Bi-LSTM原理及TensorFlow实现序列标注
本文整理了Bi-LSTM的原理,并在静觅博客静觅:TensorFlow Bi-LSTM实现序列标注 的基础上对TensorFlow 搭建一个Bi-LSTM来处理序列标注问题的代码进行了详细的注释。
Bi-LSTM理解
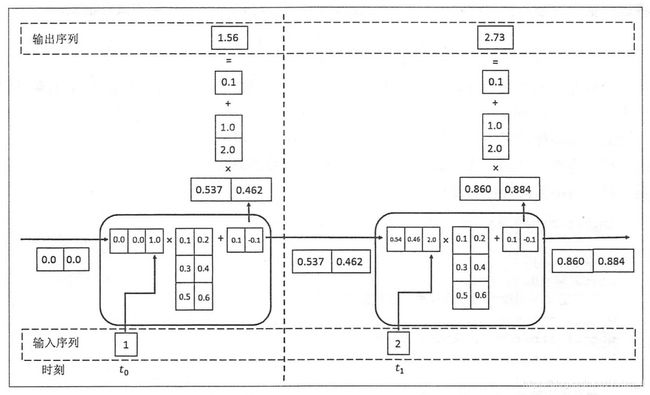
RNN的意思是,为了预测最后的结果,我先用第一个词预测,当然,只用第一个预测的预测结果肯定不精确,我把这个结果作为特征,跟第二词一起,来预测结果;接着,我用这个新的预测结果结合第三词,来作新的预测;然后重复这个过程;直到最后一个词。这样,如果输入有n个词,那么我们事实上对结果作了n次预测,给出了n个预测序列。整个过程中,模型共享一组参数。因此,RNN降低了模型的参数数目,防止了过拟合,同时,它生来就是为处理序列问题而设计的,因此,特别适合处理序列问题。RNN循环神经网络原理见下图:
我们知道 RNN 是可以学习到文本上下文之间的联系的,输入是上文,输出是下文,但这样的结果是模型可以根据上文推出下文,而如果输入下文,想要推出上文就没有那么简单了,为了弥补这个缺陷,我们可以让模型从两个方向来学习,这就构成了双向 RNN。在某些任务中,双向 RNN 的表现比单向 RNN 要好,本文要实现的文本分词就是其中之一。不过本文使用的模型不是简单的双向 RNN,而是 RNN 的变种 — LSTM。
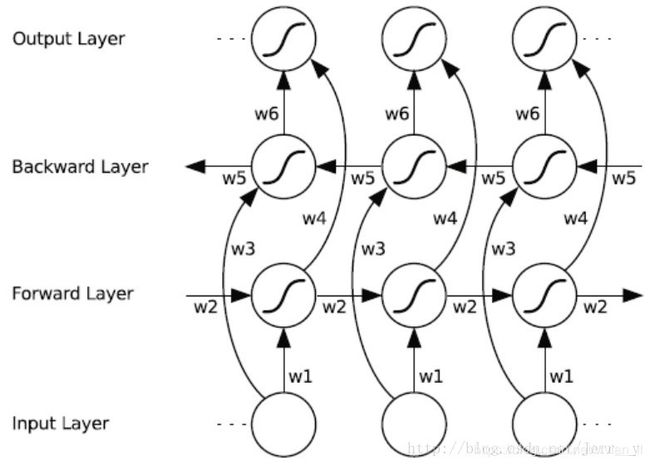
如图所示为 Bi-LSTM 的基本原理,输入层的数据会经过向前和向后两个方向推算,最后输出的隐含状态再进行 concat,再作为下一层的输入,原理其实和 LSTM 是类似的,就是多了双向计算和 concat 过程。
多层LSTM同理,示意图如下:
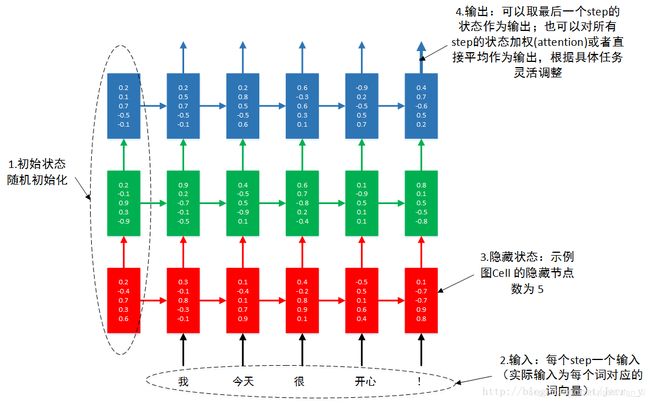
更简单直观的图如下:
单层BiLSTM

多层BiLSTM
数据处理
本文的训练和测试数据使用的是已经做好序列标注的中文文本数据。序列标注,就是给一个汉语句子作为输入,以“BEMS”组成的序列串作为输出,然后再进行切词,进而得到输入句子的划分。其中,B 代表该字是词语中的起始字,M 代表是词语中的中间字,E 代表是词语中的结束字,S 则代表是单字成词。
这里的原始数据样例如下:
人/b 们/e 常/s 说/s 生/b 活/e 是/s 一/s 部/s 教/b 科/m 书/e
这里一个字对应一个标注,我们首先需要对数据进行预处理,预处理的流程如下:
- 将句子切分
- 将句子的的标点符号去掉
- 将每个字及对应的标注切分
- 去掉长度为 0 的无效句子
首先我们将句子切分开来并去掉标点符号,代码实现如下:
# Read origin data
text = open('data/testdata.txt', encoding='utf-8').read() # txt文件的保存格式应为utf-8,开头字符\ufeff不用管
# Get split sentences
sentences = re.split('[,。!?、‘’“”]/[bems]', text) # 去掉标点符号,如?/s的形式,斜杠前面是标点,后面是标注
# Filter sentences whose length is 0
sentences = list(filter(lambda x: x.strip(), sentences)) # strip删除开头结尾空白字符,filter过滤序列,返回True的元素放入新列表python3中filter返回的并不是一个list,而是一个filter对象
# Strip sentences
sentences = list(map(lambda x: x.strip(), sentences)) # map() 会根据提供的函数对指定序列做映射
这样我们就可以将句子切分开来并做好了清洗,接下来我们还需要把每个句子中的字及标注转为 Numpy 数组,便于下一步制作词表和数据集,代码实现如下:
import re
# To numpy array
words, labels = [], []
print('Start creating words and labels...')
for sentence in sentences:
groups = re.findall('(.)/(.)', sentence) # list 中包含若干个2个元素的tuple,返回[('人', 'b'), ('们', 'e'), ('常', 's'),....]这种形式
arrays = np.asarray(groups) # asarray可以将元组,列表,元组列表,列表元组转化成ndarray对象,若每个元组的size不一样,所以只是一维array,否则二维
words.append(arrays[:, 0])
labels.append(arrays[:, 1])
print('Words Length', len(words), 'Labels Length', len(labels))
print('Words Example', words[0])
print('Labels Example', labels[0])
这里我们利用正则 re 库的 findall() 方法将字及标注分开,并分别添加到 words 和 labels 数组中,运行效果如下:
Words Length 321533 Labels Length 321533
Words Example ['人' '们' '常' '说' '生' '活' '是' '一' '部' '教' '科' '书']
Labels Example ['b' 'e' 's' 's' 'b' 'e' 's' 's' 's' 'b' 'm' 'e']
接下来我们有了这些数据就要开始制作词表了,词表制作起来无非就是输入词表和输出词表的不重复的正逆对应,制作词表的目的就是将输入的文字或标注转为 index,同时还能反向根据 index 获取对应的文字或标注,所以我们这里需要制作 word2id、id2word、tag2id、id2tag 四个字典。
为了解决 OOV 问题,我们还需要将无效字符也进行标注,这里我们统一取 0。制作时我们借助于 pandas 库的 Series 进行了去重和转换,另外还限制了每一句的最大长度,这里设置为 32,如果大于32,则截断,否则进行 padding,代码如下:
from itertools import chain
import pandas as pd
import numpy as np
# Merge all words
all_words = list(chain(*words)) # words为二维数组,通过chain和*,将words拆成一维数组
# All words to Series
all_words_sr = pd.Series(all_words) # 序列化 类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。
# Get value count, index changed to set
all_words_counts = all_words_sr.value_counts() # 计算字频
# Get words set
all_words_set = all_words_counts.index # index为字,values为字的频数,降序
# Get words ids
all_words_ids = range(1, len(all_words_set) + 1) # 字典,从1开始
# Dict to transform
word2id = pd.Series(all_words_ids, index=all_words_set) # 按字频降序建立所有字的索引,字-id
id2word = pd.Series(all_words_set, index=all_words_ids) # id-字
# Tag set and ids
tags_set = ['x', 's', 'b', 'm', 'e'] # 为解决OOV(Out of Vocabulary)问题,对无效字符标注取零
tags_ids = range(len(tags_set))
# Dict to transform
tag2id = pd.Series(tags_ids, index=tags_set)
id2tag = pd.Series(tags_set, index=tag2id) # 0-x,1-s,2-b,3-m,4-e
max_length = 32 # 句子最大长度
def x_transform(words):
# print(words)
ids = list(word2id[words])
# print(ids)
if len(ids) >= max_length:
ids = ids[:max_length]
ids.extend([0] * (max_length - len(ids)))
return ids
def y_transform(tags):
# print(tags)
ids = list(tag2id[tags])
# print(ids)
if len(ids) >= max_length:
ids = ids[:max_length]
ids.extend([0] * (max_length - len(ids)))
return ids
print('Starting transform...')
# print(words)
data_x = list(map(lambda x: x_transform(x), words)) # 字对应的id的序列,words为二维array,多个seq时map并行处理
data_y = list(map(lambda y: y_transform(y), labels)) # 字对应的标注的id的序列,二维列表
print('Data X Length', len(data_x), 'Data Y Length', len(data_y))
print('Data X Example', data_x[0])
print('Data Y Example', data_y[0])
data_x = np.asarray(data_x)
data_y = np.asarray(data_y)
这样我们就完成了 word2id、id2word、tag2id、id2tag 四个字典的制作,并制作好了 Numpy 数组类型的 data_x 和 data_y,这里 data_x 和 data_y 单句示例如下:
Data X Example: [8, 43, 320, 88, 36, 198, 7, 2, 41, 163, 124, 245, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Data Y Example: [2, 4, 1, 1, 2, 4, 1, 1, 1, 2, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
可以看到数据的 x 部分,原始文字和标注结果都转化成了词表中的 index,同时不够 32 个字符就以 0 补全。
接下来我们将其保存成 pickle 文件,以备训练和测试使用:
print('Starting pickle to file...')
with open(join(path, 'testdata.pkl'), 'wb') as f:
pickle.dump(data_x, f) # 序列化对象并追加
pickle.dump(data_y, f)
pickle.dump(word2id, f)
pickle.dump(id2word, f)
pickle.dump(tag2id, f)
pickle.dump(id2tag, f)
print('Pickle finished')
好,现在数据预处理部分就完成了。
构造模型
接下来我们就需要利用 pickle 文件中的数据来构建模型了,首先进行 pickle 文件的读取,然后将数据分为训练集、开发集、测试集,详细流程不再赘述,赋值为如下变量:
# Load data
data_x, data_y, word2id, id2word, tag2id, id2tag = load_data()
# Split data
train_x, train_y, dev_x, dev_y, test_x, test_y = get_data(data_x, data_y)
接下来我们使用 TensorFlow 自带的 Dataset 数据结构构造输入输出,利用 Dataset 我们可以构造一个 iterator 迭代器,每调用一次 get_next() 方法,我们就可以得到一个 batch,这里 Dataset 的初始化我们使用 from_tensor_slices() 方法,然后调用其 batch() 方法来初始化每个数据集的 batch_size,接着初始化同一个 iterator,并绑定到三个数据集上声明为三个 initializer,这样每调用 initializer,就会将 iterator 切换到对应的数据集上,代码实现如下:
# Train and dev dataset
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)) # 函数接受一个数组并返回表示该数组切片的 tf.data.Dataset(即把array的第一维切开)
train_dataset = train_dataset.batch(FLAGS.train_batch_size)
dev_dataset = tf.data.Dataset.from_tensor_slices((dev_x, dev_y))
dev_dataset = dev_dataset.batch(FLAGS.dev_batch_size)
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y))
test_dataset = test_dataset.batch(FLAGS.test_batch_size) # 获取批量样本
# A reinitializable iterator
iterator = tf.data.Iterator.from_structure(train_dataset.output_types, train_dataset.output_shapes) # Iterator从不同的Dataset对象中读取数值,可重新初始化,通过from_structure()统一规格
train_initializer = iterator.make_initializer(train_dataset) # 初始化
dev_initializer = iterator.make_initializer(dev_dataset)
test_initializer = iterator.make_initializer(test_dataset)
有了 Dataset 的 iterator,我们只需要调用一次 get_next() 方法即可得到 x 和 y_label 了,就不需要使用 placeholder 来声明了,代码如下:
# Input Layer
with tf.variable_scope('inputs'): # 打开一个已经存在的作用域,与创建/调用变量函数tf.Variable() 和tf.get_variable()搭配使用。
x, y_label = iterator.get_next()
接下来我们需要实现 embedding 层,调用 TensorFlow 的 embedding_lookup 即可实现,这里没有使用 Pre Train 的 embedding,代码实现如下:
# Embedding Layer
with tf.variable_scope('embedding'):
embedding = tf.Variable(tf.random_normal([vocab_size, FLAGS.embedding_size]), dtype=tf.float32)
inputs = tf.nn.embedding_lookup(embedding, x) # 根据input_ids中的id,寻找embeddings中的第id行。比如input_ids=[1,3,5],则找出embeddings中第1,3,5行,组成一个tensor返回
接下来我们就需要实现双向 LSTM 了,这里我们要构造一个 2 层的 Bi-LSTM 网络,实现的时候我们首先需要声明 LSTM Cell 的列表,然后调用 stack_bidirectional_rnn() 方法即可:
cell_fw = [lstm_cell(FLAGS.num_units, keep_prob) for _ in range(FLAGS.num_layer)]
cell_bw = [lstm_cell(FLAGS.num_units, keep_prob) for _ in range(FLAGS.num_layer)]
inputs = tf.unstack(inputs, FLAGS.time_step, axis=1) # 矩阵分解,time_step即序列本身的长度,即句子最大长度max_length=32
output, _, _ = tf.contrib.rnn.stack_bidirectional_rnn(cell_fw, cell_bw, inputs=inputs, dtype=tf.float32) # 创建一个双向循环神经网络。堆叠2个双向rnn层
这个方法内部是首先对每一层的 LSTM 进行正反向计算,然后对输出隐层进行 concat,然后输入下一层再进行计算,这里值得注意的地方是,我们不能把 LSTM Cell 提前组合成 MultiRNNCell 再调用 bidirectional_dynamic_rnn() 进行计算,这样相当于只有最后一层才进行 concat,是错误的。
现在我们得到的 output 就是 Bi-LSTM 的最后输出结果了。
接下来我们需要对输出结果进行一下 stack() 操作转化为一个 Tensor,然后将其 reshape() 一下,转化为 [-1, num_units * 2] 的 shape:
output = tf.stack(output, axis=1)
output = tf.reshape(output, [-1, FLAGS.num_units * 2])
这样我们再经过一层全连接网络将维度进行转换:
# Output Layer 全连接
with tf.variable_scope('outputs'):
w = weight([FLAGS.num_units * 2, FLAGS.category_num])
b = bias([FLAGS.category_num])
y = tf.matmul(output, w) + b # 矩阵相乘
y_predict = tf.cast(tf.argmax(y, axis=1), tf.int32) # cast张量数据类型转换,argmax针对传入函数的axis参数,去选取array中相对应轴元素值大的索引
print('Output Y', y_predict)
这样得到的最后的 y_predict 即为预测结果,shape 为 [batch_size],即每一句都得到了一个最可能的结果标注。
接下来我们需要计算一下准确率和 Loss,准确率其实就是比较 y_predict 和 y_label 的相似度,Loss 即为二者交叉熵:
# Reshape y_label
y_label_reshape = tf.cast(tf.reshape(y_label, [-1]), tf.int32)
# Prediction
correct_prediction = tf.equal(y_predict, y_label_reshape)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# Loss
# logits:就是神经网络最后一层的输出,有batch的话,它的大小就是[batchsize,num_classes];labels:实际的标签。因为sparse_softmax_cross_entropy_with_logits返回一个向量,求loss需做reduce_mean,求交叉熵则求reduce_sum
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y_label_reshape, logits=tf.cast(y, tf.float32)))
# Train
train = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(cross_entropy, global_step=global_step)
这里计算交叉熵使用的是 sparse_softmax_cross_entropy_with_logits() 方法,Optimizer 使用的是 Adam。
最后指定训练过程和测试过程即可,训练过程如下:
for epoch in range(FLAGS.epoch_num):
tf.train.global_step(sess, global_step_tensor=global_step)
# Train
sess.run(train_initializer)
for step in range(int(train_steps)):
smrs, loss, acc, gstep, _ = sess.run([summaries, cross_entropy, accuracy, global_step, train], feed_dict={keep_prob: FLAGS.keep_prob})
# Print log
if step % FLAGS.steps_per_print == 0:
print('Global Step', gstep, 'Step', step, 'Train Loss', loss, 'Accuracy', acc)
if epoch % FLAGS.epochs_per_dev == 0:
# Dev
sess.run(dev_initializer)
for step in range(int(dev_steps)):
if step % FLAGS.steps_per_print == 0:
print('Dev Accuracy', sess.run(accuracy, feed_dict={keep_prob: 1}), 'Step', step)
这里训练时首先调用了 train_initializer,将 iterator 指向训练数据,这样每调用一次 get_next(),x 和 y_label 就会被赋值为训练数据的一个 batch,接下来打印输出了 Loss,Accuracy 等内容。另外对于开发集来说,每次进行验证的时候也需要重新调用 dev_initializer,这样 iterator 会再次指向开发集,这样每调用一次 get_next(),x 和 y_label 就会被赋值为开发集的一个 batch,然后进行验证。
对于测试来说,我们可以计算其准确率,然后将测试的结果输出出来,代码实现如下:
sess.run(test_initializer)
for step in range(int(test_steps)):
x_results, y_predict_results, acc = sess.run([x, y_predict, accuracy], feed_dict={keep_prob: 1})
print('Test step', step, 'Accuracy', acc)
y_predict_results = np.reshape(y_predict_results, x_results.shape)
for i in range(len(x_results)):
x_result, y_predict_result = list(filter(lambda x: x, x_results[i])), list(
filter(lambda x: x, y_predict_results[i]))
x_text, y_predict_text = ''.join(id2word[x_result].values), ''.join(id2tag[y_predict_result].values)
print(x_text, y_predict_text)
这里打印输出了当前测试的准确率,然后得到了测试结果,然后再结合词表将测试的真正结果打印出来即可。
运行结果
在训练过程中,我们需要构建模型图,然后调用训练部分的代码进行训练,输出结果类似如下:
Global Step 0 Step 0 Train Loss 1.67181 Accuracy 0.1475
Global Step 100 Step 100 Train Loss 0.210423 Accuracy 0.928125
Global Step 200 Step 200 Train Loss 0.208561 Accuracy 0.920625
Global Step 300 Step 300 Train Loss 0.185281 Accuracy 0.939375
Global Step 400 Step 400 Train Loss 0.186069 Accuracy 0.938125
Global Step 500 Step 500 Train Loss 0.165667 Accuracy 0.94375
Global Step 600 Step 600 Train Loss 0.201692 Accuracy 0.9275
Global Step 700 Step 700 Train Loss 0.13299 Accuracy 0.954375
...
随着训练的进行,准确率可以达到 96% 左右。
在测试阶段,输出了当前模型的准确率及真实测试输出结果,输出结果类似如下:
Test step 0 Accuracy 0.946125
据新华社北京7月9日电连日来 sbmebebmmesbes
董新辉为自己此生不能侍奉母亲而难过 bmesbebebebmmesbe
...
可见测试准确率在 95% 左右,对于测试数据,此处还输出了每句话的序列标注结果,如第一行结果中,“据”字对应的标注就是 s,代表单字成词,“新”字对应的标注是 b,代表词的起始,“华”字对应标注是 m,代表词的中间,“社”字对应的标注是 e,代表结束,这样 “据”、“新华社” 就可以被分成两个词了,可见还是有一定效果的。
遇到问题
ImportError: numpy.core.multiarray failed to import
出现这个错误的原因是numpy的版本太低了。
查询numpy版本号方法为在python的IDE里输入:
import numpy
print numpy.version.version
使用:
pip install -U numpy
就可以更新numpy版本了。
2.
AttributeError: ‘NoneType’ object has no attribute ‘model_checkpoint_path’
第一次运行时需要先训练,parser.add_argument('--train', help='train', default=True, type=bool),这里train应设为True。
3.
tf.gfile.DeleteRecursively(FLAGS.summaries_dir)报错 Directory not empty
不知道为什么,只好注释掉下面两句:
if tf.gfile.Exists(FLAGS.summaries_dir):
tf.gfile.DeleteRecursively(FLAGS.summaries_dir)
W tensorflow/core/framework/op_kernel.cc:1401] OP_REQUIRES failed at save_restore_v2_ops.cc:137 : Failed precondition: Failed to rename: ckpt/model.ckpt-425.data-00000-of-00001.tempstate7180034828233266701 to: ckpt/model.ckpt-425.data-00000-of-00001 : ��һ����������ʹ�ô��ļ������������ʡ�
; Broken pipe
不知道为什么,只好继续注释掉:
# writer = tf.summary.FileWriter(join(FLAGS.summaries_dir, 'train'),sess.graph) # 创建一个FileWrite的类对象,并将计算图写入文件
和
# writer.add_summary(smrs, gstep)
和
# # Save model
# if epoch % FLAGS.epochs_per_save == 0:
# saver.save(sess, FLAGS.checkpoint_dir, global_step=gstep)
结语
本节通过搭建一个 Bi-LSTM 网络实现了序列标注,并可实现分词,准确率可达到 95% 左右,但是最主要的还是学习 Bi-LSTM 的用法,本实例代码较多,部分代码已经省略,静觅的完整代码见:https://github.com/AIDeepLearning/BiLSTMWordBreaker。
注释版的完整代码见:https://github.com/vivianLL/BiLSTM
参考网址:
【Tensorflow】Dataset 中的 Iterator
如何使用TensorFlow中的Dataset API
Embedding原理和Tensorflow-tf.nn.embedding_lookup()
终于理解了RNN里面的time_step
[tensorflow] tf.nn.sparse_softmax_cross_entropy_with_logits的使用方法及常见报错
【TensorFlow】关于tf.nn.sparse_softmax_cross_entropy_with_logits()
【TensorFlow】tf.nn.softmax_cross_entropy_with_logits的用法
TensorFlow入门(五)多层 LSTM 通俗易懂版
TensorFlow入门(六) 双端 LSTM 实现序列标注(分词)