MYSQL高级编程学习总结
文章目录
- MYSQL高级编程
- 视图view
- 视图的定义和作用
- 具体操作
- 创建
- 修改
- 删除
- 查看
- 索引key/index
- 作用
- 分类
- 使用
- 创建/修改
- 删除索引
- 查看索引
- 索引使用限制条件
- 存储过程procedure
- 简介
- 存储过程创建及使用
- 创建
- 参数
- 调用
- 查询
- 修改
- 删除
- 函数function
- 创建
- 使用
- 删除
- 触发器trigger
- 创建
- NEW与OLD对象
- 查看触发器
- 删除触发器
- 事务transaction
- 定义
- 事务四大特征(ACID)
- 事务开启与结束
- 事务提交与回滚
- 事务的隔离性
- 设置隔离级别
- 流程控制语句
- if
- case
- loop
- while
MYSQL高级编程
思维导图
视图view
视图的定义和作用
视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,不存储具体的数据
具体操作
创建
create view 视图名 as 表达式
例:
create view stu as select sName,sId from Student where location like '%杭州%'
把来自杭州市的学生姓名和id作为视图
修改
alter view 视图名 as 表达式
create view stu as select sName,sId from Student where location like '%成都%'
删除
drop view 视图1,视图2...
查看
desc 视图名;
SHOW TABLE STATUS (like) 视图名
索引key/index
作用
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
关于具体为什么可以加快查询速度本文不做探讨
分类
- 普通索引
- 唯一索引(unique)
- 全文索引(full)
- 单列/多列索引
- 组合索引
使用
创建/修改
假设已创建表student
drop table if exists Students;
create table Students
(
sNo char(8) not null,
sPassword varchar(12),
sName varchar(10),
sMajor varchar(20),
sCard char(18),
sMobile char(11),
primary key (sNo) /*建表时创建主键索引*/
);
建表时创建:[unique] key keyname (column_list)
primary key (column_list)
已完成建表后创建:create [UNIQUE] key/index keyname on table_name(column_list);
ALTER TABLE table_name ADD UNIQUE indexName ON (column)
删除索引
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
查看索引
show index from tablename;
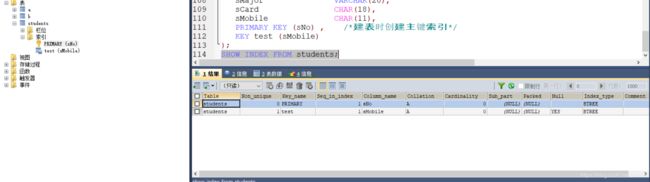
· Table
表的名称。
· Non_unique
如果索引不能包括重复词,则为0。如果可以,则为1。
· Key_name
索引的名称。
· Seq_in_index
索引中的列序列号,从1开始。
· Column_name
列名称。
· Collation
列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。
· Cardinality
索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
· Sub_part
如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
· Packed
指示关键字如何被压缩。如果没有被压缩,则为NULL。
· Null
如果列含有NULL,则含有YES。如果没有,则该列含有NO。
· Index_type
用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
· Comment
索引使用限制条件
由于索引的创建会大大增加数据库占用的存储空间,以下条件满足时则不宜使用索引
表记录太少
经常插入、删除、修改的表
数据重复且分布平均的表字段
经常和主字段一块查询但主字段索引值比较多的表字段
存储过程procedure
简介
SQL语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
存储过程是可编程的函数,在数据库中创建并保存,可以由SQL语句和控制结构组成。当想要在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟,它允许控制数据的访问方式。
存储过程的优点:
(1).增强SQL语言的功能和灵活性:存储过程可以用控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
(2).标准组件式编程:存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
(3).较快的执行速度:如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
(4).减少网络流量:针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织进存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大减少网络流量并降低了网络负载。
(5).作为一种安全机制来充分利用:通过对执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
存储过程创建及使用
创建
CREATE PROCEDURE 过程名([[IN|OUT|INOUT] 参数名 数据类型[,[IN|OUT|INOUT] 参数名 数据类型…]]) [特性 …] 过程体
DELIMITER //
CREATE PROCEDURE myproc(OUT s int)
BEGIN
SELECT COUNT(*) INTO s FROM students;
END
//
DELIMITER ;
参数
存储过程根据需要可能会有输入、输出、输入输出参数,如果有多个参数用","分割开。MySQL存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT:
IN:参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值
OUT:该值可在存储过程内部被改变,并可返回
INOUT:调用时指定,并且可被改变和返回
调用
call procedure_name(参数)
查询
SHOW PROCEDURE STATUS WHERE db='数据库名';
SHOW CREATE PROCEDURE 数据库.存储过程名;
修改
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
characteristic:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
sp_name参数表示存储过程或函数的名称;
characteristic参数指定存储函数的特性。
CONTAINS SQL表示子程序包含SQL语句,但不包含读或写数据的语句;
NO SQL表示子程序中不包含SQL语句;
READS SQL DATA表示子程序中包含读数据的语句;
MODIFIES SQL DATA表示子程序中包含写数据的语句。
SQL SECURITY { DEFINER | INVOKER }指明谁有权限来执行,DEFINER表示只有定义者自己才能够执行;INVOKER表示调用者可以执行。
COMMENT 'string’是注释信息。
实例:
#将读写权限改为MODIFIES SQL DATA,并指明调用者可以执行。
ALTER PROCEDURE num_from_employee
MODIFIES SQL DATA
SQL SECURITY INVOKER ;
#将读写权限改为READS SQL DATA,并加上注释信息'FIND NAME'。
ALTER PROCEDURE name_from_employee
READS SQL DATA
COMMENT 'FIND NAME' ;
删除
DROP PROCEDURE [过程1[,过程2…]]
函数function
函数和存储过程类似这里一带而过
创建
CREATE FUNCTION func_name ( [func_parameter] ) //括号是必须的,参数是可选的
RETURNS type
[ characteristic ...] routine_body
CREATE FUNCTION 用来创建函数的关键字;
func_name 表示函数的名称;
func_parameters为函数的参数列表,参数列表的形式为:[IN|OUT|INOUT] param_name type
使用
select func_name(func_parameter)
删除
drop func_name(parameter_list)
触发器trigger
创建
CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
[trigger_order]
trigger_body
trigger_time: { BEFORE | AFTER }
trigger_event: { INSERT | UPDATE | DELETE }
trigger_order: { FOLLOWS | PRECEDES } other_trigger_name
BEFORE和AFTER参数指定了触发执行的时间,在事件之前或是之后。
FOR EACH ROW表示任何一条记录上的操作满足触发事件都会触发该触发器,也就是说触发器的触发频率是针对每一行数据触发一次。
tigger_event详解:
①INSERT型触发器:插入某一行时激活触发器,可能通过INSERT、LOAD DATA、REPLACE 语句触发(LOAD DAT语句用于将一个文件装入到一个数据表中,相当与一系列的INSERT操作);
②UPDATE型触发器:更改某一行时激活触发器,可能通过UPDATE语句触发;
③DELETE型触发器:删除某一行时激活触发器,可能通过DELETE、REPLACE语句触发。
trigger_order是MySQL5.7之后的一个功能,用于定义多个触发器,使用follows(尾随)或precedes(在…之先)来选择触发器执行的先后顺序。
例如:
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN
执行语句列表
END;
实例:
create trigger sq_trig after insert on 'Student' FOR EACH ROW
BEGIN
INSERT INTO time VALUES(NOW());
END
当然只有一个语句的触发器也可以这样定义:
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件 ON 表名 FOR EACH ROW 执行语句;
NEW与OLD对象
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据,来引用触发器中发生变化的记录内容,具体地:
①在INSERT型触发器中,NEW用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
②在UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据;
③在DELETE型触发器中,OLD用来表示将要或已经被删除的原数据;
如:
NEW.columnName (columnName为相应数据表某一列名)
set new.sName=‘xxx’
查看触发器
SHOW TRIGGERS
显示所有触发器的基本信息;无法查询指定的触发器
SELECT * FROM information_schema.triggers
显示所有触发器的详细信息;同时,该方法可以查询制定触发器的详细信息
删除触发器
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
事务transaction
定义
事务:一个最小的不可再分的工作单元;通常一个事务对应一个完整的业务(例如银行账户转账业务,该业务就是一个最小的工作单元)
例如,银行的转账就可以视为银行业务的最小单位之一,从账户A转账到账户B整个过程称为事务,事务可以操作成功,也可以回滚操作(由于某些原因导致转账失败)
事务四大特征(ACID)
原子性(A):事务是最小单位,不可再分
一致性©:事务要求所有的DML语句操作的时候,必须保证同时成功或者同时失败
隔离性(I):事务A和事务B之间具有隔离性
持久性(D):是事务的保证,事务终结的标志(内存的数据持久到硬盘文件中)
事务开启与结束
1、任何一条DML语句标志着事务的开始
2 、
- 提交:成功的结束,将所有的DML语句操作历史记录和底层硬盘数据来一次同步
- 回滚:失败的结束,将所有的DML语句操作历史记录全部清空
事务提交与回滚
提交事务:
start transaction
DML语句
commit
回滚事务(事务失败):
start transaction
DML语句
rollback
事务的隔离性
-
事物A和事物B之间具有一定的隔离性
-
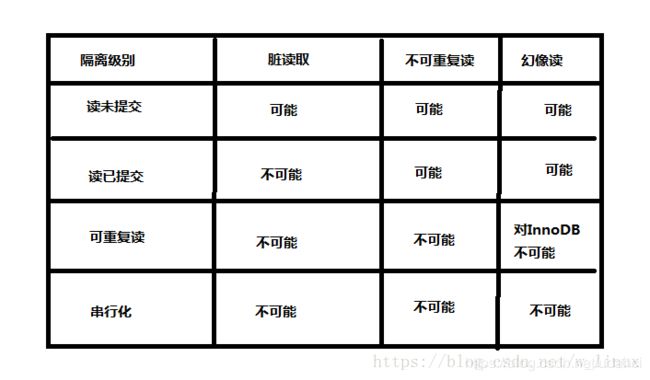
隔离性有隔离级别(4个)
读未提交:read uncommitted
读已提交:read committed(Oracle默认级别)
可重复读:repeatable read(mysql默认级别)
串行化:serializable
设置隔离级别
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL
其中的可以是:
– READ UNCOMMITTED
– READ COMMITTED
– REPEATABLE READ
– SERIALIZABLE
例如: SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
流程控制语句
IF语句、CASE语句、LOOP语句、WHILE语句、LEAVE语句、ITERATE语句、REPEAT语句和WHILE语句
※每个流程中,可能包含一个单独语句,也可以是使用BEGIN……END构造的复合语句,可以嵌套
以下:
Expr_condition,表示判断条件
Statement_list,表示SQL语句列表,它可以包括一个或多个语句
if
IF expr_condition THEN statement_list
[ELSEIF expr_condition THEN statement_list]
[ELSE statement_list]
END IF
case
CASE case_expr
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list]……
[ELSE statement_list]
END CASE
或: CASE
WHEN expr_condition THEN statement_list
[WHEN expr_condition THEN statement_list]
[ELSE statement_list]
END CASE;
loop
[loop_label:] LOOP
Statement_list
END LOOP [loop_label]
while
[while_lable:] WHILE expr_condition DO
Statement_list
END WHILE [while_lable]