Python中的并行(多进程)方法比较
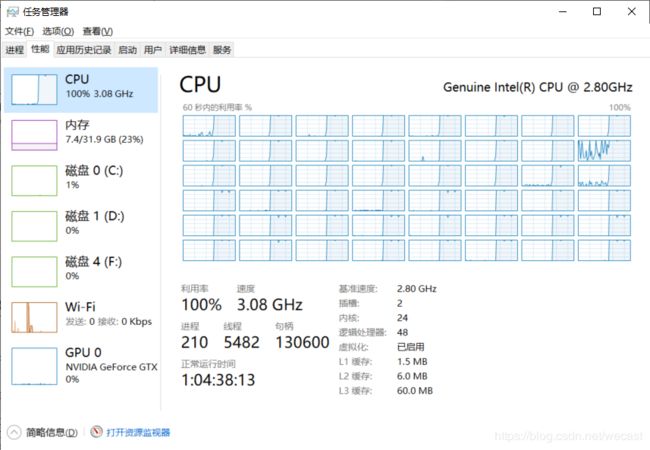
近期由于使用遗传算法,计算时间过长,观察CPU运行情况,发现基本上处于一人干活,全家围观的场景,便想着研究一下多进程并行计算,简单总结一下。
【电脑简述】
电脑类型:台式机电脑
操作系统:Windows10
CPU硬件:双路Intel至强处理器、24核48线程、主频2.8Ghz
程序运行环境:Python3.7.2、Jupyter notebook
【错误的并行打开方式】
from multiprocessing.pool import ThreadPool
from scoop import futures
from concurrent.futures import ThreadPoolExecutor
import time
def fib(n):
if n<= 2:
return 1
return fib(n-1) + fib(n-2)
#(一)
begin = time.time()
returnValues=[]
for i in range(36):
returnValues.append(fib(i))
end = time.time()
print ('a:',end-begin)
#(二)
begin = time.time()
returnValues = list(map(fib, range(36)))
end = time.time()
print ('b:',end-begin)
#(三)
begin = time.time()
returnValues = list(futures.map(fib, range(36)))
end = time.time()
print ('c:',end-begin)
#(四)
begin = time.time()
pool = ThreadPool(36)
returnValues = pool.map(fib, range(36))
end = time.time()
print('d:',end-begin)
#(五)
begin = time.time()
executor=ThreadPoolExecutor(36)
returnValues = list(executor.map(fib, range(36)))
end = time.time()
print ('e:',end-begin)【运行结果】
a: 5.879765033721924
b: 5.939977407455444
c: 5.8969762325286865
d: 5.982716798782349
e: 5.974947929382324【结论】
显然运行时间并没有任何改善。
【分析】
既然网上那么多的帖子都说这些并行方法有用,再仔细观察,发现回调函数为斐波那契函数,使用了递归算法,问题有可能出在这里。
【正确的并行打开方式】from multiprocessing.pool import ThreadPool
from scoop import futures
from concurrent.futures import ThreadPoolExecutor
import time
def timekill(n):
time.sleep(0.1)
return n
#(一)
begin = time.time()
returnValues=[]
for i in range(36):
returnValues.append(timekill(i))
end = time.time()
print ('a:',end-begin)
#(二)
begin = time.time()
returnValues = list(map(timekill, range(36)))
end = time.time()
print ('b:',end-begin)
#(三)
begin = time.time()
returnValues = list(futures.map(timekill, range(36)))
end = time.time()
print ('c:',end-begin)
#(四)
begin = time.time()
pool = ThreadPool(36)
returnValues = pool.map(timekill, range(36))
end = time.time()
print('d:',end-begin)
#(五)
begin = time.time()
executor=ThreadPoolExecutor(36)
returnValues = list(executor.map(timekill, range(36)))
end = time.time()
print ('e:',end-begin)【运行结果】a: 3.921525478363037
b: 3.9089832305908203
c: 3.892822504043579
d: 0.12189888954162598
e: 0.13081955909729004
【结论】
并行效果显著,运行时间约降低为非并行运算的1/36。但若将线程池的数量改为35,则运行时间加倍。
multiprocessing和concurrent的并行算法好使,scoop不好使。(也有可能用法不对,以后再研究)
另外,python并发的回调函数不能使用递归算法!!!
【并行在遗传算法中的运用】
使用Deap模块,加上multiprocessing并行模块后,进行某段最优特征组合筛选,耗时从180s降到了64s,提升效果明显。