爬取新浪微博用户信息及微博内容并进行可视化分析
参考博文:https://blog.csdn.net/asher117/article/details/82793091
主要代码如下图
from selenium import webdriver
from pyecharts.charts import PictorialBar
from pyecharts.charts import Line
from opdata.opexcel import Operatingexcel
from bs4 import BeautifulSoup
import time
import Draw as draw
import re
from pyecharts import options as opts
from collections import Counter
import jieba.posseg as psg
from snownlp import SnowNLP
# browser = webdriver.Chrome()
# #给定登陆的网址
# url = 'https://passport.weibo.cn/signin/login'
# browser.get(url)
# time.sleep(3)
def login():
print(u'登陆新浪微博手机端...')
# 找到输入用户名的地方,并将用户名里面的内容清空,然后送入你的账号
username = browser.find_element_by_css_selector('#loginName')
time.sleep(2)
username.clear()
username.send_keys('输入自己的账号') # 输入自己的账号
# 找到输入密码的地方,然后送入你的密码
password = browser.find_element_by_css_selector('#loginPassword')
time.sleep(2)
password.send_keys('输入自己的密码')
# 点击登录
browser.find_element_by_css_selector('#loginAction').click()
##这里给个15秒非常重要,因为在点击登录之后,新浪微博会有个九宫格验证码,下图有,通过程序执行的话会有点麻烦(可以参考崔庆才的Python书里面有解决方法),这里就手动
time.sleep(15)
print('完成登陆!')
def get_info():
dic_info={}
id = 'dengchao'
niCheng = id
# 用户的url结构为 url = 'http://weibo.cn/' + id
url = 'http://weibo.cn/' + id
browser.get(url)
time.sleep(3)
# 使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
# 爬取商户的uid信息
uid = soup.find('td', attrs={'valign': 'top'})
uid = uid.a['href']
uid = uid.split('/')[1]
# 爬取最大页码数目
pageSize = soup.find('div', attrs={'id': 'pagelist'})
pageSize = pageSize.find('div').getText()
pageSize = (pageSize.split('/')[1]).split('页')[0]
# 爬取微博数量
divMessage = soup.find('div', attrs={'class': 'tip2'})
weiBoCount = divMessage.find('span').getText()
weiBoCount = (weiBoCount.split('[')[1]).replace(']', '')
# 爬取关注数量和粉丝数量
a = divMessage.find_all('a')[:2]
guanZhuCount = (a[0].getText().split('[')[1]).replace(']', '')
fenSiCount = (a[1].getText().split('[')[1]).replace(']', '')
dic_info.setdefault("微博总数",weiBoCount)
dic_info.setdefault("微博关注", guanZhuCount)
dic_info.setdefault("微博粉丝", fenSiCount)
contents=[]
dianZans=[]
zhuanFas=[]
pinLuns=[]
faBuTimes=[]
yuanChuangs=[]
# 通过循环来抓取每一页数据
# int(pageSize) + 1
for i in range(1, 10): # pageSize+1
# 每一页数据的url结构为 url = 'http://weibo.cn/' + id + ‘?page=’ + i
url = 'https://weibo.cn/dengchao?page=' + str(i)
browser.get(url)
time.sleep(1)
# 使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
body = soup.find('body')
divss = body.find_all('div', attrs={'class': 'c'})[1:-2]
for divs in divss:
# yuanChuang : 0表示转发,1表示原创
yuanChuang = '1' # 初始值为原创,当非原创时,更改此值
div = divs.find_all('div')
# 这里有三种情况,两种为原创,一种为转发
if (len(div) == 2): # 原创,有图
# 爬取微博内容
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[1].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
# 爬取点赞数
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
# 爬取转发数
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
# 爬取评论数目
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
# 爬取微博来源和时间
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
contents.append(content)
dianZans.append(dianZan)
zhuanFas.append(zhuanFa)
pinLuns.append(pinLun)
faBuTimes.append(faBuTime)
yuanChuangs.append(yuanChuang)
# 和上面一样
elif (len(div) == 1): # 原创,无图
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[0].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
contents.append(content)
dianZans.append(dianZan)
zhuanFas.append(zhuanFa)
pinLuns.append(pinLun)
faBuTimes.append(faBuTime)
yuanChuangs.append(yuanChuang)
# 这里为转发,其他和上面一样
elif (len(div) == 3): # 转发的微博
yuanChuang = '0'
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[2].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
contents.append(content)
dianZans.append(dianZan)
zhuanFas.append(zhuanFa)
pinLuns.append(pinLun)
faBuTimes.append(faBuTime)
yuanChuangs.append(yuanChuang)
dic_info.setdefault("内容", contents)
dic_info.setdefault("点赞", dianZans)
dic_info.setdefault("转发", zhuanFas)
dic_info.setdefault("评论", pinLuns)
dic_info.setdefault("时间", faBuTimes)
dic_info.setdefault("原创", yuanChuangs)
time.sleep(2)
# print(i)
return dic_info
# 存入txt文件
def writetxt(jjrw, result):
with open(jjrw, 'w+',encoding="utf-8") as r:
for i in range(len(result)):
if result[i] != "":
s = str(result[i]).strip().replace("emoji", "").replace("span", "").replace("class", "").replace("#","").replace("http","")
rec = re.compile("1f\d+\w*|[<>/=]|\r|\n|")
s = rec.sub("", s)
r.write(s+"\n")
def count(seg_list1):
# 计数
count = Counter(seg_list1)
# 字典排序
result = sorted(count.items(), key=lambda x: x[1], reverse=True)
return result
# 读取文件并进行分词排序
def readjieba(text,excludes,list_replace):
dic_result = {}
seg_list1 = []
nr=[]
ns=[]
# 分词
seg_list = psg.cut(text)
for w, t in seg_list:
# 去除停用词
if len(w) != 1 and t != 'm' and w not in excludes:
# 替换词
for j in list_replace:
if w == j[0]:
real_word == j[1]
else:
real_word = w
if t == 'nr':
nr.append("{0}".format(real_word))
if t=='ns':
ns.append("{0}".format(real_word))
seg_list1.append("{0}".format(real_word))
dic_result.setdefault("全部", count(seg_list1))
dic_result.setdefault("人名", count(nr))
dic_result.setdefault("地名", count(ns))
return dic_result
# 趋势图
def drawline(arrt,value,value1,value2,name):
# 图表初始化配置
init_opts = opts.InitOpts(page_title=name)
line = Line(init_opts=init_opts)
# 标题配置
title = opts.TitleOpts(title=name,
pos_left="10%")
# 图例配置
legend_opts = opts.LegendOpts(orient="horizontal",
pos_top="5%",
pos_right="15%")
# 工具箱配置
# feature = opts.ToolBoxFeatureOpts(save_as_image=True, restore=True, data_view=True, data_zoom=True)
# 工具箱配置
toolbox_opts = opts.ToolboxOpts(orient="vertical",
pos_bottom="15%",
pos_left="90%",
)
line.set_global_opts(title_opts=title,
legend_opts=legend_opts,
toolbox_opts=toolbox_opts,
datazoom_opts = opts.DataZoomOpts(orient="vertical"),
)
line.add_xaxis(arrt, )
line.add_yaxis("点赞", value, is_smooth=True, linestyle_opts=opts.LineStyleOpts(color="#E83132", width="4"))
line.add_yaxis("评论", value1, is_smooth=True, linestyle_opts=opts.LineStyleOpts(color="#00FFFF ", width="4"))
line.add_yaxis("转发", value2, is_smooth=True, linestyle_opts=opts.LineStyleOpts(color="#7CFC00", width="4"))
line.render('{0}.html'.format(name))
def drawPictorialBar(location,values,name):
c = (
PictorialBar()
.add_xaxis(location)
.add_yaxis(
"",
values,
label_opts=opts.LabelOpts(is_show=False),
symbol_size=22,
symbol_repeat="10000",
symbol_offset=[0, -5],
is_symbol_clip=True,
# symbol='image://https://github.githubassets.com/images/spinners/octocat-spinner-32.gif'
symbol='image://http://weizhendong.top/images/1.png'
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title=name),
xaxis_opts=opts.AxisOpts(is_show=False),
yaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(opacity=0)
),
),
)
.render("{0}.html".format(name))
)
def read_snowNLP(filename):
snow_list = []
a=0
b=0
c=0
with open(filename, "r", encoding='utf-8') as f:
for line in f.readlines():
if line != "":
s = SnowNLP(line)
if s.sentiments > 0.5:
snow_list.append("{0}——褒义".format(line))
a+=1
elif s.sentiments < 0.5:
snow_list.append("{0}——贬义".format(line))
b += 1
else:
snow_list.append("{0}——中性".format(line))
c+=1
return snow_list,a,b,c
if __name__ == '__main__':
# 登录
# login()
# 获取信息
# dic_info=get_info()
# print(dic_info)
ol = Operatingexcel()
# 存储到excel
# ol.set_excel_dic(dic_info, "data\csdn_data.xlsx", 0, 0)
dics = ol.get_excel_dic("data\csdn_data.xlsx", "大学排名")
# print(dics)
"""绘制饼图"""
# yuanchuang = dict()
# for f in dics["原创"]:
# if f == '1':
# yuanchuang["原创"] = yuanchuang.get("原创", 0) + 1
# elif f == '0':
# yuanchuang["非原创"] = yuanchuang.get("非原创", 0) + 1
# attr = ['原创', '非原创']
# value = [yuanchuang["原创"], yuanchuang["非原创"]]
# draw.drawpie(attr,value,"data/原创和非原创饼图")
"""绘制词云"""
excludes = {'将军', '却说', '令人', '赶来', '徐州', '不见', '下马', '喊声', '因此', '未知', '大败', '百姓', '大事', '一军', '之后', '接应', '起兵',
'成都', '原来', '江东', '正是', '忽然', '原来', '大叫', '上马', '天子', '一面', '太守', '不如', '忽报', '后人', '背后', '先主', '此人',
'城中', '然后', '大军', '何不', '先生', '何故', '夫人', '不如', '先锋', '二人', '不可', '如何', '荆州', '不能', '如此', '主公', '军士',
'商议', '引兵', '次日', '大喜', '魏兵', '军马', '于是', '东吴', '今日', '左右', '天下', '不敢', '陛下', '人马', '不知', '都督', '汉中',
'一人', '众将', '后主', '只见', '蜀兵', '马军', '黄巾', '立功', '白发', '大吉', '红旗', '士卒', '钱粮', '于汉', '郎舅', '龙凤', '古之',
'白虎', '古人云', '尔乃', '马飞报', '轩昂', '史官', '侍臣', '列阵', '玉玺', '车驾', '老夫', '伏兵', '都尉', '侍中', '西凉', '安民', '张曰',
'文武',
'白旗',
'祖宗', '寻思','英雄','赞美','乳牙'} # 排除的词汇
key = "玄德曰"
value = "刘备"
list_replace = []
list_replace.append(tuple((key, value)))
writetxt("内容.txt", dics["内容"])
with open('内容.txt', 'r', encoding='utf-8') as f:
text = f.read()
dic_result = readjieba(text,excludes,list_replace)
draw.drawWordCloud(dic_result["全部"], "data/微博内容词云")
draw.drawWordCloud(dic_result["地名"], "data/微博地点词云")
draw.drawWordCloud(dic_result["人名"], "data/微博人名词云")
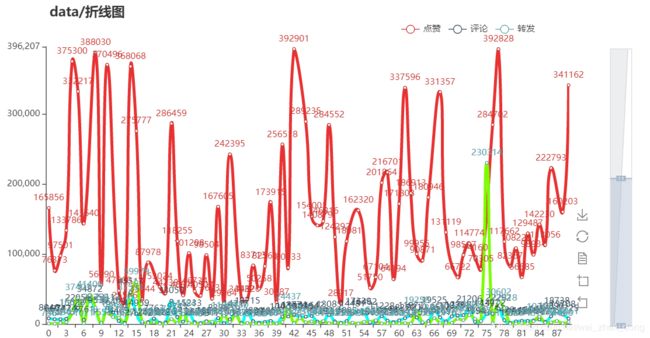
"""绘制折线图"""
# arrt = [x for x in range(len(dics["评论"]))]
# drawline(arrt, dics["点赞"], dics["评论"], dics["转发"], "data/折线图")
"""点赞象形图"""
# drawPictorialBar(arrt,dics["评论"], "data/点赞象形图")
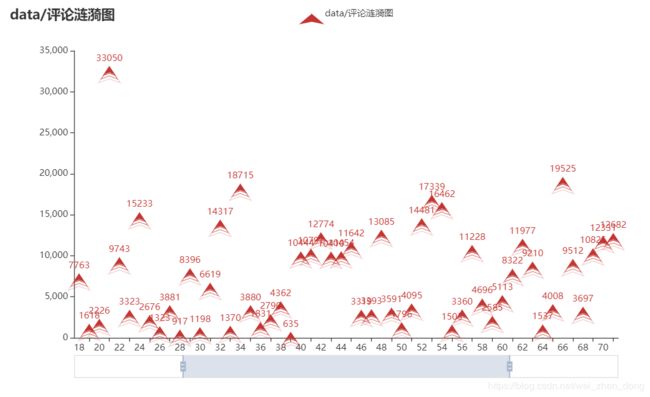
"""评论涟漪图"""
# draw.drawEffectScatter(arrt, dics["评论"],"data/评论涟漪图")
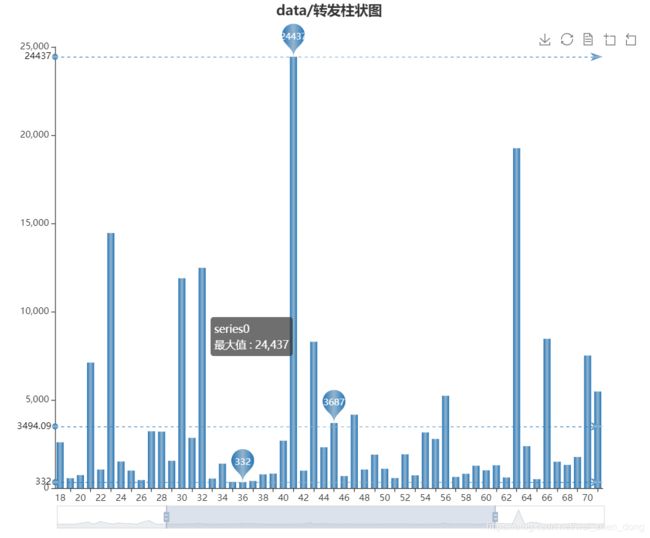
"""转发柱状图"""
# draw.drawbar(arrt, dics["转发"], "data/转发柱状图")
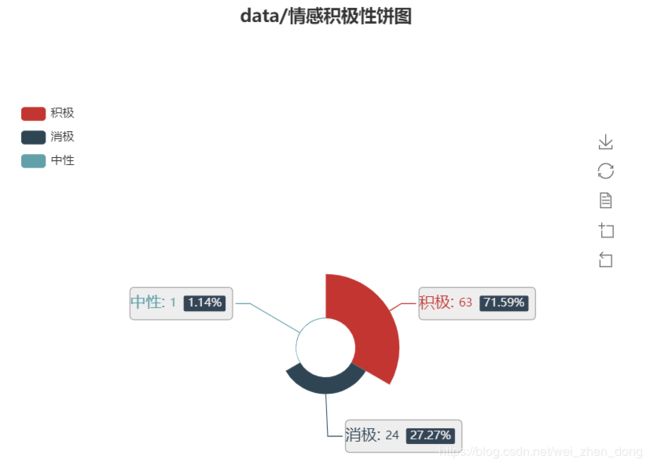
"""微博情感极性"""
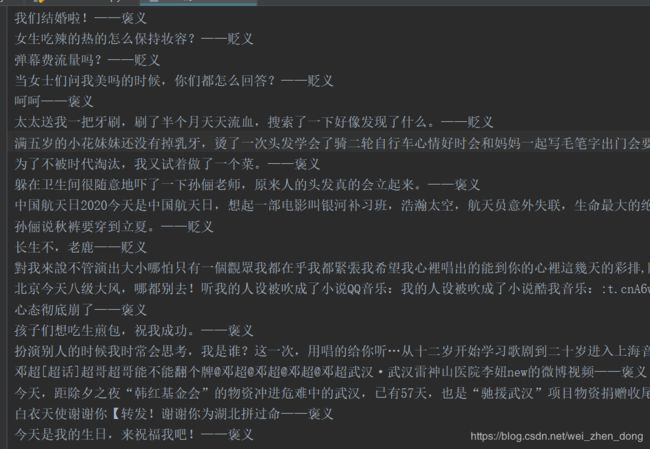
snow_list,a,b,c = read_snowNLP("内容.txt")
# 保存到txt文件中
writetxt("data/微博情感极性.txt", snow_list)
"""绘制饼状图"""
attr = ['积极', '消极',"中性"]
value = [a, b,c]
draw.drawpie(attr,value,"data/情感积极性饼图")
Draw .py : https://blog.csdn.net/wei_zhen_dong/article/details/106300719
opdata.py :https://blog.csdn.net/wei_zhen_dong/article/details/105318970