android直播中的一些流媒体技术浅析
最近在做一个直播的android手机app,难点在于流媒体的处理,主要是对流媒体进行编码与传输,在此用H264编码,传输协议采用RTMP,流媒体服务器用nginx并进行配置。本文先写编码相关的知识。
所谓视频编码方式就是指通过特定的压缩技术,将某个视频格式的文件转换成另一种视频格式文件的方式。
压缩技术:
有损压缩:将视频数字信号合并整理,信号本身没有损失
无损压缩:进一步根据人眼的特性(诸如时滞性等),减少信号两,信号本身有一定的损失,也就是图象质量有损失。
编码方案
音频视频编码方法有很多,主要有2类:
MPEG系列:
(由ISO[国际标准组织机构]下属的MPEG[运动图象专家组]开发 )视频编码方面主要是Mpeg1(vcd用的就是它)、Mpeg2(DVD使用)、Mpeg4(的DVDRIP使用的都是它的变种,如:divx,xvid等)、Mpeg4 AVC(正热门);音频编码方面主要是MPEG Audio Layer 1/2、MPEG Audio Layer 3(大名鼎鼎的mp3)、MPEG-2 AAC 、MPEG-4 AAC等等。注意:DVD音频没有采用Mpeg的。
H.26X系列:
(由ITU[国际电传视讯联盟]主导,侧重网络传输,注意:只是视频编码)
包括H.261、H.262、H.263、H.263+、H.263++、H.264(就是MPEG4 AVC-合作的结晶)[1]
编码原理
数字化后的视频信号能进行压缩主要依据两个基本条件:
数据冗余:
例如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。消除这些冗余并不会导致信息损失,属于无损压缩。
视觉冗余:
人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。这种压缩属于有损压缩。
数字视频信号的压缩正是基于上述两种条件,使得视频数据量得以极大的压缩,有利于传输和存储。一般的数字视频压缩编码方法都是混合编码,即将变换编码,运动估计和运动补偿,以及熵编码三种方式相结合来进行压缩编码。通常使用变换编码来消去除图像的帧内冗余,用运动估计和运动补偿来去除图像的帧间冗余,用熵编码来进一步提高压缩的效率。
视频图像数据有极强的相关性,也就是说有大量的冗余信息。其中冗余信息可分为空域冗余信息和时域冗余信息。压缩技术就是将数据中的冗余信息去掉(去除数据之间的相关性),压缩技术包含帧内图像数据压缩技术、帧间图像数据压缩技术和熵编码压缩技术。
- 去时域
使用帧间编码技术可去除时域冗余信息,它包括以下三部分:
- 运动补偿
运动补偿是通过先前的局部图像来预测、补偿当前的局部图像,它是减少帧序列冗余信息的有效方法。
- 运动表示
不同区域的图像需要使用不同的运动矢量来描述运动信息。运动矢量通过熵编码进行压缩。
-运动估计
运动估计是从视频序列中抽取运动信息的一整套技术。
注:通用的压缩标准都使用基于块的运动估计和运动补偿。 - 去空域
主要使用帧内编码技术和熵编码技术:
-变换编码
帧内图像和预测差分信号都有很高的空域冗余信息。变换编码将空域信号变换到另一正交矢量空间,使其相关性下降,数据冗余度减小。
- 量化编码
经过变换编码后,产生一批变换系数,对这些系数进行量化,使编码器的输出达到一定的位率。这一过程导致精度的降低。
-熵编码
熵编码是无损编码。它对变换、量化后得到的系数和运动信息,进行进一步的压缩。
关于编码原理可以参考http://blog.csdn.net/leixiaohua1020/article/details/28114081
H264编码原理
H264是新一代的编码标准,以高压缩高质量和支持多种网络的流媒体传输著称,在编码方面,我理解的他的理论依据是:参照一段时间内图像的统计结果表明,在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内。所以对于一段变化不大图像画面,我们可以先编码出一个完整的图像帧A,随后的B帧就不编码全部图像,只写入与A帧的差别,这样B帧的大小就只有完整帧的1/10或更小!B帧之后的C帧如果变化不大,我们可以继续以参考B的方式编码C帧,这样循环下去。这段图像我们称为一个序列(序列就是有相同特点的一段数据),当某个图像与之前的图像变化很大,无法参考前面的帧来生成,那我们就结束上一个序列,开始下一段序列,也就是对这个图像生成一个完整帧A1,随后的图像就参考A1生成,只写入与A1的差别内容。
在H264协议里定义了三种帧,完整编码的帧叫I帧,参考之前的I帧生成的只包含差异部分编码的帧叫P帧,还有一种参考前后的帧编码的帧叫B帧。
H264采用的核心算法是帧内压缩和帧间压缩,帧内压缩是生成I帧的算法,帧间压缩是生成B帧和P帧的算法。
序列的说明
在H264中图像以序列为单位进行组织,一个序列是一段图像编码后的数据流,以I帧开始,到下一个I帧结束。
一个序列的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。H.264 引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
一个序列就是一段内容差异不太大的图像编码后生成的一串数据流。当运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个I帧,然后一直P帧、B帧了。当运动变化多时,可能一个序列就比较短了,比如就包含一个I帧和3、4个P帧。
三种帧的说明
- 1、I帧
I帧:帧内编码帧 ,I帧表示关键帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)
I帧特点:
1)它是一个全帧压缩编码帧。它将全帧图像信息进行JPEG压缩编码及传输;
2)解码时仅用I帧的数据就可重构完整图像;
3)I帧描述了图像背景和运动主体的详情;
4)I帧不需要参考其他画面而生成;
5)I帧是P帧和B帧的参考帧(其质量直接影响到同组中以后各帧的质量);
6)I帧是帧组GOP的基础帧(第一帧),在一组中只有一个I帧;
7)I帧不需要考虑运动矢量;
8)I帧所占数据的信息量比较大。 - 2、P帧
P帧:前向预测编码帧。P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧的画面差别的数据)
P帧的预测与重构:P帧是以I帧为参考帧,在I帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。在接收端根据运动矢量从I帧中找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。
P帧特点:
1)P帧是I帧后面相隔1~2帧的编码帧;
2)P帧采用运动补偿的方法传送它与前面的I或P帧的差值及运动矢量(预测误差);
3)解码时必须将I帧中的预测值与预测误差求和后才能重构完整的P帧图像;
4)P帧属于前向预测的帧间编码。它只参考前面最靠近它的I帧或P帧;
5)P帧可以是其后面P帧的参考帧,也可以是其前后的B帧的参考帧;
6)由于P帧是参考帧,它可能造成解码错误的扩散;
7)由于是差值传送,P帧的压缩比较高。 - 3、B帧
B帧:双向预测内插编码帧。B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别(具体比较复杂,有4种情况,但我这样说简单些),换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累。
B帧的预测与重构
B帧以前面的I或P帧和后面的P帧为参考帧,“找出”B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。接收端根据运动矢量在两个参考帧中“找出(算出)”预测值并与差值求和,得到B帧“某点”样值,从而可得到完整的B帧。
B帧特点
1)B帧是由前面的I或P帧和后面的P帧来进行预测的;
2)B帧传送的是它与前面的I或P帧和后面的P帧之间的预测误差及运动矢量;
3)B帧是双向预测编码帧;
4)B帧压缩比最高,因为它只反映丙参考帧间运动主体的变化情况,预测比较准确;
5)B帧不是参考帧,不会造成解码错误的扩散。
注:I、B、P各帧是根据压缩算法的需要,是人为定义的,它们都是实实在在的物理帧。一般来说,I帧的压缩率是7(跟JPG差不多),P帧是20,B帧可以达到50。可见使用B帧能节省大量空间,节省出来的空间可以用来保存多一些I帧,这样在相同码率下,可以提供更好的画质。
压缩算法的说明
h264的压缩方法:
1.分组:把几帧图像分为一组(GOP,也就是一个序列),为防止运动变化,帧数不宜取多。
2.定义帧:将每组内各帧图像定义为三种类型,即I帧、B帧和P帧;
3.预测帧:以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧;
4.数据传输:最后将I帧数据与预测的差值信息进行存储和传输。
帧内(Intraframe)压缩也称为空间压缩(Spatial compression)。当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩,跟编码jpeg差不多。
帧间(Interframe)压缩的原理是:相邻几帧的数据有很大的相关性,或者说前后两帧信息变化很小的特点。也即连续的视频其相邻帧之间具有冗余信息,根据这一特性,压缩相邻帧之间的冗余量就可以进一步提高压缩量,减小压缩比。帧间压缩也称为时间压缩(Temporal compression),它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩一般是无损的。帧差值(Frame differencing)算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
原理可以参考http://blog.sina.com.cn/s/blog_4ad7c2540101me90.html
NAL简介与I帧判断
1、NAL全称Network Abstract Layer, 即网络抽象层。
在H.264/AVC视频编码标准中,整个系统框架被分为了两个层面:视频编码层面(VCL)和网络抽象层面(NAL)。其中,前者负责有效表示视频数据的内容,而后者则负责格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。因此我们平时的每帧数据就是一个NAL单元(SPS与PPS除外)。在实际的H264数据帧中,往往帧前面带有00 00 00 01 或 00 00 01分隔符,一般来说编码器编出的首帧数据为PPS与SPS,接着为I帧……
如下图:
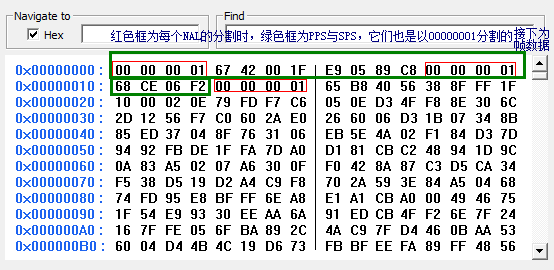
2、如何判断帧类型(是图像参考帧还是I、P帧等)?
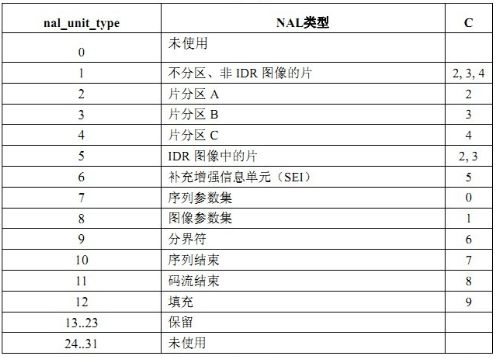
NALU类型是我们判断帧类型的利器,从官方文档中得出如下图:
我们还是接着看最上面图的码流对应的数据来层层分析,以00 00 00 01分割之后的下一个字节就是NALU类型,将其转为二进制数据后,解读顺序为从左往右算,如下:
(1)第1位禁止位,值为1表示语法出错
(2)第2~3位为参考级别
(3)第4~8为是nal单元类型
例如上面00000001后有67,68以及65
其中0x67的二进制码为:
0110 0111
4-8为00111,转为十进制7,参考第二幅图:7对应序列参数集SPS
其中0x68的二进制码为:
0110 1000
4-8为01000,转为十进制8,参考第二幅图:8对应图像参数集PPS
其中0x65的二进制码为:
0110 0101
4-8为00101,转为十进制5,参考第二幅图:5对应IDR图像中的片(I帧)
所以判断是否为I帧的算法为: (NALU类型 & 0001 1111) = 5 即 NALU类型 & 31 = 5
比如0x65 & 31 = 5
一些名词解释:
VCL video coding layer 视频编码层
NAL network abstraction layer 网络提取层
PTS:Presentation Time Stamp。PTS主要用于度量解码后的视频帧什么时候被显示出来
DTS:Decode Time Stamp。DTS主要是标识读入内存中的bit流在什么时候开始送入解码器中进行解码。
序列的参数集(SPS):包括了一个图像序列的所有信息,
图像的参数集(PPS):包括了一个图像所有片的信息。
NAL以NALU(NAL unit)为单元来支持编码数据在基于分组交换技术网络中传输。 它定义了符合传输层或存储介质要求的数据格式,同时给出头信息,从而提供了视频编码和外部世界的接口。
NALU:定义了可用于基于分组和基于比特流系统的基本格式 RTP封装:只针对基于NAL单元的本地NAL接口。
三种不同的数据形式:
SODB 数据比特串-->最原始的编码数据
RBSP 原始字节序列载荷-->在SODB的后面填加了结尾比特(RBSP trailing bits 一个bit“1”)若干比特“0”,以便字节对齐
EBSP 扩展字节序列载荷–>在RBSP基础上填加了仿校验字节(0X03)它的原因是: 在NALU加到Annexb上时,需要添加每 组NALU之前的开始码
参考http://blog.chinaunix.net/uid-23883288-id-3034586.html