python爬虫之反爬虫情况下的煎蛋网图片爬取初步探索
本次爬虫网址:http://jandan.net/ooxx
前言:
前段时间一直在折腾基于qqbot的QQ机器人,昨天用itchat在微信上也写了一个机器人,相比webqq,微信的web端功能比较丰富,图片、文件等都可以传输。今天闲来无事准备给写个爬虫丰富微信机器人的功能,就想到了爬煎蛋网上面的图片。
说做就做,打开浏览器一看,渲染前的源码里是没有图片地址的。这个很正常,首先想到的就是异步请求去获取例如json格式的图片地址,然后渲染在页面上。于是用Chrome的全局搜索功能尝试搜了一下某一张图片的地址,结果居然是没有搜到。早就耳闻煎蛋被爬虫弄得苦不堪言,看来也开始采取一些措施了。于是去GitHub上搜了一下jiandan关键词,按时间排序,发现靠前的几个项目要不就没意识到煎蛋的反爬从而还是在用原来的方式直接处理源码,要不就是在用selenium(web自动化框架,可参考我的这篇文章:点击打开链接)进行爬虫。看来这个简单的这个反爬机制是最近一个月才用上的,很不凑巧被我撞上了。用selenium确实是一种万能、省力的方式,但实在太耗费性能。我在我阿里云的服务器上放了一个selenium+chromeheadless的微博爬虫,每次爬虫运行的时候服务器都非常卡。加上对煎蛋的反爬机制挺好奇的,于是我就准备通过分析js来找出图片的请求地址。
正文:
首先查看js渲染前的html源码,发现放图片的位置是这样的![]()
本该放地址的地方赫然放着blank.gif,并且在onload属性上绑定了一个jandan_load_img函数。这个jandan_load_img就成为本次爬虫的突破所在了。继续ctrl+shift+F全局搜索,找到这个函数
function jandan_load_img(b) {
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = f_K1Ft7i9UekcAhptpgQlLRFFKpzH6gOr0(e, "n8DpQLgoyVr2evbxYcQyFzxk9NRmsSKQ");
var a = $('[查看原图]');
d.before(a);
d.before("
");
d.removeAttr("onload");
d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3"));
if (/\.gif$/.test(c)) {
d.attr("org_src", location.protocol + c);
b.onload = function() {
add_img_loading_mask(this, load_sina_gif)
}
}
}果然就是这个函数在处理图片相关的标签,写在一个单独的js文件里。容易看到,第7、8行将a标签插入到img之前,查看源码看到a标签就是是查看原图的链接,也就是我们接下来爬取的时候用到的地址了。第6行f_后跟着一长串字母的这个函数(简称f函数)返回的就是图片地址。第7行中replace函数的作用是当图片为gif时替换中间的一个字符串为large。
那么接下来的任务就是分析f函数到底是怎么获取图片的地址的。首先看参数,第一个参数e为img-hash标签的text,第二个参数则是一个常量。这个常量我实测是会变化的,所以需要我们去请求这个js文件然后用正则去匹配到该常量。js文件的地址则写在了html源码里,文件名应该也是会变化的,也是用正则去匹配到。拿到常量之后接下来仍然使用chrome全局搜索(注:最好是打上断点跳过去,同一个js文件里的第605行和第943行有两个f函数可能会造成干扰,参见本文评论区),找到f函数,我发现此函数只是在做一些md5、base_64加密等操作,并不算复杂,可以将js代码转为python运行。当然也可以选择直接运行js,不过应该也是比较耗费性能的。我在转化成python代码的过程中,在base64解码上耗费了较长时间,也说明了自己在字符编码方面的知识比较薄弱。
下面是我对转换的一点解释,把一些无意义的ifelse等代码精简掉,再把代码分成五块之后,f函数长这样:
var f_K1Ft7i9UekcAhptpgQlLRFFKpzH6gOr0 = function(m, r, d) {
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var l = m.substr(0, q);
var c = o + md5(o + l);
var k;
m = m.substr(q);
k = base64_decode(m);
var h = new Array(256);
for (var g = 0; g < 256; g++) {
h[g] = g
}
var b = new Array();
for (var g = 0; g < 256; g++) {
b[g] = c.charCodeAt(g % c.length)
}
for (var f = g = 0; g < 256; g++) {
f = (f + h[g] + b[g]) % 256;
tmp = h[g];
h[g] = h[f];
h[f] = tmp;
}
var t = "";
k = k.split("");
for (var p = f = g = 0; g < k.length; g++) {
p = (p + 1) % 256;
f = (f + h[p]) % 256;
tmp = h[p];
h[p] = h[f];
h[f] = tmp;
t += chr(ord(k[g]) ^ (h[(h[p] + h[f]) % 256]));
}
t = t.substr(26);
return t
};转换得到的python代码也相对应地分成五块之后如下:
def parse(imgHash, constant):
q = 4
constant = md5(constant)
o = md5(constant[0:16])
l = imgHash[0:q]
c = o + md5(o + l)
imgHash = imgHash[q:]
k = decode_base64(imgHash)
h =list(range(256))
b = list(range(256))
for g in range(0,256):
b[g] = ord(c[g % len(c)])
f=0
for g in range(0,256):
f = (f+h[g]+b[g]) % 256
tmp = h[g]
h[g] = h[f]
h[f] = tmp
result = ""
p=0
f=0
for g in range(0,len(k)):
p = (p + 1) % 256;
f = (f + h[p]) % 256
tmp = h[p]
h[p] = h[f]
h[f] = tmp
result += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
result = result[26:]
return result这样对比之下应该就比较清晰了,基本上就是逐行翻译。另外base64需要重写一下。
最后就是一些普通的http请求操作了,以及使用itchat进行图片传输。所有代码已经上传到github上,后续有时间我打算添加上ip代理等新功能。没有系统学习过python所以代码可能不太规范,希望大家多多交流。项目地址:点击打开链接
另附本次爬虫的思维导图:
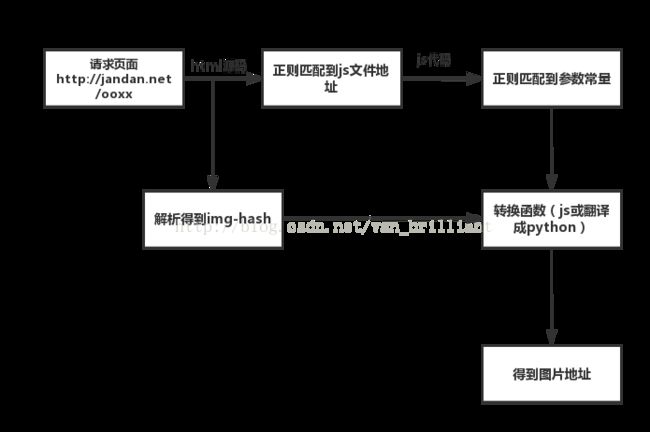
温馨提醒:虽然煎蛋肯定还有其他反爬措施,大家在爬虫过程中请务必遵守基本的互联网秩序,具体是啥相信大家都懂滴。
参考资料:
python base64解码incorect padding错误:点击打开链接
写于2017年12月6日晚
编辑于2018年2月6日晚