Ensemble Learning and Random Forests
Notes and codes from Hands-on ml using sklearn and tensorflow --chapter 7
集成学习(ensemble learning):
将一群预测模型放到一起称谓集成,这种技术称为集成次学习。
集成方法(ensemble method):
bagging,boosting,stacking 等。
常见的分类器:
逻辑回归,支持向量机,随机森林,KNN。

一个简单的更好的分类器是将这个分类器放到一起进行分类预测,采用投票表决的方法进行分类决定。(a hard voting classifier) 尽管每一个单独的分类器可能预测能力并不好(weak learner),但是通过集成之后,总体上的分类器可能是一个好的分类器(strong learner)。
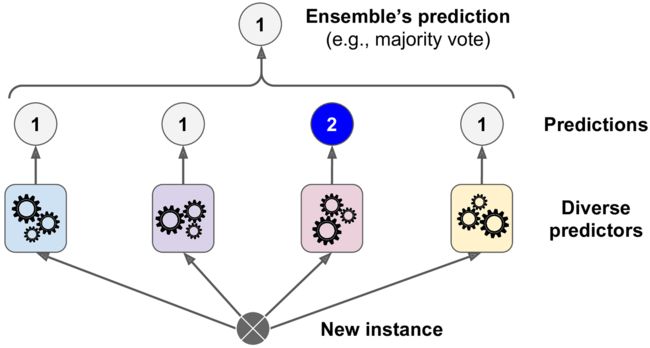
集成方法表现很好的一个前提是:每个predictor都区别于其他的,那么可以在训练时候使用不同的算法,保持这个diversity。
投票分类器
from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split X, y = make_moons(n_samples=500, noise=0.30, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf=LogisticRegression()
rnd_clf=RandomForestClassifier()
svm_clf=SVC()
voting_clf=VotingClassifier(estimators=[("lr",log_clf),("rf",rnd_clf),("svc",svm_clf)],voting="hard")
voting_clf.fit(X_train,y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf,rnd_clf,svm_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
从上面结果看出来,集成学习表现还不错。(我这跑出来的结果和书本不一样,书本结果集成学习是最好的。)
要是每个分类器都能预测类别的概率,再取平均概率,这样得到的分类结果,称为 soft voting。
summary:投票分类器分成两种,hard voting -soft voting。hard voting 直接给出分类结果,按多数表决。soft voting 算出分类的概率,再根据平均概率最高的来分类。
Bagging and Pasting
两种方法保持集成学习模型表现好:
- 使用不同的分类模型构成集成学习模型,像上面提到的使用逻辑回归,支持向量机,随机森林构成集成的分类器模型;
- 使用相同的模型,但是训练模型的数据要随机要不同;
bagging&pasting定义及异同:
- 当样本有放回的抽取,这种方法叫做bagging。(bootstrap aggregating的简称)
- 当样本无放回的抽取,这种方法叫做pasting。
- bagging&pasting抽取样本方法都可以用在由不同模型构成的集成学习模型中。
- 只要bagging抽样适合于由相同模型构成的集成学习模型。

from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier bag_clf=BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,max_samples=100,bootstrap=True,n_jobs=-1) bag_clf.fit(X_train,y_train) y_pred=bag_clf.predict(X_test)
Out-of-Bag Evaluation(oob)
因为训练模型不会看到oob样本在训练的时候,所以训练模型同时可以通过oob样本来评估。这样在bagging训练模型的时候,不需要单独把数据分成验证集进行交叉验证。
from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split X, y = make_moons(n_samples=500, noise=0.30, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier bag_clf=BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,oob_score=True,bootstrap=True,n_jobs=-1) bag_clf.fit(X_train,y_train) y_pred=bag_clf.predict(X_test) bag_clf.oob_score_
from sklearn.metrics import accuracy_score
y_pred=bag_clf.predict(X_test)
accuracy_score(y_test,y_pred)
0.904
summary:
- 集成学习中两种抽取样本的方法:bagging and pasting。对于集成模型中,模型不变的情况下,只能使用bagging。
- bagging抽样方法中,有些样本可能会被抽中很多遍,但是有些样本或许一次也不会抽中。因此总有一部分比较多样本是不会被抽到的,称为“out-of-bag evaluation”。这部分样本可以用来作为验证集。
Random Forests
随机森林就是一种典型的集成学习模型。采用bagging抽样思想,在sklearn中有专门的API.
from sklearn.ensemble import RandomForestClassifier rnd_clf=RandomForestClassifier(n_estimators=500,max_leaf_nodes=16,n_jobs=-1) rnd_clf.fit(X_train,y_train) y_pred_rf=rnd_clf.predict(X_test)
Feature Importance
sklearn可以计算每个特征在不同树中的深度,越靠近根结点的特征重要性越大。
from sklearn.datasets import load_iris iris=load_iris() rnd_clf=RandomForestClassifier(n_estimators=500,n_jobs=-1) rnd_clf.fit(iris["data"],iris["target"]) for name,score in zip(iris["feature_names"],rnd_clf.feature_importances_): print(name,score) sepal length (cm) 0.113499587893 sepal width (cm) 0.0241249316785 petal length (cm) 0.416398067855 petal width (cm) 0.445977412574
summary: 随机森林是使用bagging思想,在sklearn中有专门的API,同时也能看特征重要性。
Boosting (hypothesis boosting)
the general idea of most boosting methods is to train predictors sequentially,each trying to correct its predecessor.(有序的训练模型,不断改变之前的模型)
在boosting技术里面最常用的是AdaBoosting (Adaptive Boosting) 和 Gradient Boosting。
AdaBoosting

不断更新之前模型分类不正确的权重,不断的像集成模型中添加模型,逐渐使模型更好。
all the predictors have different weights depending on their overal accurancy on the weighted training set。
注意:按顺讯学习模型有一个缺点:这个过程不能并行处理,因为每个predictor只能根据上一个predictor的表现进行训练,结果就是不能像bagging或者pasting那样并行计算。
一个新的predictor是通过更新上一个模型的权重,错误的分类被boosted。整个过程都在repeat更新权重,知道一个完美的predictor产生或者predictor数量达到了。
对于二分类,用AdaBoost.多分类,用SAMME(Stagewise additive modeling using multiclass exponential loss function)。
from sklearn.ensemble import AdaBoostClassifier ada_clf=AdaBoostClassifier(DecisionTreeClassifier(max_depth=1) ,n_estimators=200,algorithm="SAMME.R",learning_rate=0.5) ada_clf.fit(X_train,y_train)
如果AdaBoost ensemble 过拟合了,那么可以尝试减少estimator个数,或者对模型使用正则化。
summary:adaboost ensemble 是不断更新之前模型的权重,不断修正模型,增加模型。
Gradient Boosting
just like adaboost,gradient boosting works by sequentially adding predictors to an ensemble,each one correcting its predecessor.
However, instead of tweaking the instance weights at every iteration like AdaBoost does,this method tries to fit the new predictor to the residual errors by the previous predictor。
tree_reg1=DecisionTreeRegressor(max_depth=2) tree_reg1.fit(X,y) y2=y-tree_reg1.predict(X) tree_reg2=DecisionTreeRegressor(max_depth=2) tree_reg2.fit(X,y2) y3=y2-tree_reg2.predict(X) tree_reg3=DecisionTreeRegressor(max_depth=2) tree_reg3.fit(X,y3) y_pred=sum(tree.predict(X_new) for tree in (tree_reg1,tree_reg2,tree_reg3))
summary: gradient boosting和adaboosting类似,都是根据前面的模型表现,按序更新模型。adaboost每次是修正权重,而gradient boosting则是根据前面模型的残差来修正模型。
Stacking (stacked generalization)
stacking也是一种集成学习方法。 stacking的思想是训练一个模型来表现“aggregation”。
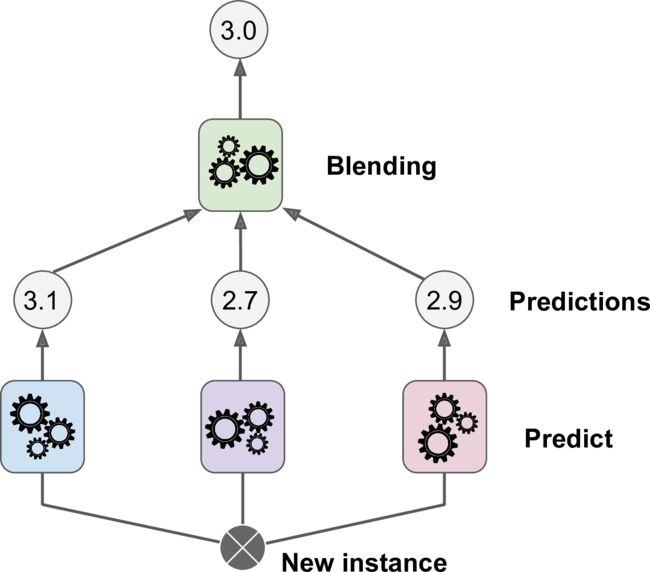
要训练blender(meta learner),可采用方法 hold-out set。
conclusion:
- 集成学习分类模型中投票机制。[hard voting and soft voting]
- 集成学习方法分类:要么用不同模型,要么用相同模型不同的训练集。
- 集成学习中sampling 抽样方法。[bagging and pasting]
- 几种集成学习思想。[AdaBoost,Gradient Boosting,Stacking]
Noted:
-
A hard voting classifier just counts the votes of each classifier in the ensemble and picks the class that gets the most votes. A soft voting classifier computes the average estimated class probability for each class and picks the class with the highest probability. This gives high-confidence votes more weight and often performs better, but it works only if every classifier is able to estimate class probabilities (e.g., for the SVM classifiers in Scikit-Learn you must set probability=True).
-
When you are growing a tree in a Random Forest, only a random subset of the features is considered for splitting at each node. This is true as well for Extra-Trees, but they go one step further: rather than searching for the best possible thresholds, like regular Decision Trees do, they use random thresholds for each feature. This extra randomness acts like a form of regularization: if a Random Forest overfits the training data, Extra-Trees might perform better. Moreover,since Extra-Trees don’t search for the best possible thresholds, they are much faster to train than Random Forests. However, they are neither faster nor slower than Random Forests when making predictions.