JMeter学习笔记——JMeter关联
比如: 用户登录后,session信息都不同,有些操作要使用session,就需要将这个动态的信息保存下来。 还有经常遇到的场景,第二个请求提交的参数要从第一个请求的返回数据中获取。
具体方法:
一、正则表达式提取器
在默认的测试计划中添加一个线程组,然后添加取样器。
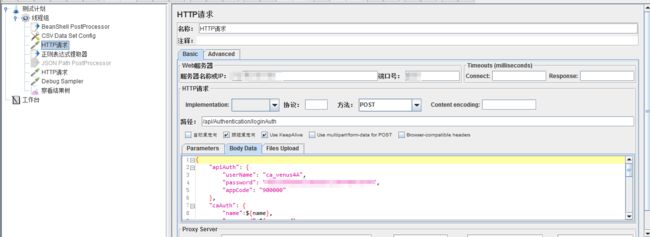
右键添加后置处理器→正则表达式提取器,正则表达式提取器界面如下:
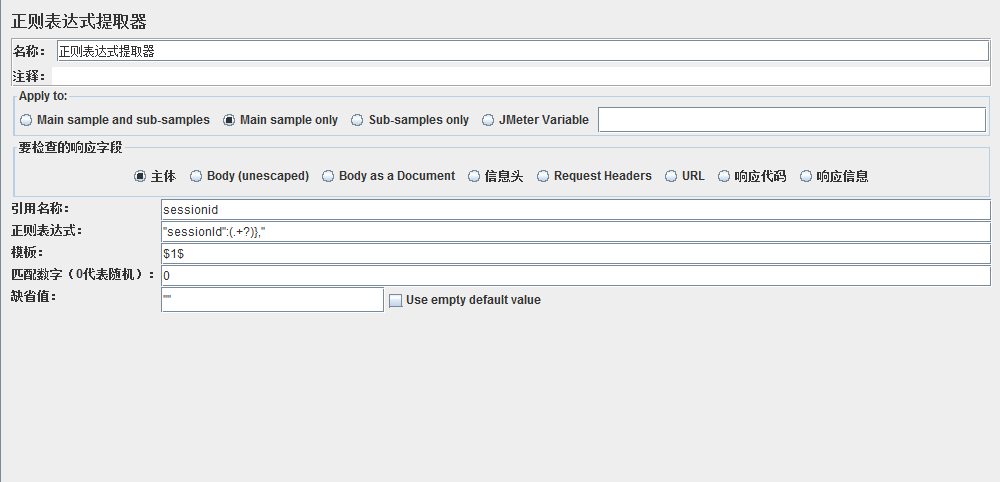
说明:
后置处理器:在请求结束或者返回响应结果时发挥作用
正则表达式提取器:允许用户从服务器的响应中通过使用perl的正则表达式提取值。该元素会作用在指定范围取样器,用正则表达式提取所需值,生成模板字符串,并将结果存储到给定的变量名中。
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
要检查的响应字段:需要检查的响应报文的范围
主体:响应报文的主体
Body(unescaped):主体,响应的主体内容且替换了所有的html转义符,注意html转义符处理时不考虑上下文,因此可能有不正确的转换,不太建议使用
Body as a Document:从不同类型的文件中提取文本,注意这个选项比较影响性能
Response Headers:响应信息头
Request Headers:请求信息头
URL:统一资源定位符,即Internet上用来描述信息资源的字符串
响应代码:响应状态码,比如200、404等
响应信息:响应信息
引用名称(Reference Name):Jmeter变量的名称,存储提取的结果;即下个请求需要引用的值、字段、变量名(例子中我提取的是SOCIAL_NO)
正则表达式(Regular Expression):使用正则表达式解析响应结果,“()”表示提取字符串中的部分值,请不要使用“||”,除非你本身需要匹配这个字符。
常用的正则表达式操作符:
操作符 |
说明 |
实例 |
. |
表示任何单个字符 |
|
[ ] |
字符集,对单个字符给出范围 |
[abc]表示a、b、c,[a-z]表示a-z的单个字符 |
[^ ] |
非字符集,对单个字符给出排除范围 |
[^abc]表示非a或b或c的单个字符 |
* |
前一个字符零次或无限次扩展 |
abc* 表示ab、abc、abcc、abccc等 |
+ |
前一个字符1次货无限次扩展 |
abc+ 表示 abc、abcc、abccc等 |
? |
前一个字符0次或1次扩展 |
abc? 表示 ab、abc |
| |
左右表达式的任意一个 |
abc|def 表示 abc、def |
{m} |
扩展前一个字符m次 |
ab{2}c 表示 abbc |
{m,n} |
扩展前一个字符m到n次 |
ab{1,2}c 表示 abc、abbc |
^ |
匹配字符串开头 |
^abc 表示 abc且在一个字符串的开头 |
$ |
匹配字符串结尾 |
abc$ 表示 abc且在一个字符串结尾 |
( ) |
分组标记内部只能使用|操作符 |
(abc)表示abc,(abc|def)表示abc、def |
\d |
数字,等价于0-9 |
|
\w |
单词字符,等价于[a-z0-9A-Z_] |
|
模板:代表从正则表达式结果引用的样式,其实结果是一组,而不是一个。$0$代表这一组结果的全部,$1$代表这一组结果的第1个,以此类推;$1$$2$代表该正则表达式一组结果中的第1个和第2个,俩结果挨在一起中间没有间隔;$3$,$4$代表该正则表达式一组结果中的第3个和第4个,俩结果间有一个逗号相连。
匹配数字:0代表正则表达式结果组中随机,1代表全部。
缺省值:当引用不对时显示传递的信息,通畅写一个ERROR。
最后,根据上面的说明,完成配置,然后可以先添加一个监视器(查看结果树),检查是否取到了对应的值;提取到的参数,调用时用${sessionid_1},${sessionid_2}...,如果想要得到匹配出的参数的个数,${sessionid_matchNr}。
二、json path postprocessor(JSON Extractor)
用处:
当前接口响应返回的json中提取内容,作为变量可以在不同的请求中传递。如下,从登陆接口返回的json中提取user id,变量名设置为id,在其他请求中可以直接调用这个变量,或者作为post参数。次插件对于restful接口非常好用。

Variable names : 名称
JSONPath Expression:JSON表达式
Match Numbers:匹配哪个,可为空即默认第一个
Default Value:未取到值的时候默认值
比如返回值如下:
{
"userSession": {
"businessCode": "900000",
"createTime": "2018-05-25 03:24:17",
"userCode": "29feaa3c98014e02bec16c6f448a6459",
"userName": "lip-",
"sessionId": "10a4cee035d044d8b2f25e2cebb2843e"
}
}则json表达式为:$.userSession.sessionId
如果返回值是数组,则需要加上数组的位置,如
{
"userSession": [
{
"businessCode": "900000",
"createTime": "2018-05-25 03:24:17",
"userCode": "29feaa3c98014e02bec16c6f448a6459",
"userName": "lip-",
"sessionId": "10a4cee035d044d8b2f25e2cebb2843e"
}
]
}三、XPath Extractor
jmeter提供的对关联的支持包括以下2个方面:①能够将返回页面上的指定内容保存在参数中;(即正则表达式提取器和JSON Extractor)
②能够将GET或POST方法中的数据使用该参数来替换;(XPath Extractor)
XPath Extractor的使用方法与正则表达式提取器(Regular Expression Extractor)类似,只不过该Expression中指定的不是正则表达式,而是给定的XPath路径。
后置处理器(Post Processor)本质上是一种对sampler发出请求后接受到的响应数据进行处理(后处理)的方法。必须将后置处理器元件放在合适的位置才能达到预期的效果。
新建一个线程组,然后右键-添加-后置处理器-XPath Extractor:
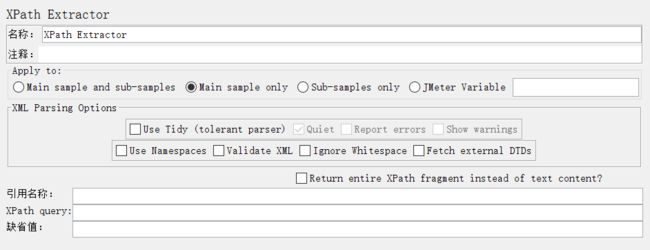
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:要解析的XML参数
Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet表示只显示需要的HTML页面,Report errors表示显示响应报错,Show warnings表示显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容;
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
Reference Name:存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。
Default Value:参数的默认值。
正则表达式提取器和XPath Extractor的区别:
①正则表达式提取器可以用于对页面任何文本的提取,提取的内容是根据正则表达式在页面内容中进行文本匹配;
②XPath Extractor则可以提取返回页面任意元素的任意属性;
③如果需要提取的文本是页面上某元素的属性值,建议使用XPath Extractor;
④如果需要提取的文本在页面上的位置不固定,或者不是元素的属性,建议使用正则表达式提取器。