前端面试总结(2)--从输入URL到页面加载完成,都发生了什么
目录
- 序言
- 从输入URL到页面加载完成,都发生了什么
- 1. 一个极其粗糙且简化的流程
- 2. 每个步骤都只是摘要
- 2.1 浏览器中输入URL
- 2.1.1 URL的概念
- 2.1.2 浏览器对URL的长度限制
- 2.2 浏览器的缓存机制
- 2.3 DNS域名解析
- 2.3.1 基本概念
- 2.3.2 DNS解析过程
- 2.4 TCP连接
- 2.4.1 TCP三次握手与四次挥手
- 2.4.2 TCP与UDP的对比
- 2.4.3 TCP如何保证传输可靠性
- 2.5 浏览器发送HTTP请求
- 2.5.1 HTTP
- 2.5.2 HTTPS
- 2.5.3 HTTP Headers
- 2.5.4 HTTP 请求方法
- 2.5.5 HTTP访问控制(CORS)
- 2.6 浏览器接收HTTP响应并解析
- 2.6.1 HTTP 响应代码
- 2.6.2 HTTP 缓存
- 2.6.3 HTTP cookies
- 2.6.4 Web Storage API
- 2.6.5 数据压缩
- 2.6.6 内容协商
- 2.7 浏览器渲染流程
- 后记
众里寻他千百度。蓦然回首,那人却在,灯火阑珊处。
只因为面试官在人群中多看了你一眼 ,你回首,笑靥如花,那一刻,仿佛三千宠爱寄予你一身,你的生活充满了无限的可能性,你的脑海构建了无数的未来,你有着无限的潜力,不用多久,你就能升职加薪,当上总经理,出任CEO,迎娶白富美,走上人生巅峰。
直到那句“从输入URL到页面加载完成,都发生了什么”传入耳中,你才明白,那日夕阳下的问答,是你逝去的青春。
序言
本文基于面试中经典面试题“从输入URL到页面加载完成,都发生了什么”这个问题整理相关的知识点。
当你读完本文,无论是否赞同,是否收藏转载,是否推荐分享,都挣脱不了一个事实——于你的面试毫无意义。
除非,当你看到下面列出来的每一个知识点时,脑中顿时生出一篇500字小黄作文,言语风轻云淡却掷地有声,逻辑无懈可击时,你便可以与面试官谈笑风生了。那时,当你手中握着100+offers时,别忘了,回来点个赞,顺便谈谈灯火阑珊下,你心中的小作文~
因此,本文目的是汇总这个问题可能遇到的考点,重点在于抛砖引玉。
P.S. 博主•真•呕心沥血整理,各位靓仔靓妹觉得有用的话点个赞再收藏呗~
从输入URL到页面加载完成,都发生了什么
一个经典、复杂、没有标准答案而又直击程序猿/媛灵魂深处的考题,网上答案一箩筐,类似回答看了一百遍,内心仿佛有了一百种表达,总觉得遇到这个问题必然会对答如流,结果往往是,话到嘴边不知如何出口,一出口便被怼得满地找牙。
经典总是有其经典的道理的。这个问题即要考广度,又要考深度,可谓面试题中的老流氓,你了解http协议,他问你DNS解析都做了什么,你和他谈tcp的三次握手,他问你跨域请求都有哪些解决方案。总之,这道题总是可以让面试官处立于不败之地。
本文同样给不出标准答案。在本文,这个问题讨论的重点,不在于问题的答案,而在于如何思考问题,以及给出问题背后可能存在的考点。
首先,给出一个总体的流程。
1. 一个极其粗糙且简化的流程
这个回答来自stackoverflow 中的一个问题:what happens when you type in a URL in browser的最高赞回答,大意是这样的:
Assume the simplest possible HTTP request (no HTTPS, no HTTP2, no extras), simplest possible DNS, no proxies, single-stack IPv4, one HTTP request only, a simple HTTP server on the other end, and no problems in any step. This is, for most contemporary intents and purposes, an unrealistic scenario; all of these are far more complex in actual use, and the tech stack has become an order of magnitude more complicated since this was written. With this in mind, the following timeline is still somewhat valid:
假设最简单的HTTP请求(没有HTTPS,没有HTTP2,没有其他功能),最简单的DNS,没有代理,单堆栈IPv4,仅一个HTTP请求,另一端同样是一个简单的HTTP服务器,而且整个流程中每个步骤都不出错。
对于绝大多数现代浏览器实际的工作流程,这是一种过于简单且不现实的场景。尽管如此,基于上述假设,以下步骤仍然在一定程度上是有效的:
- browser checks cache; if requested object is in cache and is fresh, skip to #9 --> 浏览器检查缓存,如果请求的对象在缓存中并且没有过期,跳至步骤9
- browser asks OS for server’s IP address --> 浏览器要求操作系统(OS)提供服务器的IP地址
- OS makes a DNS lookup and replies the IP address to the browser --> 操作系统(OS)进行DNS查找并返回IP地址给浏览器
- browser opens a TCP connection to server (this step is much more complex with HTTPS) --> 浏览器与服务器建立TCP连接(如果使用https协议,这一步会更复杂)
- browser sends the HTTP request through TCP connection --> 浏览器通过TCP连接发送HTTP请求
- browser receives HTTP response and may close the TCP connection, or reuse it for another request --> 浏览器接收HTTP响应,之后可能关闭TCP连接,也可能将其重新用于其他请求
- browser checks if the response is a redirect or a conditional response (3xx result status codes), authorization request (401), error (4xx and 5xx), etc.; these are handled differently from normal responses (2xx) --> 浏览器检查响应是重定向响应还是条件响应(3xx为重定向意义的一类状态码),授权请求(401),错误(4xx和5xx)等; 浏览器对这些情况处理方式与正常响应方式不同(2xx)。
- if cacheable, response is stored in cache --> 如果响应是可缓存的,则将响应存储在缓存中
- browser decodes response (e.g. if it’s gzipped) --> 浏览器对响应进行解析(例如,是否压缩)
- browser determines what to do with response (e.g. is it a HTML page, is it an image, is it a sound clip?) --> 浏览器确定如何处理响应(例如,响应是HTML页面,图像还是音频片段?)
- browser renders response, or offers a download dialog for unrecognized types --> 如果浏览器可以识别响应的类型,就会渲染响应;如果无法识别响应的类型,则提供下载对话框。
简单来说,基于一切流程最简化且正常工作的情况,从输入URL到页面加载完成,浏览器做了上述步骤的工作。换句话说,上述步骤,是这个考点最简单的完整回答。如果你连这个最简单的流程都讲不清楚,恐怕你只能用微笑来缓解你与面试官面面相觑的尴尬了。
2. 每个步骤都只是摘要
在你终于流畅地讲完了上述流程,千万别沾沾自喜,这只是敲门砖,接下来才是残酷的沙场,迎接你的将是面试官大量的虎狼之词严谨问题。
为了能够应付面试官千变万化的提问,最有效的办法只有一个,掌握所有问题的答案。这听起来很不现实,没错,如果你能回答所有问题,那坐在面试官位置的人应该就是你了。但是,如果你比别人多答对一个问题的话。。。这么想想是不是还有点小激动呢~
面试官的问题,无非就是对你掌握的知识点的考察。面对面试官的提问,你首先需要从自己的知识体系中定位知识点。如果找不到,就说明这是知识点盲点。
何为知识体系呢?知识体系通常呈现为金字塔结构,以这个问题为例:“从输入URL到页面加载完成,都发生了什么”这个主题,就是金字塔的塔尖;而塔尖下一层次,就是前一节提到的步骤,塔尖的主题和下一层次的步骤呈纵向关系。在金字塔结构中,位于某组思想上一层次的思想是对这一组思想的概括,这一组思想则是对其上一层次思想的解释和支持。
到目前为止,本文只讨论到了第二层次,而面试官会对第二层次中每个步骤都可以提出各种问题,换句话说,你需要基于现有的两层架构,继续深入,建立第三层,第四层,甚至第五层结构来完善自己的知识体系。这样,面对考官对整个知识体系的考察,你才能从容不迫地应对。
本文接下来主要对这个知识体系的第三层进行总结归纳,可能适当延伸,尽可能覆盖主要考点。
2.1 浏览器中输入URL
这是整个问题的第一个点,下面会列出主要的考点。
2.1.1 URL的概念
-
定义:Uniform Resource Locator,统一资源定位符,是一种特殊类型的URI(Uniform Resource Identifiers),是浏览器用来检索web上公布的任何资源的机制。URL无非就是一个给定的独特资源在Web上的地址。理论上说,每个有效的URL都指向一个独特的资源。这个资源可以是一个HTML页面,一个CSS文档,一幅图像,等等。
-
URL的组成,包括了协议,域名,端口,路径等。详细内容参见: 什么是URL
-
同源策略与跨域问题,基于URL的组成,这个问题是对URL问题的延伸,属于更深层次的问题。此处不做展开,会在新开一篇blog给出自己的理解。
-
Get和Post有什么区别
-
直观区别
- 定义上,get是从指定的资源请求数据,而post是向指定的资源提交要被处理的资源
- get请求的数据放在url后,以?分隔url和传输的数据,参数之间以&符号连接,post把提交的数据放在http的body中
- get提交的数据大小有限,通常受到浏览器url长度的限制,不同浏览器的限制不同;post提交的数据量没有限制。
- get通常只能传递ASCII字符,而post没有限制。
-
深层次的讨论:讨论两者的区别,实际上就是在理解,在哪些情况下,应该去用get请求,哪些情况下应该用post请求
- 从http协议定义来说,get和post区别在于语义上,get是请求数据,post是提交数据,对于怎样携带数据,将数据放在url后还是http请求的body中,协议中并没有相关的规定。换句话说,如果不考虑具体的实现,get和post在定义上只有语义区别。
- 光有定义是不行的,我们在实际使用中,需要实现get和post请求,那么问题就归结为,该怎样使用get和post,应该取决于实际中怎样实现的get和post。根据RFC规范,get的语义上是请求资源,post语义上是处理资源,具体实现两种方法时,必须考虑其语义,做出符合语义的行为。在理论上,get应该是安全、幂等、可缓存的,而post不安全、不幂等、大部分情况下不可缓存。所谓安全,是指请求不会引起服务器资源的变化,因此是无害的;幂等是指多次请求和一次请求的结果完全相同。但是,规范定义的并不代表具体的实现,所谓的实现,通常是指浏览器根据RFC规范对方法的实现。
- 对于具体的实现,通常是指,浏览器做了哪些事情来处理get和post请求。例如,通常情况下,get请求的数据可以再 url中可见,而post请求的数据不会显示在url中;get和post请求的数据量大小不一致,数据编码类型的不一致;get后退、刷新时无影响,而post数据会被重新提交(浏览器会提醒)等。浏览器在实现请求方法时提出了一些规范要求,这些要求最终体现在实际的get、post请求时所表现出来的不一致。
- 浏览器的实现,是为了更好的让get和post按照其语义来实现功能。在我们讨论完get和post的这些区别后,问题变成了,我们该怎样来选择使用get请求和post请求?在实际中,不遵循语义去实现请求也是可行的,例如get修改数据,post获取资源列表。我们可以在get和post请求时使用完全相同的语法,我们可以将get的数据放在http的body中,也可以在post的url中发送数据,尽管这些方式在浏览器中可能会受到限制,但实现了功能,语法上的正确并不代表语义的正确。我们应该遵循对get、post请求方法的规范,去设计我们的请求,这样才能更好地得到浏览器的支持,更好地处理实际的业务,让我们的网站更易于理解。
-
2.1.2 浏览器对URL的长度限制
浏览器对URL的长度限制
- IE浏览器对URL的长度现限制为2048字节。
- 360极速浏览器对URL的长度限制为2118字节。
- Firefox(Browser)对URL的长度限制为65536字节。
- Safari(Browser)对URL的长度限制为80000字节。
- Opera(Browser)对URL的长度限制为190000字节。
- Google(chrome)对URL的长度限制为8182字节。
————————————————
版权声明:本文为CSDN博主「Martin_Yelvin」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36279445/article/details/102854491
2.2 浏览器的缓存机制
又是一个庞大而又深刻的问题,这里给出一篇Blog作为参考:
- 深入理解浏览器的缓存机制
这篇文章字数5k+,很长,但是很系统很全面,而最最重要的一点是:这篇文章中的所有内容都是考点。
换句话说,请深刻理解这篇文章,并用自己的语言将整个机制系统地表述出来。
2.3 DNS域名解析
理解了缓存机制,你距离成功更近了一步。
当浏览器没有在缓存中找到请求的对象时,浏览器就要去存放资源的地方获取请求的对象了。那资源到底存放在什么地方呢?这就涉及到当前的话题,DNS域名解析了。
简单来说,DNS域名解析过程,就是根据输入URL中的域名信息,查询获取域名对应主机IP的过程。
2.3.1 基本概念
-
什么是域名(domain name)
-
IP Address
-
DNS的定义
百度百科
域名系统(Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。DNS使用TCP和UDP端口53。当前,对于每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符。DNS协议是用来将域名转换为IP地址(也可以将IP地址转换为相应的域名地址)。维基百科
The Domain Name System (DNS) is a hierarchical decentralized naming system for computers, services, or other resources connected to the Internet or a private network. It associates various information with domain names assigned to each of the participating entities. Most prominently, it translates more readily memorized domain names to the numerical IP addresses needed for locating and identifying computer services and devices with the underlying network protocols. By providing a worldwide, distributed directory service, the Domain Name System is an essential component of the functionality on the Internet, that has been in use since 1985.
2.3.2 DNS解析过程
这部分只给出简要步骤,记住,每一个步骤都是摘要,细节需要你自己去补充。
什么是DNS?
DNS查找信息通常会在查询计算机内部缓存或在DNS基础结构中远程缓存。DNS查找通常有8个步骤。缓存DNS信息时,将从DNS查找过程中跳过步骤,这样可以更快地完成。下面的示例概述了没有缓存任何内容时的所有8个步骤。
DNS查找中的8个步骤:
- 用户在Web浏览器中键入“example.com”,查询将进入Internet并由DNS递归解析程序接收。
- 解析器然后查询DNS根名称服务器(。)。
- 然后,根服务器使用顶级域(TLD)DNS服务器(例如.com或.net)的地址响应解析器,该服务器存储其域的信息。在搜索example.com时,我们的请求指向.com TLD。
- 解析器然后向.com TLD提出请求。
- 然后,TLD服务器使用域名服务器example.com的IP地址进行响应。
- 最后,递归解析器向域的名称服务器发送查询。
- 然后,example.com的IP地址将从名称服务器返回到解析程序。
- 然后DNS解析器使用最初请求的域的IP地址响应Web浏览器。
————————————————
版权声明:本文为CSDN博主「Mr_Wing5」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jiayu5100687/article/details/81985968
2.4 TCP连接
经过DNS解析,终于拿到了服务器的IP地址。接下来,浏览器首先需要和目标服务器建立连接。
这部分最常见的考点是TCP建立连接的过程(三次握手,四次挥手),TCP与UDP的区别和TCP如何保证可靠性。
2.4.1 TCP三次握手与四次挥手
这里给出一篇讲解TCP三次握手与四次挥手的文章,讲的非常清楚:
- 两张动图-彻底明白TCP的三次握手与四次挥手
除了基本的过程,这篇文章中提到的点也很重要,特意拉出来强调一下:
为什么TCP客户端最后还要发送一次确认呢?
一句话,主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用的是两次握手建立连接,假设有这样一种场景,客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
————————————————
版权声明:本文为CSDN博主「小书go」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qzcsu/article/details/72861891
为什么建立连接是三次握手,关闭连接确是四次挥手呢?
建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
而关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送,从而导致多了一次。
————————————————
版权声明:本文为CSDN博主「小书go」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qzcsu/article/details/72861891
2.4.2 TCP与UDP的对比
同样用一篇blog作为回答,更多地展开就需要靠自己咯。
- TCP 和 UDP 的区别
2.4.3 TCP如何保证传输可靠性
- TCP协议-如何保证传输可靠性
2.5 浏览器发送HTTP请求
当浏览器终于与服务器建立了TCP连接了,浏览器就可以发送HTTP请求了。
TCP与HTTP之间什么关系呢?引用知乎上的一个回答:
打个比方,你有一些想法,你把他们变成文字写在信纸上,这是http
你把这个信纸塞进信封,这个信封是tcp
你把这个信封写上地址交给邮局,这地址是IP引自:TCP/IP 和 HTTP 的区别和联系是什么? - 无胖次不生活的回答 - 知乎
https://www.zhihu.com/question/38648948/answer/239925503
这个比喻非常贴切,可以很好地理解TCP与HTTP之间的关系。
作为前端攻城狮,HTTP是最常被问起的考点。接下来列考点,这里只列出了部分关键点,其中大部分引用内容标题可点击查看细节~
2.5.1 HTTP
定义
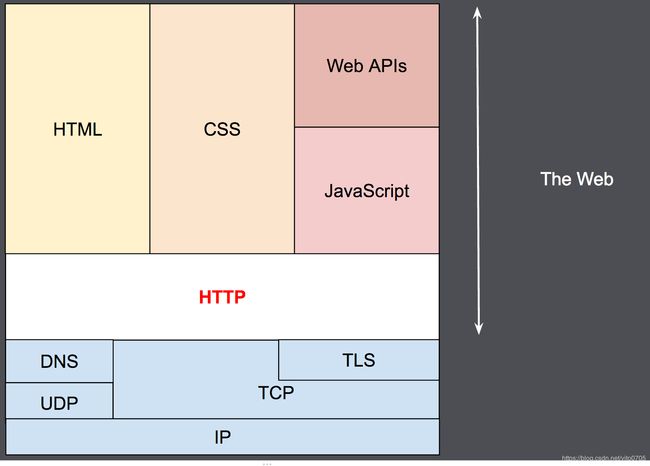
超文本传输协议(HTTP)是一个用于传输超媒体文档(例如 HTML)的应用层协议。它是为 Web 浏览器与 Web 服务器之间的通信而设计的,但也可以用于其他目的。HTTP 遵循经典的客户端-服务端模型,客户端打开一个连接以发出请求,然后等待它收到服务器端响应。HTTP 是无状态协议,这意味着服务器不会在两个请求之间保留任何数据(状态)。该协议虽然通常基于 TCP/IP 层,但可以在任何可靠的传输层上使用;也就是说,不像 UDP,它是一个不会静默丢失消息的协议。RUDP——作为 UDP 的可靠化升级版本——是一种合适的替代选择。
- HTTP概述
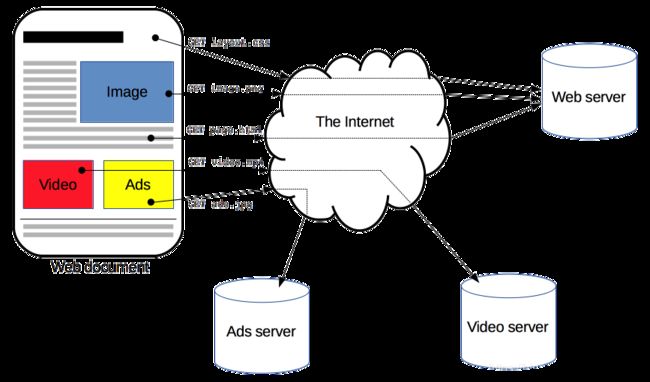
HTTP是一种能够获取如 HTML 这样的网络资源的 protocol(通讯协议)。它是在 Web 上进行数据交换的基础,是一种 client-server 协议,也就是说,请求通常是由像浏览器这样的接受方发起的。一个完整的Web文档通常是由不同的子文档拼接而成的,像是文本、布局描述、图片、视频、脚本等等。
客户端和服务端通过交换各自的消息(与数据流正好相反)进行交互。由像浏览器这样的客户端发出的消息叫做 requests,被服务端响应的消息叫做 responses。
HTTP被设计于20世纪90年代初期,是一种可扩展的协议。它是应用层的协议,通过TCP,或者是TLS-加密的TCP连接来发送,理论上任何可靠的传输协议都可以使用。因为其良好的扩展性,时至今日,它不仅被用来传输超文本文档,还用来传输图片、视频或者向服务器发送如HTML表单这样的信息。HTTP还可以根据网页需求,仅获取部分Web文档内容更新网页。
2.5.2 HTTPS
HTTPS又是一个很复杂的问题,这里不再展开,只列出几个考点。
HTTPS
HTTPS (安全的HTTP)是 HTTP 协议的加密版本。它通常使用 SSL 或者 TLS 来加密客户端和服务器之间所有的通信 。这安全的链接允许客户端与服务器安全地交换敏感的数据,例如网上银行或者在线商城等涉及金钱的操作。
- http与https的区别
- https工作流程
- https的优缺点
2.5.3 HTTP Headers
HTTP Headers
根据不同上下文,可将消息头(Headers)分为:
- General headers: 同时适用于请求和响应消息,但与最终消息主体中传输的数据无关的消息头。
- Request headers: 包含更多有关要获取的资源或客户端本身信息的消息头。
- Response headers: 包含有关响应的补充信息,如其位置或服务器本身(名称和版本等)的消息头。
- Entity headers: 包含有关实体主体的更多信息,比如主体长(Content-Length)度或其MIME类型。
2.5.4 HTTP 请求方法
HTTP 请求方法
HTTP 定义了一组请求方法, 以表明要对给定资源执行的操作。指示针对给定资源要执行的期望动作. 虽然他们也可以是名词, 但这些请求方法有时被称为HTTP动词. 每一个请求方法都实现了不同的语义, 但一些共同的特征由一组共享:: 例如一个请求方法可以是 safe, idempotent, 或 cacheable.
- GET方法请求一个指定资源的表示形式. 使用GET的请求应该只被用于获取数据.
- HEAD方法请求一个与GET请求的响应相同的响应,但没有响应体.
- POST方法用于将实体提交到指定的资源,通常导致在服务器上的状态变化或副作用.
- PUT方法用请求有效载荷替换目标资源的所有当前表示。
- DELETE方法删除指定的资源。
- CONNECT方法建立一个到由目标资源标识的服务器的隧道。
- OPTIONS方法用于描述目标资源的通信选项。
- TRACE方法沿着到目标资源的路径执行一个消息环回测试。
- PATCH方法用于对资源应用部分修改。
2.5.5 HTTP访问控制(CORS)
HTTP访问控制(CORS)
跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain) 上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。
比如,站点 http://domain-a.com 的某 HTML 页面通过的 src 请求 http://domain-b.com/image.jpg。网络上的许多页面都会加载来自不同域的CSS样式表,图像和脚本等资源。
2.6 浏览器接收HTTP响应并解析
目标服务器接收并解析了HTTP请求后,将相应的HTTP响应返回给了浏览器。此时,浏览器会对HTTP响应进行解析。
在HTTP响应中,包含着指示特定 HTTP 请求是否已成功完成的HTTP 响应状态码,浏览器会针对不同的状态码进行不同的操作。结合HTTP响应头,浏览器还会对获取到的资源进行解析和操作(例如解压缩,缓存等)。
2.6.1 HTTP 响应代码
HTTP 响应代码
HTTP 响应状态代码指示特定 HTTP 请求是否已成功完成。响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599)。状态代码由 section 10 of RFC 2616定义
2.6.2 HTTP 缓存
HTTP 缓存
重用已获取的资源能够有效的提升网站与应用的性能。Web 缓存能够减少延迟与网络阻塞,进而减少显示某个资源所用的时间。借助 HTTP 缓存,Web 站点变得更具有响应性。
2.6.3 HTTP cookies
HTTP cookies
HTTP Cookie(也叫Web Cookie或浏览器Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie使基于无状态的HTTP协议记录稳定的状态信息成为了可能。
Cookie主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
Cookie曾一度用于客户端数据的存储,因当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie渐渐被淘汰。由于服务器指定Cookie后,浏览器的每次请求都会携带Cookie数据,会带来额外的性能开销(尤其是在移动环境下)。新的浏览器API已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB 。
2.6.4 Web Storage API
Web Storage API
Web Storage API 提供机制, 使浏览器能以一种比使用Cookie更直观的方式存储键/值对。
Web Storage 包含如下两种机制:
sessionStorage为每一个给定的源(given origin)维持一个独立的存储区域,该存储区域在页面会话期间可用(即只要浏览器处于打开状态,包括页面重新加载和恢复)。localStorage同样的功能,但是在浏览器关闭,然后重新打开后数据仍然存在。这两种机制是通过
Window.sessionStorage和Window.localStorage属性使用(更确切的说,在支持的浏览器中Window对象实现了WindowLocalStorage和WindowSessionStorage对象并挂在其localStorage和sessionStorage属性下)—— 调用其中任一对象会创建Storage对象,通过Storage对象,可以设置、获取和移除数据项。对于每个源(origin)sessionStorage和localStorage使用不同的 Storage 对象——独立运行和控制。
此处补充一个点:
- cookie,localStorage和sessionStorage比较
- 相同点:都将数据保存在浏览器端,且是同源的
- 区别
- 是否与服务器端交互:
- cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器之间相互传递。
- sessionStorage和localStorage不会自动把数据传给服务器,只在本地保存
- 存储大小限制:
- cookie存储的数据不能超过4k(各个浏览器不同,4095-4097之间),由于http请求每次都会携带cookie,会占用带宽,因此cookie适合存储较小的数据,比如会话标识。
- sessionStorage和localStorage大小一般为5M
- 数据有效期不同:
- cookie数据的生命期一般有服务器生成,可设置失效时间。如果不设置失效时间,则关闭浏览器时cookie失效
- sessionStorage为每一个给定的源(given origin)维持一个独立的存储区域,该存储区域在页面会话期间(page session)有效(即只要浏览器打开状态,包括页面重新加载或恢复),页面刷新不会清除数据,浏览器或是页面关闭才会清除数据
- localStorage无过期设置,保存数据后始终有效,浏览器或页面关闭也一直保存,可作为持久数据
- 作用域不同:
- cookie在所有同源窗口中都是共享的
- localStorage在所有同源窗口中也是共享的
- sessionStorage在不同的浏览器窗口中是不共享的,即使是同源页面
- 其他:
- cookie数据有路径(path)的概念,可以限制cookie只属于某个路径
- web storage(sessionStorage和localStorage)支持事件通知机制,可以将数据更新的通知发送给监听者
- web storage的API更方便
- 是否与服务器端交互:
- 应用场景
- cookie常用的场景是判断用户是否登录
- localStorage 可以用来记录用户的浏览历史
- sessionStorage可以用来统计页面上元素的点击次数
- 安全性
- 敏感数据不适宜放在浏览器存储中,可以被随意修改
- cookie的安全性比较复杂,需要单独讨论
2.6.5 数据压缩
HTTP协议中的数据压缩
数据压缩是提高 Web 站点性能的一种重要手段。对于有些文件来说,高达70%的压缩比率可以大大减低对于带宽的需求。随着时间的推移,压缩算法的效率也越来越高,同时也有新的压缩算法被发明出来,应用在客户端与服务器端。
2.6.6 内容协商
内容协商
在 HTTP 协议中,内容协商是这样一种机制,通过为同一 URI 指向的资源提供不同的展现形式,可以使用户代理选择与用户需求相适应的最佳匹配(例如,文档使用的自然语言,图片的格式,或者内容编码形式)。
一份特定的文件称为一项资源。当客户端获取资源的时候,会使用其对应的 URL 发送请求。服务器通过这个 URL 来选择它指向的资源的某一变体——每一个变体称为一种展现形式——然后将这个选定的展现形式返回给客户端。整个资源,连同它的各种展现形式,共享一个特定的 URL 。当一项资源被访问的时候,特定展现形式的选取是通过内容协商机制来决定的,并且客户端和服务器端之间存在多种协商方式。

2.7 浏览器渲染流程
如何浏览器解析得到的响应内容是HTML文档,浏览器将其解析渲染呈现给用户。仍然用一篇优秀的blog来回答这个非常重要的考点:
- 前端必会!四步带你吃透浏览器渲染基本原理
讲的很清楚也很全面,不看你真的会后悔的。
后记
终于整理完了,太累了。。。
我尽可能完整地整理了“从输入URL到页面加载完成,都发生了什么”这个问题的三层金字塔知识结构,也引用了很多优秀且理解深刻的博文,但终归而言,这些东西都是别人的东西。如果你不能用自己的话正确且完整地表述这些问题,你仍然无法真正理解这些知识。面对久经沙场的老司机面试官,一知半解的知识只会得到无情的毒打,当然如果你是抖M,就当我没有说过这句话。
谢谢各位看官的阅读~