知识图谱综述浅谈
知识图谱是人工智能领域的一颗掌上明珠,也是当前的一个新兴研究热点。知识图谱领域的研究和发展,对于智能问答、语义搜索等场景有着巨大应用潜力。
在你的工作当中,是否慢慢的开始遇到一些和知识图谱相关的技术,想要学习知识图谱,首先要对所有知识点有一个整体的宏观的认识。这也是本场 Chat 的目标所在。
在本场 Chat 中,会讲到如下内容:
- 知识图谱的提出
- 知识图谱的定义
- 知识图谱的构成
- 知识图谱历史发展
- 知识图谱的分类
- 知识图谱的应用
适合人群: 对知识图谱有兴趣的技术人员或科研工作者,希望能对你有所帮助。
知识图谱入门必知
一、概念提出
了解一门技术,首先要知道这门技术是怎样提出的?
目前我们所研究的知识图谱,英文名Knowledge Graph,简称KG,是google公司 在 2012 年提出的。当时将知识图谱这个概念发表在这篇谷歌的 Official Blog:《Introducing the Knowledge Graph:things,not strings》(附在文章最后),想入门知识图谱的朋友,还是有必要去看一下最初的这篇博客。
通过技术概念的提出,可以看出两点:
- 提出时间不久,还是一个比较新的事物(一会儿再谈相关技术的历史)。
- 提出时渲染的非常有寓意,知识图谱,真实世界的事物,而不再是字符串,引人入胜。
二、知识图谱定义
了解了知识图谱的提出后,接下来就要知道,到底什么是知识图谱?
当前对于知识图谱的定义众说纷纭,总结了一下,主要都是从主要从以下几个角度来描述:
1.从应用的角度
谷歌最初提知识图谱时,就是从应用的角度来定义的,应用的目的是为了用于谷歌高效的搜索。上述那篇谷歌博客中定义了这么一句话:" the Knowledge Graph, which will help you discover new information quickly and easily",主要从用途上来定义知识图谱,说的是知识图谱能够用来帮助人们快速和简便发现新的信息。
2.从技术的角度
电子工业出版社 2019 年出版的《知识图谱方法、实践与应用》一书中,将知识图谱概况了一句话:知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。这本书也是入门时值得一看的好书。
这里将知识图谱定义为一种技术,这种观点目前支持者比较多,主要是认为知识图谱是包含了知识图谱建模、知识获取、知识存储、知识图谱应用等一整套的工程技术。
3.从数据模型的角度
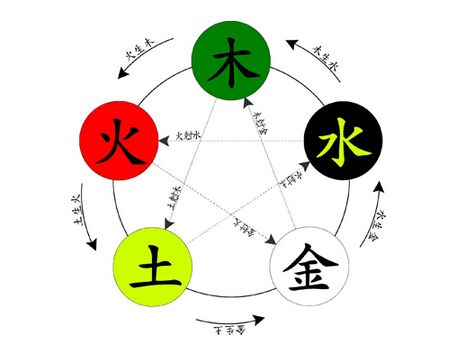
从数据模型的角度来看,知识图谱无论是用于搜索还是智能问答等,其实本质还是知识或者说数据的组织形式,很多文献都是从这个角度来定义,认为知识图谱其实是一种结构化的语义知识库,基本组成单位是实体-属性-关系。即具有有向图结构的一个知识库.理解这个定义的关键在于理解里面的图结构,或者图模型,这里的图模型简单的来说,就是由节点和边组成。需要注意的是,节点可以是实体,如一个具体的人、一本具体的书等,也可以是抽象的概念,如人工智能、知识图谱等。边可以是实体的属性,如姓名、性别,也可以是实体之间的关系,如朋友、配偶。(这块如果不理解,可以再看看后面知识图谱构成)中国古人的五行学说和易经八卦就是对世间万物进行高度抽象后的知识图谱。这儿的这几个节点金木水火土,都是抽象的概念。
4.其他角度
鲍捷老师在 GitChat《深度解析知识图谱发展关键阶段及技术脉络》中,认为知识图谱从某种程度来说只不过是谷歌提出的一个营销名词。Freebase 的背后是一家名叫 Metaweb 的创业公司,2005 年成立,致力于开发用于 W e b 语义服务的开放共享的世界知识库。创始人之一是希利斯(Danny Hillis)。2010 年 Metaweb 被谷歌收购,谷歌获得其语义搜索技术,并给它起了个响亮的名字“知识图谱”。
美团技术团队认为,知识图谱作为人工智能时代最重要的知识表示方式之一,知识图谱能够打破不同场景下的数据隔离,为搜索、推荐、问答、解释与决策等应用提供基础支撑。这里将知识图谱定义为一种知识表示方式。
可以看出,上述的这些组织或者单位,从不同角度给知识图谱下了不同定义,有从数据模型角度的定义,也有从技术角度的定义,等等。而我想说的是,对于知识图谱这个词本身,我们了解各家说法就足够了,相比而言,更为重要的是学习它背后的一整套工程技术。
三、知识图谱构成
发展到今天,从数据模型的角度来说,目前知识图谱的构成,一般包含以下两个部分:
- 模式层
- 数据层
比如,一个简单的含有模式层和数据层的知识图谱模型如下图所示
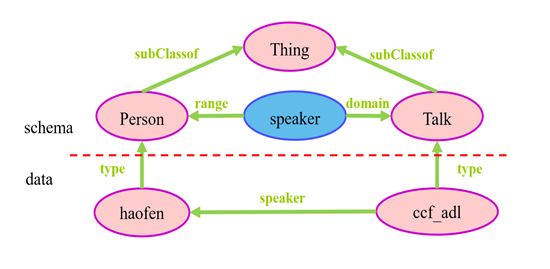
我们可以看到,上述图中:
- 模式层中,包括节点和边。节点是一个抽象的概念,比如人物person、事物Thing、演讲Talk;边是概念间的关系,比如演讲者speaker。另外,还可以看出,模式层本身也是分层的,是一个树状结构的概念层次关系。
- 数据层中,包含节点和关系,节点是一个具体是实例,比如haofen这个人,边是实体间的关系,比如ccf_adl这场演讲。另外,还有一类节点是属性值,这里没有画出来,例如:男,那么所对应的边就是属性,例如性别。
四、知识图谱技术历史发展
要深入了解一个技术,还要知道这个技术的来龙去脉,知识图谱是怎样发展来的呢?
(一)首先要了解人工智能的主要学派有下列三家:(人工智能具体历史太过于复杂,这里不在赘述)
(1) 连接主义(connectionism),又称为仿生学派或生理学派,其主要原理为神经网络及神经网络间的连接机制与学习算法。这里的智能我理解的是感知智能,比如语音识别、图像识别,主要让机器能够感知周围事物,而感知智能当前已经发展的非常成熟,比如人脸支付,语音翻译等已经大规模商用。
(2) 符号主义(symbolicism),又称为逻辑主义、心理学派或计算机学派,其原理主要为物理符号系统(即符号操作系统)假设和有限合理性原理。这里的智能我理解的是认知智能,也就是让机器像人一样思考,能够自我学习、理解知识,交流问题。知识图谱就属于这个学派。
(3) 行为主义(actionism),又称为进化主义或控制论学派,其原理为控制论及感知-动作型控制系统。这里的智能我理解的是行为智能,比如足球机器人,无人驾驶汽车。
符号派一直以来都处于人工智能研究的核心位置。但是近年来,随着数据的大量积累和计算能力的大幅提升,深度学习在视觉、听觉等感知处理中取得突破性进展,进而又在围棋等博弈类游戏、机器翻译等领域获得成功,使得人工神经网络和机器学习获得了人工智能研究的核心地位。
深度学习在处理感知、识别和判断等方面表现突出,能帮助构建聪明的人工智能,但在模拟人的思考过程、处理常识知识和推理,以及理解人的语言方面仍然举步维艰,这也是知识图谱发展的潜力所在。
(二)符号主义——知识图谱历史发展时间线:
其实早在文艺复兴时期,培根就提出了“知识就是力量”,在当今人工智能时代,各大科技公司更是纷纷提出:知识图谱就是人工智能的基础。
其实,知识图谱不是无缘无故诞生的技术,在此之前有许多相关联的技术给它做了铺垫:
1960 年,认知科学家 Allan M.Collins 提出用语义网络(Semantic Network)(注意不是语义网)研究人脑的语义记忆,提出用相互连接的节点和边来表示知识。节点表示对象、概念,边表示节点之间的关系。语义网络可以比较容易地让我们理解语义和语义关系。其表达形式简单直白,符合自然。然而,由于缺少标准,其比较难应用于实践。
1965 年,在斯坦福大学,美国著名计算机学家费根鲍姆带领学生开发了第一个专家系统 Dendral,这个系统可以根据化学仪器的读数自动鉴定化学成分。随着专家系统的提出和商业化发展,知识库(Knowledge Base)构建和知识表示更加得到重视。专家系统的基本想法是:专家是基于大脑中的知识来进行决策的,因此人工智能的核心应该是用计算机符号表示这些知识,并通过推理机模仿人脑对知识进行处理。依据专家系统的观点,计算机系统应该由知识库和推理机两部分组成,而不是由函数等过程性代码组成。
1969 年,因特网诞生于美国。它的前身“阿帕网”( ARPAnet)是一个军用研究系统,后来才逐渐发展成为连接大学及高等院校计算机的学术系统,现在则已发展成为一个覆盖五大洲 150 多个国家的开放型全球计算机网络系统,拥有许多服务商。
1980 年,本体论,哲学概念”本体”被引入人工智能领域用来刻画知识。
1989 年,英国科学家 Tim Berners-Lee 在欧洲高能物理研究所工作的时候,发明了万维网技术。Tim Berners-Lee 发明的万维网技术,把信息用网页(HTML)表示,用超链接 HTTP 协议把不同的网页链接起来。万维网一下子激活了信息组织的灵活性,使万维网成为了互联网上的最大应用。
1998 年,在上述技术基础上,英国科学家 Tim Berners-Lee(还是这个人)又提出语义网,希望把这个万维网技术向前推进一步。
Tim Berners-Lee 提出了最初的语义网体系结构,随着人们对语义网的深入研究,语义网的体系结构也在不断地发展演变。体系结构如下图所示。可以看出,语义网是传统人工智能与 Web 融合的结果,是符号主义核心知识表示与推理在现代 Web 中的应用,其中的 RDF/OWL 都是面向 Web 的知识表示语言。
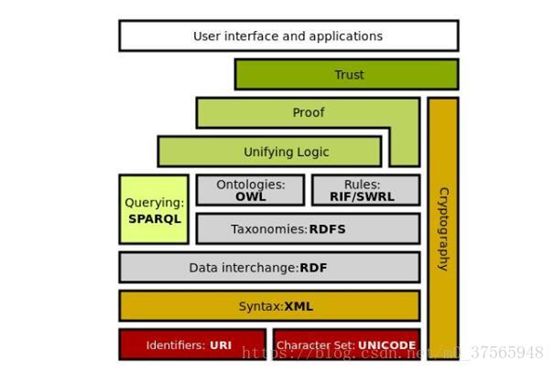
语义网和万维网、语义网络的区别如下:
- 万维网是以文档来组织的,我们所访问的网页、文件,本质上都是一个个文档,而文档中存在大量知识,只有人可以读懂。
- 语义网当中的相关技术 RDF, schema, 和 inference languages 等目的是将万维网所有的文档数据降解到数据级别,降解到能够被计算机所理解的语义,我们就可以将当前网络上无结构或半结构化的文档转换为网络数据,变成一个巨大的数据库,从而使计算机与人更好的合作。
- 相对于最早语义网络,语义网更倾向于描述万维网中资源、数据之间的关系,语义网中提出了更多规范的标准:例如,RDF 的提出解决了语义网络的缺点 1 和缺点 2,在节点和边的取值上做了约束,制定了统一标准,为多源数据的融合提供了便利;W3C 制定的另外两个标准 RDFS/OWL,解决区分概念和对象的问题,即定义 Class 和 Object(也称作 Instance, Entity)。
2006 年,Tim Berners Lee(还是这个人)提出链接数据。由于语义网的设计模型是“自顶向下”的,大规模情况下实现起来很困难,于是乎,学者们逐渐将焦点转向数据本身,在这种情况下,Tim Berners-Lee 提出关联数据(Linked Data)的概念,鼓励大家将数据公开并遵循一定的原则(2006 年提出 4 条原则,2009 年精简为 3 条原则)将其发布在互联网中,链接数据起初是用于定义如何利用语义网技术在网上发布数据,其强调在不同的数据集间创建链接。

在上述背景下,大型数据集项目越来越多,包括国外的DBpedia 项目、Wikidata 项目、Freebase项目等。在中文社区类似的项目有清华大学的 XLore、复旦大学的 CN-pedia等。
2012 年,谷歌在上述技术的基础上,特别是依托收购的Freebase,进行改扩充和改进(谷歌自己的专业团队在Freebase 的基础上又设计了模式层等),最后提出了知识图谱,目的是提升搜索引擎返回的答案质量和用户查询的效率,有知识图谱作为辅助,搜索引擎能够洞察用户查询背后的语义信息,返回更为精准、结构化的信息,更大可能地满足用户的查询需求。
知识图谱和专家系统、本体、语义网、链接数据区别如下:
- 知识图谱和专家系统:知识图谱技术继承了知识本体和专家系统的精髓,成为了当代知识表示和推理的重要技术。但知识图谱与传统专家系统时代的知识工程有着显著的不同。传统专家系统时代主要依靠专家手工获取知识,构建规则,而现代知识图谱的显著特点是规模巨大,无法单一依靠人工和专家构建。
- 知识图谱和本体:知识图谱与本体的相同之处在于:二者都通过定义元数据以支持语义服务。不同之处在于: 知识图谱更灵活, 支持通过添加自定义的标签划分事物的类别。本体侧重概念模型的说明,能对知识表示进行概括性、抽象性的描述,强调的是概念以及概念之间的关系。大部分本体不包含过多的实例, 本体实例的填充通常是在本体构建完成以后进行的.。知识图谱更侧重描述实体关系, 在实体层面对本体进行大量的丰富与扩充.。可以认为, 本体是知识图谱的抽象表达, 描述知识图谱的上层模式; 知识图谱是本体的实例化, 是基于本体的知识库。
- 知识图谱和语义网:知识图谱继承了语义网的知识表示方法,比如说和RDFS和OWL具有紧密的关系,因为知识图谱可以看成是一种知识存储的数据结构,本身并不具备形式化的语义,但是可以通过RDFS 或者OWL 的规则应用于知识图谱进行推理,从而赋予知识图谱形式化语义。从某种角度说,知识图谱就是大规模语义网,也是对链接数据这个概念的进一步包装。
- 知识图谱和链接数据:链接数据技术直接促成了谷歌的知识图谱技术(Knowledge Graph)。链接数据和知识图谱最大的区别在于:1. 链接数据更强调不同 RDF 数据集(知识图谱)的相互链接。2. 知识图谱不一定要链接到外部的知识图谱(和企业内部数据通常也不会公开一个道理),更强调有一个本体层来定义实体的类型和实体之间的关系。另外,知识图谱数据质量要求比较高且容易访问,能够提供面向终端用户的信息服务(查询、问答等等)。
五、知识图谱分类
近年来,不管是学术界还是工业界都纷纷构建自家的知识图谱,按应用来说,主要可以分为两大类:
- 一是通用知识图谱,又叫做开放领域知识图谱。通俗讲就是大众版,没有特别深的行业知识及专业内容,一般是解决科普类、常识类等问题。
- 二是行业知识图谱,又叫做特定领域知识图谱,又叫做垂直领域知识图谱。通俗讲就是专业版,根据对某个行业或细分领域的深入研究而定制的版本,主要是解决当前行业或细分领域的专业问题。
两种类型的知识图谱区别其实比我们想象的要大:
- 通用知识图谱通常包含的节点和关系非常多,甚至是无限多个,一个问题是很难在体量上做到全面,另外一个是最终的准确性很难去判别,很多通用性知识不是非对即错的。
- 行业知识图谱知识图谱节点和关系类型很有限,对准确性和图谱的质量强调较高,最大的问题是在专业领域,构建图谱所需的语料一般都比较缺乏。
六、知识图谱技术应用
那么,学习知识图谱可以做什么用?目前主要又以下几个用途。
1.智能问答
从人工智能发展的历史就可以看出,知识图谱作为符号主义的一部分,最主要的是要解决认知智能的问题,知识图谱从既然是一张事物关系图,可以建模世间万物,最主要是用它来作为聊天机器人的“大脑”,用来做智能问答系统。
- 优势是对一些关联性问题,比如“姚明的妻子是谁?”,“谷歌的总裁是谁?”,机器可以利用知识图谱可以效率很高的进行回答。
- 但从实际的效果来看,现阶段,绝大部分产品只能完成简单的问答和对话。其实我们思考一下,对于以下几种问题是难度非常大的,一是存在歧义的时候,比如“你喜欢苹果吗”,这里的苹果是水果还是手机,实体消岐问题。二是有上下文关联问题时,和机器聊天,如果我问“我今天问的苹果和昨天问的苹果一样吗”,这种机器就很难,因为我们目前见到的聊天机器人都只能回答单个问题。三是要用到逻辑推理时,我认为这个时最难的,人的联想和推理能力目前机器很难超越,比如我问机器“湖人队如果赢了火箭队,谁能当美国总统”,机器能否理解这个问题是无厘头问题都比较难,说不定会回答一堆别的东西。
2.语义搜索
知识图谱比搜索引擎做的效果要好的多。比如搜索香蕉的颜色是什么?搜索引擎会返回给用户一堆网页,让用户自己判断,而知识图谱系统会直接返回知识:黄色。
3.个性化推荐
个性化推荐是指基于用户画像, 不同的用户会看到不同的推荐结果, 有着重要的商业价值。
例如: 基于商品间的关联信息以及从网页抽取的相关信息, 构建知识图谱, 当用户输入关键词查看商品时, 基于知识图谱向用户推荐可能需要的相关知识, 包括商品结果、使用建议、搭配等, 通过“你还可能感兴趣的有”、“猜您喜欢”或者是“其他人还在搜”进行相关的个性化推荐。
最后附上谷歌 2012 年的这篇博客:
《Introducing the Knowledge Graph:things,not strings》Search is a lot about discovery—the basic human need to learn and broaden your horizons. But searching still requires a lot of hard work by you, the user. So today I’m really excited to launch the Knowledge Graph, which will help you discover new information quickly and easily.
Take a query like [taj mahal]. For more than four decades, search has essentially been about matching keywords to queries. To a search engine the words [taj mahal] have been just that—two words.
But we all know that [taj mahal] has a much richer meaning. You might think of one of the world’s most beautiful monuments, or a Grammy Award-winning musician, or possibly even a casino in Atlantic City, NJ. Or, depending on when you last ate, the nearest Indian restaurant. It’s why we’ve been working on an intelligent model—in geek-speak, a “graph”—that understands real-world entities and their relationships to one another: things, not strings.The Knowledge Graph enables you to search for things, people or places that Google knows about—landmarks, celebrities, cities, sports teams, buildings, geographical features, movies, celestial objects, works of art and more—and instantly get information that’s relevant to your query. This is a critical first step towards building the next generation of search, which taps into the collective intelligence of the web and understands the world a bit more like people do.
Google’s Knowledge Graph isn’t just rooted in public sources such as Freebase, Wikipedia and the CIA World Factbook. It’s also augmented at a much larger scale—because we’re focused on comprehensive breadth and depth. It currently contains more than 500 million objects, as well as more than 3.5 billion facts about and relationships between these different objects. And it’s tuned based on what people search for, and what we find out on the web.The Knowledge Graph enhances Google Search in three main ways to start:
1.Find the right thing
Language can be ambiguous—do you mean Taj Mahal the monument, or Taj Mahal the musician? Now Google understands the difference, and can narrow your search results just to the one you mean—just click on one of the links to see that particular slice of results:
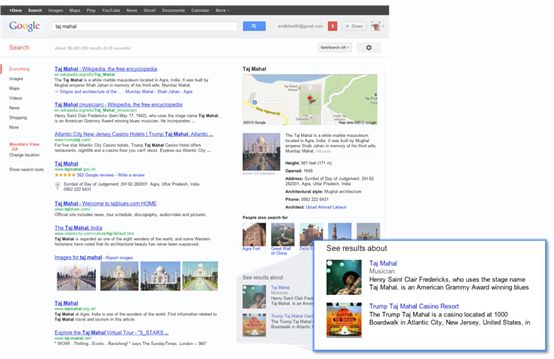
2.Get the best summaryWith the Knowledge Graph, Google can better understand your query, so we can summarize relevant content around that topic, including key facts you’re likely to need for that particular thing. For example, if you’re looking for Marie Curie, you’ll see when she was born and died, but you’ll also get details on her education and scientific discoveries:
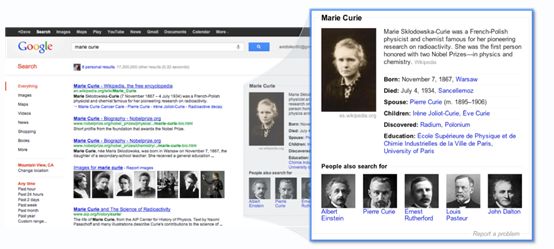
How do we know which facts are most likely to be needed for each item? For that, we go back to our users and study in aggregate what they’ve been asking Google about each item. For example, people are interested in knowing what books Charles Dickens wrote, whereas they’re less interested in what books Frank Lloyd Wright wrote, and more in what buildings he designed.
The Knowledge Graph also helps us understand the relationships between things. Marie Curie is a person in the Knowledge Graph, and she had two children, one of whom also won a Nobel Prize, as well as a husband, Pierre Curie, who claimed a third Nobel Prize for the family. All of these are linked in our graph. It’s not just a catalog of objects; it also models all these inter-relationships. It’s the intelligence between these different entities that’s the key.
3.Go deeper and broader
Finally, the part that’s the most fun of all—the Knowledge Graph can help you make some unexpected discoveries. You might learn a new fact or new connection that prompts a whole new line of inquiry. Do you know where Matt Groening, the creator of the Simpsons (one of my all-time favorite shows), got the idea for Homer, Marge and Lisa’s names? It’s a bit of a surprise:
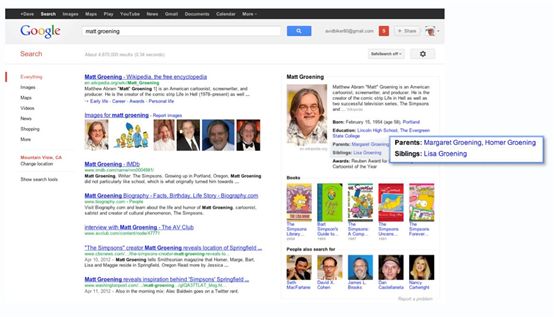
We’ve begun to gradually roll out this view of the Knowledge Graph to U.S. English users. It’s also going to be available on smartphones and tablets—read more about how we’ve tailored this to mobile devices. And watch our video (also available on our site about the Knowledge Graph) that gives a deeper dive into the details and technology, in the words of people who’ve worked on this project.
We hope this added intelligence will give you a more complete picture of your interest, provide smarter search results, and pique your curiosity on new topics. We’re proud of our first baby step—the Knowledge Graph—which will enable us to make search more intelligent, moving us closer to the “Star Trek computer” that I’ve always dreamt of building. Enjoy your lifelong journey of discovery, made easier by Google Search, so you can spend less time searching and more time doing what you love.
Posted by Amit Singhal, SVP, Engineering
阅读全文: http://gitbook.cn/gitchat/activity/5e5cf5a990867262b3e6319d
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。
