音频文件按照正常语句,断句拆分的处理方法
关于录音文件断句分割的方法
前言
最近看讲座听在线英文电台的时候总有个想法,
讲座能不能自动记笔记?
电台能不能自动配中英文翻译对照字幕?
当然,这些东西,在一些软件里其实已经实现了的。
只是找不到能直接MP3转文本,免费又方便的,所以想用python来写点东西。
好在讯飞和百度都提供了免费的API可以调用。
这里用了一下百度语音识别的(讯飞不上传身份证认证只能用100条,身份证没带在身边)
百度语音识别目前对文件有上传有格式要求:
1、 pcm格式。这个用ffmpeg转就好了,百度自带的文档已经提到了
2、单个文件长度不能超过1分钟,所以我们需要把MP3之类的音频文件切成一段一段的,然后提交给百度语音识别。
寻找工具或代码
切分语音不难,问题在于怎么能不把一句话切成两半,或者一个词或字切成两半。
本身不是科班出身,也没做过语音处理,不知道是搜的不对还是什么,搜索语音分割这几个字,就没找到太合适东西。
1、百度文档里面提到的 speech-vad-demo在win上配好了环境,报错:pthread.h: No such file or dire ctory,检索了一下大概是这个是linux环境才能提供的东西,没去研究怎么配。
2、找到个pyAudioAnalysis 报错 'ascii' codec can't decode byte 0xef
3、找到个py_speech_seg 跑默认例子还行,但实际用的时候,效果就不太好了,可能是不太会用。
音频这个东西,看波形都能看出来有没有声音,只是简单的按照有没有声音切分,应该是比较容易的东西,怎么网上都没有教程呢?直到找到了这篇文章,作者讲解了一下python的pydub库分割语音的方法,这才终于是找到了。
正文:按语音停顿切分
直接用pydub库,实现拆分的核心就是这一行代码:
这里silence_thresh是认定小于-70dBFS以下的为silence,发现小于-70dBFS部分超过 700毫秒,就进行拆分。
from pydub.silence import split_on_silence
chunks = split_on_silence(sound,min_silence_len=700,silence_thresh=-70)
2019-5-7补充下面一段代码。。
如果想要具体测试一下split_on_silence效果的,可以用以下代码:
自行调整参数测试分割效果。
from pydub import AudioSegment
from pydub.silence import split_on_silence
import os
# 初始化
audiopath = "C:/Users/L/Desktop/test/test.mp3"
audiotype = 'mp3' #如果wav、mp4其他格式参看pydub.AudioSegment的API
# 读入音频
print('读入音频')
sound = AudioSegment.from_file(audiopath, format=audiotype)
sound = sound[:3*60*1000] #如果文件较大,先取前3分钟测试,根据测试结果,调整参数
# 分割
print('开始分割')
chunks = split_on_silence(sound,min_silence_len=300,silence_thresh=-70)#min_silence_len: 拆分语句时,静默满0.3秒则拆分。silence_thresh:小于-70dBFS以下的为静默。
# 创建保存目录
filepath = os.path.split(audiopath)[0]
chunks_path = filepath+'/chunks/'
if not os.path.exists(chunks_path):os.mkdir(chunks_path)
# 保存所有分段
print('开始保存')
for i in range(len(chunks)):
new = chunks[i]
save_name = chunks_path+'%04d.%s'%(i,audiotype)
new.export(save_name, format=audiotype)
print('%04d'%i,len(new))
print('保存完毕')
这样可以快速对分割效果进行测试,并得出结论。
读入音频
开始分割
开始保存
0000 110
0001 7880
0002 17912
0003 152607
保存完毕
[Finished in 14.5s]
================================================================
至于下面这么长的代码,是针对百度语音识别写的,
按句拆分,尽量拆成接近1分钟的文件,后续用于识别。具体都在注释里。
为了测试,找了个讲座视频,长度30分钟左右,语音比较清晰,语速也适中的,转成wav格式,拿来测试。
2019-12-21 这两天想快速过一遍某个长达1个月的视频教程,就又用到了这个代码。结果发现chunk_split_length_limit这个函数之前写的太乱,自己看着都费劲,于是重写了一下这个函数并加了标注。
from pydub import AudioSegment
from pydub.silence import split_on_silence
import sys
import os
def main():
# 载入
name = '1.wav'
sound = AudioSegment.from_wav(name)
#sound = sound[:3*60*1000] # 如果文件较大,先取前3分钟测试,根据测试结果,调整参数
# 设置参数
silence_thresh=-70 # 小于-70dBFS以下的为静默
min_silence_len=700 # 静默超过700毫秒则拆分
length_limit=60*1000 # 拆分后每段不得超过1分钟
abandon_chunk_len=500 # 放弃小于500毫秒的段
joint_silence_len=1300 # 段拼接时加入1300毫秒间隔用于断句
# 将录音文件拆分成适合百度语音识别的大小
total = prepare_for_baiduaip(name,sound,silence_thresh,min_silence_len,length_limit,abandon_chunk_len,joint_silence_len)
def prepare_for_baiduaip(name,sound,silence_thresh=-70,min_silence_len=700,length_limit=60*1000,abandon_chunk_len=500,joint_silence_len=1300):
'''
将录音文件拆分成适合百度语音识别的大小
百度目前免费提供1分钟长度的语音识别。
先按参数拆分录音,拆出来的每一段都小于1分钟。
然后将,时间过短的相邻段合并,合并后依旧不长于1分钟。
Args:
name: 录音文件名
sound: 录音文件数据
silence_thresh: 默认-70 # 小于-70dBFS以下的为静默
min_silence_len: 默认700 # 静默超过700毫秒则拆分
length_limit: 默认60*1000 # 拆分后每段不得超过1分钟
abandon_chunk_len: 默认500 # 放弃小于500毫秒的段
joint_silence_len: 默认1300 # 段拼接时加入1300毫秒间隔用于断句
Return:
total:返回拆分个数
'''
# 按句子停顿,拆分成长度不大于1分钟录音片段
print('开始拆分(如果录音较长,请耐心等待)\n',' *'*30)
chunks = chunk_split_length_limit(sound,min_silence_len=min_silence_len,length_limit=length_limit,silence_thresh=silence_thresh)#silence time:700ms and silence_dBFS<-70dBFS
print('拆分结束,返回段数:',len(chunks),'\n',' *'*30)
# 放弃长度小于0.5秒的录音片段
for i in list(range(len(chunks)))[::-1]:
if len(chunks[i])<=abandon_chunk_len:
chunks.pop(i)
print('取有效分段:',len(chunks))
# 时间过短的相邻段合并,单段不超过1分钟
chunks = chunk_join_length_limit(chunks,joint_silence_len=joint_silence_len,length_limit=length_limit)
print('合并后段数:',len(chunks))
# 保存前处理一下路径文件名
if not os.path.exists('./chunks'):os.mkdir('./chunks')
namef,namec = os.path.splitext(name)
namec = namec[1:]
# 保存所有分段
total = len(chunks)
for i in range(total):
new = chunks[i]
save_name = '%s_%04d.%s'%(namef,i,namec)
new.export('./chunks/'+save_name, format=namec)
# print('%04d'%i,len(new))
print('保存完毕')
return total
def chunk_split_length_limit(chunk,min_silence_len=700,length_limit=60*1000,silence_thresh=-70):
'''
将声音文件按正常语句停顿拆分,并限定单句最长时间,返回结果为列表形式
Args:
chunk: 录音文件
min_silence_len: 拆分语句时,静默满足该长度,则拆分,默认0.7秒。
length_limit:拆分后单个文件长度不超过该值,默认1分钟。
silence_thresh:小于-70dBFS以下的为静默
Return:
done_chunks:拆分后的列表
'''
todo_arr = [] #待处理
done_chunks =[] #处理完
todo_arr.append([chunk,min_silence_len,silence_thresh])
while len(todo_arr)>0:
# 载入一个音频
temp_chunk,temp_msl,temp_st = todo_arr.pop(0)
# 不超长的,算是拆分成功
if len(temp_chunk)<length_limit:
done_chunks.append(temp_chunk)
else:
# 超长的,准备处理
# 配置参数
if temp_msl>100: # 优先缩小静默判断时常
temp_msl-=100
elif temp_st<-10: # 提升认为是静默的分贝数
temp_st+=10
else:
# 提升到极致还是不行的,输出异常
tempname = 'temp_%d.wav'%int(time.time())
chunk.export(tempname, format='wav')
print('万策尽。音长%d,静长%d分贝%d依旧超长,片段已保存至%s'%(len(temp_chunk),temp_msl,temp_st,tempname))
raise Exception
# 输出本次执行的拆分,所使用的参数
msg = '拆分中 音长,剩余[静长,分贝]:%d,%d[%d,%d]'%(len(temp_chunk),len(todo_arr),temp_msl,temp_st)
print(msg)
# 拆分
temp_chunks = split_on_silence(temp_chunk,min_silence_len=temp_msl,silence_thresh=temp_st)
# 拆分结果处理
doning_arr = [[c,temp_msl,temp_st] for c in temp_chunks]
todo_arr = doning_arr+todo_arr
return done_chunks
def chunk_join_length_limit(chunks,joint_silence_len=1300,length_limit=60*1000):
'''
将声音文件合并,并限定单句最长时间,返回结果为列表形式
Args:
chunk: 录音文件
joint_silence_len: 合并时文件间隔,默认1.3秒。
length_limit:合并后单个文件长度不超过该值,默认1分钟。
Return:
adjust_chunks:合并后的列表
'''
#
silence = AudioSegment.silent(duration=joint_silence_len)
adjust_chunks=[]
temp = AudioSegment.empty()
for chunk in chunks:
length = len(temp)+len(silence)+len(chunk) # 预计合并后长度
if length<length_limit: # 小于1分钟,可以合并
temp+=silence+chunk
else: # 大于1分钟,先将之前的保存,重新开始累加
adjust_chunks.append(temp)
temp=chunk
else:
adjust_chunks.append(temp)
return adjust_chunks
if __name__ == '__main__':
main()
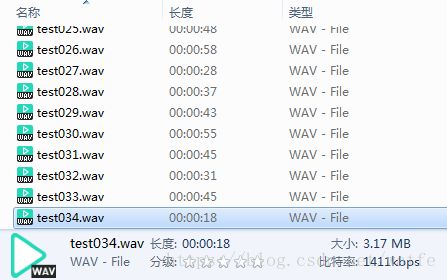
跑了一下效率有点低用了6分钟,6分钟才分割完,也许是拿来处理的文件比特率太高了?
听了一下分割的基本还可以。
百度语音识别
把 wav 语音都用 ffmpeg 转码成 pcm 的。
ffmpeg 这么好的东西,每当转换的时候,首先就应该想起它,处理视频转码什么的毫无压力。
后续看到百度语音识别的文档,发现推荐的也是ffmpeg。
import subprocess
# wav 文件转 16k 16bits 位深的单声道pcm文件
subprocess.call('ffmpeg -y -i 16k.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm')
然后pip install baidu-aip,安装百度语音识别的python库。
怎么用还是看这里的官方文档
创建一个应用,拿到APP_ID, API_KEY, SECRET_KEY 然后按照文档获取就行了
from aip import AipSpeech
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
sound = with open(filePath, 'rb') as fp:fp.read()
d = client.asr(sound , 'pcm', 16000, {'dev_pid': '1536',})
返回的是json,result = d['result'][0]就拿到了语音识别结果。
效果
拆出来的34个文件,识别一共用了7分钟。

识别出来的效果和我想的差不多,大致正确。随便截一段,看了一下,有的能猜出来是什么,有的就不太通顺了。如果想当笔记用,还是需要校对一下的。