前言
许久未更,百感交集...因为最近研究各类算法,无边落发萧萧下TAT
废话不多说,最近使用FP-Growth算法继续进行毕设数据挖掘
选择它的原因有二:
1.比kNN算法逼格高
2.比Apriori算法精简高效
FP-Growth算法简介:
算法介绍内容引用自:https://www.cnblogs.com/datahunter/p/3903413.html
关联分析又称关联挖掘,就是在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。关联分析的一个典型例子是购物篮分析。通过发现顾客放入购物篮中不同商品之间的联系,分析顾客的购买习惯。比如,67%的顾客在购买尿布的同时也会购买啤酒。通过了解哪些商品频繁地被顾客同时购买,可以帮助零售商制定营销策略。关联分析也可以应用于其他领域,如生物信息学、医疗诊断、网页挖掘和科学数据分析等。
而在关联分析中,最常用到的就是Apriori算法,也是一个十分经典的算法
和Apriori算法相比,FP-growth算法只需要对数据库进行两次遍历,从而高效发现频繁项集。对于搜索引擎公司而言,他们需要通过查看互联网上的用词来找出经常在一块出现的词对,因此这些公司就需要能够高效的发现频繁项集的方法,FP-growth算法就可以完成此重任。
1.问题定义

图1表示顾客的购物篮数据,其中每一行是每位顾客的购物记录,对应一个事务,而每一列对应一个项。令I={i1, i2, ... , id}是购物篮数据中所有项的集合,而T={t1, t2, ... , tN}是所有事务的集合。每个事务ti包含的项集都是I的子集。在关联分析中,包含0个或多个项的集合被称为项集(itemset)。所谓的关联规则是指形如X→Y的表达式,其中X和Y是不相交的项集。在关联分析中,有两个重要的概念——支持度(support)和置信度(confidence)。支持度确定规则可以用于给定数据集的频繁程度,而置信度确定Y在包含X的事务中出现的频繁程度。支持度(s)和置信度(c)这两种度量的形式定义如下:

其中,N是事务的总数。关联规则的支持度很低,说明该规则只是偶然出现,没有多大意义。另一方面,置信度可以度量通过关联规则进行推理的可靠性。因此,大多数关联分析算法采用的策略是:
(1)频繁项集产生:其目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集。
(2)规则的产生:其目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称作强规则。
2.构建FP-Tree
FP-growth算法通过构建FP-tree来压缩事务数据库中的信息,从而更加有效地产生频繁项集。FP-tree其实是一棵前缀树,按支持度降序排列,支持度越高的频繁项离根节点越近,从而使得更多的频繁项可以共享前缀。

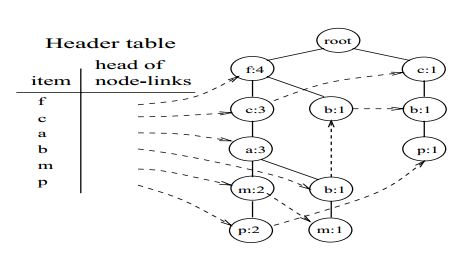
图2表示用于购物篮分析的事务型数据库。其中,a,b,...,p分别表示客户购买的物品。首先,对该事务型数据库进行一次扫描,计算每一行记录中各种物品的支持度,然后按照支持度降序排列,仅保留频繁项集,剔除那些低于支持度阈值的项,这里支持度阈值取3,从而得到<(f:4),(c:4),(a:3),(b:3),(m:3,(p:3)>(由于支持度计算公式中的N是不变的,所以仅需要比较公式中的分子)。图2中的第3列展示了排序后的结果。
FP-tree的根节点为null,不表示任何项。接下来,对事务型数据库进行第二次扫描,从而开始构建FP-tree:
第一条记录
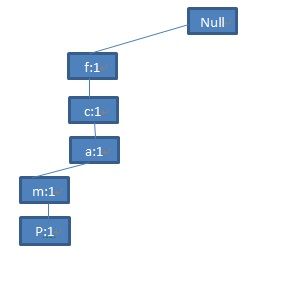
由于第二条记录

第三条记录

第四条记录

类似地,将第五条记录

为了便于对整棵树进行遍历,建立一张项的头表(an item header table)。这张表的第一列是按照降序排列的频繁项。第二列是指向该频繁项在FP-tree中节点位置的指针。FP-tree中每一个节点还有一个指针,用于指向相同名称的节点:
3. 从FP-tree中挖掘频繁模式(Frequent Patterns)
我们从头表的底部开始挖掘FP-tree中的频繁模式。在FP-tree中以p结尾的节点链共有两条,分别是<(f:4),(c:3),(a:3),(m:2),(p:2)>和<(c:1),(b:1),(p:1)>。其中,第一条节点链表表示客户购买的物品清单

从图9可以看到p的条件FP-tree中满足支持度阈值的只剩下一个节点(c:3),所以以p结尾的频繁项集有(p:3),(cp:3)。由于c的条件模式基为空,所以不需要构建c的条件FP-tree。
在FP-tree中以m结尾的节点链共有两条,分别是<(f:4),(c:3),(a:3),(m:2)>和<(f:4),(c:3),(a:3),(b:1),(m:1)>。所以m的条件模式基是<(f:2),(c:2),(a:2)>和<(f:1),(c:1),(a:1),(b:1)>。我们将m的条件模式基作为新的事务数据库,每一行存储m的一个前缀节点链,计算每一行记录中各种物品的支持度,然后按照支持度降序排列,仅保留频繁项集,剔除那些低于支持度阈值的项,建立m的条件FP-tree:
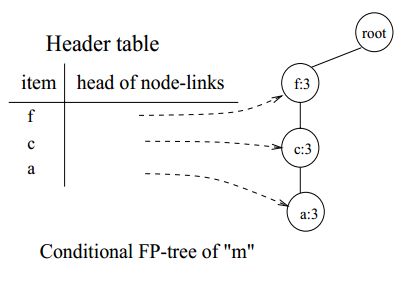
与p不同,m的条件FP-tree中有3个节点,所以需要多次递归地挖掘频繁项集mine(<(f:3),(c:3),(a:3)|(m:3)>)。按照<(a:3),(c:3),(f:3)>的顺序递归调用mine(<(f:3),(c:3)|a,m>),mine(<(f:3)|c,m>),mine(null|f,m)。由于(m:3)满足支持度阈值要求,所以以m结尾的频繁项集有{(m:3)}。

从图11可以看出,节点(a,m)的条件FP-tree有2个节点,需要进一步递归调用mine(<(f:3)|c,a,m>)和mine(

从图12可以看出,节点(c,m)的条件FP-tree只有1个节点,所以只需要递归调用mine(
在FP-tree中以b结尾的节点链共有三条,分别是<(f:4),(c:3),(a:3),(b:1)>,<(f:4),(b:1)>和<(c:1),(b:1)>。由于节点b的条件模式基<(f:1),(c:1),(a:1)>,<(f:1)>和<(c:1)>都不满足支持度阈值,所以不需要再递归。因此,以b结尾的频繁项集只有(b:3)。
同理可得,以a结尾的频繁项集{(fa:3),(ca:3),(fca:3),(a:3)},以c结尾的频繁项集{(fc:3),(c:4)},以f结尾的频繁项集{(f:4)}。
Python2.7实现FP-Growth算法
尝试用原生python写了两天...丑到惨不忍睹
想想还是去GitHub上转了两圈...找到一个第三方的包,还挺好使,就移植到本地了(▽)
FP-Growth第三方包下载地址:https://github.com/enaeseth/python-fp-growth
install the module by running python setup.py install from within the extracted package directory.
操作说明:
from fp_growth import find_frequent_itemsets
for itemset in find_frequent_itemsets(transactions, minsup):
print itemset
其中transactions是一个可迭代的列表变量
一个小栗子:
本地有个test1.csv文件
长这样:
a,b
b,c,d
a,c,d,e
a,d,e
a,b,c
a,b,c,d
a
a,b,c
a,b,d
b,c,e
# -*- coding: UTF-8 -*-
__author__ = 'SuZibo'
"""
FP_Growth包测试
"""
import csv
from fp_growth import find_frequent_itemsets
csv_reader =csv.reader(open('./data/test1.csv'))
transactions = [line for line in csv_reader]
# print transcations
minsup = 3
#最小置信度
for itemset in find_frequent_itemsets(transactions,minsup):
print itemset
#itemset即为满足最小置信度的数组
Python2.7 FP-Growth实战
讲到这里,不得不与我最近做的毕业设计挂一下钩了~
毕设原始数据有巨大数量的mac地址(按照时间序列)
数据集长这样:(规整后的)
2017-08-29 07:12:00,13,84742ab11871
2017-08-29 07:12:00,18,84742aac34f3
2017-08-29 07:13:00,12,742344af2efd,acc1eef136c1
2017-08-29 07:13:00,13,84742ab11871
2017-08-29 07:13:00,18,000000000000,84742aac34f3
2017-08-29 07:14:00,12,a4717460508e,742344af2efd,acc1eef136c1
2017-08-29 07:14:00,13,84742ab11871
2017-08-29 07:14:00,18,84742aac34f3,000000000000
2017-08-29 07:15:00,12,a4717460508e,742344af2efd,a8c83abd75f6,acc1eef136c1
2017-08-29 07:15:00,13,84742ab11871
2017-08-29 07:15:00,18,000000000000,84742aac34f3
2017-08-29 07:16:00,12,a4717460508e,742344af2efd,a8c83abd75f6,acc1eef136c1
2017-08-29 07:16:00,13,84742ab11871
2017-08-29 07:16:00,18,84742aac34f3,000000000000
2017-08-29 07:17:00,12,a4717460508e,742344af2efd,a8c83abd75f6,acc1eef136c1
2017-08-29 07:17:00,13,84742ab11871
2017-08-29 07:17:00,18,000000000000,84742aac34f3
2017-08-29 07:18:00,12,a4717460508e,acc1eef136c1,a8c83abd75f6
2017-08-29 07:18:00,13,84742ab11871
2017-08-29 07:18:00,18,84742aac34f3,000000000000
2017-08-29 07:19:00,12,a4717460508e,acc1eef136c1,a8c83abd75f6
2017-08-29 07:19:00,18,84742aac34f3,000000000000
2017-08-29 07:20:00,12,a4717460508e,acc1eef136c1,742344af2efd,a8c83abd75f6
2017-08-29 07:20:00,18,000000000000,84742aac34f3
2017-08-29 07:21:00,12,acc1eef136c1,742344af2efd,a8c83abd75f6,a4717460508e
2017-08-29 07:21:00,13,dc742ab11aa2,58404eb6d01d
2017-08-29 07:21:00,18,84742aac34f3,000000000000
2017-08-29 07:22:00,12,a4717460508e,acc1eef136c1,742344af2efd,a8c83abd75f6
2017-08-29 07:22:00,13,58404eb6d01d,dc742ab11aa2
2017-08-29 07:22:00,18,205d47dfd85b,000000000000,84742aac33ed,84742aac34f3
2017-08-29 07:23:00,12,742344af2efd,a8c83abd75f6,acc1eef136c1,a4717460508e
2017-08-29 07:23:00,13,58404eb6d01d,dc742ab11aa2
2017-08-29 07:23:00,18,205d47dfd85b,000000000000,fc1a11f6c610,84742aac33ed,84742aac34f3,84742aac34d7,84742aac34e1
2017-08-29 07:24:00,12,4c1a3d46813b,acc1eef136c1,a8c83abd75f6,742344af2efd,a4717460508e
2017-08-29 07:24:00,13,dc742ab11aa2,58404eb6d01d
2017-08-29 07:24:00,18,205d47dfd85b,84742aac34f3,fc1a11f6c610,84742aac33ed,000000000000,84742aac34d7,84742aac34e1
2017-08-29 07:25:00,12,e0ddc09ba9f0,742344af2efd,a4717460508e,4c1a3d46813b,acc1eef136c1
2017-08-29 07:25:00,13,dc742ab11aa2,58404eb6d01d
2017-08-29 07:25:00,18,205d47dfd85b,84742aac34f3,fc1a11f6c610,84742aac33ed,000000000000,84742aac34d7,84742aac34e1
2017-08-29 07:26:00,12,205d470c0ada,a03be3e38947,4c1a3d46813b,acc1eef136c1,a4717460508e,e0ddc09ba9f0,742344af2efd
2017-08-29 07:26:00,13,dc742ab11aa2,58404eb6d01d
...
数据挖掘流程:
1.数据采样。原始数据采样间隔为1min,为精简数据,将采样间隔设成15min。并返回文件
2.读取采样后的文件,设置目标mac地址和最小置信度
3.进行FP-Growth算法,并返回与目标mac相关联的mac地址列表,并生成本地文件
Python代码:
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
from dateutil.parser import parse
import datetime
import csv
from fp_growth import find_frequent_itemsets
"""
1.输入起止时间start_time end_time、时间采样间隔delta_min 输出maclist
2.输入mac地址、最小置信度minsup 输出关联mac
"""
__author__ = 'SuZibo'
start_time = '2017-09-01 00:00:00'
end_time ='2017-09-30 23:00:00'
delta_min = 15
outpath = './data/'+start_time[5:10]+'_'+end_time[5:10]+'_'+str(delta_min)+'_mins.txt'
def timeSampling(start_time,end_time,delta_min,outpath):
#采样函数 根据起止时间,delta_min 返回mac文件
rs = open(outpath, 'w')
with open('./data/origin_info.txt') as f:
for line in f:
line = line.split(',')
if line[0] < start_time:
continue
#时间区间判定
if line[0] >= start_time and line[0] <= end_time:
#时间区间判定
# print len(line)
line[-1] = line[-1].strip('\n')
macline = line[2:]
#只取mac
macline = str(macline)
macline = macline.strip('[').strip(']').replace("'", "").replace(" ", "")
# print macline[2:]
# print line
rs.write(str(macline) + '\n')
start_time = datetime.datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S')
start_time += datetime.timedelta(minutes=delta_min)
#时间按照单位时间递增
start_time = str(start_time)
rs.close()
mac ='c81ee7c39fca'
#目标mac
minsup = 10
#最小置信度
outpath2 ='./data/related_maclist.txt'
#相关的mac地址 以文件形式输出
def findMacList(mac,minsup):
#FP—Growth算法 通过输入mac,计算符合最小置信度(minsup)的关联mac地址列表
related_maclist=[]
#存FP算法得到的原始列表
mac_list=[]
#去重后的列表
csv_reader = csv.reader(open(outpath))
transactions = [line for line in csv_reader]
#csv转列表
for itemset in find_frequent_itemsets(transactions,minsup):
if len(itemset) == 1:
continue
else:
if mac in itemset:
related_maclist.append(itemset)
print related_maclist
for i in xrange(len(related_maclist)):
for n in xrange(len(related_maclist[i])):
if related_maclist[i][n] == mac:
continue
if related_maclist[i][n] in mac_list:
continue
else:
mac_list.append(related_maclist[i][n])
#遍历related_maclist 做数据规整
# mac_list.remove(mac)
print mac_list
f1 = open(outpath2,'w')
f1.write(str(mac_list))
f1.close()
#规整后的数据写入本地文件
timeSampling(start_time,end_time,delta_min,outpath)
findMacList(mac,minsup)
最终得到
数据1:
[['c81ee7c39fca', '84119e957f21'],
['4888cab62744', 'c81ee7c39fca'],
['84742aac3178', '4888cab62744', 'c81ee7c39fca'],
['84742aac33a6', '4888cab62744', 'c81ee7c39fca'],
['84742aac3178', '84742aac33a6', '4888cab62744', 'c81ee7c39fca'],
['84742aac3178', 'c81ee7c39fca'],
['84742aac33a6', 'c81ee7c39fca'],
['84742aac3178', '84742aac33a6', 'c81ee7c39fca'],
['c81ee7c39fca', 'cc2d83698348'],
['c81ee7c39fca', '8c293792974c'],
['4888cab62744', 'c81ee7c39fca', '8c293792974c'],
['84742aac3178', '4888cab62744', 'c81ee7c39fca', '8c293792974c'],
['84742aac3178', 'c81ee7c39fca', '8c293792974c'],
['84742aac33a6', 'c81ee7c39fca', '8c293792974c']]
数据2(清洗、去重):
['84119e957f21', '4888cab62744', '84742aac3178', '84742aac33a6', 'cc2d83698348', '8c293792974c']
即为mac='c81ee7c39fca'的关联mac(置信度10)