JVM-垃圾回收概述
垃圾判定
引用计数
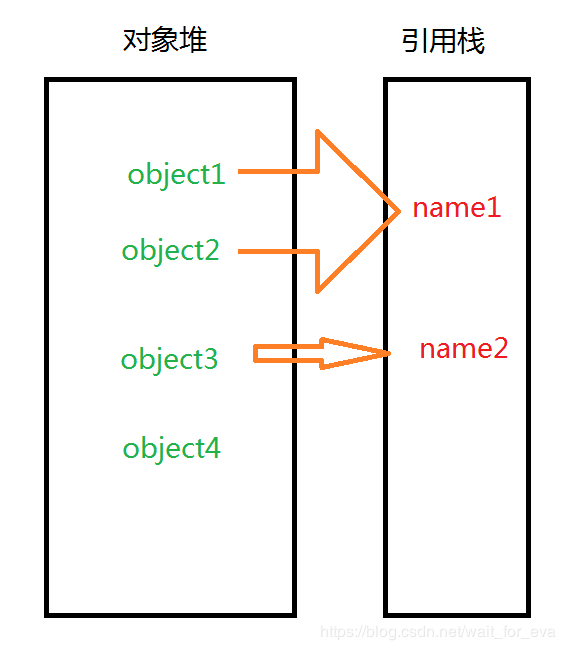
差不多就是这个样子,把被引用的次数记下来,当引用为0时,就判定是垃圾。
不过存在一个问题,那就是对象引用对象的时候,这个办法就失效了。
class Node{
Node prev;
Node next;
int value;
}
public static void main(String []args){
Node head = new Node();
Node tail = new Node();
head.next = tail;
tail.prev = head;
head = null;
tail = null;
}
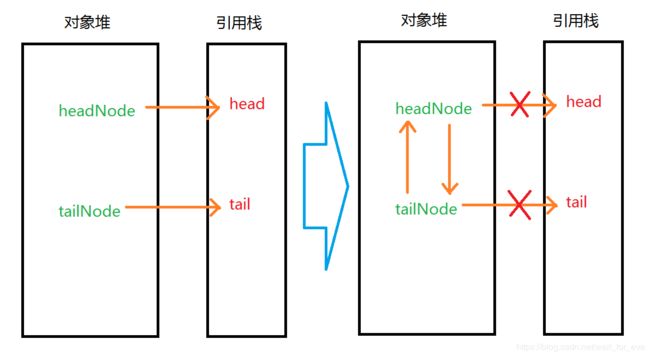
嗯,直白的看出来,这两个都是垃圾了,但是使用这种办法并不能判别这种情况的垃圾。
甚至不能够识别自引用
可达性分析
核心思想:引用源头gcRoot必须是有效引用,而不是对象。
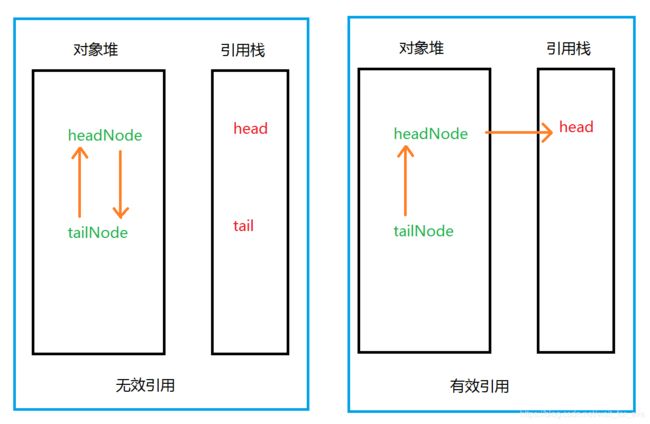
这样就避免了对象自引用的蒙蔽视听。
就像我们所说的伴生,或者说链表,我们只需要能够索引到head,双向链表的话,任意node都可以。
这样哪怕只有一个保持引用,就不会是垃圾,但是不可达的话,就必定是垃圾。
显示垃圾回收信息
-verbose:gc:简单信息-XX:PrintGCDetails:详细信息
回收算法
前一篇说指针碰撞存在一个问题,就是空间不连续。
标记清除

- 红色:使用中
- 橙色:需回收
- 绿色:可分配
就是这样,分别对对象打上标记,然后分别对特征对象进行垃圾回收。
不过这里存在两个问题:
- 空间问题:对象占用空间大小不一,大量零散空间不能存储单一大对象,指针碰撞时讨论过。
- 效率问题:出现上述问题后反复触发垃圾回收,恶性循环
复制算法

多个空间,把存活的对象转移到另一个区域当中,然后全部清理当前区域。
这样一来,就只是对象复制的问题,不存在单个对象清理,同事变相的实现了空间压缩。
不存在空间固定大小的问题。
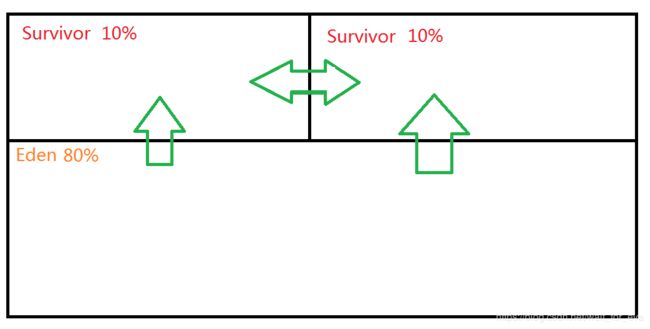
JVM是这样划分的,首先对象创建都在伊甸园Eden,然后垃圾回收一步步复制到Survivor中。
这就是JVM的新生代,同样的,还有老年代。
Eden回收时,就会把存活对象复制到Surivor,但是使用时只使用一个。
Survivor中也会进行垃圾回收,向另一个Surviro中进行复制,重复一定次数后,就迁移至老年代。
| param | example | description |
|---|---|---|
-XX:NewRation |
4 |
新生代:老年代( 1:?) |
-XX:SurvivorRatio |
8 |
survivor*2:Eden(2:?) |
复制算法的确很好,但不得不说存在一个很大的弊端,那就是
空间不复用。不断的递进,但是不可能存在无限的内存。
标记整理

垃圾收集总需要识别,标记是必不可少的。
和标记清除对比:整理过后再清除,空间连续
和复制算法对比:复用空间,但是操作麻烦
复制转整理
- 复制算法需要更多的空间,但是节省时间。
- 标记整理节省了空间,但是要花费更多时间。
单方向来说,复制算法没有终点,似乎更偏向于标记整理。
但是可以如果回环的复制,就能得到标记整理的效果。
两个
Survivor相互复制,就能够得到整理后的连续空间,就是如此。
分代收集
梳理一下
- 标记清除:垃圾回收总要先标记后清除,但是简单的标记清除无用
- 复制算法:快速,但是空间消耗
- 标记整理:空间复用且连续,但是耗时
考核一下对象的状态
- 新对象:大部分存活时间短,回收需求大
- 老对象:大部分存活时间长,回收需求小
于是分代收集算法出现了
| 分代 | 算法 |
|---|---|
| 新生代 | 复制算法 |
| 老年代 | 标记整理 |
通过复制算法,快速的回收新生代对象,并转移到老年代。
使用标记整理,应对回收率低的老年代,并为复制算法的空间开销做个终结。
分代收集,就是划分层次,然后特定处理。
垃圾收集器
Serial
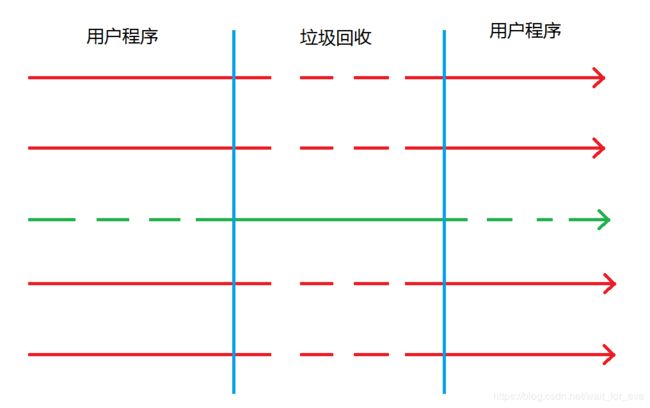
-
红色:用户线程
-
绿色:垃圾回收
-
虚线:挂起
-
实线:运行
Serial是单线程的垃圾回收器,使用单个线程完成垃圾回收操作。
在垃圾回收期间,其他的用户线程会被挂起,垃圾回收和用户线程是互斥状态,不能够并行运行。
采用的算法为复制算法,属于新生代收集器。
parnew

和Serial不同:垃圾回收采用多线程完成工作
相同点:
- 都是复制算法,属于新生代收集器
- 用户线程和垃圾回收线程互斥
parallel
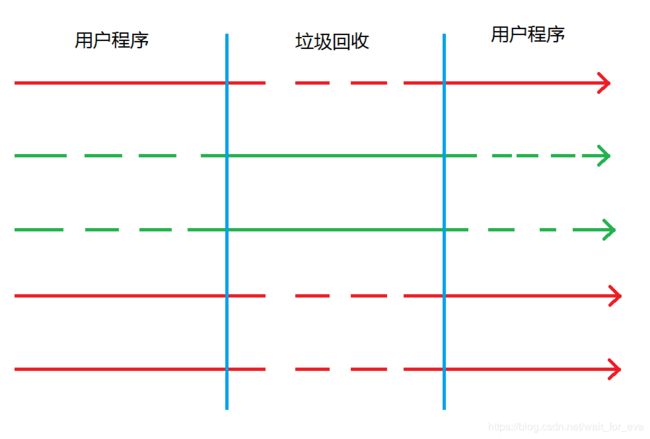
parallel和parnew大体相同,关键增加了垃圾回收时吞吐量的控制。
吞吐量 = 用户代码执行时间 / (用户代码执行事件 + 垃圾回收执行时间)因为垃圾回收和用户时间互斥,所以总时间就是两者之和。
| params | description |
|---|---|
-XX:MaxGCPauseMillis |
垃圾回收停顿时间 |
-XX:GCTimeRatio |
吞吐量大小 ( 0 , 100 ) (0, 100) (0,100) |
默认吞吐量是最大的99(%),也就是说用户代码执行时间:垃圾回收占用事件 = 99 : 1。
同时,还可以调节垃圾回收的停顿时间,不过这里有一个误区:并不是停顿时间越小越好
步子小,相同的路程同样的时间,就只能提高频率了。
所以过小的停顿时间,势必频繁的触发垃圾回收,说不上就是好东西,但是算得上精准。
过大的停顿时间,不仅降低用户体验,如果没那么多垃圾,也只是浪费资源。
cms
并发与并行
并发:同时在做多件事,来回切换
并行:同时在做多件事,同时执行
就好比有三个跑道,同时跑的话:
并发:一个人跑,在跑道间来回切换,最终跑完三个跑道
并行:三个人跑,每个人负责一个跑道,最终跑完三个跑道
电脑同时运行多个软件程序,是我们并行的错觉,底层仍然是
CPU快速的并发切换。追根究底,是
执行者数量的限制。多核,意味着
多CPU,这才是真正的并行,不过运行时是单CPU并发,还是多CPU并行,并看不到。

工作过程
- 初始标记
- 并发标记
- 重新标记
- 并发清理
图中的直观感受:在某些时刻,垃圾回收和用户代码执行是并发的进行的,而不是独占的阻塞。
相对来说,垃圾回收时的停顿时间是有所下降的,并发的步骤,并不阻塞用户的代码执行,这是它的优点。
对应的,有如下缺点:
- 占用
CPU资源:并行操作抢占CPU - 无法降低吞吐量:垃圾回收中,仍然存在独占现象
- 无法处理浮动垃圾:线程同步生成的新对象,只能等待下次回收
Concurrent Mode Failure:回收时空间独占,新对象需到指定空间进行分配,空间不足会异常- 空间碎片:
Concurrent Mark Sweep,采用标记清除,会造成空间碎片
耗费资源,它是老年代的垃圾回收器,不是新声代的菜。
不过老年代使用它的话,新声代一般配合使用parnew。
G1
分代回收是在原来的基础上,加上了对象的存活时间的特征区分,然后分别采用高效回收方式。
对于G1而言,采用分区来替换了分代。
因为分代有一个明显的瑕疵:分代区域划分明显。
即使是老年代,也有某个时刻需要大量回收的场景,而新对象存活时间长也需要进行反复复制。
这个时候,针对分代年龄进行的特定算法,就不再那么特定了。
G1中对整块内存进行分区,分而治之,并记录每个区域的可回收数量,然后特定的进行垃圾回收。
也就是说,对于相同的区域,跟随时间变化,它可以即是新生代,也可以是老年代。
由新生代变为老年代的过程,并不需要进行移动操作。
步骤:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
在分代中,是通过固定的内存区域进行对象年龄的划分,引出了分代的概念,但是不一定能够很好的判别。
G1中进行多次标记,最终筛选回收,通过回收数量来判定区域的分代年龄,更加精确。
优势:
- 并发:并发操作
- 分代:没有分代区的限定,通过回收数量更精确判定分代年龄
- 整合:对于空间碎片多等区域,采用标记整理,消除空间碎片
- 可预测:由于对每个区间的回收数量有所记录,可以预测操作中的停顿时间
追根究底,在于对分代的准确判定,抛弃固定分区进而更加的精准操作。
加上详细分区,虽然是老年代或者新生代,但针对的不再是大块的区域,小范围管理方便且快速。
小结
- 垃圾判定:
- 引用计数
- 可达性分析
- 回收算法
- 标记清除:最基本,存在空间碎片
- 复制算法:提高速度,消除空间碎片,需更多空间,降低可使用空间
- 标记整理:单一空间复用,消除空间碎片,耗时
- 分代收集:新声代复制,老年代标记整理,各取所长
- 垃圾收集器
Serial:复制算法,单线程parnew:复制算法,多线程parallel:复制算法,多线程,提供吞吐量控制cms:标记清除,并发执行G1:准确分代,取长补短