spring源码深度解析---bean的加载(中)
spring源码深度解析—bean的加载(中)
1. 缓存中获取单例bean
之前一篇我们介绍过FactoryBean的用法之后,就可以了解bean加载的过程了。单例在Spring的同一个容器内只会被创建一次,后续再获取bean直接从单例缓存中获取,当然这里也只是尝试加载,首先尝试从缓存中加载,然后再次尝试从singletonFactorry加载因为在创建单例bean的时候会存在依赖注入的情况,而在创建依赖的时候为了避免循环依赖,Spring创建bean的原则不等bean创建完成就会创建bean的ObjectFactory提早曝光加入到缓存中,一旦下一个bean创建时需要依赖上个bean,则直接使用ObjectFactory,接下来我们看下获取单例bean的方法getSingleton(beanName),进入方法体:
@Override
@Nullable
public Object getSingleton(String beanName) {
//参数true是允许早期依赖
return getSingleton(beanName, true);
}
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//检查缓存中是否存在实例
Object singletonObject = this.singletonObjects.get(beanName);
//如果缓存为空且单例bean正在创建中,则锁定全局变量
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//如果此bean正在加载,则不处理
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//当某些方法需要提前初始化的时候会直接调用addSingletonFactory把对应的ObjectFactory初始化策略存储在singletonFactory中
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//使用预先设定的getObject方法
singletonObject = singletonFactory.getObject();
记录在缓存中,注意earlySingletonObjects和singletonFactories是互斥的
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}接下来我们根据源码再来梳理下这个方法,这样更易于理解,这个方法先尝试从singletonObjects里面获取实例,如果如果获取不到再从earlySingletonObjects里面获取,如果还获取不到,再尝试从singletonFactories里面获取beanName对应的ObjectFactory,然后再调用这个ObjectFactory的getObject方法创建bean,并放到earlySingletonObjects里面去,并且从singletonFactoryes里面remove调这个ObjectFactory,而对于后续所有的内存操作都只为了循环依赖检测时候使用,即allowEarlyReference为true的时候才会使用。
这里涉及到很多个存储bean的不同map,简单解释下:
singletonObjects:用于保存BeanName和创建bean实例之间的关系,beanName–>bean Instance
singletonFactories:用于保存BeanName和创建bean的工厂之间的关系,banName–>ObjectFactory
earlySingletonObjects:也是保存BeanName和创建bean实例之间的关系,与singletonObjects的不同之处在于,当一个单例bean被放到这里面后,那么当bean还在创建过程中,就可以通过getBean方法获取到了,其目的是用来检测循环引用。
registeredSingletons:用来保存当前所有已注册的bean.
2. 从bean的实例中获取对象
获取到bean以后就要获取实例对象了,这里用到的是getObjectForBeanInstance方法。getObjectForBeanInstance是个频繁使用的方法,无论是从缓存中获得bean还是根据不同的scope策略加载bean.总之,我们得到bean的实例后,要做的第一步就是调用这个方法来检测一下正确性,其实就是检测获得Bean是不是FactoryBean类型的bean,如果是,那么需要调用该bean对应的FactoryBean实例中的getObject()作为返回值。
无论是从缓存中获取到的bean还是通过不同的scope策略加载的bean都只是最原始的bean状态,并不一定是我们最终想要的bean.举个例子,加入我们需要对工厂bean进行的处理,那么这里得到的其实是工厂bean的初始状态,但我们真正想要的是工厂bean中定义的factory-method方法中返回的bean,而getObjectForBeanInstance方法就是完成这个。接下来我们看下此方法的源码:
protected Object getObjectForBeanInstance(
Object beanInstance, String name, String beanName, @Nullable RootBeanDefinition mbd) {
//如果指定的name是工厂相关的(以&开头的)
if (BeanFactoryUtils.isFactoryDereference(name)) {
//如果是NullBean则直接返回此bean
if (beanInstance instanceof NullBean) {
return beanInstance;
}
//如果不是FactoryBean类型,则验证不通过抛出异常
if (!(beanInstance instanceof FactoryBean)) {
throw new BeanIsNotAFactoryException(transformedBeanName(name), beanInstance.getClass());
}
}
// Now we have the bean instance, which may be a normal bean or a FactoryBean.
// If it's a FactoryBean, we use it to create a bean instance, unless the
// caller actually wants a reference to the factory.
if (!(beanInstance instanceof FactoryBean) || BeanFactoryUtils.isFactoryDereference(name)) {
return beanInstance;
}
Object object = null;
if (mbd == null) {
object = getCachedObjectForFactoryBean(beanName);
}
if (object == null) {
// Return bean instance from factory.
FactoryBean factory = (FactoryBean) beanInstance;
// Caches object obtained from FactoryBean if it is a singleton.
if (mbd == null && containsBeanDefinition(beanName)) {
mbd = getMergedLocalBeanDefinition(beanName);
}
boolean synthetic = (mbd != null && mbd.isSynthetic());
object = getObjectFromFactoryBean(factory, beanName, !synthetic);
}
return object;
}我们详细分析下代码会发现此方法中没有重要信息,大多都是一些辅助功能性的检查判断,而真正的核心功能是在getObjectFromFactoryBean(factory, beanName, !synthetic)方法中实现的,继续跟进代码:
protected Object getObjectFromFactoryBean(FactoryBean factory, String beanName, boolean shouldPostProcess) {
if (factory.isSingleton() && containsSingleton(beanName)) {
synchronized (getSingletonMutex()) {
Object object = this.factoryBeanObjectCache.get(beanName);
if (object == null) {
object = doGetObjectFromFactoryBean(factory, beanName);
// Only post-process and store if not put there already during getObject() call above
// (e.g. because of circular reference processing triggered by custom getBean calls)
Object alreadyThere = this.factoryBeanObjectCache.get(beanName);
if (alreadyThere != null) {
object = alreadyThere;
}
else {
if (shouldPostProcess) {
try {
object = postProcessObjectFromFactoryBean(object, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName,
"Post-processing of FactoryBean's singleton object failed", ex);
}
}
if (containsSingleton(beanName)) {
this.factoryBeanObjectCache.put(beanName, object);
}
}
}
return object;
}
}
else {
Object object = doGetObjectFromFactoryBean(factory, beanName);
if (shouldPostProcess) {
try {
object = postProcessObjectFromFactoryBean(object, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Post-processing of FactoryBean's object failed", ex);
}
}
return object;
}
}在这段代码中,没有太多东西,基本上做了一件事情,就是如果返回的bean是单例的,就必须保证全局唯一,同时不可重复创建,可以使用缓存来提高性能,也就是说加载过就记录下来以便于下次复用。而在doGetObjectFromFactoryBean我们看到了想要的方法,就是Object=factory.getObejct(),继续看方法体:
private Object doGetObjectFromFactoryBean(final FactoryBean factory, final String beanName)
throws BeanCreationException {
Object object;
try {
if (System.getSecurityManager() != null) {
AccessControlContext acc = getAccessControlContext();
try {
object = AccessController.doPrivileged((PrivilegedExceptionAction以前我们曾经介绍过FactoryBean的调用方法,如果bean声明为FactoryBean类型,则当提取bean时候提取的不是FactoryBean,而是FactoryBean中对应的getObject方法返回的bean,而doGetObjectFromFactroyBean真是实现这个功能。而调用完doGetObjectFromFactoryBean方法后,并没有直接返回,getObjectFromFactoryBean方法中还调用了object = postProcessObjectFromFactoryBean(object, beanName);方法,在子类AbstractAutowireCapableBeanFactory,有这个方法的实现:
@Override
protected Object postProcessObjectFromFactoryBean(Object object, String beanName) {
return applyBeanPostProcessorsAfterInitialization(object, beanName);
}
@Override
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
Object current = beanProcessor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}对于后处理器的使用,我们目前还没接触,后续会有大量篇幅介绍,这里我们只需要了解在Spring获取bean的规则中有这样一条:尽可能保证所有bean初始化后都会调用注册的BeanPostProcessor的postProcessAfterInitialization方法进行处理,在实际开发过程中大可以针对此特性设计自己的业务处理。
3. 获取单例
之前我们说过从缓存中获取单例的过程,但如果缓存中不存在已经加载的单例bean就需要从头开始bean的加载过程了,Spring中使用了getSingleton的重载方法实现bean的加载过程。我们先回头看下doGetBean方法,如下图:
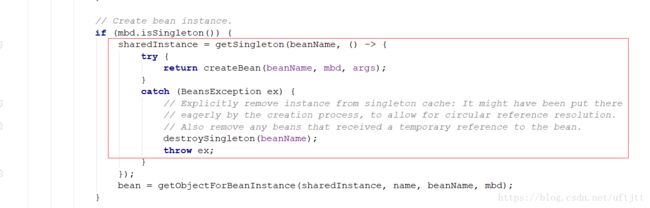
这里就是使用了getSingleton重载方法的地方,我们进入方法体:
public Object getSingleton(String beanName, ObjectFactory singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
if (logger.isDebugEnabled()) {
logger.debug("Creating shared instance of singleton bean '" + beanName + "'");
}
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
catch (IllegalStateException ex) {
// Has the singleton object implicitly appeared in the meantime ->
// if yes, proceed with it since the exception indicates that state.
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
throw ex;
}
}
catch (BeanCreationException ex) {
if (recordSuppressedExceptions) {
for (Exception suppressedException : this.suppressedExceptions) {
ex.addRelatedCause(suppressedException);
}
}
throw ex;
}
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
afterSingletonCreation(beanName);
}
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}上述代码中其实,使用了回调方法,使得程序可以在单例创建的前后做一些准备及处理操作,而真正获取单例bean的方法其实并不是在此方法中实现的,其实现逻辑是在ObjectFactory类型的实例singletonFactory中实现的(即上图贴上的第一段代码)。而这些准备及处理操作包括如下内容。
(1)检查缓存是否已经加载过
(2)如果没有加载,则记录beanName的正在加载状态
(3)加载单例前记录加载状态。
可能你会觉得beforeSingletonCreation方法是个空实现,里面没有任何逻辑,但其实这个函数中做了一个很重要的操作:记录加载状态,也就是通过this.singletonsCurrentlyInCreation.add(beanName)将当前正要创建的bean记录在缓存中,这样便可以对循环依赖进行检测。
(4)通过调用参数传入的ObjectFactory的个体Object方法实例化bean.
(5)加载单例后的处理方法调用。
同步骤3的记录加载状态相似,当bean加载结束后需要移除缓存中对该bean的正在加载状态的记录。
(6)将结果记录至缓存并删除加载bean过程中所记录的各种辅助状态。
(7)返回处理结果
在上面的第一段代码中,定义了bean的加载逻辑,ObejctFactory的核心部分其实是调用了createBean的方法,所以我们还需要看看createBean方法。
4. 准备创建bean
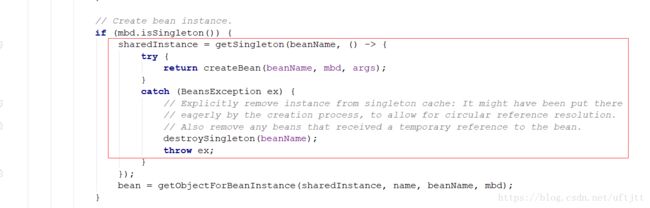
如上图所示,createBean是真正创建bean的地方,此方法是定义在AbstractAutowireCapableBeanFactory中,我们看下其源码:
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
if (logger.isDebugEnabled()) {
logger.debug("Creating instance of bean '" + beanName + "'");
}
RootBeanDefinition mbdToUse = mbd;
// Make sure bean class is actually resolved at this point, and
// clone the bean definition in case of a dynamically resolved Class
// which cannot be stored in the shared merged bean definition.
Class resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// Prepare method overrides.
try {
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
try {
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
catch (BeanCreationException | ImplicitlyAppearedSingletonException ex) {
// A previously detected exception with proper bean creation context already,
// or illegal singleton state to be communicated up to DefaultSingletonBeanRegistry.
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", ex);
}
}我们详细分析下代码的流程:
(1)设置class属性或者根据className来解析class
(2)验证MethodOverride属性进行验证及标记
在上述代码中有一个方法:mbd.prepareMethodOverrides();
其实在Spring中确实没有override-method这样的配置,但是我们前面说过,在Spring配置中是存在lookup-method和replace-method的,而这个两个配置的加载其实就是将配置统一存放在BeanDefinition中的methodOverrides属性里,而这个函数的操作其实也就是针对于这两个配置的。我们先看看Override属性标记及验证的逻辑实现。
(3)应用初始化前的后处理器,解析指定bean是否存在应用初始化前的短路操作
(4)创建bean
我们看下prepareMethodOverrides方法,代码如下:
public void prepareMethodOverrides() throws BeanDefinitionValidationException {
// Check that lookup methods exists.
if (hasMethodOverrides()) {
Set overrides = getMethodOverrides().getOverrides();
synchronized (overrides) {
for (MethodOverride mo : overrides) {
prepareMethodOverride(mo);
}
}
}
} 之前反复提起过,在Sprin配置中存在lookup-method和replace-method两个配置功能,而这两个配置的加载其实就是将配置统一放在BeanDefinition中的methodOverrides属性里,这两个功能实现原理其实是在bean实例化的时候如果检测到存在methodOverrides属性,会动态地位当前bean生成代理并使用对应的拦截器为bean做增强处理,相关的逻辑实现在bean的实例化部分详细介绍。
这里要提到的是,对于方法的匹配来讲,如果一个类中存在若干个重载方法,那么在函数调用及增强的时候还需要根据参数类型进行匹配,来最终确认当前调用的到底是哪个函数。但是Spring将一部分匹配工作在这里完成了,如果当前类中的方法只有一个,那就设置重载该方法没有被重载,这样在后续调用的时候便可以直接使用找到的方法,而不需要进行方法的参数匹配验证了,而且还可以提前对方法存在性进行验证,正可谓一举两得。
5. 实例化的前置操作
我们回到createBean方法中,在doCreateBean方法前使用了resolveBeforeInstantiation(beanName, mbdToUse)方法,此方法是对BeanDefinition中的属性做了一些前置处理,我们看下方法代码:
@Nullable
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// Make sure bean class is actually resolved at this point.
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
Class targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}此方法内部分别对bean初始化前后的后处理器进行了调用,代码如下:
@Nullable
protected Object applyBeanPostProcessorsBeforeInstantiation(Class beanClass, String beanName) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
Object result = ibp.postProcessBeforeInstantiation(beanClass, beanName);
if (result != null) {
return result;
}
}
}
return null;
}
@Override
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
Object current = beanProcessor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}6. 循环依赖
6.1 什么是循环依赖
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图所示:
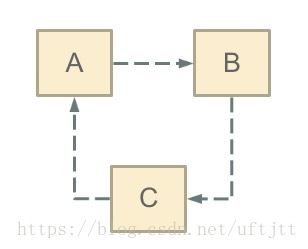
注意,这里不是函数的循环调用,是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。
Spring中循环依赖场景有:
(1)构造器的循环依赖
(2)field属性的循环依赖。
6.2 如何检测循环依赖
检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。
6.3 Spring怎么解决循环依赖
Spring的循环依赖的理论依据其实是基于Java的引用传递,当我们获取到对象的引用时,对象的field或则属性是可以延后设置的(但是构造器必须是在获取引用之前)。
Spring的单例对象的初始化主要分为三步:
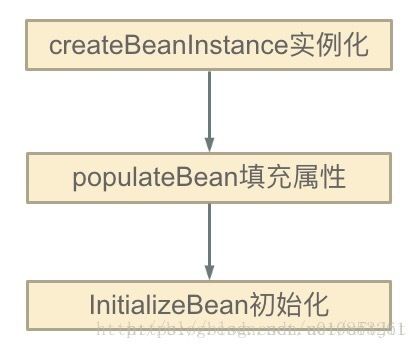
(1)createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
(2)populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
(3)initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一、第二部。也就是构造器循环依赖和field循环依赖。
那么我们要解决循环引用也应该从初始化过程着手,对于单例来说,在Spring容器整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存,首先我们看源码,三级缓存主要指:
/** Cache of singleton objects: bean name --> bean instance */
private final Map singletonObjects = new ConcurrentHashMap(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map> singletonFactories = new HashMap>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map earlySingletonObjects = new HashMap(16); 这三级缓存分别指:
(1)singletonFactories : 单例对象工厂的cache
(2)earlySingletonObjects :提前暴光的单例对象的Cache
(3)singletonObjects:单例对象的cache
我们在创建bean的时候,首先想到的是从cache中获取这个单例的bean,这个缓存就是singletonObjects。主要调用方法就就是:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}上面的代码需要解释两个参数:
(1)isSingletonCurrentlyInCreation()判断当前单例bean是否正在创建中,也就是没有初始化完成(比如A的构造器依赖了B对象所以得先去创建B对象, 或则在A的populateBean过程中依赖了B对象,得先去创建B对象,这时的A就是处于创建中的状态。)
(2)allowEarlyReference 是否允许从singletonFactories中通过getObject拿到对象
分析getSingleton()的整个过程,Spring首先从一级缓存singletonObjects中获取。如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取,如果获取到了则:
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);从singletonFactories中移除,并放入earlySingletonObjects中。其实也就是从三级缓存移动到了二级缓存。
从上面三级缓存的分析,我们可以知道,Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory,定义如下:
public interface ObjectFactory {
T getObject() throws BeansException;
} 这个接口在下面被引用:
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}这里就是解决循环依赖的关键,这段代码发生在createBeanInstance之后,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行初始化的第二步和第三步),但是已经能被人认出来了(根据对象引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来让大家认识,让大家使用。
这样做有什么好处呢?让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
知道了这个原理时候,肯定就知道为啥Spring不能解决“A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题了!因为加入singletonFactories三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决