Deeplearning4j 实战(8) : Keras为媒介导入Tensorflow/Theano等其他深度学习库的模型
Eclipse Deeplearning4j GitChat课程:https://gitbook.cn/gitchat/column/5bfb6741ae0e5f436e35cd9f
Eclipse Deeplearning4j 系列博客:https://blog.csdn.net/wangongxi
Eclipse Deeplearning4j Github:https://github.com/eclipse/deeplearning4j
在之前的几篇博客中,我直接通过Deeplearning4j进行建模、训练以及评估预测。但在实际使用中,各个团队未必都会将Deeplearning4j作为首选的开源库。这样一来,模型的复用就变得非常困难,无形中增加了重复劳动的成本。虽然我们可以自己开发一套不同库之间模型转换的工具,但是这需要对转换双方的库的实现都要非常清楚,包括正确的解析模型文件及参数,正确建模以及导入参数等等,显然这项工作出错的可能性极大,而且现在主流的几个深度学习库的接口依然在变化,无疑使得这项工作更加繁琐。
其实对于模型复用的问题,Deeplearning4j的团队是给出了解决方案的,即通过Keras来读取类似(Tensorflow、Theano)等开源库的模型,而Deeplearning4j只需正确读取Keras的模型文件就可以了。换句话说,Keras作为Deeplearning4j读取其他开源库训练出来的模型的桥梁和入口。在这里,简单介绍下Keras这个库。Keras可以认为是对Tensorflow和Theano的抽象封装,本身基于Python进行开发。它的明显特点就是搭建网络更为快速和直观,主流的神经网络结构在Keras被模块化,调用方便。后台可以在Tensorflow和Theano之间切换,即把两者作为Keras后台张量计算的框架。目前Keras应该已经到了2.0的版本,接口相比于1.0也有了比较大的变化,和Tensorflow的结合也越发的紧密(链接:http://www.oschina.net/news/81072/google-tensorflow-chooses-keras)。Deeplearning4j支持对Keras 1.x.x版本模型的读取。大致情况就先介绍到这里,下面就Deeplearning4j读取Keras的模型给出具体的例子。
这个例子是用MLP做Mnist数据集的分类,这里为了兼容两个库的数据读取方式,将Mnist数据以图片形式存储而非二进制文件,其中训练数据是42000,测试集是从中随机挑出的1000张图片。
首先我们需要安装Keras的环境,简单起见,我直接安装了Anaconda Python2.7的版本,然后pip install keras==1.2.2安装1.2.2版本的Keras。安装好后,验证一下即可:
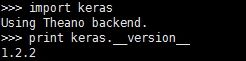
可以看到我们现在用的后台是Theano。
Tensorflow的安装也同样用pip命令,这里我安装的是1.0.0版本的Tensorflow,验证结果如图所示:
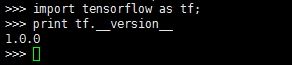
验证好环境后就可以开始利用Keras搭建多层感知机的网络,读取数据并训练。这一部分比较容易理解,我直接贴代码了:
#coding:utf-8
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras.optimizers import SGD
from keras.utils import np_utils, generic_utils
from six.moves import range
from data import load_data,mlp_load_data,mlp_load_test_data
import random,cPickle
from keras.callbacks import EarlyStopping
import numpy as np
np.random.seed(1024)
#加载数据
data, label = mlp_load_data()
test_data, test_label = mlp_load_test_data()
#label为0~9共10个类别,keras要求形式为binary class matrices,转化一下,直接调用keras提供的这个函数
nb_class = 10
label = np_utils.to_categorical(label, nb_class)
#定义多层感知机
def MLP():
model = Sequential()
model.add(Dense(input_dim=784,output_dim=500, init='glorot_uniform'))
model.add(Activation('relu'))
#model.add(Dropout(0.5))
model.add(Dense(input_dim=500,output_dim=500,init='glorot_uniform'))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(input_dim=500,output_dim=10,init='glorot_uniform'))
model.add(Activation('softmax'))
return model
#############
#开始训练模型
##############
model = MLP()
sgd = SGD(lr=0.0001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(data, label, batch_size=128,nb_epoch=10)
classes = model.predict_classes(test_data)
acc = np_utils.accuracy(classes, test_label)
print('Test accuracy:', acc)
##保存模型信息和weight
json_string = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(json_string)
model.save_weights('model_weights.h5')
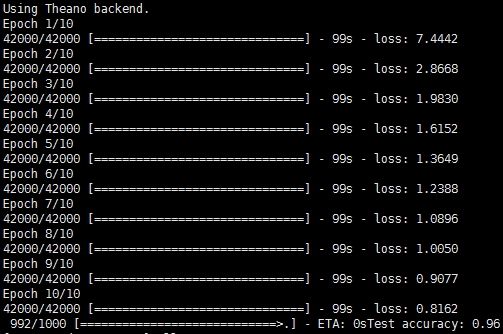
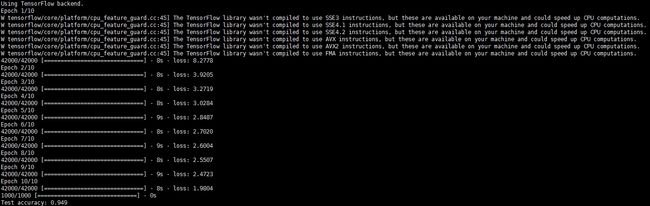
简单解释下这段代码。首先读取目录中的图片数据,包括训练数据和测试数据。然后定义三层的全连接网络结构,选择优化算法SGD以及损失函数,最后开始训练模型。在模型训练完成之后,评估模型的准确率并保存保存模型及参数。在这里,我们重点是要将训练好的模型保存下来,以便之后被Deeplearning4j读取并复用,因此模型的训练过程以及超参数的设置并没有经过精心的设计,跑通即可。下面两张图是分分别基于Theano和Tensorflow的训练过程及评估结果:
Theano作为后端的训练过程以及预测:
Tensorflow作为后端的训练过程以及预测结果:
到此,基于不同后台的模型已经被训练并保存了下来。而要通过Deeplearning4j对模型进行复用则只需要利用已有的接口读取模型及参数文件即可。具体逻辑如下:
System.out.println("Load data....");
List testData = new ArrayList();
final ImageLoader imageLoader = new ImageLoader(28, 28, 1);
File dir = new File("mnist_small");
if( !dir.isDirectory() ){
System.err.println("Not A Directory");
return;
}
File[] pics = dir.listFiles();
System.out.println("Total Test Image: " + pics.length);
for( File pic : pics ){
INDArray features = imageLoader.asRowVector(pic);
String picName = pic.getName();
INDArray labels = Nd4j.zeros(10);
String label = picName.split("\\.")[0];
int intLabel = Integer.parseInt(label);
labels.putScalar(0, intLabel, 1.0);
DataSet test = new DataSet(features, labels);
testData.add(test);
}
//Load Model
MultiLayerNetwork model = KerasModelImport.importKerasSequentialModelAndWeights("keras_model/model.json", "keras_model/model_weights.h5");
Evaluation eval = new Evaluation(10);
for( DataSet ds : testData ){
INDArray output = model.output(ds.getFeatureMatrix(), false);
eval.eval(ds.getLabels(), output);
}
System.out.println(eval.stats());
由于测试的数据集是以图片的形式存储的,所以先写一段读取图片数据的逻辑,然后就是利用KerasModelImport中的static方法读取之前已经保存下来的模型然后再对测试数据集进行分类准确性评估。基于Theano和Tensorflow的模型被Deeplearning4j读取后评估的效果如下:
首先是DL4j-Theano模型的评估:

接下来是DL4j-Tensorflow的模型评估:

对比之前的图片可以看到,Deeplearning4j读取的模型的评估效果和用模型本身预测的准确性几乎是完全一致的。这样,我们就基本完成了利用Theano和Tensorflow作为后台,以Keras作为桥梁对模型进行读取和复用的工作了。
最后做下简单的总结。本文主要是利用Deeplearning提供的导入Keras模型的接口,对基于不同后台训练的Keras模型进行读取和复用,并且给出了读取前后模型的预测准确性评估。可以看出,复用的效果和直接使用模型预测的准确率几乎是一致的。除了Tensorflow和Theano以外,其他的深度学习开源库如Caffe,Torch等等都可以通过类似的方式将模型复用到Deeplearning4j中。不过这会依赖Keras对这些库生成模型的解析工作。目前的Deeplearning4j只支持对Keras1.x.x的模型读取,不过对2.x.x的支持也已经在开发中了。