操作系统原理Linux篇 读书笔记(2)——Linux进程管理
1.Linux进程的组成
Linux进程组成:由 正文段(text)、用户数据段(user segment)和系统数据段。
➢ 正文段:存放进程要执行的指令代码。Linux中正文段具有只读属性。
➢ 用户数据段:进程运行过程中处理数据的集合,它们是进程直接进行操作的所有数据,包括进程运行处理的数据段和进程使用的堆栈。
➢ 系统数据段:存放反映一个进程的状态和运行环境的所有数据。这些数据只能由内核访问和使用。 在系统数据段中包括进程控制块PCB.。
在Linux中,PCB是一个名为task_struct的结构体,称为任务结构体。2.Linux进程在处理机上的执行状态
在Linux系统中,用户不能直接访问系统资源,如处理机、寄存器、存储器和各种外围设备。因此提供了两种不同指令:
➢ 一般指令:供用户和系统编程使用,不能直接访问系统资源;
➢ 特权指令:供操作系统使用,可以直接访问和控制系统资源;
为了区分处理机在执行那种指令,通常将处理机的执行状态又分为两种:
➢ 管态(内核态、系统)
➢ 目态(用户态)
由目态转变为管态的情况可能有:
➢ 进程通过系统调用向系统提出服务请求
➢ 进程执行某些不正常的操作时,如除数为0、超出权限的非法访问、用户堆栈溢出等。
➢ 进程使用设备进行I/O操作时,当操作完成或设备出现异常情况时。- 3.进程空间和系统空间
进程的虚拟地址空间:Linux操作系统运行在多道环境下,多个进程能够同时在系统中并发活动。为了防止进程间的干扰,系统为每个进程都分配了一个相对独立的虚拟地址空间,又称为进程的虚拟内存空间。
进程的虚拟地址空间包含进程本身的代码和数据等,同时还包括操作 系统的代码和数据。故进程的虚拟地址空间分两部分:进程空间和系统空间。
进程空间(如图):
注:
➢ 内核堆栈:进程在需要使用内核功能而通过系统调用运行内核代码时,需要使用堆栈保存数据。这个堆栈是由系统内和使用的,故称内核堆栈。
➢ 其中系统数据段,只能在内核态执行
系统空间:操作系统的内核映射到进程的虚拟地址空间。(可供多个进程共享,只能内核态执行)

4.进程上下文和系统上下文
进程上下文:进程的运行环境动态变化,在linux中把进程的动态变化的环境总和称为进程上下文。
➢ 当前进程
➢ 进程切换
➢ 上下文切换
➢ 进程通过系统调用执行内核代码时,内核运行是为进程服务,所以此时内核运行在进程上下文中。
系统上下文: 内核除了为进程服务,也需要完成操作系统本身任务,如响应外部设备的中断、更新有关定时器、重新计算进程优先级等。 故把系统在完成自身任务是的运行环境称为系统上下文(system context).5.Linux进程的状态及转换
linux中进程状态分为5种。
每个进程在系统中所处的状态记录在它的任务结构体的成员项state中。进程的状态用符号常量表示,它们定义在/include/linux/sched.h下:
- #define TASK_RUNNING 0 可运行态(运行态、就绪态)
- #define TASK_INTERRUPTIBLE 1 可中断的等待态
- #define TASK_UNINTERRUPTIBLE 2 不可中断的等待态
- #define TASK_ZOMBLE 3 僵死态
- #define TASK_STOPPED 4 暂停态- a.运行态(running)——运行,该进程称为当前进程(current process)
实际上linux并没有该状态,而是将其归结在可运行态。系统中设置全局指针变量current,指向当前进程。 - b.可运行态(Running)——就绪
Linux中把所有处于运行、就绪状态的进程链接成一个双向链表,称为可运行队列(run_queue)。使用任务结构体中的两个指针:
Struct task_struct next_run;/指向后一个任务结构体的指针*/
Struct task_struct prev_run;/指向前一个任务结构体的指针*/
该链表的首结点为init_task。系统设置全局变量nr_running记录处于运行、就绪态的进程数。 - c.等待态(wait)——阻塞
在linux中将该状态进一步划分为:可中断的等待态(interruptible)和不可中断的等待状态(uninterruptible)。
➢ 可中断的等待态的进程可以由信号(signal)来解除其等待态,收到信号后进程进入可运行态。
➢ 不可中断的等待状态的进程,一般都是直接或间接在等待硬件条件,只能用特定的方式来解除其等待状态,如是用wakeup()。
处于等待态的进程根据其等待的事件排在不同的等待队列中。Linux中等待队列是由一个wait_queue结构体组成的单向循环链表。该结构体定义在include/linux/wait.h中,如下所示:
Struct wait_queue {
Struct task_struct *task;/*指向一个等待态的进程的任务结构体*/
Struct wait_queue *next;/*指向下一个wait_queue结构体*/
}注:
➢ 与可运行队列不同,等待队列不是直接由进程的任务结构体组成队列,而是由于任务结构体对应的wait_queue构成。
➢ 每个等待队列都有一个指向该队列的队首指针,它一般是个全局指针变量。
- d.暂停态(stopped)
暂停态:进程由于需要接受某种特殊处理而暂时停止运行所处的状态。通常,进程在接受到外部进程的某个信号(SIGSTOP、SIGSTP、SIGTTOU)而进入暂停态。通常正在接受调试的进程就处于暂停态。 - e.僵死态(zombie)
僵死态:进程的运行已经结束,但是由于某种原因它的进程结构体仍在系统中。 - 6.进程标识哈希表
Linux的进程表示哈希表提供了按照哈希算法从进程PID快速查找对应任务结构体的方法,实现哈希算法的哈希函数定义为带参数的宏pid_hashfn(x),如下所示:
#define pid_hashfn(x) ((((x)>>8)^(x))&(PIDHASH_SZ-1))???其中:参数x就是进程的标识PID,计算结果的哈希值用于检索对应的任务结构体。例如PID为228的哈希值是100,PID为27536的哈希值是123,PID为 27535的哈希值是100。
为了解决哈希值冲突的问题,Linux把具有相同哈希值的PID对应的进程组成一个个双向循环链表。在task_struct中的两个成员项:
Struct task_struct * pidhash_next;/指向后一个任务结构体的指针/
Struct task_struct * pidhash _prev;/指向前一个任务结构体的指针/
1.进程标识哈希表
Linux 使用一个称为pidhash[]的指针数组管理这些链表,称为进程标识哈希表。该表中记录各个链表首结点地址,数组元素的下标与链表的哈希值相同。在include/linux/sched.h中pidhash[]数组定义如下:
Struct task_struct * pidhash[PIDHASH_SZ];从定义中可以看出,
➢ pidhash数组由PIDHASH_SZ个元素组成,每个元素是指向一个进程任务结构体的指针。
➢ 数组元素个数PIDHASH_SZ是系统中最多可容纳的进程数NR_TASKS除以4,定义如下:
#define PIDHASH_SZ(NR_TASKS>>2)???图4.7Linux进程标识哈希表
2进程标识哈希表操作函数:
Hash_pid():进程创建时,将其任务结构体插入哈希链表
Unhash_pid():进程撤销时,将其任务结构体从哈希链表中删除。
Find_task_by_pid():根据PID相应进程的任务结构体。
- 7.Linux进程调度策略
Linux是一个同时具有分时和实时系统特征的操作系统。Linux在进程调度中采用的是可抢占的调度方式。
Linux中的进程分为普通进程和实时进程。实时进程的优先级高于普通进程。对实时进程和普通进程采用不同的调度策略。
Linux为每个进程都规定了一种调度策略,并记录在其任务结构体policy成员项中。Linux调度策略有3种,它们以符合常量的形式定义在/include/linux/sched.h中,其定义及意义如下所示:
#define SCHED_OTHER 0 普通进程的时间片轮转算法(根据优先权选择下一个进程)
#define SCHED_FIFO 1 实时进程的先进先出算法(适用于响应时间要求比较严格的短小进程)
#define SCHED_RR 2 实时进程的时间片轮转算法(适用于响应时间要求比较严格的较大进程)因此在linux的可运行队列中,从调度策略来分SCHED_FIFO的实时进程具有最高优先级,其次是SCHED_RR的实时进程,而SCHED_OTHER的普通进程优先级最低。
8.Linux进程调度方法
实时进程的优先级大于普通进程的优先级,故只有当可运行队列的所有实时进程都运行完成后,普通进程才能得到运行。
linux普通进程的优先级由Priority和counter共同决定。在进程运行过程中Priority保持不变,体现了进程的静态优先级概念;而counter不断减少,表示了进程的动态优先级。采用动态优先级的方法,使得一个进程占用CPU的时间越长,counter的值越小。这样使得每个进程都可以公平地分配到CPU。-
- Linux进程调度时机
Linux进程调度是由Schedule()完成的。该函数定义在/kernel/sched.c中。执行该函数 的情况可以分为两种:
➢ 在某些系统调用函数中直接调用Schedule()。
➢ 在系统运行过程中,通过检查调度标志而执行该函数。进程调度标志是一个名为need_resched的全局变量,当它的值为1时,表明需要执行调度函数。
下面介绍几种需要执行进程调度的时机:
1.进程状态发生变化时
Linux进程状态不断发生变化,在下列状态转换是需要执行进程调度:
1)当前进程进入等待状态
例如,运行太的进程可以通过执行系统调用sleep_on()主动放弃CPU而进入等待状态。Sleep_on()的部分源代码如下:
- Linux进程调度时机
Current->state=state; /* 把当前进程状态设置为等待状态*/
Save_flags(flags);
_add_wait_queue(p,&wait); /*把当前进程加入等待队列*/
Sti();
Schedule(); /*执行进程调度*/
Cli();2)运行态下的进程运行结束后
一般通过调用内核函数do_exit()终止运行进程并转入僵死状态。该函数部分源码:
……
Current->state = TASK_ZOMBIE; /*把当前进程设置为僵死状态*/
……
Schedule();/*执行调度程序*/
……3)使用wake_up_process()将处于等待状态的进程唤醒,然后将它置于可运行状态。该函数部分源码:
Save_flags(flafs);
Cli();
p->state = TASK_RUNNING; /*把进程置为可运行态*/
if(!p—>next_run)
add_to_runqueue(p); /*加入到可运行队列*/
restore_flags(flags);
if(p->counter>current->counter+3)
need_resched =1; /*调度标志置位,执行进程调度*/4)当一个进程的程序接受调试时。
调式进程向被调试进程发送SIGSTOP信号,被调试进程处理该信号时调用内核函数do_signal()。部分源码:
……
Current->state = TASK_STOPPED /*把当前进程置为暂停态*/
Notify_parent(current);
Schedule();/*执行进程调度*/
……5)当被调试的进程接收到调试进程发送的SIGCONT信号时,执行send_sig(),其中使用wake_up_process()解除被调试进程的暂停态而重新进入可运行态。
If(sig==SOGKILL||sig==SIGCONT))
{
If(p->state==TASK_STOPPED) /*若进程为暂停态*/
wake_up_process(p);2.当前进程时间片用完时
在进程时间片运行完时,需要将CPU重新分配给下一个被选中的进程,这个过程是在时钟中断中实现。在时钟中断处理程序中调用了内核函数update_process_times(),它用于更新进程的各个时间信息,其中包括下面语句:
p->counter -= ticks
if(p->counter<0)
{
P->counter=0;
Need_resched=1;
}3.进程从系统调用返回用户态时
当进程从系统调用返回用户态时,需要执行内核的汇编例程ret_from_sys_call,其中包括对need_resched标志进行检测的指令。
Cmpl $0,need_resched
Jne reschedule
当need_resched=1时,就转移到reschedule。
Reschedule:
Call SYMBOL_NAME(schedule)
4.中断处理后,进程返回用户态时
同3,当中断处理结束后,也需要执行内核的汇编例程ret_from_sys_call
- 10.Linux进程的创建和撤销
- 1 Linux进程的族亲关系
在系统加电启动后,系统只有一个进程,它就是由系统创建的初始进程,又称init进程。Init进程的任务结构体名字为init_task。Init进程是系统中所有进程的祖先进程,进程标识号PID为1。
➢ 进程之间的父子关系
➢ 进程之间的兄弟关系:按照创建时间确定,先者为兄,后者为弟; - 2 Linux进程的族亲关系
在每个进程的任务结构体中设置了5个成员项指针:
- 1 Linux进程的族亲关系
Struct task_struct *p_opptr /*指向祖先进程任务结构体指针*/
Struct task_struct *p_pptr /*指向父进程任务结构体指针*/
Struct task_struct *p_cptr /*指向子进程任务结构体指针*/
Struct task_struct *p_ysptr /*指向弟进程任务结构体指针*/
Struct task_struct *p_osptr /*指向兄进程任务结构体指针*/说明:
在任务结构体中只有一个指向子进程指针,它指向该进程子进程中最年轻的一个,其他子进程通过兄弟关系指针与父进程的关系。
- 11.Linux进程的创建
Linux中,除init进程是启动时由系统创建的,其他进程都是由当前进程使用系统调用fork()创建的。
➢ 子进程被创建后,通常要继承(共享)父进程所有的资源。包括虚拟存储空间的内容、打开的文件、专用的信号处理程序等。
➢ 写时拷贝(copy on write)技术:子进程和父进程共享同一个虚拟空间,只是这两个进程中某个进程需要虚拟内存写入时,这时才建立属于该进程的那部分虚拟空间,并把原虚拟空间的那部分内容拷贝到新建的虚拟内存区域中,然后在新建的属于自己的虚拟空间区域中写入信息。 这样既可以使子进程继承父进程的资源,又可以在需要时建立自己的存储空间,避免子进程存储空间的无谓浪费,有效地节省了系统时间。
➢ 父进程和子进程在“分裂”后,运行时都在继续执行fork()程序的代码。但是为了区分两个进程:父进程执行完fork()时返回值是子进程的PID值;而子进程执行fork()的返回值是0。
例:
#include 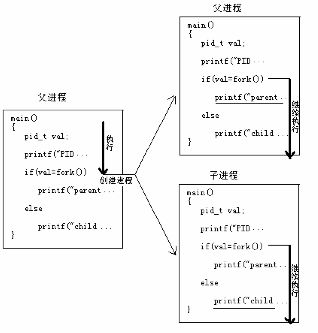
- 12 .Linux进程创建的过程
Linux中进程都是由当前进程使用系统调用fork()创建的,而实际上是fork()中进一步调用内核函数do_fork()来完成的。Fork()的源代码定义在/kernel/fork.c中。下面给出do_fork()内核函数的主要功能:
1)在内存空间为新进程(子进程)分配任务结构体使用的空间,然后把当前进程(父进程)的任务结构体的所有内容拷贝到子进程的任务结构体中。
2)为新进程在其虚拟内存建立内核堆栈。虽然子进程共享父进程的虚拟空间,但是两个进程在进入核心态后必须有自己独立的内核堆栈。
3)对子进程任务结构体中的部分内容进行初始化设置,例如进程的链接关系(族亲关系)等,主要是与父进程不同的那些数据。
4)把父进程的资源管理信息拷贝给子进程,如虚拟内存信息、文件信息、信号信息等,前面说过,这里的拷贝是建立两个进程对这些资源的共享关系。
5)把子进程加入可运行队列中,由调度进程在适当的时机调度运行,也就是在这个时候,当前进程分裂为两个进程。
7)无论哪个进程使用CPU运行,都继续执行do_fork()函数的代码,执行结束后返回它们各自的返回值。
从以上过程可以看出,do_fork()函数的功能首先是建立子进程的任务结构体和对其进行初始化,然后继承父进程资源,最后设置进程的时间片并把它加入可运行队列。
- 子进程执行新的程序
一个进程使用fork()建立子进程后,让子进程执行另外一个程序的方法也是通过使用exec()系统调用。程序的一般形式为:
- 子进程执行新的程序
Main()
{
Pid_t val;
Val =fork();
If(val!=0)
{
…….. /*执行父进程的语句*/
}
Else
{
exec(…..); /*执行程序*/
}
……..
Exit(1);
}Linux采用“写时拷贝”技术,所以子进程在创建时是共享父进程的正文段和数据段,但是在执行exec()时,子进程将建立自己的虚拟空间,并把参数arg0制定的可执行程序映像装入子进程的虚拟空间,这是就形成了子进程自己的正文段和数据段。
- 12.Linux进程的终止和撤销
进程终止的两种情况:
➢ 进程完成自身的任务而自动终止:方法1,使用系统调用exit()显示终止进程;方法2,执行到程序的main()的结尾而隐式地终止进程。
➢ 进程被内核强制终止:如进程运行出现致命错误,或者收到不能处理的信号时。
1.进程的终止 exit()
Linux中终止进程是通过调用内核函数do_exit()实现的,该函数定义在kernel/exit.c中。下面结合do_exit()函数的部分源代码对进程终止和撤销的过程说明如下:
1)函数首先设定当前进程的标志,即任务结构体的flags成员项设定为PF_EXITING,表示该进程将要终止
Current->flags = PF_EXITING;
2) 释放系统中该进程在各个管理队列中的任务结构体。
Del_timer(¤t->real_timer);/从动态计时器系列中释放该进程的任务结构体/
Sem_exit(); /从IPC进程间通信的信号量机制中释放该进程的任务结构体/
3)释放进程使用的各种资源。
Kerneld_exit(); /*释放内核*/
_exit_mm(current); /*释放虚拟空间*/
_exit_files(current); /*释放打开的文件*/
_exit_fs(current); /*释放fs结构体*/
_exit_sighand(current); /*释放信号*/
Exit_thread(); /*释放线程*/4)把进程的状态设置为僵死状态。
Current->state = TASK_ZOMBIE;
5)把退出码置入任务结构体。
Current->exit_code =code;/正常退出时,退出码为0;异常退出时,为非0值,通常是错误编号/
6)变更进程族亲关系。
Exit_notify();/把要撤销的进程的子进程的父进程赋予init进程/
7)执行进程调度,选择下一个使用CPU的进程。
Schedule();
2 . 进程的撤销 release()
一个进程终止后不能自己撤销自己,而只能由他的父进程或祖先进程来撤销它:
父进程在建立子进程后,通常要使用系统调用wait()等待子进程的终止。在一个进程终止时,把退出码置入任务结构体后,内核就把该进程终止的信号发给它的父进程。父进程就收到信号后,结束等待状态,继续执行wait()程序,检查到该子进程的状态为僵死态,则调用release()函数,撤销该子进程,将其任务结构体释放,则该子进程从此彻底消亡。
如果父进程在子进程之前终止,则为了不使其子进程成为孤立进程,则将它的子进程赋予init进程,使init进程成为这些进程的父进程,并由其负责撤销这些子进程。
- 13.Linux管道
- 1.管道的概念
管道是linux进程通信的一种手段,使用管道通信时,两个进程中的一个进程(写管道进程)从管道的一端把数据送入管道,另一个进程(读管道进程)从管道的另一端得到这些数据。管道实际上就是一种共享文件,所以管道机制是以文件系统为基础实现的。数据在管道中以先进先出的方式,并以字符流的形态传送。
- 1.管道的概念
管道分两种:无名管道、命名管道。它们的内部结构是一致的,但是用方式不同。
➢ 无名管道:只能在父子进程之间通信
➢ 命名管道:可以在任意进程间通信。
- 无名管道
linux管道可以在终端的命令行中使用,也可以在程序中使用。
1.终端使用
在终端键入Linux命令时,可以使用无名管道连接两个命令,例如
$ls –l | more
其中“|”就是管道命令符,它的作用是把第一条命令的输出与第二条命令的输入连接在一起。
2.程序中使用
在程序设计中无名管道的建立由系统调用pipe()实现,其定义:
#include 其中filedes[]是具有两个元素的int型数组。在调用pipe()建立一个无名管道后,使用两个文件标识号来表示管道的两端(一端写,一端读),并记入filedes[]中。其中filedes[0]是读取管道的文件标识号,filedes[1]是写入管道的文件标识号。
说明:
➢ 父子进程使用无名管道通信是建立在子进程继承父进程资源的基础上。父子进程通信时,必须先建立管道,再创建子进程。
➢ 使用管道时必须确定管道通信的方向,且一旦确定后不能改变。
➢ 父子进程中一个进程只能使用一个文件标识号,所以另一个不使用的标识号可以使用系统调用close()关闭它。

使用无名管道的进程通信
例:在该例中,父进程建立管道后创建一个子进程。子进程的任务是把一组字符串信息写入管道,父进程在子进程完成任务终止后,从管道中读取信息并显示在显示器上。
#include 继续说明:
➢ 无名管道与一般文件不同,它没有纳入文件系统的目录,不占用外存空间,仅使用内存作为数据传输的缓冲区。
➢ 缓冲区的大小决定每次写入管道的字节数。该值由全局符号常量PIPE BUF确定。 缺省值为一个物理页面。
➢ 由文件系统管理
- 命名管道
又称FIFO管道。命名管道与无名管道的区别:命名管道有文件名,在文件系统中可见;可以实现任意进程间的通信。
1.终端使用
使用mkfifo建立一个命名管道。
例: mkfifomyfifo;/∗建立一个名字为myfifo的管道。此时使用ls命令,就可以查看到该文件信息。 ls –l myfifo
prw-r—- wang user 0 fen 22 13:45 myinfo /*第一个字符p,表示是FIFO文件
在命名管道建立后,就可以用它在两个进程间进行通信。如:
cut –c1-5< myfifo&cat file1 >myfifo
其中cat命令把文件file1的内容写入管道myfifo,命令cut从管道myfifo中读出文件的内容进行裁剪后显示每行的前1~5个字符。
2.程序中使用
1)建立命名管道
方法一:调用C函数mkfifo()实现的,其定义如:
#include 其中:
path:指明要创建的命名管道的路径和名字;
mode:指明管道访问的权限。
创建成功返回0,否则为负数。
另一种方法:使用linux系统调用mknod()
mknod()可以建立任何类型的文件,在建立命名管道时使用的形式如下:
mknod(path,mode|S_FIFO,0);
参数含义与上同,其中S_FIFO表示建立FIFO文件。
这两种方法作用基本相同:建立命名管道的目录结构、inode节点、file文件结构体等。
2)打开管道
由于任何进程都可以通过命名管道进行通信,所以在使用命名管道时,必须先打开它,由系统调用open()实现。
open(char *path, int mode)
其中:
path:指明要使用的命名管道的路径和名字;
mode:指明管道访问的模式:O_RDONLY(只读)、O_WRONLY(只写)
创建成功返回文件标识号,否则为负数。
注:在使用文件操作对管道进行各种操作时,要使用文件标识号,而不是管道名。
例:有两个程序,其中wrfifo.c把一组信息写入管道,另一个程序rdfifo.c把管道中的信息读出后显示在屏幕上。
/*读管道程序rdfifo.c*/
#include - 13.IPC信号量机制
Linux的信号量机制有两种:
➢ 其本身设置的信号量机制
➢ 引进UNIX SYSTEM V的IPC(Internal Process Communication)中的信号量机制
本节介绍后者,其涉及到的函数和数据结构分别定义在Linux源文件的ipc/sem.c和include/linux/sem.h
- 1 信号量与信号量集合
- IPC信号量机制的工作原理与之前原理部分介绍的信号量的工作原理基本相同。但是它更完善、更方便使用。
1.信号量
定义:
系统中每个信号量对应一个信号量结构体sem,其定义如下:
Struct sem
{
Short semval; /信号量的值/
Unshort sempid; /记录对信号量最后一次实施操作进程的PID/
}
PV操作
(为了解决死锁)IPC信号量机制在这方面做了改进,它可以使用原语一次对多个信号量进行操作。为此,引进了信号量集合的概念。
2.信号量集合
在IPC信号量机制中,把进程需要访问资源对应的信号量组成一个信号量集合,并可以使用操作原语一次性地对信号量集中的多个信号量进行PV操作。
信号量数组:在IPC信号量机制中把多个信号量组成一个信号量集合,该集合由信号量结构体sem组成,称为信号量数组。
信号量集合描述符:系统中的每个信号量集合用一个描述符描述其特征和记载其管理信息。其定义如下:
Struct semid_ds
{
Struct_ipc_perm sem_perm; /对信号量集合的访问权限/
Time_t sem_otime; /最后一次对信号量集进行操作的时间/
Time_t sem_ctime; /最后一次修改信号量集的时间/
Struct sem sem_base; /指向信号量数组*/
Struct sem_queue sem_pending; /指向等待队列头*/
Struct sem_queue sem_pending_last;/ 指向等待队列尾*/
Struct sem_undo undo; /进程终止时需要使用sem_undo结构体中的信
息,对信号量集合进行有关操作*/
Unshort sem_nsems; /信号量集合中信号量的数目/
}
3.信号量集合的集中
IPC对系统中的所有信号量集合进行集中管理,把所有的信号量集合描述符组织在一个semary[]数组中,其定义如下:
Static struct semid_ds *smeary[SEMMNI];
其中SEMMNI为数组大小,是系统中可以设置的信号量集合的最大数目,其缺省值为128,宏定义如下:
#define SEMMNI 128 - 2 信号量PV操作
IPC中没有对信号量分别设置P和V操作原语,而是统一由具有原语性质的系统调用semop()实现的,通常称其为信号量操作函数。其定义如下:
Int semop(int semid,struct sembuf *sops, unsigned nsops);
➢ Semid:实施pv操作的信号量集合的标识号
➢ Nsops:本次实施操作的信号量的个数
➢ Sops:指向一个信号量操作数组。因为每次对信号量集合中实施操作的信号量个数不同,不同信号量实施的操作不同,所以必须指明本次操作是对哪些信号量,实施哪些操作。该数组的元素个数就是Nsops。
Sops中的每个元素是一个sembuf结构体,它由系统定义:
Struct sembuf
{
Ushort sem_num; /指出信号量在信号量数组中的下标/
Short sem_op; /指出操作的种类/
Short sem_flg; /指出操作的标志/
}
说明:
Sem_op的值决定操作的类型:
Sem_op的值是负数:表示进程请求资源,则实施P操作,把semval的值减去sem_op绝对值。
Sem_op的值是正数:表示进程释放资源,则实施V操作,把semval的值加上sem_op
以上两种情况下,若对信号量集实施操作后,所有信号量的值semval均大于等于0,则函数返回0,表示进程所需的多个资源都可用,此时进程可以继续运行;否则,只要有一个semval结果为负数,则表示进程需要的这种资源不可用,进程被阻塞,并将本次操作加入该信号量集合的等待队列。
Sem_op的值为0。此时若semval也是0,则函数返回,调用semop的进程继续执行;若semval非0,则进程被阻塞。
sem_flg :控制进程的执行。通常取值0;若指定为IPC_NOWAIT,则在执行semop操作时,即使出现需要进程阻塞的情况,也不阻塞,而是继续运行。 - 3 信号量操作等待队列
上节提到如果进程执行信号量操作时被阻塞,则将把该次操作被加入到信号量集合的等待队列。IPC每个信号量集合都有一个等待队列,分别由其描述符中的成员向sem_pending和sem_pending_last指向其头部和尾部。该等待队列是由sem_queue结构体组成的双向循环链表。
Struct sem_queue
{
Struct sem_queue *next; /*指向队列后一个节点*/
Struct sem_queue *prev; /*指向队列前一个节点*/
Struct wait_queue *sleeper; /*指向被阻塞进程*/
Struct sem_undo *undo;
Int pid; /*实施操作的进程的PID*/
Int status;
Struct semid_ds *sma; /*指出对哪个信号量集合实施操作*/
Struct sembuf *sops; /*指向是进程阻塞的操作数组*/
Int nsops; /*指出操作数组中操作的个数*/
}将信号量操作移出等待队列
上节我们介绍了,进程执行信号量操作时,出现进程阻塞,操作放入信号量操作等待队列的情况。下面我们介绍如何将进程唤醒、将操作冲等待队列移出的情况:
若某个进程在执行semop()时没有阻塞,函数将检查该信号量集的操作等待队列:
➢ 若无操作等待, 则返回;
➢ 若有操作等待, 则依次重新执行这些操作:
1)若进程仍需等待,则操作保留在等待队列中;
2)若进程可以继续执行,则通过该sem_queue结构体中的sleeper在进程等待队列中找到该进程,并将其唤醒;再将该sem_queue结构体从操作等待队列中删除。
- IPC消息队列
信号和管道。它们的缺点是,信号每次只能传递一个数据;管道只能在两个进程间单向交换信息。接下来我们将介绍两种高级通信机制IPC的消息队列和共享内存。
- 消息队列的结构
IPC的消息队列的工作原理与前面原理部分介绍过的进程间的消息通信机制基本一致。IPC消息队列一般用于客户机/服务器(C/S)模型中,客户机进程向服务器发送请求服务的消息,服务器进程接受到消息后执行客户机请求。
1.消息
IPC中一个消息由消息头和消息正文组成。消息头是一个msg 结构体。其定义如下:
- 消息队列的结构
struct msg
{
struct msg *msg_next; /*指向下一个消息*/
long msg_type; /*消息类型:大于0,是通信双方约定的消息标志*/
char *msg_spot; /*消息正文地址*/
time_t msg_time; /*消息发送时间*/
short msg_ts; /*消息正文大小,最大长度由MSGMAX决定,缺省为
4057字节*/
}2.消息队列
Linux中可以根据进程的需要建立多个IPC消息队列,消息队列的最大数量由符号常量MSGMNI决定,缺省为128。系统对所有消息队列统一管理。每个消息队列有唯一的标识号。每个消息队列是由消息结构体构成的单向链表。
描述消息队列的数据结构struct msqid_ds,称为消息队列描述符。与消息队列一一对应。其定义如下:
struct msqid_ds
{
Struct ipc_perm msg_perm; /*访问权限*/
Struct msg *msg_first; /*指向消息队列头*/
Struct msg *msg_last; /*指向消息队列尾*/
Time_t msg_stime; /*最近发送消息的时间*/
Time_t msg_rtime; /*最近接收消息的时间*/
Time_t msg_ctime; /*最近修改消息的时间*/
Struct wait_queue *wait; /*等待接收消息的进程等待队列*/
Struct wait_queue *wait; /*等待发送消息的进程等待队列*/
Unshort msg_cbytes; /*队列中当前字节数*/
Unshort msg_qnum; /*队列中消息数*/
Unshort msg_qbytes; /*队列最大字节数,不能超过MSGMN(缺省16384)*/
Unshort msg_lspid; /*最近发送进程的PID*/
Unshort msg_lrpid; /*最近接收进程的PID*/
}说明:IPC消息队列用于多个进程间的数据交换,其中包含多个进程发送来的消息,这些消息又要传递给不同的进程。故发送进程在发送的消息中需要设定一个类型msg_type(详见消息结构体),接收进程在消息队列中按照类型就可以找到对方进程发来的消息。
- 消息队列的生成与控制
1.建立及检索消息队列
在程序中使用msgget()建立一个消息队列或者检索消息队列的标识号。其定义为:
Int msgget(key_t key, int msgflg) /msgflg的值与semget()中的semflg完全相同/
调用成功则返回消息队列的标识号,否则返回-1;
2.消息队列的控制
对消息队列的控制操作由系统调用msgctl()实现,其定义如下:
Int msgctl(int msqid,int cmd,struct msqid_ds *buf)
Msqid:消息队列的标识号。
Cmd:操作类型。
Buf:用于向函数传递数据和从函数的得到的结果数据。
说明:cmd参数的种类与semctl()类似,但制定操作的意义不同。主要有:
MSG_STAT或IPC_STAT:把指定消息队列的描述符内容拷贝到buf指定的msqid_ds结构体中。
IPC_SET:允许修改制定消息队列描述符内容。该操作用于修改消息队列的访问权限,即msg_perm的成员项。超级用户可以修改msg_dbyte的值。变更后,msg_ctime的值自动更新。
IPC_RMID:删除消息队列及其数据结构,该操作只有超级用户或消息队列生成者进行。
MSG_INFO或IPC_INFO:把与消息队列有关的最大值数据输出到msginfo结构体中。在该结构体中记录着IPC消息队列的消息数、字节数和消息的字节最大数。
- 消息的发送与接收
进程使用系统调用msgsnd()向消息队列写消息;接受进程使用系统调用msgrcv()从消息队列读取消息。 - 14 共享内存
共享内存是进程通信中速度最快的一种。该机制的实现与linux的存储管理密切相关。
- 1 共享内存
基本思想:通过允许多个进程访问同一个内存区域实现进程之间的数据传送。进程不能直接访问物理内存空间,所以需要将共享的内存空间映射到通信进程的虚拟地址空间,这个个过程对用户进程透明。(attach 结合, detach脱离)
共享内存实现机制与信号量、消息管理机制一致。每一个共享内存有唯一标识,称为内存标记号,每个区域内存由一个数据结构记录他的管理信息,称为内存描述符shmid_ds结构体,定义如下:
- 1 共享内存
Struct shmid_ds
{
Struct ipc_perm shm_perm; / *访问权限*/
Int shm_segsz; /*共享内存大小(字节)*/
Time_t shm_atime; /*最近一次结合时间*/
Time_t shm_dtime; /*最近一次分离时间*/
Time_t shm_ctime; /*最近一次修改时间*/
Unsigned short shm_cpid; /*创建者pid*/
Unsigned short shm_lpid; /*最后一次对共享内存进行操作的进程的pid*/
Short shm_nattch; /*当前结合进程的数量*/
Unsigned short shm_npages; /*共享内存使用的页面数*/
Unsigned long shm_pages; /*共享内存页表指针*/
Struct vm_area_struct *attaches; /*供结合进程使用的虚拟内存描述符*/
}- 2共享内存的生成与控制
- 1.Shmget()建立或检索共享内存
Shmget(key_t key, int size ,int shmflg);
➢ 此处不对参数进行详细介绍,因为部分与前面介绍内容雷同。
➢ Size:共享内存大小,要说明的是:检索时,size要小于共享内存实际大小。 - 2.Shmctl()控制函数
Shmctl(int shmid,int cmd,struct shmid_ds *buf)
➢ 此处不对参数进行详细介绍,因为部分与前面介绍内容雷同。
➢ Cmd指出的对共享内存的操作种类如下:
IPC_STAT:获取共享内存的管理信息,并将其复制到buf。
IPC_SET:修改共享内存描述符内容。
IPC_RMID:删除共享内存,必须在共享内存与所有进程分离后。
SHM_LOCK:禁止共享内存的页面交换;
SHM_UNLOCK:允许共享内存的页面交换;
- 1.Shmget()建立或检索共享内存
3.共享内存的结合与分离
- 1.与共享内存结合
系统调用shmat()
Int shmat(int shmid,char *shmaddr,int shmflg);
Shmid:共享内存的标识号;
Shmaddr:共享内存在进程虚拟空间的起始地址。若为0,则由系统在进程虚拟空间分配共享内存区域。
Shmflg:操作特性。若为SHM_RDONLY,只能对共享内存进行读取操作;若为0,则可以读写。对内存没有只写操作。 - 2.与共享内存分离
Int shmdt(char *shmaddr)
Shmaddr:进出虚拟空间中共享内存的首地址。执行该函数将释放进程虚拟空间中共享内存占用的区域,并修改shmid_ds中的相关项。
- 1.与共享内存结合
15.IPC对象
通常把Linux中使用的System V IPC 的3种通信机制称为IPC对象(IPC object)。
这三种机制有一定的统一性:
首先:它们有统一的管理方式,每一种机制都有描述符记录管理信息;
其次:有格式统一的操作接口,即系统调用。如生成函数***get()、控制函数***ctl();而且这些函数使用的符号常量也是一致的。
IPC对象的键值
IPC对象的另外一个重要特征:系统使用一个键值和一个标识号来识别每一个IPC对象。键值和标识号都是唯一的,且一一对应。为什么要使用两种识别方法呢?
因为:IPC的标识号是创建者进程运行过程中动态生成的,在其他进程中不可见,这样就无 法使用其IPC对象进行通信;而键值是一个静态的识别码,对所有进程都可见。
生成键值:调用c函数 ftok()。定义:
Key_t ftok(char * pathname, char proj);
Pathname:一个已经存在的路径和文件名;
Proj :任意字符
使用同一个IPC对象进行通信的相关进程可以使用该函数和相同参数的到该对象的键值。(为了使得相关进程能够得到生成键值的参数,一般的做法是把这些参数组织在一个头部文件中,然后将其包括到进程程序的头部文件中。
2.IPC对象的访问权限
为了限制进程对IPC对象的使用,防止出现混乱。IPC对其对象规定了一定的访问权限。结构体 ipc_perm记录着IPC对象的访问权限等静态属性。其定义为:
Struct ipc_perm
{
Key_t key; /*IPC对象键值*/
Unshort uid; /*所有者用户标识*/
Unshort gid; /*所有者组标识*/
Unshort cuid; /*创建者用户标识*/
Unshort cgid; /*创建者组标识*/
Unshort mode; /*访问权限和操作模式*/
Unshort seq /*序列号*/
}进程访问IPC对象时,系统首先要根据该进程的用户标识和组标识,对照访问权限来确定本次访问是否合法。
3.IPC对象的终端命令
在linux中提供了终端上查看和删除IPC对象的命令。常用的有ipcs和ipcrm两条命令。
➢ Ipcs 查看命令
常用格式:ipcs [-asmq]
选择项
-a 显示所有IPC对象信息
-s 显示信号量机制信息
-m 显示共享内存信息
-q 显示消息队列信息
➢ Ipcrm 删除命令
常用格式:Ipcrm[shm|msg|sem] id /id 为IPC对象的标识号/