Scrapy 爬取拉勾网数据
又到了一年一度的招聘热季节,大量的工作机会在想我们招手,为了了解一下热门岗位的薪资情况,这里爬取拉钩网的Java招聘岗位,,这里使用Scrapy来完成。并保存为xlsx文件。这里不做条件筛选,只对关键词进行筛选。这节作为准备,只讲拉钩的爬取规则,以及如何反爬。
工具:浏览器,Postman,IDE,Python环境,Win10。
Python:Scrapy,Openpyxl,Json
首先访问一下拉钩搜索“java”关键字:
拿到url后,复制粘贴到Postman中访问一遍:
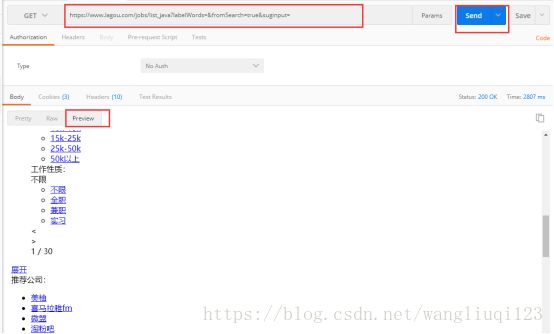
跟我们想的一样。数据都是异步刷新出来的。所以我们要找异步请求的地址,打开浏览器F2 控制台。切到Network 下,清空之前的网络请求后,点击第二页(查看浏览器发送的请求):
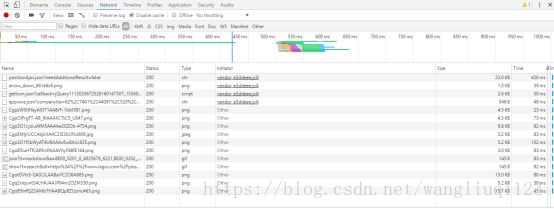
出现了许多请求。其中包括图片等等。我们需要过滤一下。点击XHR:

我们过滤出来两条请求(分别打开查看一下):

经过肉眼筛选。我们发现第一条里面才是包含的真实招聘信息的json串。接下来我们点击Hearder复制请求的地址,使用PostMan访问一下看看:
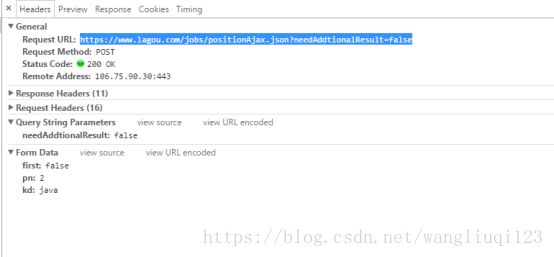
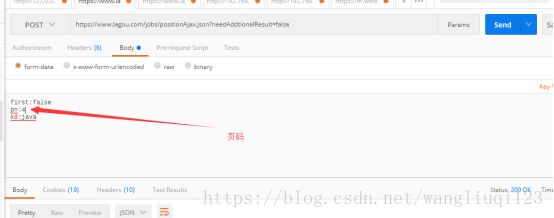
我们可以看到需要post请求地址,并且传入三个参数:
参数的含义:大概也能看出来,pn是页码,kd 是搜索关键字:keyword。First没看出来,多访问几个页面发现也是False。所以我们直接写死。
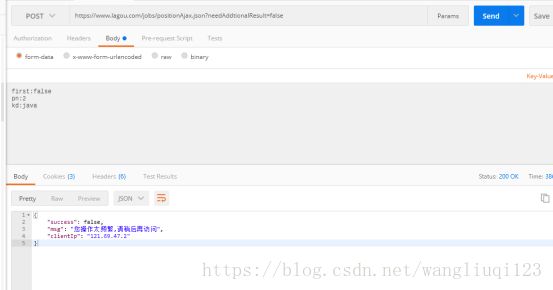
Postman访问,发现有反扒机制。所以,我们需要加请求头。把之前浏览器中的请求头全部复制下来粘贴到postman中:

这里需要注意:打开postman中的interceptor。不然postman不会使用自定义的伪造头。
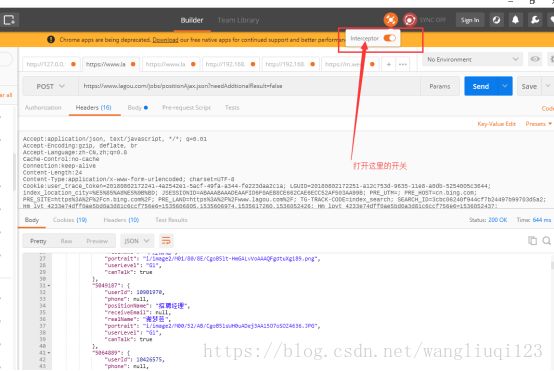
这样我们就获取到了第二页所有的数据:
但是这里还是有个问题。我们修改post参数中的页码发现每次获取的json都是一样的,我们对获取到的json 进行检查发现,这些json并不是我们要的java相关岗位的数据,全是造的假数据。拉钩的程序员小哥哥真狡猾。
这里为什么会出现这样呢。是因为我们的请求头太丰富了。我们需要删除一部分。只保留必须的。经过测试。我保留了:
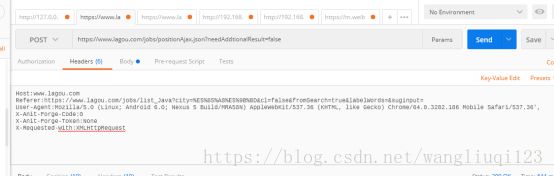
Host:www.lagou.com
Referer:https://www.lagou.com/jobs/list_Java?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Mobile Safari/537.36',
X-Anit-Forge-Code:0
X-Anit-Forge-Token:None
X-Requested-With:XMLHttpRequest
保留了几个hearder头。这些就够用了。
这次我们才发现获取到了真实的数据。
之后只需要修改页码便可获取到不同页的数据。