百度PaddlePaddle + NLP 学习心得+作业分享贴(一)
这次是一次作业贴分享, 提交在百度社区: https://ai.baidu.com/forum/topic/show/957882
通过这次的作业,我的心得和体会总结:
1. PaddleNLP的分词速度优势非常明显, 开启GPU模式可以达到 1GB文本/小时, 是我目前使用过的最快和准确性最高的中文分词技术!
2. PaddleHub的LAC使用方便简单
3. jieba 可以 调用Paddle模式.
4. NLP 技术很有趣.
今后都会多使用Paddle做NLP,很有优势!
具体作业和心得感悟如下:
作业1-1
(1)下载飞桨本地并安装成功,将截图发给班主任:

推荐 conda 创建环境 进行安装,因为paddle 更新较快,不同版本下有些细微的差异.包括生成的model 也可能会有使用上的一些小问题.
建议用ubuntu 环境,对paddle-gpu功能支持的比较完整.
paddle建议安装1.6及以上,对NLP支持完整
需要安装paddlehub
(2)学习使用PaddleNLP下面的LAC模型或Jieba分词
LAC模型地址:https://github.com/PaddlePaddle/models/tree/release/1.6/PaddleNLP/lexical_analysis
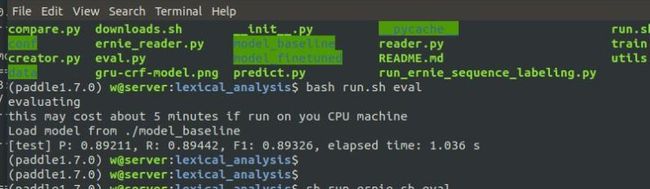
模型评估
我们基于自建的数据集训练了一个词法分析的模型,可以直接用这个模型对测试集 ./data/test.tsv 进行验证,
# baseline model
bash run.sh eval
得到结果:
# ERNIE finetuned model
bash run_ernie.sh eval
得到结果:

模型训练
基于示例的数据集,可通过下面的命令,在训练集 ./data/train.tsv 上进行训练,示例包含程序在单机单卡/多卡,以及CPU多线程的运行设置
Warning: 若需进行ERNIE Finetune训练,需自行下载 ERNIE 开放的模型,下载链接为: https://baidu-nlp.bj.bcebos.com/ERNIE_stable-1.0.1.tar.gz,下载后解压至 ./pretrained/ 目录下。
# baseline model, using single GPU
sh run.sh train_single_gpu
模型预测
加载已有的模型,对未知的数据进行预测
# baseline model
sh run.sh infer
得到结果:

(3)对人民日报语料完成切词,并通过统计每个词出现的概率,计算信息熵
语料地址:https://github.com/fangj/rmrb/tree/master/example/1946%E5%B9%B405%E6%9C%88
下载到本地后,先用paddleNLP的预处理进行分词预处理 :
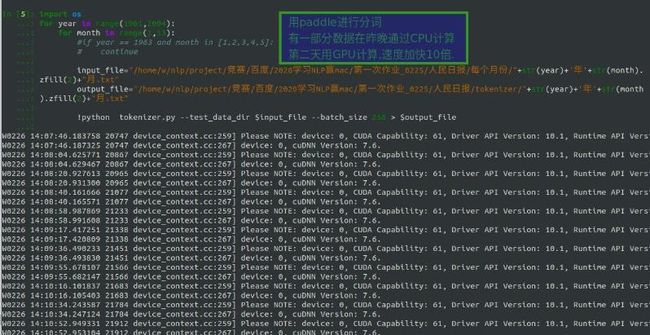
原来CPU 10小时 1GB文本 ,GPU只需要50分钟.完成. paddle在分词速度上优势明显.
分别按月\年\所有 三个时间维度 统计词频:


可以发现每一年的新闻都有一些不同的高频词汇,反映当时的政治面貌
接着计算信息熵:

作业1-2
(1)思考一下,假设输入一个词表里面含有N个词,输入一个长度为M的句子,那么最大前向匹配的计算复杂度是多少?
对于长度为N的词典,长度为M的句子,最坏情况下每个词都需要切分,一般用字典树存储词典,查找一个词的时间复杂度为O(该词的长度),复杂度是O(N*M), 由于词最大的长度是整个句子的长度,所以计算复杂度是O(M^2)
(2)给定一个句子,如何计算里面有多少种分词候选,你能给出代码实现吗?
paddle的分词只支持精确模式,这里用jieba做初步处理.
匹配算法直接引用网友"纠缠state "的实现

(3)除了最大前向匹配和N-gram算法,你还知道其他分词算法吗,请给出一段小描述。
比如:
1.逆向最大匹配算法RMM:该算法是正向最大匹配的逆向思维,匹配不成功,将匹配字段的最前一个字去掉,实验表明,逆向最大匹配算法要优于正向最大匹配算法。
2. 双向最大匹配法:是将正向最大匹配法得到的分词结果和逆向最大匹配法的到的结果进行比较,从而决定正确的分词方法。
本次完成的作业清单:
2月25日第一次作业
作业奖励: 3月2日中午12点之前完成,会从中挑选10位回答优秀的同学获得飞桨定制数据线+本
作业1-1
(1)下载飞桨本地并安装成功,将截图发给班主任
(2)学习使用PaddleNLP下面的LAC模型或Jieba分词
LAC模型地址:https://github.com/PaddlePaddle/models/tree/release/1.6/PaddleNLP/lexical_analysis
Jieba模型:https://github.com/fxsjy/jieba
(3)对人民日报语料完成切词,并通过统计每个词出现的概率,计算信息熵
语料地址:https://github.com/fangj/rmrb/tree/master/example/1946%E5%B9%B405%E6%9C%88
作业1-2
(1)思考一下,假设输入一个词表里面含有N个词,输入一个长度为M的句子,那么最大前向匹配的计算复杂度是多少?
(2)给定一个句子,如何计算里面有多少种分词候选,你能给出代码实现吗?
(3)除了最大前向匹配和N-gram算法,你还知道其他分词算法吗,请给出一段小描述。