深度数字语音处理
深度数字语音处理
引言|有用的工具|知识体系|数学|传统特征
引言
TODO
有用的工具
语音数据集|奇怪的网站|开发环境|第三方库
语音数据集
| 数据集 | 描述 |
|---|---|
| ESC-50 dataset | 该数据集由2000条语音组成,每条语音5秒,共分为50个语义类别(每个语义类别40条) |
ESC-50[paper]共有50个类(2000条),共分5个大类:
- Animals 动物(0-9)
- 自然场景声音 Natural soundscapes & water sounds (10-19)
- 人声(非语音) Human (non-speech) sounds (20-29)
- 室内 Interior/Domestic sounds (30-39)
- 室外/街道 Exterior/urban noises (40-49)
奇怪的网站
shields.io : 一个用来生成各种markdown小图标的网站
开发环境
| Software | Description |
|---|---|
| Anaconda | pythong环境管理 |
| PyCharm | python最好用的IDE之一,community即可 |
| VS Code | 万金油IDE+Text Editor,PyCharm coomunity无法使用版本控制后的github最佳选择之一 |
| Xshell/Xftp | 远程服务器管理工具,可以支持本地tensorboard |
第三方库
soundfile|LibROSA|Sounddevice
soundfile
跨平台的音频读写包
Installration:
pip/conda install soundfile, Linux可能需要apt-get install libsndfile1Read/Write:
soundfile.read(filename),soundfile.write(filename, data, samplerate)(WAV, FLAC, OGG, MAT)Blocking:
soundfile.blocks(filename, blocksize, overlap)SoundFile:
soundfile.SoundFile(filaname, I/O mode)/soundfile.close()
RAW files: 需要指定读入声音文件的类型
import soundfile as sf
data, samplerate = sf.read('myfile.raw', channels=1, samperate=44100, subtype='FLOAT')
x86机器默认
endian='LITTLE',老机器上可能需要指定endian='BIG'Virtual IO
import io
import soundfile as sf
from urllib.request import urlopen
url = "http://tinyurl.com/shepard-risset"
data, samplerate = sf.read(io.BytesIO(urlopen(url).read()))
有可能出现写OGG文件为空的情况
LibROSA
音乐和音频分析python包
Install:
pip conda install librosaorconda install -c conda-forge librosaWindows需要另外安装ffmpeg来支持更多的音频格式
Note:LibROSA有很大一部分module和function是为music processing and analysis服务的
CoreIO and DSP:包括音频处理(
load,resample,zero_crossings),谱表示(stft,istft,cqt,icqt),幅度变换(amplitude_to_db,db_to_power),时域与频域转换(frames_to_samples,frames_to_time,samples_to_frames),音高与调音Display:可视化功率谱、波形图等(
specshow,waveplot)Feature extraction:梅尔功率谱图(
melspectrogram)、mfcc(mfcc)、过零率(zero_crossing_rate)、特征转换(inverse.mel_to_stft,inverse.mfcc_to_mel)等TODO待补完
Example for LibROSA
Sounddevice
sounddevice是一个与Numpy兼容的录音以及播放声音的包
主要功能是播放和录音,以及一些交互式控制音频设备的方法
Example for Sounddevice
~悠久之风~
知识体系
音频格式|
音频格式
采样频率:1秒钟采样次数,大部分采样频率是44.1KHz
采样位数(位深,精度,比特):类似图像的位数,CD音频是16bit
比特率(音频位速,码率):单位时间内传送的比特数bps
CD音频比特率 = 44.1KHz * 16bit * 2 channels = 1411.2Kbps
16bit/44.1KHz是CD音频的采样
24bit/48KHz是DVD音频的采样
24bit/192KHz是蓝光中音频的采样
数学
STFT|CQT
传统特征
短时时频域特征|色度特征|mfcc|chroma|Mel|Contrast|Tonnetz
短时时频域特征
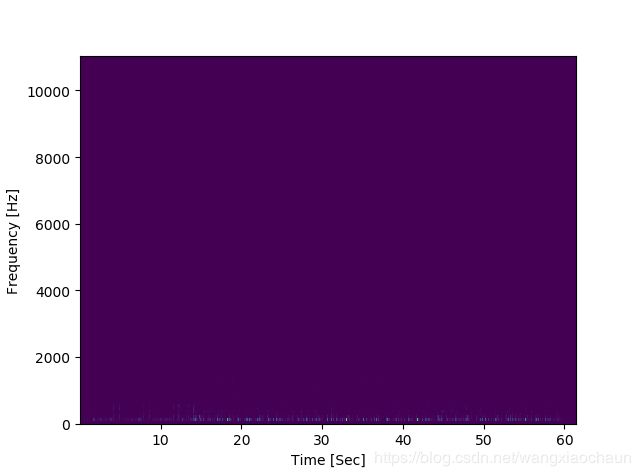
短时时频域分析基于短时傅里叶变换(STFT)。把长信号分帧、加窗,再对每一帧做傅里叶变换(FFT),最后把每一帧的结果沿另一个维度(声音信号对应就是时间)堆叠起来,得到类似一幅图的二维信号形式。对应声音信号就是声谱图(spectrogram)source
色度特征
色度特征是色度向量(Chroma vector)和色度谱(Chromagram)的统称。色度向量是一个含有12个元素的向量,这些元素分别代表一段时间(如1帧)内12个音级中的能量,不同八度(音高,pitch)的同一音级能量累加,色度图谱则是色度向量的序列(时间扩展)。
import librosa
import numpy as np
# chroma
# 沿着分帧的维度取均值,最终向量是12维
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T, axis=0)
mfcc
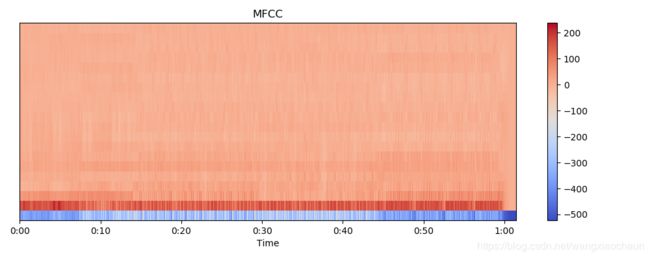
梅尔倒谱系数是倒谱分析的一种。在梅尔频谱上做倒谱分析(取对数,做dct变换)
librosa.feature.mfcc(y=None, sr=22050, S=None, n_mfcc=20,
dct_type=2, norm='ortho', lifter=0, **kwargs)
# 既可以输入时序信号y,也可以输入log-power Mel频谱图S
# 这里的S就是
# S = librosa.feature.melspectrogram(y)
# S = librosa.power_to_db(S)
cepstral -spectral “倒”谱
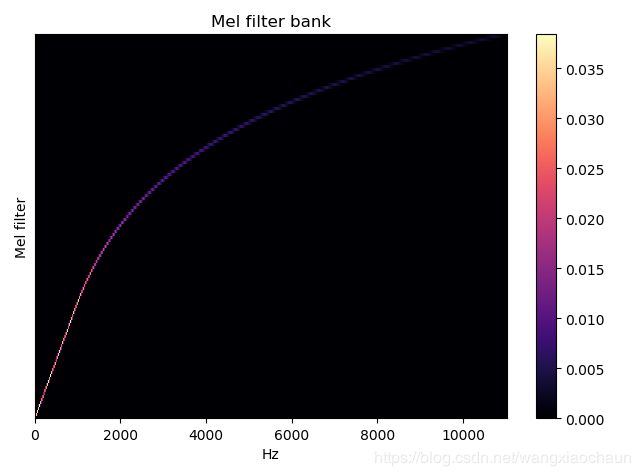
Mel
声谱图往往是很大的一张图,为了得到合适大小的声音特征,往往把它通过梅尔标度滤波器组(Mel-scale filter banks)变换为梅尔频谱(Mel-spectrogram)。
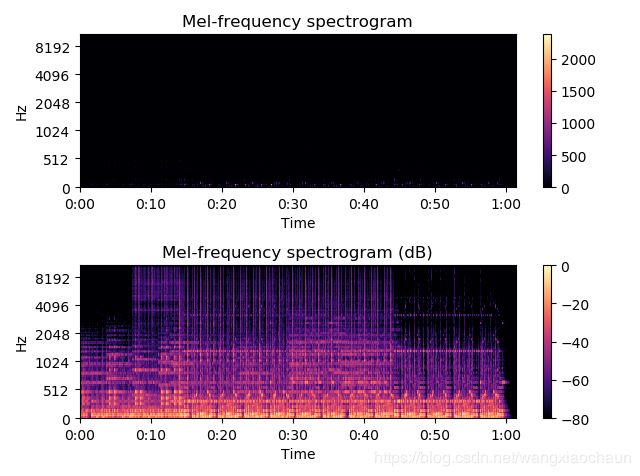
- 梅尔标度(Mel scale):通过观察人耳对声音频率变换的感知特性,将普通的频率标度转换为梅尔频率标度:
m e l ( f ) = 2595 ∗ l o g 10 ( 1 + f / 700 ) mel(f)=2595*log_{10}(1+f/700) mel(f)=2595∗log10(1+f/700)
在梅尔标度下,人耳对频率的感知度变成了线性关系。当频率较小时,mel随Hz变化较快;当频率很大时,mel的上升很缓慢,曲线的斜率很小。这说明人耳对低频音调的感知较灵敏;在高频时很迟钝。
- 梅尔标度滤波器组:受上述启发,设计的三角滤波器,低频处滤波器密集,门限值大;高频处滤波器稀疏,门限值低。在人声领域(语音识别、说话人辨认)等领域,常使用等面积梅尔滤波器(mel-filter bank with same bank area);在非人声领域,prefer的是等高梅尔滤波器(mel-filter bank with same bank height)。
Mel filter的生成(每个滤波器的起始频率、终止频率;等面积梅尔滤波器的最高门限值)
如果已知频谱图(声谱图) S S S,可以直接映射到梅尔标度。
D = np.abs(librosa.stft(y)) ** 2
S = librosa.feature.melspectrogram(S=D, sr=sr)
如果输入是时序信号,那么首先计算幅度谱图(magnitude spectrogram,S**power),然后再映射到mel scale。默认power=2,计算结果是功率谱。
S = librosa.feature.melspectrogram(y=y, sr=sr, ...)
Contrast
计算谱对比度(spectral contrast)[1]
声谱图(spectrogram)S对应的每个分帧被分为子带(sub-bands)。对每个子带,比较top quantile(peak energy)的mean energyt与bottom quantile(valley energy)的平均能量。High contrast值一般对应clear,narrow-band信号,low contrast值对应broad-band噪声。
Spectral contrast相较MFCC,保留了更多子带信息(MFCC是roughly的平均)
- 原始Spectral Contrast特征估计
对原始音频分帧,每个分帧做STFT,然后分为若干子带(一般是6个,对应librosa里面的n_bands=6)。在每个子带内,估计Peak和Valley(一般是把FFT幅值排序,然后选择最大的几个(这个通过一个比例因子来确定从总数为N的FFT幅值中选 α × N \alpha \times N α×N个, α \alpha α对应librosa里面的quantile=0.02),取log均值作为Peak值;类似得到Valley值),然后计算差值 S C k = P e a k k − V a l l e y k SC_{k}=Peak_{k}-Valley_{k} SCk=Peakk−Valleyk。最后将 { S C k , V a l l e y k } \{SC_{k}, Valley_{k}\} {SCk,Valleyk}作为原始Spectral Contrast特征。
- Karhunen-Loeve Transform
KL变换的目的是去掉不同维度之间的相关性。通过在训练集上找到一个正交基,将提取的Spectral Constrast特征投影,得到不相关的特征向量。
[1] Jiang, Dan-Ning, Lie Lu, Hong-Jiang Zhang, Jian-Hua Tao, and Lian-Hong Cai. “Music type classification by spectral contrast feature.” In Multimedia and Expo, 2002. ICME‘02. Proceedings. 2002 IEEE International Conference on, vol. 1, pp. 113-116. IEEE, 2002.
librosa.feature.spectral_contrast(y=None, sr=22050, S=None, n_fft=2048,
hop_length=512, win_length=None, window='hann', center=True, pad_mode='reflect',
freq=None, fmin=200.0, n_bands=6, quantile=0.02, linear=False)
# Return: contrast.ndarray[shape=(n_band+1, t)]
Tonnetz
计算tonal centroid features(tonnetz)[2]
[2] Harte, C., Sandler, M., & Gasser, M. (2006). “Detecting Harmonic Change in Musical Audio.” In Proceedings of the 1st ACM Workshop on Audio and Music Computing Multimedia (pp. 21-26). Santa Barbara, CA, USA: ACM Press. doi:10.1145/1178723.1178727.
librosa.feature.tonnetz(y=None, sr=22050, chroma=None)
# Parameter: chroma: Normalized energy for each chroma bin at each frame.
# If None, a cqt chromagram is performed.
# Returns: tonnetz shape:[6,t]
主要用于music中的和声关系表示。和声包括纯五度(fifth),大三度(major third),小三度(minor third)。tonnetz centroid features反应每个分帧在以上三个空间中的投影坐标[B站视频]。