Elasticsearch入门教程(一):Elasticsearch及插件安装
分享一个朋友的人工智能教程(请以“右键”->"在新标签页中打开连接”的方式访问)。比较通俗易懂,风趣幽默,感兴趣的朋友可以去看看。
一:安装Elasticsearch
-
下载并解压Elasticsearch
直接到官网(https://www.elastic.co/cn/downloads/elasticsearch)下载适合自己的系统的Elasticsearch,这里下载的是目前最新的版本6.1.1,然后解压放到合适的目录即可,这里放在/usr/local下面.
elasiticsearch目录
bin 运行Elasticsearch实例和管理插件的一些脚本
config 配置文件, elasticsearch.yml
data 在节点上每个索引/碎片的数据文件的位置
lib Elasticsearch自身使用的.jar文件
logs 日志文件
modules
plugins 已安装的插件的存放位置 -
启动Elasticsearch
切换到Elasticsearch目录下,然后运行bin下的elasticsearch
cd /usr/local/elasticsearch-6.1.1 ./bin/elasticsearch./bin/elasticsearch是前台启动,如果想后台启动可以使用-d参数: ./bin/elasticsearch -d
-
REST访问
Elasticsearch使用的端口是9200,可以在浏览器上直接访问http://localhost:9200/ 或者使用curl命令访问http://localhost:9200
curl -XGET 'http://localhost:9200' { "name" : "XV7DTDS", "cluster_name" : "elasticsearch", "cluster_uuid" : "4-7jTDMbSASmws83WgavTg", "version" : { "number" : "6.1.1", "build_hash" : "bd92e7f", "build_date" : "2017-12-17T20:23:25.338Z", "build_snapshot" : false, "lucene_version" : "7.1.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" } -
停止Elasticsearch
如果使用前台模式启动的话直接使用Ctrl+C来停止Elasticsearch
二:安装ik分词器
分词是全文索引中非常重要的部分,Elasticsearch是不支持中文分词的,ik分词器支持中文
-
下载elasticsearch-analysis-ik
直接到github上下载elasticsearch-analysis-ik分词器,注意下载分词器的版本必须要和elasticsearch的版本保持一致,下载地址 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.1.1/elasticsearch-analysis-ik-6.1.1.zip, 根据需要可以将6.1.1改成自己elasticsearch的版本就可以直接下载。
-
安装ik分词器
直接解压elasticsearch-analysis-ik-6.1.1.zip,并将解压后的文件目录elasticsearch放到elasticsearch的安装目录下的plugins下,然后重启elasticsearch即可

-
测试ik分词器
curl -XGET -H 'Content-Type: application/json' 'http://localhost:9200/_analyze?pretty' -d '{
“analyzer” : “ik_max_word”,
“text”: “中华人民共和国国歌”
}’
---
### 三: 安装kibana
Kibana是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。
1. 下载并解压
直接到官网https://www.elastic.co/downloads/kibana 去下载,解压到合适的目录,下载的版本必须要和Elasticsearch的版本保持一致
2. 配置elasticsearch.url
编辑 kibana目录/conf/kibana.yml 文件中有一个elasticsearch.url被注释掉了,打开elasticsearch.url注释即可
3. 启动kibana
切换到kibana目录并启动
cd /usr/local/kibana-6.1.1
./bin/kibana
4. 访问:http://localhost:5601/
---
### 四: 安装x-pack
注意:安装x-pack需要先安装kibana
>x-pack安装:讲的比较详细,这里推荐一下 http://www.51niux.com/?id=210
x-pack是elasticsearch的一个扩展包,将安全,警告,监视,图形和报告功能捆绑在一个易于安装的软件包中
具体按住步骤官网上有详细说明:https://www.elastic.co/downloads/x-pack
cd /usr/local/elasticsearch-6.1.1
安装过程中输入y即可
./bin/elasticsearch-plugin install x-pack
启动es
./bin/elasticsearch
在另一个窗口执行
cd /usr/local/elasticsearch-6.1.1
设置过程中提示,输入y即可
./bin/x-pack/setup-passwords auto
# 返回结果
Changed password for user kibana
PASSWORD kibana = wZ54LdeFa+1N5C##IAuF
Changed password for user logstash_system
PASSWORD logstash_system = E6&gqoW5TP-?JJMLsHjs
Changed password for user elastic
PASSWORD elastic = @Dc?$qz3w6eZf%jUwKD+
cd /usr/local/kibana-6.1.1
安装过程比较慢
./bin/kibana-plugin install x-pack
在kibana.yml中配置用户名和密码
elasticsearch.username: “kibana”
密码是上面步骤自动生成的
elasticsearch.password: “wZ54LdeFa+1N5C##IAuF”
安装完成后访问http://localhost:5601/并使用用户名: elastic 密码:@Dc?$qz3w6eZf%jUwKD+ 登录
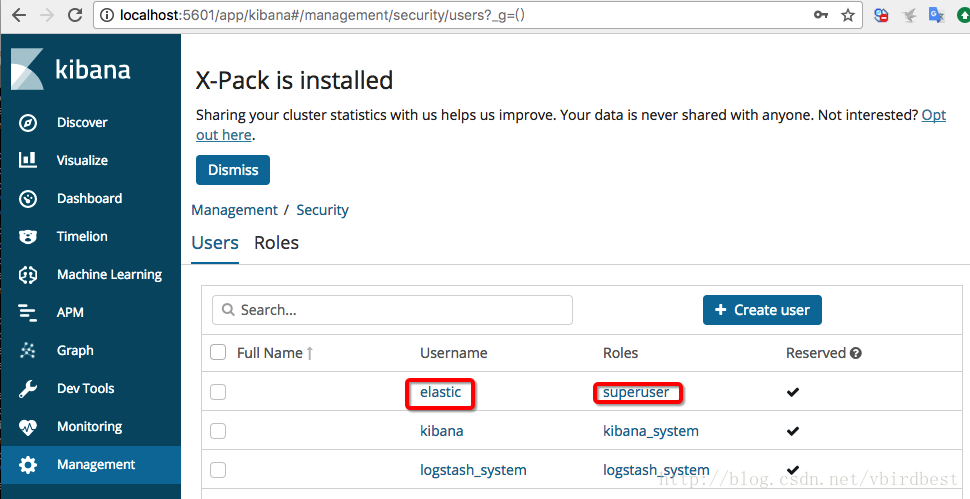
注意:elastic的角色是超级用户superuser,超级用户可以在Dev Tools中使用api操作es,kibana用户的角色是kibana_system,通过Management可以对用户进行管理,如创建用户、修改密码(为了方便,这里把密码改成了123456)、分配权限等
Dev Tools: 可以对curl进行简化操作es,只需要指定HTTP动词、api路径和参数即可。例如
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
Monitoring: 用于监控集群
# -i:用于显示响应头
# -u:用于设置用户名和密码
# -H:用于设置参数的格式
# -X:用于指定http的动词
# 在路径上使用参数?pretty表示将响应结果进行格式化输出,更加容易读
curl -XGET -i -u elastic:123456 -H 'Content-Type: application/json' 'http://localhost:9200/_analyze?pretty' -d '{
"analyzer" : "ik_max_word",
"text": "中华人民共和国国歌"
}'
ES中常用的响应状态码:
200 OK - 一般表示操作成功
404 Not Found - 一般在查询时找不到文档是返回404找不到
201 Created - 一般创建文档成功时返回201已经创建
409 Conflict - 一般创建文档或者更新文档时失败返回冲突
问题
在登录kibana,如果用户名和密码不能输入,提示“Login is currently disabled. Administrators should consult the Kibana logs for more details.”
需要重新生成密码, 然后将elstic的用户名和密码配置到kibana.yml中
./bin/x-pack/setup-passwords auto
elasticsearch.username: "elastic"
elasticsearch.password: ""
安装Logstash
该部分不是必须的,可忽略。
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。能集中处理各种类型的数据,能标准化不同模式和格式的数据,能快速的扩展自定义日志的格式,能非常方便的添加插件来自定义数据源, Logstash采用JRuby开发的,本身也支持插件的功能
ELK:开源分布式日志分析搜索平台
- E: elasticsearch, 负责数据的存储和查询
- L: logstash, 负责日志数据的过滤和解析
- K: Kibana, 负责web方式的前端展现
启动
./logstash -e ‘input { stdin {} } output { stdout {} }’
安装时注意jdk的版本,如果在启动时报已下错误可能是jdk版本低了
NameError: cannot link Java class org.logstash.RubyUtil org/logstash/RubyUtil : Unsupported major.minor version 52.0
input: 用于处理输入的
filter: 用于处理过滤的
output: 用于处理输出的
input {
file {
path => ""
start_position => beginning
}
}
filter {
}
output {
elasticsearch {}
stdout {}
}
分享一个朋友的人工智能教程(请以“右键”->"在新标签页中打开连接”的方式访问)。比较通俗易懂,风趣幽默,感兴趣的朋友可以去看看。
我的微信公众号:
