Capsule介绍