浅谈pandas,pyspark 的大数据ETL实践经验
文章大纲
- 0.序言
- 1. 数据接入
- 2. 脏数据的清洗
- 2.1 文件转码
- 2.2 指定列名
- 2.3 pyspark dataframe 新增一列并赋值
- 2.4 时间格式处理与正则匹配
- 3. 缺失值的处理
- 4. 数据质量核查与基本的数据统计
- 4.1 统一单位
- 4.1.1 年龄
- 4.1.2 日期
- 4.1.3 数字
- 4.2 去重操作
- 4.3 聚合操作与统计
- 4.4 Top 指标获取
- 5.数据导入导出
- 参考文献
- 大数据ETL 系列文章简介
0.序言
本文主要以基于AWS 搭建的EMR spark 托管集群,使用pandas pyspark 对合作单位的业务数据进行ETL ---- EXTRACT(抽取)、TRANSFORM(转换)、LOAD(加载) 等工作为例介绍大数据数据预处理的实践经验,很多初学的朋友对大数据挖掘,数据分析第一直观的印象,都只是业务模型,以及组成模型背后的各种算法原理。往往忽视了整个业务场景建模过程中,看似最普通,却又最精髓的数据预处理或者叫数据清洗过程。
1. 数据接入
我们经常提到的ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,首先第一步就是根据不同来源的数据进行数据接入,主要接入方式有三:
- 1.批量数据
可以考虑采用使用备份数据库导出dmp,通过ftp等多种方式传送,首先接入样本数据,进行分析 - 2.增量数据
考虑使用ftp,http等服务配合脚本完成 - 2.实时数据
消息队列接入,kafka,rabbitMQ 等
数据接入对应ETL 中的E----EXTRACT(抽取),接入过程中面临多种数据源,不同格式,不同平台,数据吞吐量,网络带宽等多种挑战。
python 这种胶水语言天然可以对应这类多样性的任务,当然如果不想编程,还有:Talend,Kettle,Informatica,Inaplex Inaport等工具可以使用.
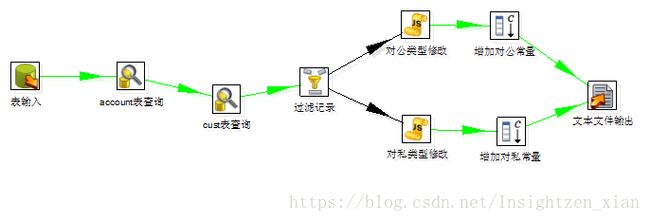
e.g. 一个kettle 的作业流
以上不是本文重点,不同数据源的导入导出可以参考:
数据库,云平台,oracle,aws,es导入导出实战
我们从数据接入以后的内容开始谈起。
2. 脏数据的清洗
比如在使用Oracle等数据库导出csv file时,字段间的分隔符为英文逗号,字段用英文双引号引起来,我们通常使用大数据工具将这些数据加载成表格的形式,pandas ,spark中都叫做dataframe
对与字段中含有逗号,回车等情况,pandas 是完全可以handle 的,spark也可以但是2.2之前和gbk解码共同作用会有bug
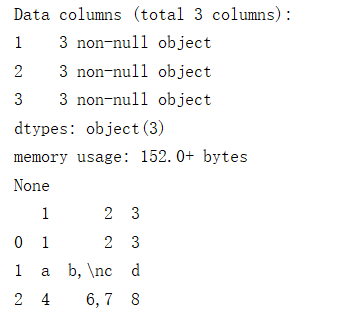
数据样例
1,2,3
"a","b,
c","d"
"4","6,7","8"
pandas
# -*- coding:utf-8 -*-
"""@author:season@file:testCSV.py@time:2018/5/3110:49"""
import pandas
def sum_analysis(filename,col_names):
# 读csv文件
data = pandas.read_csv(filename,names=col_names,\
engine='python', dtype=str)
# 返回前n行
first_rows = data.head(n=2)
print(first_rows)
# 返回全部列名
cols = data.columns
print(cols)
# 返回维度
dimensision = data.shape
print(dimensision)
print(data.info())
return data
def main():
col_names = ['1','2','3']
file_test = u'''test.csv'''
print(sum_analysis(file_test,col_names))
if __name__=='__main__':
main()
pyspark
sdf = spark.read.option("header","true") \
.option("charset","gbk") \
.option("multiLine", "true") \
.csv("s3a://your_file*.csv")
pdf = sdf.limit(1000).toPandas()
linux 命令
强大的sed命令,去除两个双引号中的换行
**处理结果放入新文件**
sed ':x;N;s/\nPO/ PO/;b x' INPUTFILE > OUTPUTFILE
**处理结果覆盖源文件**
sed -i ':x;N;s/\nPO/ PO/;b x' INPUTFILE
2.1 文件转码
当然,有些情况还有由于文件编码造成的乱码情况,这时候就轮到linux命令大显神威了。
比如 使用enconv 将文件由汉字编码转换成utf-8
enconv -L zh_CN -x UTF-8 filename
或者要把当前目录下的所有文件都转成utf-8
enca -L zh_CN -x utf-8 *
在Linux中专门提供了一种工具convmv进行文件名编码的转换,可以将文件名从GBK转换成UTF-8编码,或者从UTF-8转换到GBK。
下面看一下convmv的具体用法:
convmv -f 源编码 -t 新编码 [选项] 文件名
#将目录下所有文件名由gbk转换为utf-8
convmv -f GBK -t UTF-8 -r --nosmart --notest /your_directory
2.2 指定列名
在spark 中
如何把别的dataframe已有的schame加到现有的dataframe 上呢?
from pyspark.sql.types import *
diagnosis_sdf_new = diagnosis_sdf.rdd.toDF(diagnosis_sdf_tmp.schema)
2.3 pyspark dataframe 新增一列并赋值
http://spark.apache.org/docs/latest/api/python/pyspark.sql.html?highlight=functions#module-pyspark.sql.functions
统一值
from pyspark.sql import functions
df = df.withColumn('customer',functions.lit("eng_string"))
#或者这么写
df = df.select('*', (df.age + 10).alias('agePlusTen'))
不同值,写udf
from pyspark.sql.types import IntegerType
from pyspark.sql.functions import udf
def func(fruit1, fruit2):
if fruit1 == None or fruit2 == None:
return 3
if fruit1 == fruit2:
return 1
return 0
func_udf = udf(func, IntegerType())
df = df.withColumn('new_column',func_udf(df['fruit1'], df['fruit2']))
2.4 时间格式处理与正则匹配
#1.日期和时间的转码,神奇的任意时间识别转换接口
import dateutil.parser
d = dateutil.parser.parse('2018/11-27T12:00:00')
print(d.strftime('%Y-%m-%d %H:%M:%S'))
#如果本来这一列是数据而写了其他汉字,则把这一条替换为0,或者抛弃?,置空
is_float = re.compile(r'^[-+]?[0-9]+\.[0-9]+$')
3. 缺失值的处理
pandas
pandas使用浮点值NaN(Not a Number)表示浮点数和非浮点数组中的缺失值,同时python内置None值也会被当作是缺失值。
如果其中有值为None,Series会输出None,而DataFrame会输出NaN,但是对空值判断没有影响。DataFrame使用isnull方法在输出空值的时候全为NaN
例如对于样本数据中的年龄字段,替换缺失值,并进行离群值清洗
pdf["AGE"] = pd.to_numeric(pdf["AGE"],"coerce").fillna(500.0).astype("int")
pdf[(pdf["AGE"] > 0) & (pdf["AGE"] < 150)]
自定义过滤器过滤
#Fix gender
def fix_gender(x):
if x is None:
return None
if "男" in x:
return "M"
if "女" in x:
return "F"
pdf["PI_SEX"] = pdf["PI_SEX"].map(fix_gender)
or
pdf["PI_SEX"] = pdf["PI_SEX"].apply(fix_gender)
或者直接删除有缺失值的行
data.dropna()
pyspark
spark 同样提供了,.dropna(…) ,.fillna(…) 等方法,是丢弃还是使用均值,方差等值进行填充就需要针对具体业务具体分析了
#查看application_sdf每一列缺失值百分比
import pyspark.sql.functions as fn
queshi_sdf = application_sdf.agg(*[(1-(fn.count(c) /fn.count('*'))).alias(c+'_missing') for c in application_sdf.columns])
queshi_pdf = queshi_sdf.toPandas()
queshi_pdf
4. 数据质量核查与基本的数据统计
对于多来源场景下的数据,需要敏锐的发现数据的各类特征,为后续机器学习等业务提供充分的理解,以上这些是离不开数据的统计和质量核查工作,也就是业界常说的让数据自己说话。
4.1 统一单位
多来源数据 ,突出存在的一个问题是单位不统一,比如度量衡,国际标准是米,然而很多北美国际习惯使用英尺等单位,这就需要我们使用自定义函数,进行单位的统一换算。
比如,有时候我们使用数据进行用户年龄的计算,有的给出的是出生日期,有的给出的年龄计算单位是周、天,我们为了模型计算方便需要统一进行数据的单位统一,以下给出一个统一根据出生日期计算年龄的函数样例。
4.1.1 年龄
import datetime
def CalculateAge(str_Date):
'''Calculates the age and days until next birthday from the given birth date'''
try:
Date = str_Date.split(' ')[0].split('-')
BirthDate = datetime.date(int(Date[0]), int(Date[1]), int(Date[2]))
Today = datetime.date.today()
if (Today.month > BirthDate.month):
NextYear = datetime.date(Today.year + 1, BirthDate.month, BirthDate.day)
elif (Today.month < BirthDate.month):
NextYear = datetime.date(Today.year, Today.month + (BirthDate.month - Today.month), BirthDate.day)
elif (Today.month == BirthDate.month):
if (Today.day > BirthDate.day):
NextYear = datetime.date(Today.year + 1, BirthDate.month, BirthDate.day)
elif (Today.day < BirthDate.day):
NextYear = datetime.date(Today.year, BirthDate.month, Today.day + (BirthDate.day - Today.day))
elif (Today.day == BirthDate.day):
NextYear = 0
Age = Today.year - BirthDate.year
return Age
# if NextYear == 0: #if today is the birthday
# return '%d, days until %d: %d' % (Age, Age+1, 0)
# else:
# DaysLeft = NextYear - Today
# return '%d, days until %d: %d' % (Age, Age+1, DaysLeft.days)
except:
return 'Wrong date format'
## 如果用在spark 的udf 中
from pyspark.sql.functions import udf
CalculateAge = udf(CalculateAge, IntegerType())
# Apply UDF function
Member_df = Member_df.withColumn("AGE", CalculateAge(Member_df['date of birthday']))
由身份证号获取年龄
import datetime
def get_age(id):
"""通过身份证号获取年龄"""
birth_year = int(id[6:10])
birth_month = int(id[10:12])
birth_day = int(id[12:14])
now = (datetime.datetime.now() + datetime.timedelta(days=1))
year = now.year
month = now.month
day = now.day
if year == birth_year:
return 0
else:
if birth_month > month or (birth_month == month and birth_day > day):
return year - birth_year - 1
else:
return year - birth_year
4.1.2 日期
清洗日期格式字段
from dateutil import parser
def clean_date(str_date):
try:
if str_date:
d = parser.parse(str_date)
return d.strftime('%Y-%m-%d')
else:
return None
except Exception as e:
return None
def clean_schema_date(spark_df,column_Date):
func_udf_clean_date = udf(clean_date, StringType())
for column in column_Date:
spark_df=spark_df.withColumn(column, func_udf_clean_date(spark_df[column]))
return spark_df
4.1.3 数字
#清洗数字格式字段
#如果本来这一列是数据而写了其他汉字,则把这一条替换为0,或者抛弃?,置空
def is_number(s):
try:
float(s)
return True
except ValueError:
pass
return False
def clean_number(str_number):
try:
if str_number:
if is_number(str_number):
return str_number
else:
return None
else:
return None
except Exception as e:
return None
func_udf_clean_number = udf(clean_number, StringType())
def clean_schema_number(spark_df,column_number):
for column in column_number:
spark_df=spark_df.withColumn(column, func_udf_clean_number(spark_df[column]))
return spark_df
4.2 去重操作
pandas
去重操作可以帮助我们统计业务的核心数据,从而迅速抓住主要矛盾。例如,对于互联网公司来说,每天有很多的业务数据,然而发现其中的独立个体的独立行为才是数据分析人员应该注意的点。
data.drop_duplicates(['column'])
pyspark
使用dataframe api 进行去除操作和pandas 比较类似
sdf.select("column1","column2").dropDuplicates()
当然如果数据量大的话,可以在spark环境中算好再转化到pandas的dataframe中,利用pandas丰富的统计api 进行进一步的分析。
pdf = sdf.select("column1","column2").dropDuplicates().toPandas()
使用spark sql,其实我觉的这个spark sql 对于传统的数据库dba 等分析师来说简直是革命性产品, 例如:如下代码统计1到100测试中每一个测试次数的人员分布情况
count_sdf.createOrReplaceTempView("testnumber")
count_sdf_testnumber = spark.sql("\
SELECT tests_count,count(1) FROM \
testnumber where tests_count < 100 and lab_tests_count > 0 \
group by tests_count \
order by count(1) desc")
count_sdf_testnumber.show()
4.3 聚合操作与统计
pyspark 和pandas 都提供了类似sql 中的groupby 以及distinct 等操作的api,使用起来也大同小异,下面是对一些样本数据按照姓名,性别进行聚合操作的代码实例
pyspark
sdf.groupBy("SEX").agg(F.count("NAME")).show()
labtest_count_sdf = sdf.groupBy("NAME","SEX","PI_AGE").agg(F.countDistinct("CODE").alias("tests_count"))
spark sql
filename = "*.csv"
df = (spark
.read
.option("header","true")
.csv(filename)
.cache()
)
df.createOrReplaceTempView("export")
df_Parents = spark.sql("SELECT STATUS,count(1) shuliang FROM export where TYPE = 'Parents' group by STATUS order by count(1) desc")
df_Parents.show()
pdf_Parents= df_Parents.toPandas()
pdf_Parents.plot(kind='bar')
plt.show()
顺带一句,pyspark 跑出的sql 结果集合,使用toPandas() 转换为pandas 的dataframe 之后只要通过引入matplotlib, 就能完成一个简单的可视化demo 了。
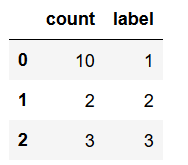
d2 = pd.DataFrame({
'label': [1,2,3],
'count': [10,2,3],})
d2.plot(kind='bar')
plt.show()
d2.plot.pie(labels=['1', '2', '3'],subplots=True, figsize=(8, 4))
plt.show()
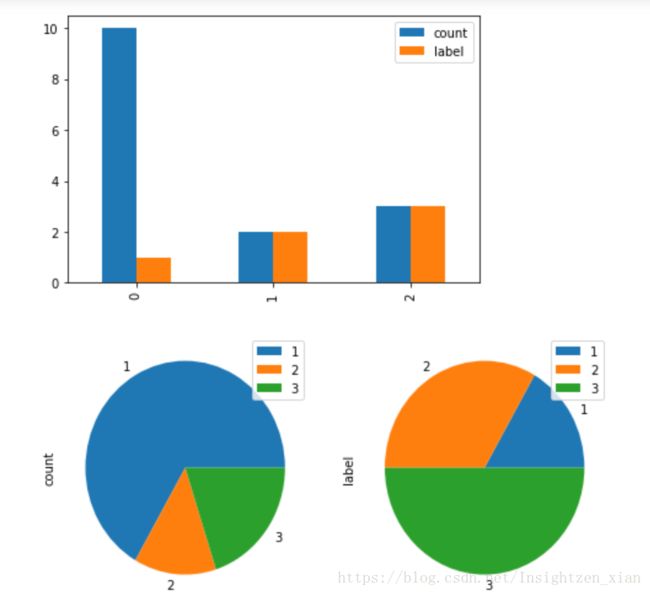
直方图,饼图
4.4 Top 指标获取
top 指标的获取说白了,不过是groupby 后order by 一下的sql 语句
5.数据导入导出
参考:数据库,云平台,oracle,aws,es导入导出实战
参考文献
做Data Mining,其实大部分时间都花在清洗数据
http://www.raincent.com/content-10-8092-1.html
基于PySpark大规模数据预处理
https://www.jianshu.com/p/b7882e9616c7
同时发表在:
https://blog.csdn.net/insightzen_xian/article/details/80659243
大数据ETL 系列文章简介
本系列文章主要针对ETL大数据处理这一典型场景,基于python语言使用Oracle、aws、Elastic search 、Spark 相关组件进行一些基本的数据导入导出实战,如:
- oracle使用数据泵impdp进行导入操作。
- aws使用awscli进行上传下载操作。
- 本地文件上传至aws es
- spark dataframe录入ElasticSearch
等典型数据ETL功能的探索。
系列文章:
1.大数据ETL实践探索(1)---- python 与oracle数据库导入导出
2.大数据ETL实践探索(2)---- python 与aws 交互
3.大数据ETL实践探索(3)---- pyspark 之大数据ETL利器
4.大数据ETL实践探索(4)---- 之 搜索神器elastic search
5.使用python对数据库,云平台,oracle,aws,es导入导出实战
6.aws ec2 配置ftp----使用vsftp
7.浅谈pandas,pyspark 的大数据ETL实践经验
