Deeplearning4j 实战 (21):Bert简介及NLP问题应用
Eclipse Deeplearning4j GitChat课程:https://gitbook.cn/gitchat/column/5bfb6741ae0e5f436e35cd9f
Eclipse Deeplearning4j 系列博客:https://blog.csdn.net/wangongxi
Eclipse Deeplearning4j Github:https://github.com/eclipse/deeplearning4j
版权声明:本文为CSDN博主「wangongxi」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangongxi/article/details/106228218
在上一篇博客中,我们介绍了attention机制的基本原理以及如何基于Deeplearning4j中内置的attention layer对文本之类的序列数据进行建模的过程。这篇博客在上一篇的基础上,介绍下2019年Google的研究成果,同样也是和attention机制有关的Bert模型。在Google的论文中介绍,Bert模型在GLUE数据集上都达到的当时的历史最佳。当然后续改进的一些工作也逐步的在指标上超越了Bert,其中就有国内百度公司的工作ERNIE,但Bert构建NLP语言模型的方式方法还是非常值得去学习和研究,包括后续精简参数后的ALBert。这次的文章主要会分为4个部分,在第一部分中结合Bert的论文介绍其基本原理,第二部分中我们尝试将预训练好的Bert模型通过Deeplearning4j中的SameDiff工具导入到DL4j中并打印一些网络结构信息。在第二部分的基础上,也就是基于导入到DL4j中的Bert模型,我们尝试通过迁移学习的方式进行文本分类和序列标注任务的建模。最后我们对全文做下小结。
Bert简介
Bert模型的论文题目叫做《BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding》。从题目中可以很直接的看出,Bert其实是基于Transformer的一种网络结构。Transformer结构本身也就是基于self-attention,最早实在论文《Attention Is All You Need》中提出的,分为Encoder和Decoder两个部分,我们看下论文中的结构图。

Bert中用到的是transformer中的encoder部分,因此我们重点看下编码这块的网络结构。输入端和一般的网络结构类似,是Embedding向量化的结果以及加上了位置信息的Embedding信息。接着就利用到了上一篇博客中提到的多头自注意力机制(Multi-Head Attention)。接着,经过一个简单的position-wise的全连接网络与LayerNorm,也就同网络层的归一化就可以得到encoder部分的输出。需要注意的是,对于整个encoder的部分,输入和输出的格式是[BN,SeqLen,EmbedDim]。Transformer是第一个不依赖于RNN或者CNN结构,完全由Attention结构和普通全连接神经网络构成的。这也是为什么论文的题目叫做attention is all you need的原因。另外,为了弥补attention机制相比于RNN网络在时间维度的欠缺,transformer在输入端将位置信息向量化以后叠加到原始输入上作为共同输入信息进入到模型结构中。计算方式如下:

值得一提的是,transformer中也使用到了残差机制。从encoder部分可以看到,embedding的联合输入有一个箭头直接指向了Add&Norm,并没有经过自注意力机制,这样的设计其实借鉴了机器视觉中残差网络设计的思路,毕竟原始信息也非常重要,而且便于加深网络测层次,优化梯度弥散的问题。以上就是transformer结构中encoder部分的大概情况,我们回到Bert模型。
Bert模型是通过堆叠transformer结构来实现,主要是堆叠transformer的encoder部分。根据原论文中的描述,官方预训练的模型有堆叠12和24个transformer单元两个版本。通过一层一层的编码器,Bert模型可以获取到每个token的分布式表达,这个结果可以用来作为语言模型用于后期的文本建模等相关工作。预训练模型构建过程中,Bert采用了两个任务联合训练来获取句子以及token的语义信息,它们分别是Masked LM和Next Sentence Prediction (NSP)。对于Masked LM来说,在建模的时候会随机掩盖句子中的一些词,然后通过上下文来预测这个词。而对于NSP问题来说,在输出端将上下文两句话同时作为输入喂到模型中,结果做一个二分类就可以了。当然对于中文来说,有词和字mask两种方案,Google官方提供的中文版本是基于字的,而哈工大开源的是基于整词的,有兴趣的同学可以自己Google一下。对于英文来说,也不一定使用整个单词,可以使用粒度更细的Word Piece。下面看下论文中给出的建模示意图。

输入序列通过[CLS]和[SEP]两个特殊字符作为开始和句子的间隔(如果是单句,就是句子结尾)。Token Embedding很好理解,就是词向量,Segment Embedding是一个只含有0,1两个元素的序列,用于表示第一句和第二句。Position Embedding就是之前提到的,可以通过余弦变换得到的位置向量信息。将其累和后作为输入喂到transformer模型中。

以上就是官方给出的中文版本的预训练的Bert模型。

这是哈工大做整词mask的改进版Bert的github开源项目。
在第一部分的最后,我们尝试通过tensorbard看一下预训练好的Bert模型的结构。我们先看下导入到tensorboard后展示的结构。

从tensorboard可视化工具上面展示的预训练模型结构中,bert有三个输入placeholder。而bert这个大的模块其中就包含了transformer结构。
Bert模型导入SameDiff
我们首先从官网上下载中文的预训练模型。下面截图是解压缩后的预训练。

然后通过以下脚本导出pb格式的模型。
import tensorflow as tf
from tensorflow.python.tools import freeze_graph
from tensorflow.tools.graph_transforms import TransformGraph
from tensorflow.summary import FileWriter
import argparse
def load_graph(checkpoint_path, mb, seq_len):
init_all_op = tf.initialize_all_variables()
graph2 = tf.Graph()
with graph2.as_default():
with tf.Session(graph=graph2) as sess:
saver = tf.train.import_meta_graph(checkpoint_path + '.meta')
saver.restore(sess, checkpoint_path)
print("Restored structure...")
saver.restore(sess, checkpoint_path)
print("Restored params...")
graph_def = graph2.as_graph_def()
FileWriter("__tb-ch", graph2)
input_names = ["Placeholder", "Placeholder_1", "Placeholder_2"]
output_names = ["bert/pooler/dense/Tanh"]
transforms = ['strip_unused_nodes(type=int32, shape="' + str(mb) + ',' + str(seq_len) + '")']
graph2 = TransformGraph(graph2.as_graph_def(), inputs=input_names, outputs=output_names, transforms=transforms)
return graph2
parser = argparse.ArgumentParser(description='Freeze BERT model')
parser.add_argument('--minibatch', help='Minibatch size', default=4)
parser.add_argument('--seq_length', help='Sequence length', default=128)
parser.add_argument('--input_dir', help='Input directory for model', default="D:/chinese_L-12_H-768_A-12/chinese_L-12_H-768_A-12/")
parser.add_argument('--ckpt', help='Checkpoint filename in input dir', default="bert_model.ckpt")
args = parser.parse_args()
mb = int(args.minibatch)
seq_len = int(args.seq_length)
print("minibatch: ", mb)
print("seq_length: ", seq_len)
print("input_dir: ", args.input_dir)
print("checkpoint: ", args.ckpt)
dirIn = args.input_dir
dirOut = dirIn + "frozen/"
ckpt = args.ckpt
graph = load_graph(dirIn + ckpt, mb, seq_len)
txtName = "bert_export_mb" + str(mb) + "_len" + str(seq_len) + ".pb.txt"
txtPath = dirOut + txtName
tf.train.write_graph(graph, dirOut, txtName, True)
output_graph = dirOut + "bert_frozen_mb" + str(mb) + "_len" + str(seq_len) + ".pb"
print("Freezing Graph...")
freeze_graph.freeze_graph(
input_graph=txtPath,
input_checkpoint=dirIn+ckpt,
input_saver="",
output_graph=output_graph,
input_binary=False,
output_node_names="bert/pooler/dense/Tanh", #This is log(prob(x))
# output_node_names="loss/Softmax", #This is log(prob(x))
restore_op_name="save/restore_all",
filename_tensor_name="save/Const:0",
clear_devices=True,
initializer_nodes="")
print("Freezing graph complete...")
下面我们将保存好的pb模型文件通过SameDiff导入到DL4j中并打印模型的基本信息。
File f = new File("E:/bert_frozen_ch", "bert_frozen_mb4_len128.pb");
SameDiff sd = TFGraphMapper.importGraph(f);
System.out.println(sd.summary());
这段逻辑比较简单,我们直接看下summary打印出的结果。
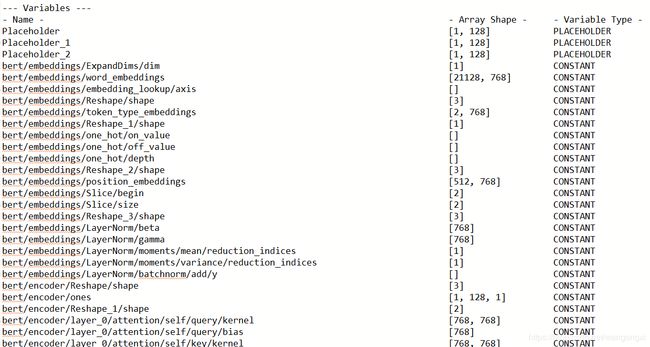

从summary的截图可以比较清楚地看到,encoder共有0~11个transformer单元模块,并在最后一个block做了pooling,这主要方便做后续的迁移学习。需要注意的是,在Bert源码中pooling的操作其实是拿出了第一个token的向量来作为整个序列的语义向量,我们在基于预训练模型做进一步的优化的时候,可以不完全按照这种方式,例如我们可以直接将每个token的序列做线性加和来达到获取整个序列语义的目的。以下Bert是源码中对pooling的解释。

我们截图出一个单独的transformer单元,并对照上文中transformer的结构来看下。

从截图中我们可以看到,红框的部分是自注意力机制的计算部分,蓝框的部分则是add&norm的部分。这和《Attention is all you need》论文中对于transformer的结构描述是一致的。开发人员可以根据和论文中的对照关系对导入的模型结构进行分析。该部分最后我们看下DL4j提供的用于Bert模型的数据迭代器。
Deeplearning4j主要为Bert提供了BertWordPieceTokenizerFactory和BertIterator两个组件。BertWordPieceTokenizerFactory支持加载官方提供的字典数据,主要维护token以及对应索引值的键值对关系。BertIterator主要用于构建Bert预训练任务和迁移监督学习任务的训练数据。对于预训练模型这块,目前只支持Mask LM的任务,暂不支持NSP。我们看下源码实现的注释中给出的例子。

从图中我们可以看到,第一步我们需要加载字典到BertWordPieceTokenizerFactory的实例中,接着我们设置BertIterator对象的参数,包括分词的工具、序列的长度、batch size、单句或者上下文序列预处理工具等等。对于预训练模型的Mask LM任务,以下这几个参数是需要指定的
.task(BertIterator.Task.UNSUPERVISED)
.masker(new BertMaskedLMMasker(new Random(12345), 0.2, 0.5, 0.5))
.unsupervisedLabelFormat(BertIterator.UnsupervisedLabelFormat.RANK2_IDX)
.maskToken("[MASK]")
task用于指定预训练的任务类型,masker参数则是用于确定掩码的token的比例,unsupervisedLabelFormat用于指定预训练模式下的标注的格式,maskToken则是指定掩盖token的特殊标识符。而对于非预训练建模问题的配置上,需要设置以下参数
.featureArrays(BertIterator.FeatureArrays.INDICES_MASK)
.vocabMap(t.getVocab())
.task(BertIterator.Task.SEQ_CLASSIFICATION)
对于非预训练任务,我们需要通过task参数设置任务的类型,示例中是序列分类。下面两个部分将分别使用预训练好的模型进行迁移学习。其中也会涉及内置Bert数据迭代器的使用。
基于Bert预训练模型的文本分类
在上面的部分中,我们介绍了如何将预训练好的中文Bert模型保存成pb格式并通过SameDiff工具导入到DL4j中。我们基于预训练好的模型可以在此基础上做进一步的迁移学习,这个部分我们首先介绍下如何通过添加部分网络结构来实现文本分类的功能。
在已经导入pb模型的基础上,我们添加以下结构
SDVariable labels = sd.placeHolder("label", DataType.FLOAT, 1, 2);
NameScope my_transfer = sd.withNameScope("loss");
SDVariable input = sd.getVariable("bert/pooler/dense/Tanh");
SDVariable my_flatten_weights = sd.var("flatten_weights", new XavierInitScheme('c', 768, 2), DataType.FLOAT, 768, 2);
SDVariable my_flatten_bias = sd.var("flatten_bias", new UniformInitScheme('c', 2),DataType.FLOAT, 2);
SDVariable linear_output = input.mmul(my_flatten_weights).add("linear_output",my_flatten_bias);
SDVariable softmax_output = sd.nn().softmax("softmax", linear_output);
SDVariable loss = sd.loss().logLoss("Loss", labels, softmax_output);
my_transfer.close();
//
sd.setLossVariables(loss);
sd.addListeners(new ScoreListener(1));
这段逻辑的核心在于我们将“bert/pooler/dense/Tanh”变量作为整个预训练模型的输出,其实就是一个768维的向量,然后我们添加一个全连接网络作为整个网络结构的输出。这里涉及到的算子比较简单,通过SameDiff的mmul、add以及softmaxLoss就可以在预训练的Bert模型上搭建起序列分类的模型结构。这里需要提一点,就是我用了NameScope为相关域范围内的算子和变量添加的命名范围,如果不使用也是可以的。通过setLossVariables来定义该网络结构的损失函数。我们同样可以输出模型结构的summary来看下整个迁移后的模型结构。

由于name scope设置的名称是loss,所以添加的网络结构的前缀都会带有loss。其余未截图出来的结构和之前Bert预训练的模型结构是一致的,这里不多描述了。下面介绍下训练数据的准备。由于时间原因,这里没有准备非常翔实的语料数据,但实现逻辑是一致的,我们先来看下
private static MyBertIterator getSupervisedDataIterator(String bertModelPath) throws Exception {
List sentences = new ArrayList() {{add("这个菜很好吃");
add("那个商品质量太差了");
add("差评!太垃圾了!");
add("非常喜欢这个品类");}};
List sentencesR = new ArrayList() {{add("");add("");add("");add("");}};
List label = new ArrayList() {{add("pos");add("neg");add("neg");add("pos");}};
CollectionLabeledPairSentenceProvider labeledPairSentenceProvider = new CollectionLabeledPairSentenceProvider(sentences, sentencesR, label, new Random(123L));
File wordPieceTokens = new File("E:/bert_frozen_ch/vocab.txt");
BertWordPieceTokenizerFactory t = new BertWordPieceTokenizerFactory(wordPieceTokens, true, true, StandardCharsets.UTF_8);
MyBertIterator b = MyBertIterator.builder()
.tokenizer(t)
.lengthHandling(MyBertIterator.LengthHandling.FIXED_LENGTH, 128)
.minibatchSize(1)
.sentenceProvider(null)
.sentencePairProvider(labeledPairSentenceProvider)
.featureArrays(MyBertIterator.FeatureArrays.INDICES_MASK_SEGMENTID)
.vocabMap(t.getVocab())
.task(MyBertIterator.Task.SEQ_CLASSIFICATION)
.prependToken("[CLS]")
.appendToken("[SEP]")
.build();
return b;
}
上面的逻辑中我们一共准备了4段短文本,主要是围绕评论的。在label这个对象中,我们为每段文本添加了一个标注,neg或者pos,也就是负面或者正面。而对于sentencesR这个对象,其实是用于sentence pair的输入的第二句文本,这里我们不需要所以将其置空。labeledPairSentenceProvider对象其实是处理原始语料和label的工具类,直接使用即可。这里有一点需要注意,就是需要从Bert模型的字典文件,也就是wordPieceTokens指向的文件位置,需要通过BertWordPieceTokenizerFactory加载到内存中。字典文件可以直接用文本编辑器打开,里面存储的是一些中文单字和英文。
单字的索引在BertWordPieceTokenizerFactory实例化后会自动维护,这里对用户是透明的。最后就是声明一个BertIterator迭代器了。这里需要注意的是,BertIterator源码中对于sentencePairProvider的reset操作有一个bug,因此我做一些修改,这里直接用我自定义的MyBertIterator,绝大部分功能实现和BertIterator是一样的。我们来看下训练模型的主逻辑。
MyBertIterator datasetIter = getSupervisedDataIterator();
SameDiff sd = getBertModel();
TrainingConfig c = TrainingConfig.builder()
.updater(new Adam(0.01))
.l2(1e-5)
.dataSetFeatureMapping("Placeholder", "Placeholder_1")
.dataSetFeatureMaskMapping("Placeholder_2")
.dataSetLabelMapping("label")
.build();
sd.setTrainingConfig(c);
System.out.println("Start Training...");
long start = System.currentTimeMillis();
for( int i = 0; i < 50; ++i ){
sd.fit(datasetIter, 1);
datasetIter.reset();
}
long end = System.currentTimeMillis();
System.out.println("Total Time Cost: " + (end - start) + "ms");
System.out.println("End Training...");
这段逻辑首先我们构建了训练语料并封装在Bert数据迭代器中,接着获取模型实例,当然这里的模型已经是在预训练模型基础上添加了全连接网络。我们通过TrainingConfig来配置训练的参数,其中包含优化器和学习率、L2正则化项以及整个模型的输入和输出。我们一共训练50个epoch并在每一轮训练完毕后需要reset一下Bert数据迭代器。我们看下控制台的部分输出。

从日志中可以看到每一轮训练后的loss情况,由于语料的数量较少,因此不能反映实际工程的状况,但可以作为开发人员的参考。最后我们对这部分做下简单的小结。
对于基于Bert预训练好的中文模型,我们先通过SameDiff导入到DL4j中,然后在预训练好的pooling层添加一个全连接网络用于分类任务。语料的准备是比较简单的构造了几句正面和负面的评价,然后通过BertIterator解析成可以喂到Bert模型中的数据格式。在构建好训练数据集以及迁移的模型后,我们设置一些训练的参数,包括优化器和学习率等超参数,然后和以往的神经网络一样训练若干个epoch即可完成基于Bert的分类建模任务。下面我们来看下Bert预训练模型如果做NER问题的。
基于Bert预训练模型的实体识别问题
基于Bert预训练模型做NER问题和文本分类有一些区别,我们需要对序列中的每一个token进行打标,而不是对于整个序列进行识别,因此我们其实并不需要预训练中pooling层的结果,我们需要的其实是12层transformer encoder结果的输出,也就是每一个batch中每一个token的768维的encoder结果。我们先给出网络结构的迁移部分的逻辑再做解释。
private static SameDiff getBertModel() throws IOException {
File f = new File("E:/bert_frozen_ch", "bert_frozen_mb4_len128.pb");
SameDiff sd = TFGraphMapper.importGraph(f);
//
SDVariable labels = sd.placeHolder("label", DataType.INT, 1, 128);
NameScope my_transfer = sd.withNameScope("loss");
SDVariable input = sd.getVariable("bert/encoder/layer_11/output/LayerNorm/batchnorm/add_1");
SDVariable my_flatten_weights = sd.var("flatten_weights", new XavierInitScheme('c', 768, 7), DataType.FLOAT, 768, 7);
SDVariable my_flatten_bias = sd.var("flatten_bias", new UniformInitScheme('c', 7),DataType.FLOAT, 7);
SDVariable linear_output = input.mmul(my_flatten_weights).add("linear_output",my_flatten_bias);
SDVariable softmax_output = sd.nn().softmax("softmax", linear_output);
SDVariable loss = sd.loss().sparseSoftmaxCrossEntropy("Loss", softmax_output, labels);
my_transfer.close();
//
sd.setLossVariables(loss);
sd.addListeners(new ScoreListener(1));
//
return sd;
}
首先我们基于SameDiff导入预训练好的模型,这个和上一部分中的逻辑相同。我们重点看下NameScope中的部分逻辑。我们把encoder部分的output部分的输出变量拿出来,然后我们用全连接网络对输出张量做线性变化并得到一个[Batch,SeqLen,LabelCount]的张量。这里的LabelCount是指的包括特殊字符[CLS]和[SEP]都在内的所有标签的数量,由于我们准备做BMSE标签方法做一个分词工具,因此除了预留的label=0之外,剩余的标签数量就是共有6个,总共是7个,这也是我们做全连接网络线性变化的时候用的是768x7的结构的原因。需要注意的是我们这里用的是sparseSoftmaxCrossEntropy作为损失函数,而不是普通的softmax交差熵loss,sparse的loss可用于每个label独立且互斥的情况。同时label数据的格式不再是one-hot的格式,而是一个整数序列。我们给出训练数据准备的逻辑。

private static List getDataIter(String fileName, Map vocab) throws IOException{
List lines = FileUtils.readLines(new File(fileName), Charset.forName("utf-8"));
List datasets = new LinkedList<>();
List idxsLst = new ArrayList<>(128);
List maskLst = new ArrayList<>(128);
List labelLst = new ArrayList<>(128);
//
for( String line : lines ){
String[] tokens = line.split("\t");
idxsLst.add(101);//头部增加[CLS]
labelLst.add(1);//CLS的默认标注
maskLst.add(1);
for( String token : tokens ){
String[] wordAndLabel = token.split("/");
String word = wordAndLabel[0];
String label = wordAndLabel[1];
idxsLst.add(vocab.getOrDefault(word, 100)); //字典中查找每个字的索引,否则默认是UNK.
maskLst.add(1);
labelLst.add(labelMap.get(label));
}
idxsLst.add(102);//尾部增加[SEP]
idxsLst.addAll(Collections.nCopies(128 - idxsLst.size(), 0));
labelLst.add(2);//SEP的默认标注
labelLst.addAll(Collections.nCopies(128 - labelLst.size(), 0));
maskLst.add(1);
maskLst.addAll(Collections.nCopies(128 - maskLst.size(), 0));
//
INDArray idxs = Nd4j.create(idxsLst);
INDArray mask = Nd4j.create(maskLst);
INDArray segmentIdxs = Nd4j.zeros(128);
INDArray labelArr = Nd4j.create(labelLst);
MultiDataSet mds = new org.nd4j.linalg.dataset.MultiDataSet(new INDArray[]{idxs, mask, segmentIdxs}, new INDArray[]{labelArr});
datasets.add(mds);
//
idxsLst.clear();
maskLst.clear();
labelLst.clear();
}
return datasets;
}
截图是语料的标注情况,当然为了验证模型我们也只是准备了非常少量的语料数据。下面的逻辑就是数据预处理的过程。当读取一条记录后,我们以tab来分割字符串并取出token以及token的label,从vocab这个字典对象中获取该token的索引值否则用正整数100来代替,它的物理含义是UNK。需要注意的是,为了兼容Bert模型的训练数据格式,我们在每一个序列的开始需要添加“CLS”这个token,它对应的索引整数是101,同时在每个序列的结尾需要添加“SEP”这个token,它对应的索引整数值是102。至于label的数据方面,我们可以为CLS、SEP以及UNK设定默认的label值,否则就按照语料中给label并给出相关的索引值。除了token序列以及标注序列,我们需要准备一个掩码序列。这个掩码序列的功能主要是标识哪些位置是有效,哪些是无效位置,用0-1二值表示即可。在构建完这三个List之后,我们就可以创建三个张量对象,然后逐个封装在MultiDataSet对象中。下面看下完整的建模过程。
File wordPieceTokens = new File("E:/bert_frozen_ch/vocab.txt");
BertWordPieceTokenizerFactory t = new BertWordPieceTokenizerFactory(wordPieceTokens, true, true, StandardCharsets.UTF_8);
Map vocab = t.getVocab();
List iter = getDataIter("seg.corpus",vocab);
//
SameDiff sd = getBertModel();
TrainingConfig c = TrainingConfig.builder()
.updater(new Adam(0.01))
.l2(1e-5)
.dataSetFeatureMapping("Placeholder", "Placeholder_1","Placeholder_2")
.dataSetLabelMapping("label")
.build();
sd.setTrainingConfig(c);
//
long start = System.currentTimeMillis();
for( int numEpoch = 0; numEpoch < 10; numEpoch++ ){
for( int i = 0; i < iter.size(); ++i ){
sd.fit(iter.get(i));
}
}
该部分逻辑和上一部分文本分类的建模逻辑类似,首先我们需要从磁盘上读取字典文件到内存中。并且结合上面介绍的训练数据准备逻辑,将token序列和label都封装在MultiDataSet的对象中。从getBertModel方法中我们可以按照之前介绍的逻辑获取序列标注的迁移模型结构。然后和之前文本分类的逻辑一致,设置训练的参数以及多轮的训练。最后我们看下控制台的日志。

总结
我们对这篇文章的内容做一下总结。对于Bert模型,我们解释了它内部的transformer结构并介绍了完整Bert预训练模型是如何构建的,包括Mask LM和NSP两个预训练任务。对于中文预训练Bert模型,我们介绍了如何先将其转化为pb模型文件以及如何借助SameDiff导入到DL4j中。此外,在Deeplearning4j中,内置了一些工具类用于支持Bert模型的训练和数据的ETL,我们也给出了对应的使用介绍。我们通过打印summary信息到控制台,可以比较清晰地看到预训练模型的结构,并对照论文进行进一步的理解。接着,在导入预训练模型的基础上,我们为其添加一些网络结构使其支持做文本分类和序列标注的迁移学习。Bert模型其实在迁移学习的过程中起到了提取特征的作用,而我们基于这样的特征提取器可以更好地进行相关的NLP任务。由于时间有限,我们没有准备太过丰富的语料信息,有兴趣的同学可以自行准备并进行验证。
Bert模型本身结构其实没有给出太过原始的创新点,主要是基于transformer的encoder部分搭建整个网络的架构。此外,由于attention机制本身对位置信息的缺失,在输入层将token以及其位置的embedding信息进行线性叠加,这样从理论上可以弥补一些时序信息的缺失。Bert本身更想做一个一个LM,这个语言模型可以迁移到其他的一些NLP任务当中,而不是像传统网络结构一样每次都重新train一个LM。NLP任务确实是AI一个难点,毕竟文字这种符号化的东西是人类自身创造的,意义也是人赋予的,而不像CV的一些问题可以认为是原始信息的一些采集。还是很期待以Bert为代表的新一代NLP解决方案可以进一步推进AI的发展。