调试JDK源码-Hashtable实现原理以及线程安全的原因
调试JDK源码-一步一步看HashMap怎么Hash和扩容
调试JDK源码-ConcurrentHashMap实现原理
调试JDK源码-HashSet实现原理
调试JDK源码-调试JDK源码-Hashtable实现原理以及线程安全的原因
Hashtable是线程安全的,我们从源码来分析
代码很简单
Hashtable ht = new Hashtable();
ht.put("111", "http://blog.csdn.net/unix21/");
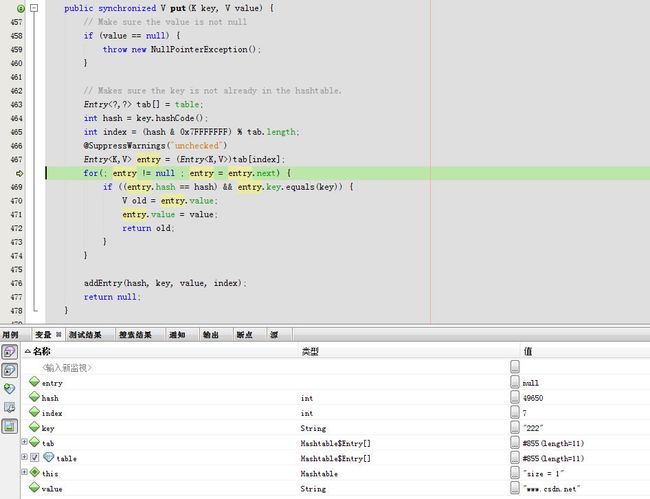
ht.put("222", "www.csdn.net");
ht.put("333", www.java.com);
注释写的很好,生成一个新的,空的hashtable,使用默认的capacity容量为11,factor增长因子为0.75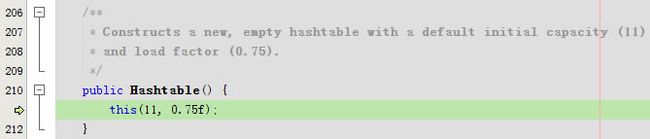
这一步开始初始化
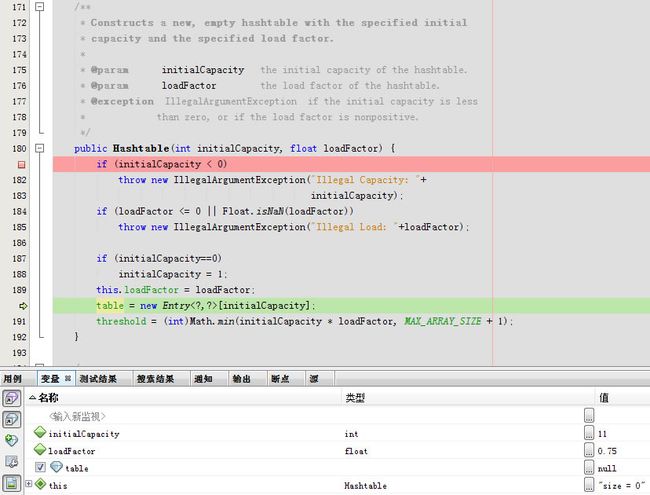
下一步就完成了实例化
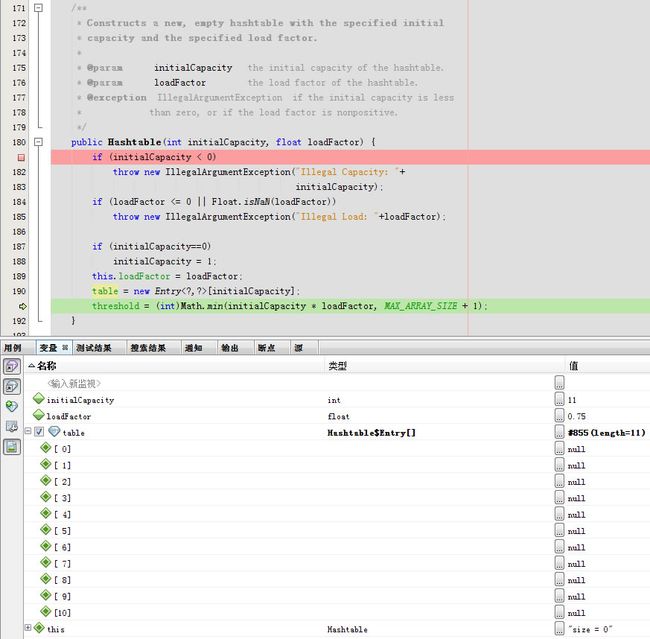
Entry是一个静态嵌套类
/**
* Hashtable bucket collision list entry
*/
private static class Entry implements Map.Entry {
final int hash;
final K key;
V value;
Entry next;
protected Entry(int hash, K key, V value, Entry next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@SuppressWarnings("unchecked")
protected Object clone() {
return new Entry<>(hash, key, value,
(next==null ? null : (Entry) next.clone()));
}
// Map.Entry Ops
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
public int hashCode() {
return hash ^ Objects.hashCode(value);
}
public String toString() {
return key.toString()+"="+value.toString();
}
}
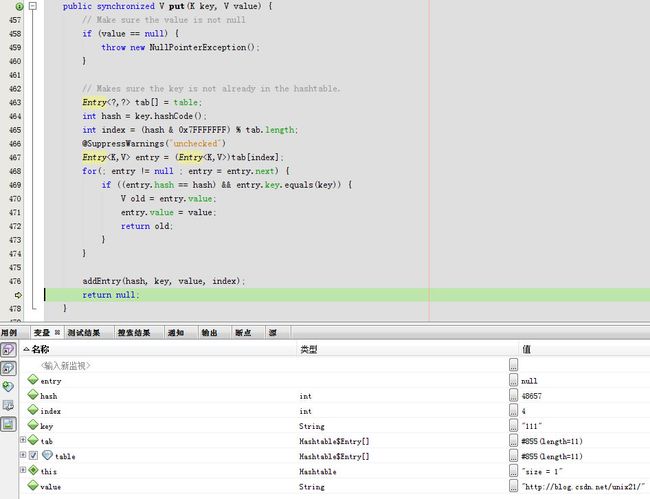
其实就是因为这个put方法是synchronized的所以可以保证其线程安全
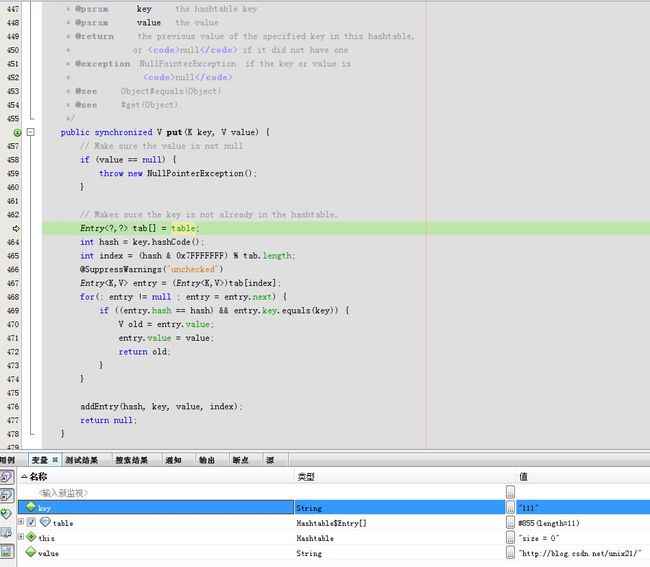
算出hash码,然后算出在默认长度11下的index索引是4
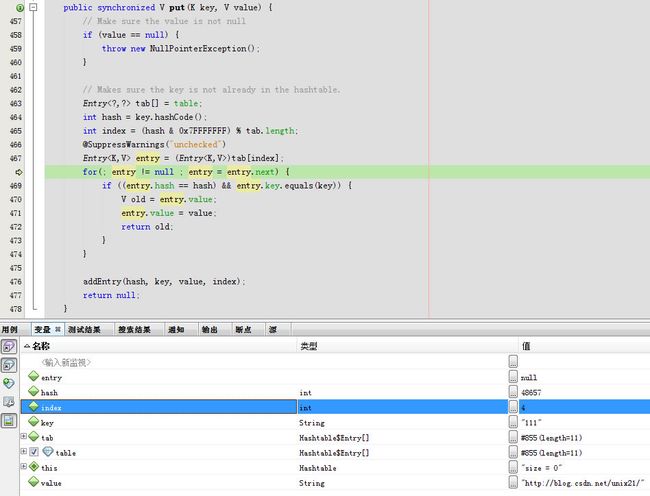
默认entry为空直接跳到addEntry(hash, key, value, index)
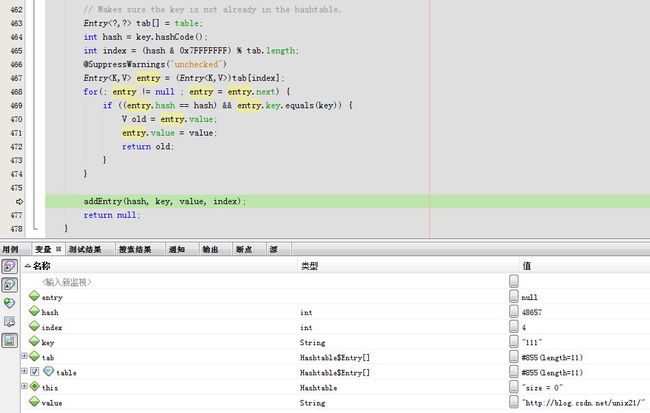
addEntry方法体内,一开始modCount=0
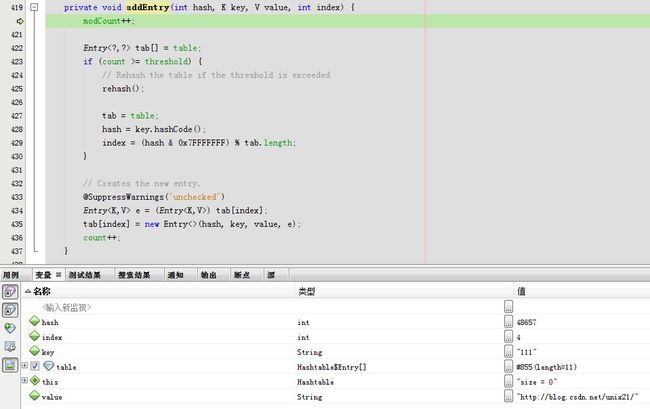
下一步由于count =0 > threshold=8
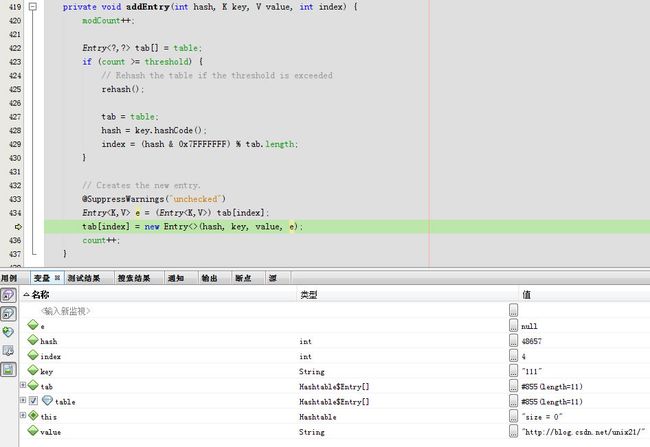
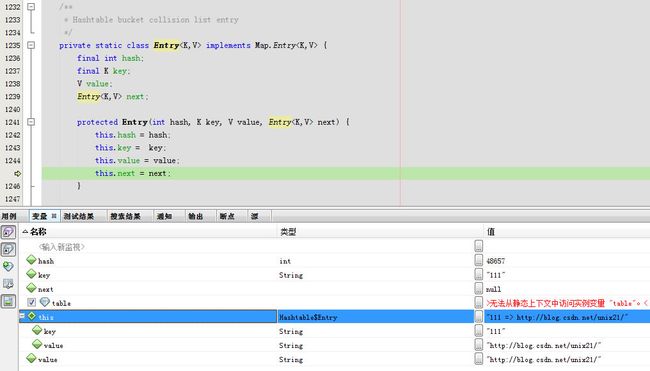
生成一个新的Entry
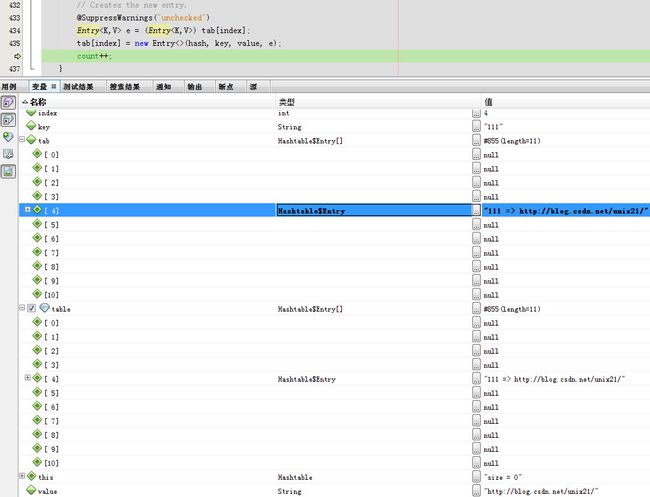
新的节点挂在tab[4]上,然后count++。
回到put函数,至此一个完整的put就完成了。
第二次put,生成的index是7
哈希冲突
注意这段代码,其实就是判断是否出现hash冲突了
Entry entry = (Entry)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
知道了hashtable默认的长度是11,那么我们就可以制造一个会产生哈希冲突的数据集就可以了
Hashtable ht = new Hashtable();
for (int i = 0; i < 20; i++) {
ht.put((char) (i + 65) + (char) (i + 66) + (char) (i + 67) + "", i + ">>>http://blog.csdn.net/unix21/");
}
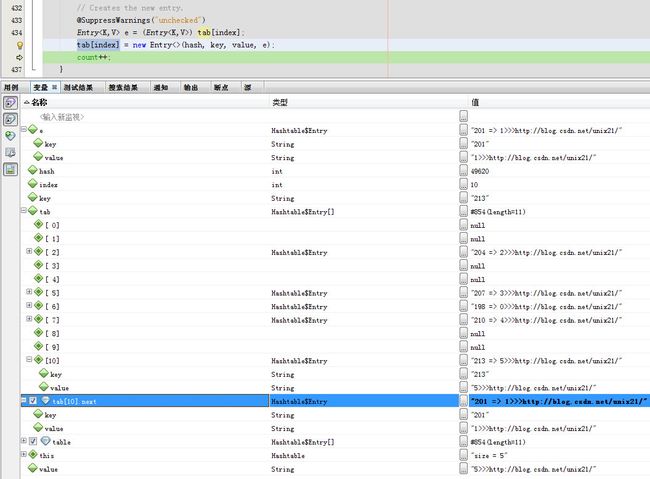
经过几次put之后,终于产生了一次哈希冲突,这次的索引是10,而tab[10]已经有值。
产生冲突有2个原因一个是因为相同的key必然会产生相同的索引。还有一种就是不同的值产生哈希冲突了。
所以这里先判断是不是相同的key导致的。
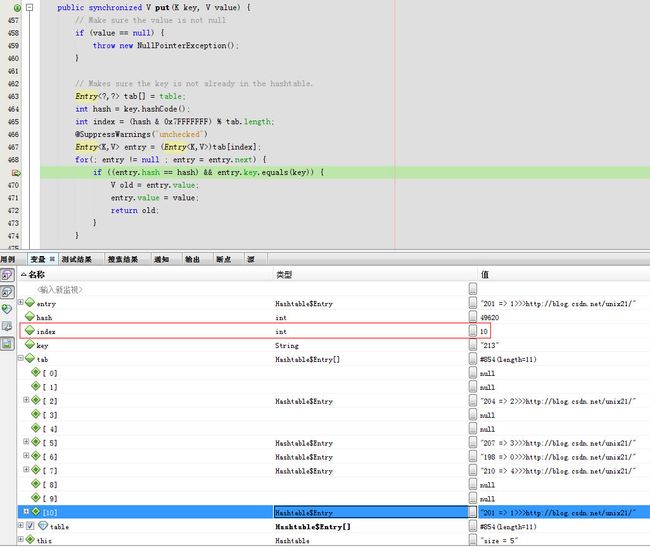
进入addEntry方法

之前的冲突节点一并传入,被挂在新节点后面也就是其next下

回到addEntry,可以看到新的节点以及挂在tab[10].next下了。