【“计算机科学与技术”专业小白成长系列】Linux Shell 编程 极简教程
Linux Shell 编程 极简教程
内容摘要
本文是 Linux Shell 编程简单入门。主要内容:
- Linux 简介
- Shell 编程入门
- Kotlin 脚本与 Shell 脚本
- Linux grep 命令与 awk 命令
- vim 编辑器简单使用
Linux 简介
Linux 英文解释为 Linux is not Unix。
Linux 内核最初只是由芬兰人林纳斯·托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。
Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。
Linux 能运行主要的 UNIX 工具软件、应用程序和网络协议。它支持 32 位和 64 位硬件。Linux 继承了 Unix 以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
Linux 的发行版说简单点就是将 Linux 内核与应用软件做一个打包。

目前市面上较知名的发行版有:Ubuntu、RedHat、CentOS、Debian、Fedora、SuSE、OpenSUSE、Arch Linux、SolusOS 等。

什么是 Shell?
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
Ken Thompson 的 sh 是第一种 Unix Shell,Windows Explorer 是一个典型的图形界面 Shell。
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。
Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 种类众多,常见的有:
Bourne Shell(/usr/bin/sh或/bin/sh)
Bourne Again Shell(/bin/bash)
C Shell(/usr/bin/csh)
K Shell(/usr/bin/ksh)
Shell for Root(/sbin/sh)
……
本教程关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为 #!/bin/bash。
#!/usr/bin/env bash
#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
我发现使用 Shell 脚本还是没有使用 Kotlin Script 来得强大自由。所以,我在这里讲 Shell 的同时,给出了 Kotlin 脚本的实例。
Hello World
shell 脚本
#!/usr/bin/env bash
echo "Hello World!"
运行:
$ ./hello_world.sh
Hello World!
kotlin 脚本
// hello world
println("Hello World!")
运行:
$ kotlinc -script KtsDemo.kts
Hello World!
使用变量
shell 脚本
# 变量:注意 shell 中的变量等于号前后不要有空格
a="I am cat"
echo $a
kotlin 脚本
// variable
val a = "I am cat"
println(a)
数组与循环
shell 脚本
# 数组 & for loop
nums=(1 2 3 4 5 6 7 8 9 10)
declare -i sum=0
for i in ${nums[*]} ; do
((sum=sum+i))
done
echo "sum is $sum"
kotlin 脚本
// for loop
var sum = 0
val nums = listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
for (i in nums) {
sum += i
}
println("sum is $sum")
条件判断
shell 脚本
# 条件判断 condition
x=1
y=1
if ((x == y))
then
echo "x=y"
elif ((x>y))
then
echo "x>y"
else
echo "x
fi
kotlin 脚本
// condition
val x = 1
val y = 1
if (x == y) {
println("x=y")
} else if (x > y) {
println("x>y")
} else {
println("x)
}
文件 IO 操作
shell 脚本
# io
curPath=$(pwd)
echo $curPath
kotlin 脚本
// io
val f = File(".")
val path = f.absolutePath
println("path:$path")
定义函数
shell 脚本
# Function
function sum(){
v1=$1
v2=$2
v=$((v1+v2))
echo $v
}
sum 1 2
s=$(sum 1 2)
echo "s is $s"
kotlin 脚本
// fun
fun sum(a: Int, b: Int): Int {
return a + b
}
val c = sum(1, 2)
println("c is $c")
附录: Shell 实现的基本运算函数
#####################
#function is_Digit()
#判断参数是否为数字
#支持浮点数
#只能传入一个参数
#是,返回1,否则返回0
######################
function is_Digit()
{
ref=`echo $1 | awk '{print($0~/^[+-]?[0-9]?*(\.[0-9]*)?$/)?"digit":"string"}'`
if [ "$ref" == "digit" ];then
return 0;
else
return 1;
fi
}
########################
#function add()
#检查参数,返回两个数字和
########################
function add()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%d \n",num_a+num_b}'`;
echo $ref;
}
add 10 10
c=$(add 10 10)
echo "c is $c"
###################
#function multiply()
#判断参数是否为数字
#并将两个参数相乘
#函数直接传入引用
#变量的变量的实现${!para}
#函数的返回值,不能像C一样return,
#需要打印输出,echo
###################
function mul()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%d \n",num_a*num_b}'`;
echo $ref;
}
########################
#function div()
#检查参数,返回两个数字差
########################
function div()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%d \n",num_a/num_b}'`;
echo $ref;
}
########################
#function sub()
#检查参数,返回两个数字差
########################
function sub()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%d \n",num_a-num_b}'`;
echo $ref;
}
###################
#function mul_f()
#判断参数是否为数字
#并将两个参数相乘
#函数直接传入引用
#变量的变量的实现${!para}
#函数的返回值,不能像C一样return,
#需要打印输出,echo
###################
function mul_f()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%0.2f \n",num_a*num_b}'`;
echo $ref;
}
########################
#function div_f()
#检查参数,返回两个数字差
########################
function div_f()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%0.2f \n",num_a/num_b}'`;
echo $ref;
}
########################
#function add_f()
#检查参数,返回两个数字和
########################
function add_f()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%0.2f \n",num_a+num_b}'`;
echo $ref;
}
########################
#function sub_f()
#检查参数,返回两个数字差
########################
function sub_f()
{
for (( i=1;i<3;i++ ))
do
pa="$i"
if is_Digit ${!pa}
then
continue;
else
echo "$pa isn't a number";
return 0;
fi
done
ref=`awk -v num_a=$1 -v num_b=$2 'BEGIN{printf "%0.2f \n",num_a-num_b}'`;
echo $ref;
}
Linux grep 命令
Linux grep 命令用于查找文件里符合条件的字符串。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
参数
-a 或 --text : 不要忽略二进制的数据。
-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 --count : 计算符合样式的列数。
-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F 或 --fixed-regexp : 将样式视为固定字符串的列表。
-G 或 --basic-regexp : 将样式视为普通的表示法来使用。
-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-i 或 --ignore-case : 忽略字符大小写的差别。
-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 --only-matching : 只显示匹配PATTERN 部分。
-q 或 --quiet或–silent : 不显示任何信息。
-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
-s 或 --no-messages : 不显示错误信息。
-v 或 --revert-match : 显示不包含匹配文本的所有行。
-V 或 --version : 显示版本信息。
-w 或 --word-regexp : 只显示全字符合的列。
-x --line-regexp : 只显示全列符合的列。
-y : 此参数的效果和指定"-i"参数相同。
Linux 命令大全 Linux 命令大全
实例
1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file
结果如下所示:
$ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件
testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行
testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行
testfile_2:Linux test #列出testfile_2 文件中包含test字符的行
2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为:
grep -r update /etc/acpi
输出结果如下:
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi”
#下包含“update”的文件
/etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.)
Rather than
/etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of
IO.) Rather than
/etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
3、反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
grep -v test *test*
结果如下所示:
$ grep-v test* #查找文件名中包含test 的文件中不包含test 的行
testfile1:helLinux!
testfile1:Linis a free Unix-type operating system.
testfile1:Lin
testfile_1:HELLO LINUX!
testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM.
testfile_1:THIS IS A LINUX TESTFILE!
testfile_2:HELLO LINUX!
testfile_2:Linux is a free unix-type opterating system.
Linux awk 命令
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
-F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value
赋值一个用户定义变量。
-f scripfile or --file scriptfile
从脚本文件中读取awk命令。
-mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。
-W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。
-W lint or --lint
打印不能向传统unix平台移植的结构的警告。
-W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。
-W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。
-W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。
-W version or --version
打印bug报告信息的版本。
awk 基本用法
log.txt文本内容如下:
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo
用法:
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号
实例:
# 每行按空格或TAB分割,输出文本中的1、4项
$ awk '{print $1,$2}' a.log
2 this
3 Are
This's a
10 There
awk、sed、grep 解析
grep 更适合单纯的查找或匹配文本
sed 更适合编辑匹配到的文本
awk 更适合格式化文本,对文本进行较复杂格式处理
解释一下变量:
变量:分为内置变量和自定义变量;输入分隔符FS和输出分隔符OFS都属于内置变量。
内置变量就是awk预定义好的、内置在awk内部的变量,而自定义变量就是用户定义的变量。
FS(Field Separator):输入字段分隔符, 默认为空白字符
OFS(Out of Field Separator):输出字段分隔符, 默认为空白字符
RS(Record Separator):输入记录分隔符(输入换行符), 指定输入时的换行符
ORS(Output Record Separate):输出记录分隔符(输出换行符),输出时用指定符号代替换行符
NF(Number for Field):当前行的字段的个数(即当前行被分割成了几列)
NR(Number of Record):行号,当前处理的文本行的行号。
FNR:各文件分别计数的行号
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
Mac系统是基于Unix内核的图形化操作系统,而在 Mac 上几乎可以跟在 Linux 上一样使用 shell 脚本、命令行等操作。
登录系统后,在当前命令窗口下输入命令:
ls /
你会看到如下图所示:

Linux 树状目录结构:
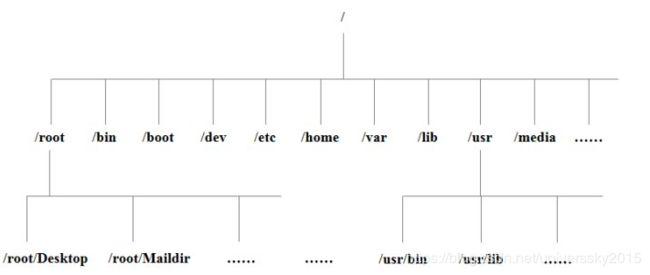
以下是对这些目录的解释:
/bin:
bin是Binary的缩写, 这个目录存放着最经常使用的命令。
/boot:
这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev :
dev是Device(设备)的缩写, 该目录下存放的是Linux的外部设备,在Linux中访问设备的方式和访问文件的方式是相同的。
/etc:
这个目录用来存放所有的系统管理所需要的配置文件和子目录。
/home:
用户的主目录,在Linux中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。
/lib:
这个目录里存放着系统最基本的动态连接共享库,其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
/lost+found:
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。
/media:
linux系统会自动识别一些设备,例如U盘、光驱等等,当识别后,linux会把识别的设备挂载到这个目录下。
/mnt:
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
/opt:
这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
/proc:
这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
/root:
该目录为系统管理员,也称作超级权限者的用户主目录。
/sbin:
s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。
/selinux:
这个目录是Redhat/CentOS所特有的目录,Selinux是一个安全机制,类似于windows的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。
/srv:
该目录存放一些服务启动之后需要提取的数据。
/sys:
这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。
sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。
该文件系统是内核设备树的一个直观反映。
当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。
/tmp:
这个目录是用来存放一些临时文件的。
/usr:
这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。
/usr/bin:
系统用户使用的应用程序。
/usr/sbin:
超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src:
内核源代码默认的放置目录。
/var:
这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
/run:
是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
在 Linux 系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。
/etc: 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。
/bin, /sbin, /usr/bin, /usr/sbin: 这是系统预设的执行文件的放置目录,比如 ls 就是在/bin/ls 目录下的。
值得提出的是,/bin, /usr/bin 是给系统用户使用的指令(除root外的通用户),而/sbin, /usr/sbin 则是给root使用的指令。
/var: 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在/var/log 目录下,另外mail的预设放置也是在这里。
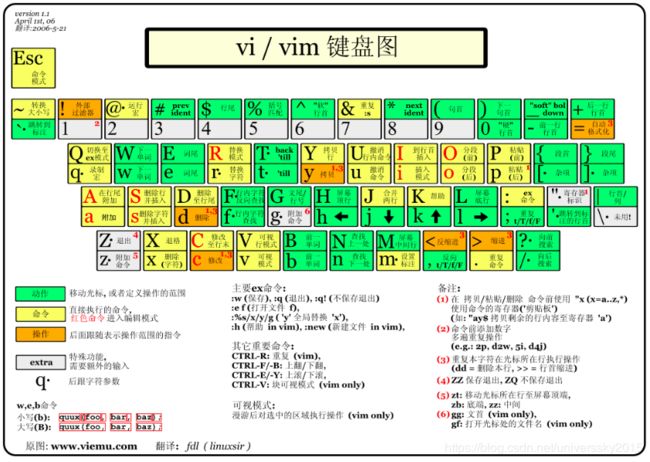
Linux vi/vim
所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在。
但是目前我们使用比较多的是 vim 编辑器。
vim 具有程序编辑的能力,可以主动的以字体颜色辨别语法的正确性,方便程序设计。
Kotlin 开发者社区

国内第一Kotlin 开发者社区公众号,主要分享、交流 Kotlin 编程语言、Spring Boot、Android、React.js/Node.js、函数式编程、编程思想等相关主题。