【redis】redis简介及基本数据结构的操作
一、简介
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
linux安装redis:https://blog.csdn.net/wangyunzhao007/article/details/105163473
redis优点
1.特别快
Redis 非常快,每秒可执行大约 110000 次的设置(SET)操作,每秒大约可执行 81000 次的读取/获取(GET)操作。
为什么这么快?
简单总结:
-
纯内存操作:读取不需要进行磁盘 I/O,所以比传统数据库要快上不少;(但不要有误区说磁盘就一定慢,例如 Kafka 就是使用磁盘顺序读取但仍然较快)
-
单线程,无锁竞争:这保证了没有线程的上下文切换,不会因为多线程的一些操作而降低性能;
-
多路 I/O 复用模型,非阻塞 I/O:采用多路 I/O 复用技术可以让单个线程高效的处理多个网络连接请求(尽量减少网络 IO 的时间消耗);
-
高效的数据结构,加上底层做了大量优化:Redis 对于底层的数据结构和内存占用做了大量的优化,例如不同长度的字符串使用不同的结构体表示,HyperLogLog 的密集型存储结构等等..
2.支持多种数据类型
支持string,list,hash,set,zset等基本类型,还有bitMap,布隆过滤器,hyperloglog,stream等高级数据类型。
3.操作具有原子性
Redis 操作都是原子操作,这确保如果两个客户端并发访问,Redis 服务器能接收更新的值。
4.支持多种工具
有消息队列,发布订阅等。
二、数据结构
1.字符串String
Redis 中的字符串是一种 动态字符串,这意味着使用者可以修改,它的底层实现有点类似于 Java 中的 ArrayList。
操作命令实例
set key value #不管key是否存在,都设置
setnx key value #key不存在,才设置
set key value xx #key存在,才设置
get key #取出key对应的value测试结果
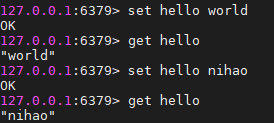
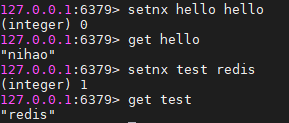

set命令:key值不存在,将新的key,value存进去;key值已经存在,将新的key值覆盖。
setnx:当key值不存在时,把新的key,value存在去;当key值存在时,不存,还保留之前的数据。
setxx:当key值存在时,将新的值覆盖旧址;当key不存在,不做操作。
此外还要mget ,rmset等命令

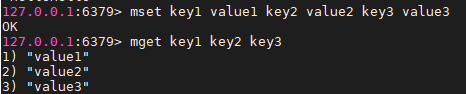
还有一些其他有关字符串的操作,如getset、append、strlen、incrbyfloat、getrange、setrange等。

2.字典Hash
Redis 中的字典相当于 Java 中的 HashMap,内部实现也差不多类似,都是通过 "数组 + 链表" 的链地址法来解决部分 哈希冲突,同时这样的结构也吸收了两种不同数据结构的优点。
操作命令实例
插入
key为redis中键值的key,二field是hash中键值的key。
hset key field value #设置hash表key中的field的值。如果hash表不存在,则创建,并执行设置field的值,如果hash表存在,值field的值覆盖或新增
hash key field value[key value] #批量设置hash表key的域
hsetnx key field value #仅仅当field域不存在时,设置hash表field的值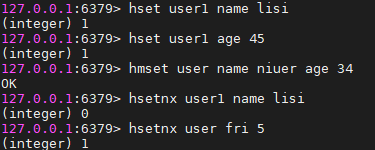
查询
hget key field #获取哈希表key的field值
hmget key field[field] #批量获取hash表的filed
hgetall key #获取hash表的所有域值
hexists key field #判断hash表中是否存在某个域
hkeys key #获取hash表的所有域
hvals key #获取hash表的所有域值 
修改
hincrby key field increment #hash表field域的数值增加步长increment,如果increment是负值,则是递减。如果域不存在,初始值视为0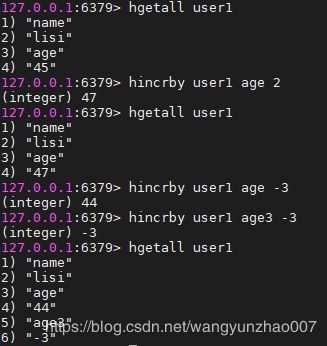
删除
hdel key field[field] #删除hash的域,如果指定多个field,则删除多个 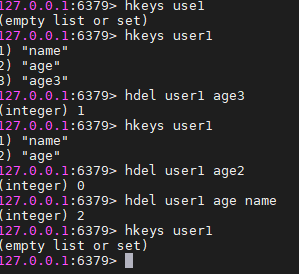
其他
hlen key #获取hash的域数量
3.列表List
Redis 的列表相当于 Java 语言中的 LinkedList,有序,重复,左右两边插入弹出,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。
操作命令实例
插入
lpush和rpush命令
lpush key value1 value2 value3...valuen #从列表左端插入(1-n)个
rpush key value1 value2 value3...valuen #从列表右端插入(1-n)个
备注:lrange mylist 0 -1 # -1 表示倒数第一个元素, 这里表示从第一个元素到最后一个元素,即查询集合所有元素
linsert命令
linsert key before value newValue #在list指定的值前插入新值
linsert key aftervalue newValue #在list指定的值后插入新值

删除
lpop 命令
lpop key #从列表左侧弹出一个item
rpop key #从列表右侧弹出一个item
lrem命令
lrem key count value
#根据count值,从列表中删除所有和value值相等的项
#count>0,从左向右删除count(不够count个,有多少删除多少)个和value值相等的项
#count<0,从右向左删除count个和value值相等的项
#count=0,删除所有和value值相等的项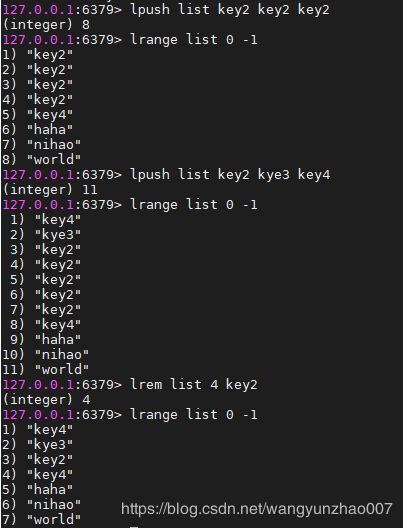
ltrim命令
ltrim key start end #按照索引范围修剪列表 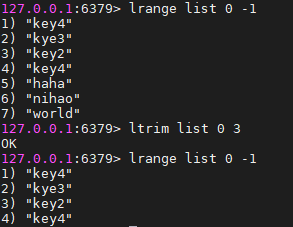
查询
lrange命令
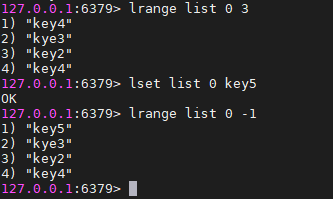
lrange key start end(包含end) #获取列表指定索引范围所有的item。 end为-1代表是末尾元素,故lrange key 0 -1 是查看所有元素
还有其他的查询就不一一展示了。

修改
lset命令
lset key index newValue #设置列表指定索引值为newValue
4.集合Set
Redis 的集合相当于 Java 语言中的 HashSet,它内部的键值对是无序、唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。
操作命令实例
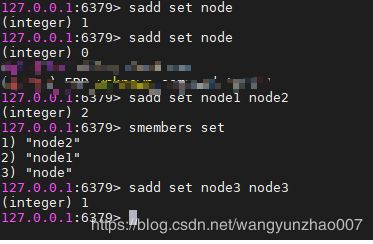
sadd key value1 value #可以一次添加多个,值不能相同,相同只能插入一个
srem key value #将集合key中的value移除掉
smembers key #获取到set集合中的所有值
scard key #获取长度
spop key #弹出一个

5.有序集合SortedSet
类似于 Java 中 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以为每个 value 赋予一个 score 值,用来代表排序的权重。它的内部实现用的是一种叫做 「跳跃表」 的数据结构。
操作命令实例
zadd key score value(可以是多个) #添加score和value
zrange key start end #获取指定索引区间内的升序元素,end写-1代表倒数第一个元素
zrem kye value(可以是多个) #删除元素
zscore key value #返回元素的分数
zincrby key increScore value #增加或减少元素的分数 
zset还有一些其他的命令,大家可以试一试

还有一些通用的命令也要知道的:
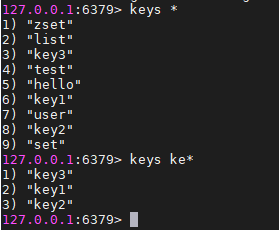
keys 查询键,还可以模糊查询
dbsize 查询键的个数

del key [key] 删除键值

expire key seconds 设置过期时间
exists key 判断是否存在

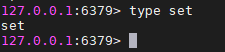
type key 存储类型
redis基本数据类型参考博客:https://mp.weixin.qq.com/s/MT1tB2_7f5RuOxKhuEm1vQ