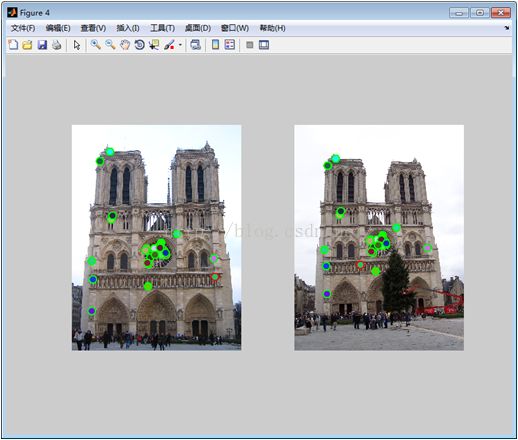
基于Harris的特征检测与匹配
之前在斯坦福的机器视觉算法与应用课程上学了一些东西,并用matlab编程实现,没来得及整理,现在把它整理一下,出来的效果可能不太完善,这有待后续的研究与改进。基于特征的图像配准方法是图像配准中最常见的方法之一。它不是直接利用图像像素值,二十通过像素值导出的符号特征(如特征点、特征线、特征区域)来实现图像配准,因此可以克服利用灰度信息进行图像配准的缺点,主要体现在以下三个方面:(1)利用特征点而不是图像灰度信息,大大减少了在匹配过程中的计算量;(2)特征点的匹配度量值相对位置变化比较敏感,可以提高匹配的精度;(3)特征点的提取过程可以减少噪声的影响,对灰度变化、图像形变以及遮挡等都有较好的适应能力。
一类重要的点特征:角点(corner points),其定义主要有以下:
- 局部窗口沿各方向移动,灰度均产生明显变化的点
- 图像局部曲率突变的点
- 典型的角点检测算法:Harris角点检测、CSS角点检测
- Harris角点检测基本思想
从图像局部的小窗口观察图像特征,角点定义:窗口向任意方向的移动都导致图像灰度的明显变化(如下图)

Harris检测:数学表达
将图像窗口平移[u,v]产生灰度变化E(u,v)

由泰勒展开,得:
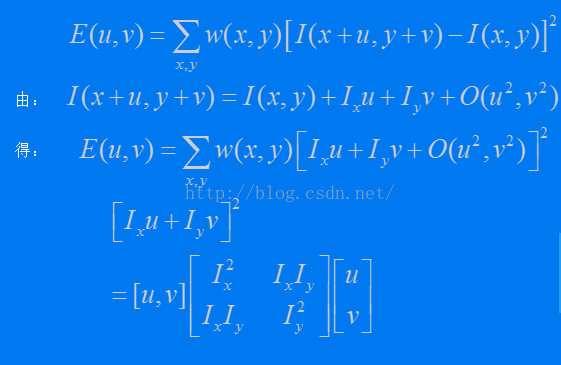

利用角点响应函数:

判断特征点是否为角点的依据:R只与M值有关,R为大数值正数时特征点为角点,R为大数值负数时为边缘,R为小数值时为平坦区,如下图:

寻找R位于一定阈值之上的局部最大值,去除伪角点。
Harris角点检测流程:
1.通过高斯函数的导数对原始图像进行卷积计算;图像在水平方向和垂直方向的导数Ix和Iy;
2.计算对应这些梯度外积即(Ix2 、Iy2、IxIy)三个图像如下图:
4.使用高斯函数对以上图像进行卷积滤波;
3.使用前面的公式计算角点响应函数R值;
5.对计算到的角点图像进行局部极大值抑制。
1.通过高斯函数的导数对原始图像进行卷积计算;图像在水平方向和垂直方向的导数Ix和Iy;
2.计算对应这些梯度外积即(Ix2 、Iy2、IxIy)三个图像如下图:
4.使用高斯函数对以上图像进行卷积滤波;
3.使用前面的公式计算角点响应函数R值;
5.对计算到的角点图像进行局部极大值抑制。
以下是我的特征检测代码,由于编程能力有限,可能过程中会出现代码不规范以及不完善的情况,望见谅!
function [x, y, confidence, scale, orientation] = get_interest_points(image,feature_width)
feature_width = 16;
fx = [-1,0,1;-2,0,2;-1,0,1];
fy = [-1,-2,-1;0,0,0;1,2,1];
Ix = imfilter(image,fx);
Iy = imfilter(image,fy);
Ix2 = Ix.* Ix;
%subplot(2,2,1);
%imshow(Ix2);
Ixy = Ix.* Iy;
% subplot(2,2,2);
% imshow(Ixy);
Iy2 = Iy.* Iy;
% subplot(2,2,3);
% imshow(Iy2);
h = fspecial('gaussian',25,2);
% subplot(2,2,4);
% imshow(h);
Ix2 = imfilter(Ix2,h);
Ixy = imfilter(Ixy,h);
Iy2 = imfilter(Iy2,h);
%寻找最大R值
Rmax = 0;
l = 0.05;
[img_height,img_width] = size(image);
M = zeros(img_height,img_width);
for i = 1:img_height
for j = 1:img_width
A = [Ix2(i,j),Ixy(i,j);Ixy(i,j),Iy2(i,j)];
M(i,j) = det(A) - l*(trace(A))^2;
if M(i,j) > Rmax
Rmax = M(i,j);
end
end
end
%局部非极大值抑制
k = 0.01;
cnt = 0; %记录角点数目
result = zeros(img_height,img_width);
for i=2:img_height-1
for j =2:img_width-1
if M(i,j)>k*Rmax && M(i,j)>M(i-1,j-1) && M(i,j)>M(i-1,j)&&M(i,j)>M(i-1,j+1)&&M(i,j)>M(i,j-1)&&M(i,j)>M(i,j+1)&&M(i,j)>M(i+1,j-1)&&M(i,j)>M(i+1,j)&&M(i,j)>M(i+1,j+1)
result(i,j) = 1;
cnt = cnt + 1;
end
end
end
[y,x] = find(result==1);
x_indexleft = find(x <= feature_width/2 - 1); %寻找x方向上左边边缘角点
%去除边缘角点
x(x_indexleft) = [];
y(x_indexleft) = [];
y_indexup = find(y <= feature_width/2 - 1); %寻找y方向上部边缘角点
x(y_indexup) = [];
y(y_indexup) = [];
x_indexright = find(x > img_width - 8); %寻找x方向右边的边缘角点
x(x_indexright) = [];
y(x_indexright) = [];
y_indexdown = find(y > img_height - 8); %寻找y方向下部的边缘角点
x(y_indexdown) = [];
y(y_indexdown) = [];
%x(find(x二、特征描述
在检测到特征(关键点)之后,我们必须匹配它们,也就是说,我们必须确定哪些特征来自于不同图像中的对应位置。物体识别的核心问题是将同一目标在不同时间、不同分辨率、不同光照、不同位姿情况下所成的图像相匹配。而为了进行匹配,我们首先要合理的表示图像。
SIFT(Scale invariant feature transform)特征通过计算检测到的关键点周围16x16窗口内每一个像素的梯度得到。在这里我只是简单的实现类似于SIFT特征描述子的特征描述方法,即我通过每4x4的四分之一象限,通过将加权梯度值加到直方图八个方向区间中的一个,计算出一个梯度方向直方图,因此在每一个特征点都会形成一个128维的非负值形成了一个原始版本的SIFT描述子向量如下图,并且将其归一化以减少对比度和增益的影响,最后为了使描述子对其他各种光度变化鲁棒,再将这些值以0.2截尾,然后再归一化到单位长度。

function [features] = get_features(image, x, y, feature_width)
y_gradient = imfilter(image,[-1,0,1]');
features = zeros(length(x),128);
for k = 1:length(x) %window of 16x16 of each feature
x_subwindow = x(k)-7:x(k)+8;
y_subwindow = y(k)-7:y(k)+8;
x_subwindow_gradient = x_gradient(y_subwindow,x_subwindow);
y_subwindow_gradient = y_gradient(y_subwindow,x_subwindow);
angles = atan2(y_subwindow_gradient,x_subwindow_gradient);
%for i = 1:16
%for j = 1:16
% if angles(i,j)<0
% angles(i,j) = angles(i,j) + 2*pi;
%end
%end
%end
angles(angles<0) = angles(angles<0) + 2*pi;
%angles_bin = [0 pi/4 pi/2 3*pi/4 pi 5*pi/4 3*pi/2 7*pi/4 2*pi];
angles_binranges = 0:pi/4:2*pi;
B = zeros(1,128);
for i = 1:feature_width/4:feature_width
for j = 1:feature_width/4:feature_width
%A = reshape(angles(i:i+3,j:j+3)',1,16);
subwindow = angles(i:i+3,j:j+3);
angles_bincounts = histc(subwindow(:),angles_binranges);
begin = 1 + 32*(floor(i/4)) + 8*(floor(j/4)); %tab the orientation of each 4x4 window
B(begin:begin+7) = angles_bincounts(1:8); %get the eight orientation of each window
%figure;
%bar(angles_binranges,angles_bincounts,'histc');
end
end
%disp(length(B/norm(B)));
features(k,:) = B/norm(B);
end
%cut the end
power = 0.8;
features = features.^power;
end
三、特征匹配
一旦我们从两幅或者多幅图像中提取到特征及其描述子后,下一步就是要在这些图像之间建立一些初始特征之间的匹配。
匹配策略一:对前面提取到的两幅图像的128维特征描述子向量做欧式距离度量,最简单的一个策略就是先设定一个阈值(最大距离),然后返回在这个阈值范围之内的另外一个图像中的所有匹配。
匹配策略二:做最近邻匹配,即比较最近邻距离和次近邻距离的比值,即最近邻比率(NNDR)。
匹配策略一:对前面提取到的两幅图像的128维特征描述子向量做欧式距离度量,最简单的一个策略就是先设定一个阈值(最大距离),然后返回在这个阈值范围之内的另外一个图像中的所有匹配。
匹配策略二:做最近邻匹配,即比较最近邻距离和次近邻距离的比值,即最近邻比率(NNDR)。
匹配策略一的缺点是,如果阈值设得太高,就会产生误报,也就是说会出现不正确的匹配。如果阈值设得太低,就会产生很多“漏报”,也就是说,很多正确的匹配被丢失。
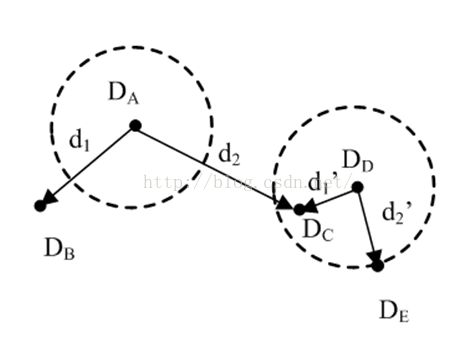
固定阈值,最近邻和最近邻比率匹配。在固定阈值(虚线圆)下,描述子DA未能与DB匹配,DD错误地与DC和DE匹配。如果我们选择最近邻,DA和DE匹配。使用最近邻比率(NNDR),小的NNDR(d1/d2)正确地将DA和DB匹配,大的NNDR(d1'/d2')正确地拒绝DD与DC、DE的匹配。
代码如下:
function [matches, confidences] = match_features(features1, features2)
ratio = 0.8;
num_matches = 0;
num_features1 = size(features1,1);
num_features2 = size(features2,1);
matches = zeros(num_features1,2);
confidences = zeros(num_features1);
for i = 1:num_features1
distances = dist(features1(i,:),features2');
[dists,index] = sort(distances);
nndr = dists(1)/dists(2);
if nndr < ratio
%num_matches = num_matches + 1;
matches(i,:) = [i,index(1)];
confidences(i) = 1 - nndr;
% else
% confidences(i) = [];
% matches(i,:) = [];
end
end
%keep only those matched
matches_index = find(confidences>0);
matches = matches(matches_index,:);
confidences = confidences(matches_index);
% Sort the matches so that the most confident onces are at the top of the
% list. You should probably not delete this, so that the evaluation
% functions can be run on the top matches easily.
[confidences, ind] = sort(confidences, 'descend');
matches = matches(ind,:);