引言
一直对AI有着莫大的兴趣,最近买了周志华先生的西瓜书,也是干货满满,最近也想从实战方面入手,了解一下机器学习,本文以《Python机器学习基础教程》为指导。
环境
Sublimetext 3 和 Jupter Notebook;
ML库:scikit-learn
项目:鸢尾花分类
已知,鸢尾花可以被分为setosa、versicolor、virginica三个品种,现在我们要建立一个模型,输入特定数据判定它是属于哪一类。
一、数据集导入:
数据集在scikit-learn的datasets中,调用load_iris()导入:
from sklearn.datasets import load_iris
iris_dataset=load_iris()二、训练集和测试集
导入的数据集我们要分为训练集和测试集,一般我们采用3:1的随机分配办法;
而拆分时为了数据分布均匀,我们先要对数据进行随机达伦,确保测试数据和训练数据的全面性;
在scikit-learn中,我们可以调用train_test_split函数实现划分,利用random_state指定随机数生成种子即可。
X_train, X_test, y_train,y_test=train_test_split(iris_dataset['data'],
iris_dataset['target'],random_state=0)三、数据观察
数据的好坏直接影响你模型构建成功与否,现实中我们的数据可能存在许多问题(单位不统一,部分数据缺失等),所以我们要提前观察下数据集,观察最好的方法就是看图,pandas为我们提供了一个绘制散点图矩阵的函数,叫做scatter_matrix。
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names)
grr=pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker="o",hist_kwds={'bins':20},s=60,alpha=.8,cmap=mglearn.cm3)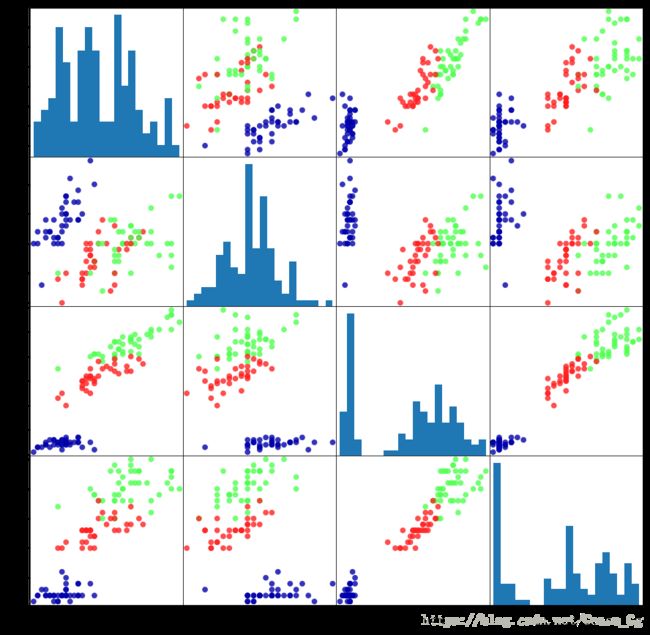
四、构建模型
算法:K近邻算法
scikit-learn中所有的机器学习模型都在各自的类中实现,统称为Estimator类。
K近邻算法是在neighbours模块中的KNeighboursClassifier类中实现,我们设置邻居参数为1。
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=1)因为knn对算法进行了封装,既包括构建模型的算法,也包括预测的算法,我们只需要调用fit方法来训练数据即可。
knn.fit(X_train,y_train)五、训练模型评估
我们训练完一个模型,这个模型是否值得我们信任?这时我们就要用测试集去测试这个模型的准确度。
y_pred=knn.predict(X_test)
print("Test set predictions:\n{}".format(y_pred))
print("Test set score:{:.2f}".format(knn.score(X_test,y_test))数据评估,我们只要将测试集的预测结果(y_pred)和测试集标签(y_test)对比,算出准确率即可。
六、预测
如果评估模型的准确率很高,那么我们就有理由相信这个模型预测地很准,所以我们可以放心去预测,反之,我们则要重新地构建一下模型。
IN:
X_new = np.array([[5,2.9,1,0.2]])
prediction = knn.predict(X_new)
print("Predicted target name:{}".format(iris_dataset['target_names'][prediction]))
OUT:
Predicted target name:['setosa']泛化、欠拟合和过拟合
泛化:即让这个模型具有普适的预测性,但拥有自己的归纳偏好,形成模型自己的“价值观”。
欠拟合:提取特征太少,事物共性提取不够,导致预测方向歪斜。
将花分类为草(错误认为绿色的都是草)
过拟合:事物特征提取过多,在共性之上加入了太多个性。
带锯齿的树叶不是树叶(错误的认为树叶必须有锯齿)
在笔者总结,泛化就是要在数据集里面最大限度找到共性,尽量忽略不能反映数据本质的个性。
欠拟合比较容易克服,例如在决策树中扩展分支,在神经网络学习中增加训练轮数等。而过拟合则很麻烦,在后面的学习中,我们将看到,过拟合是机器学习面临的关键障碍。
——《机器学习》,周志华