众所周知,莫队是由莫涛大神提出的,一种玄学毒瘤暴力骗分区间操作算法,它以简短的框架、简单易记的板子和优秀的复杂度闻名于世。然而由于莫队算法应用的毒瘤,很多可做的莫队模板题都有着较高的难度评级,令很多初学者望而却步。然而,如果你真正理解了莫队的算法原理,那么它用起来还是很简单的。当然某些套左套右的毒瘤除外
0、前置芝士:
莫队算法还是比较独立的。不过你还是得了解了解以下的一些知识:
\(1\)、分块的基本思想(开根号等)
\(2\)、STL中sort的用法(手写cmp函数或重载运算符实现结构体的多关键字排序)
\(3\)、基(du)础(liu)的卡常技巧(包含#pragma GCC optimize系列)
\(4*\)、倍增/树剖 求LCA(树上莫队所需)
\(5*\)、数值离散化(用于应付很多题目)
至此全部完毕。撒花~~(雾
诶,别走啊qwq,我可不是在劝退qwq,如果你认为自己不懂这些东西也没关系,往下看吧qwq
1、莫队算法是个啥
来历:
前面已经介绍过了(逃
有兴趣的同学可以看一下莫涛大神的知乎
然而这个算法到底是用来搞什么操作的呢?我们先看个例题:
Luogu P1972 [SDOI2009]HH的项链
题目描述
HH 有一串由各种漂亮的贝壳组成的项链。HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义。HH 不断地收集新的贝壳,因此,他的项链变得越来越长。有一天,他突然提出了一个问题:某一段贝壳中,包含了多少种不同的贝壳?这个问题很难回答……因为项链实在是太长了。于是,他只好求助睿智的你,来解决这个问题。
输入输出格式
输入格式:
第一行:一个整数N,表示项链的长度。
第二行:N 个整数,表示依次表示项链中贝壳的编号(编号为0 到1000000 之间的整数)。
第三行:一个整数M,表示HH 询问的个数。
接下来M 行:每行两个整数,L 和R(1 ≤ L ≤ R ≤ N),表示询问的区间。
输出格式:
M 行,每行一个整数,依次表示询问对应的答案。
输入输出样例
输入样例#1:
6
1 2 3 4 3 5
3
1 2
3 5
2 6输出样例#1:
2
2
4说明
数据范围:
对于100%的数据,N <= 500000,M <= 500000。
题意简明易懂:给你一个长度不大于\(n≤5×10^5\)的序列,其中数值都小于等于\(10^6\),有\(m≤5×10^5\)次询问,每次询问区间\([l,r]\)中数值个数(也就是去重后数字的个数)。
不过这个例题卡了莫队,所以请左转数据弱化版:SP3267 DQUERY - D-query
题目到手,我们开始分析本题的算法。这题最简单做法无非暴力——用一个\(cnt\)数组记录每个数值出现的次数,再暴力枚举\(l\)到\(r\)统计次数,最后再扫一遍cnt数组,统计\(cnt\)不为零的数值个数,输出答案即可。设最大数值为\(s\),那么这样做的复杂度为\(O(m(n+s))∽O(n^2)\),对于本题实在跑不起。
我们可以尝试优化一下:
优化1:每次枚举到一个数值\(num\),增加出现次数时判断一下\(cnt_{num}\)是否为0,如果为0,则这个数值之前没有出现过,现在出现了,数值数当然要+1。反之在从区间中删除\(num\)后也判断一下\(cnt_{num}\)是否为0,如果为0数值总数-1。这样我们优化掉了一个\(O(ms)\),但还是跑不起。
优化2:我们弄两个指针 \(l\) 、\(r\) ,每次询问不直接枚举,而是移动 \(l\) 、\(r\) 指针到询问的区间,直到\([l,r]\)与询问区间重合。在统计答案时,我们也只在两个指针处加减\(cnt\),然后我们就可以用优化1中的方法快速地统计答案啦\(qwq\)!
优化2具体步骤如下:
假设这个序列是这样子的:(其中\(Q1\)、\(Q2\)是询问区间)
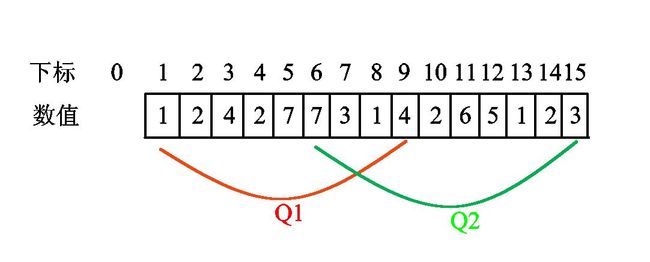
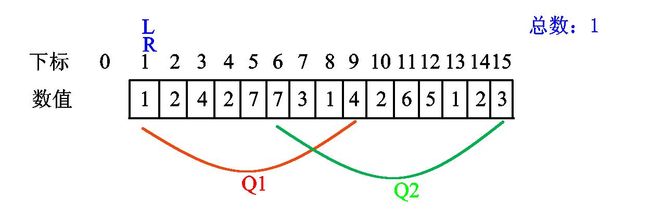
我们初始化\(l=1\)、\(r=0\)(如果\(l=0\),那么我们还需要删除一个数值\(0\),使其出现次数变成-1,导致一些奇奇怪怪错误),如下图(由于画图软件中\(l\)和\(1\)看不出区别,我只好在图中使用\(L\)和\(R\)来表示qwq):

我们发现 \(l\) 已经是第一个查询区间的左端点,无需移动。现在我们将 \(r\) 右移一位,发现新数值1:
\(r\) 继续右移,发现新数值2:
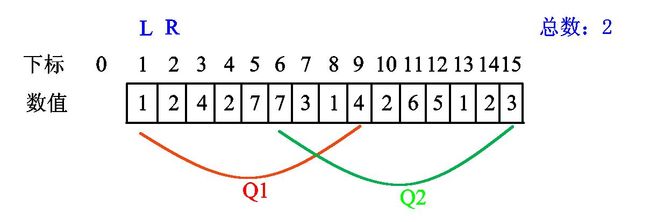
继续右移,发现新数值4:
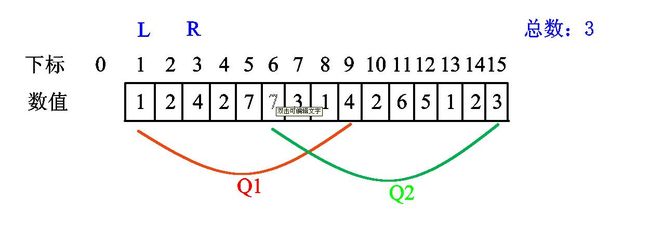
当 \(r\) 再次右移时,发现此时的新位置中的数值2出现过,数值总数不增:

接下来是两个7,由于7没出现过,所以总数+1:

继续右移发现3:

继续右移,但接下来的两个数值都出现过,总数不增。
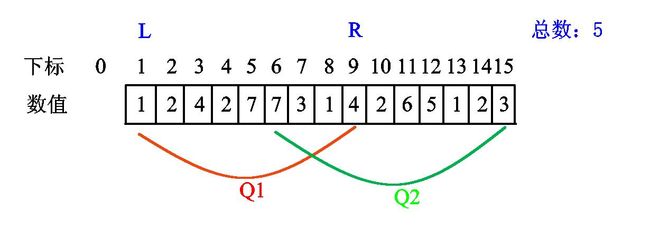
至此,\(Q1\)区间所有数值统计完成,结果为5。
现在我们又看一下\(Q2\)区间的情况:
首先我们发现, \(l\) 指针在\(Q2\)区间左端点的左边,我们需要将它右移,同时删除原位置的统计信息。
将\(l\)右移一位到位置2,删除位置1处的数值1。但由于操作后的区间中仍然有数值1存在,所以总数不减。

接下来的两位也是如此,直接删掉即可,总数不减。

当 \(l\) 指针继续右移时,发现一个问题:原位置上的数值是2,但是删除这个2后,此时的区间\([l,r]\)中再也没有2了(回顾之前的内容,这种情况就是删除后\(cnt_2 = 0\)),那么总数就要-1,因为有一个数值已经不在该区间内出现了,而本题需要统计的就是区间内的数值个数。此步骤如下图:

再右移一位,发现无需减总数,而且\(l\)已经移到了\(Q2\)区间的左端点,无需继续移下去(如下图)。当然 \(r\) 还是要移动的,只不过没图了,我相信大家应该知道做法的\(qwq\)。

\(r\)的最后位置:
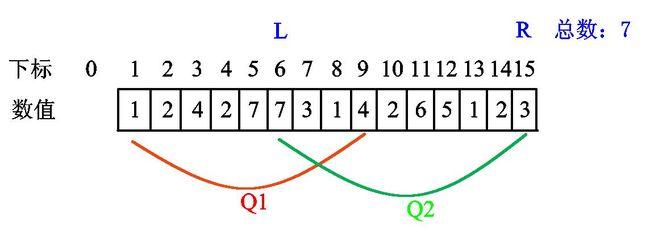
至于删除操作,也是一样的做法,只不过要先删除当前位置的数值,才能移动指针。
有了以上的内容,这段代码就可以很容易写出啦qwq:
int aa[maxn], cnt[maxn], l = 1, r = 0, now = 0; //每个位置的数值、每个数值的计数器、左指针、右指针、当前统计结果(总数)
void add(int pos) {//添加一个数
if(!cnt[aa[pos]]) ++now;//在区间中新出现,总数要+1
++cnt[aa[pos]];
}
void del(int pos) {//删除一个数
--cnt[aa[pos]];
if(!cnt[aa[pos]]) --now;//在区间中不再出现,总数要-1
}
void work() {//优化2主过程
for(int i = 1; i <= q; ++i) {//对于每次询问
int ql, qr;
scanf("%d%d", &ql, &qr);//输入询问的区间
while(l < ql) del(l++);//如左指针在查询区间左方,左指针向右移直到与查询区间左端点重合
while(l > ql) add(--l);//如左指针在查询区间左端点右方,左指针左移
while(r < qr) add(++r);//右指针在查询区间右端点左方,右指针右移
while(r > qr) del(r--);//否则左移
printf("%d\n", now);//输出统计结果
}
}优化2完结撒花✿✿ヽ(°▽°)ノ✿\(qwq\)
诶等等,什么叫做“优化2完结撒花”??!
难道这不就是莫队吗??!
我会很严肃的告诉你:这还不是莫队,但是看到这里,你已经把莫队的基础打好了。还请继续看下去:
刚刚的优化2,在普通的情况下表现很好,但是如果区间是这样:
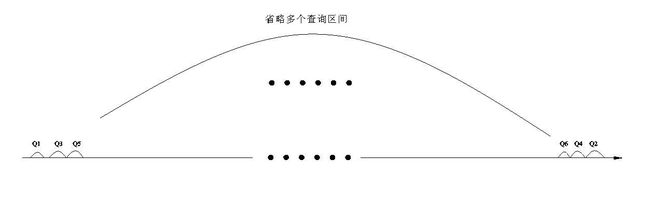
优化2基本上就萎了\(qwq\)。此时\(l\)、\(r\)指针在整个序列中移来移去,从头到尾,又从尾到头。我们发现左右指针最坏情况下均移动了\(O(nm)\)次,\(O(1)\)更新答案,总时间复杂度仍然是\(O(nm)\),在最坏情况下跑得比慢的一批的优化1还慢。尽管如此,我们还是可以继续优化。
继续优化?怎么优化?
我们可以考虑把所有查询区间按左端点排序,从而使左指针最多移动\(O(n)\)次。但这样的话右端点又是无序的,右指针又让整体复杂度打回原形。看上去,这个复杂度已经不能再优化了。在这个时候,莫队算法的出现,给无数OIer带来了光明(雾)。
至此,你可以把莫队算法理解为一种暴力,优雅而不失复杂度的暴力,只不过它的剪枝极为巧妙,达到了理想的效果。
2、莫队算法的基础实现
1、预处理
莫队算法优化的核心是分块和排序。我们将大小为\(n\)的序列分为\(\sqrt{n}\)个块,从\(1\)到\(\sqrt{n}\)编号,然后根据这个对查询区间进行排序。一种方法是把查询区间按照左端点所在块的序号排个序,如果左端点所在块相同,再按右端点排序。排完序后我们再进行左右指针跳来跳去的操作,虽然看似没多大用,但带来的优化实际上极大。
那么这样做的实际复杂度是多少呢?下面瞎胡乱搞证明它的复杂度是\(O(n\sqrt{n})\):
0.区间排序
建个结构体,用sort跑一遍即可。平均复杂度\(O(n\log n)\)。
1.左指针的移动
设每个块 \(i\) 中分布有 \(x_i\)个左端点,由于莫队的添加、删除操作复杂度为\(O(1)\),那么处理块\(i\)的最坏时间复杂度是\(O(x_i\sqrt{n})\),指针跨越整块的时间复杂度为O(\sqrt{n}),最坏需要跨越\(n\)次;总复杂度\(O(\sum x_i \sqrt{n}+n\sqrt{n})=O(n\sqrt{n})\)。
2.右指针的移动
设每个块 \(i\) 中分布有 \(x_i\)个左端点,由于左端点同块的区间右端点有序,那么对于这\(x_i\)个区间,右端点最坏只需总共\(O(n)\)的时间跳(最坏需跳完整个序列),总共\(\sqrt{n}\)个块,总复杂度\(O(n\sqrt{n})\);
至此可得出,莫队算法的总时间复杂度为\(O(n\sqrt{n}) + O(n\sqrt{n}) + O(n\log n) = O(n\sqrt{n})\)。
可见,经过一番看似鸡肋的排序之后,这个算法的复杂度猛降了一个根号之多,对于一些不需要写大常数莫队而数据范围巨大的题目来说(如例题),整整一个根号的提升意味着运行时间质的飞跃。
不过经过排序打乱原序之后,这个算法就变成了典型的离线算法,而且这种算法不支持修改。如果遇到强制在线的题目,还要另寻他法。
参考代码:
查询区间结构体的排序函数:
int cmp(query a, query b) {
return belong[a.l] == belong[b.l] ? a.r < b.r : belong[a.l] < belong[b.l];
}2、定策略
虽说莫队实质是优化后的暴力,但有时候,有些用暴力枚举很容易处理的数据用莫队并不容易处理(只能在左右指针处更新),这时候就要我们定好一个更新策略。
一般来说,我们只要找到指针移动一位以后,统计数据与当前数据的差值,找出规律(可以用数学方法或打表),然后每次移动时用这个规律更新就行啦qwq。至于例题……在后面会有哒qwq!
3、码代码与查错
莫队代码不长(或者说是很短),但很容易写错一些细节。比如自加自减运算符的优先级问题、排序关键字问题、分块大小与sqrt精度问题、还有某些题目中用到的离散化的锅。所以每次码完莫队都别先测样例(甚至可以先不编译),先静态查错一阵,真的可以帮助你大大减少错误的发生。
后面两点都特别简单但是没有特定的模式,其重要性不容小觑。
3、(重点)莫队的玄学卡常技巧
WARNING:以下内容可能引出大贤者模式,请谨慎思考。
1、#pragma GCC optimize(2)
可以用实践证明,开了O2的莫队简直跑得飞快,连\(1e6\)都能无压力跑过,甚至可以比不开O2的版本快上4~5倍乃至更多。然而部分OI比赛中O2是禁止的,如果不禁O2的话,那还是开着吧qwq
实在不行,就optimize(3)(逃
2、莫队玄学奇偶性排序
这个是最玄学的……无力吐槽
这个和莫队的主算法有异曲同工之妙……看起来卵用都没有,实际上可以帮你每个点平均优化200ms(可怕)
主要操作:把查询区间的排序函数
int cmp(query a, query b) {
return belong[a.l] == belong[b.l] ? a.r < b.r : belong[a.l] < belong[b.l];
}二话不说,直接删掉,换成
int cmp(query a, query b) {
return (belong[a.l] ^ belong[b.l]) ? belong[a.l] < belong[b.l] : ((belong[a.l] & 1) ? a.r < b.r : a.r > b.r);
}也就是说,对于左端点在同一奇数块的区间,右端点按升序排列,反之降序。这个东西也是看着没用,但实际效果显著。
它的主要原理便是右指针跳完奇数块往回跳时在同一个方向能顺路把偶数块跳完,然后跳完这个偶数块又能顺带把下一个奇数块跳完。理论上主算法运行时间减半,实际情况有所偏差。(不过能优化得很爽就对了)
3、移动指针的常数压缩
我们可以根据运算优先级的知识,把这个:
void add(int pos) {
if(!cnt[aa[pos]]) ++now;
++cnt[aa[pos]];
}
void del(int pos) {
--cnt[aa[pos]];
if(!cnt[aa[pos]]) --now;
}和这个:
while(l < ql) del(l++);
while(l > ql) add(--l);
while(r < qr) add(++r);
while(r > qr) del(r--);硬生生压缩成这个:
while(l < ql) now -= !--cnt[aa[l++]];
while(l > ql) now += !cnt[aa[--l]]++;
while(r < qr) now += !cnt[aa[++r]]++;
while(r > qr) now -= !--cnt[aa[r--]];能优化将近200ms(怎么又是这个数字)
而且这个优化看上去满满的不好搞,但实际上很有用。不过用它来优化千万要建立在熟练的基础上,不然会大大增强调试难度,不如不用。
4、手写快读、快输
大多数莫队题的输入输出量还是很大的……I/O优化与否,运行时间差异也很大。而且值得注意的是莫队经典题中基本没有输入输出负数的情况,不考虑负数又能优化一点小小的常数。
卡常部分到此结束,撒花✿✿ヽ(°▽°)ノ✿(脑补欢呼音效)
讲到现在,例题的代码已经不难写出。下面给出参考代码:
#include
#include
#include
#include
using namespace std;
#define maxn 1010000
#define maxb 1010
int aa[maxn], cnt[maxn], belong[maxn];
int n, m, size, bnum, now, ans[maxn];
struct query {
int l, r, id;
} q[maxn];
int cmp(query a, query b) {
return (belong[a.l] ^ belong[b.l]) ? belong[a.l] < belong[b.l] : ((belong[a.l] & 1) ? a.r < b.r : a.r > b.r);
}
#define isdigit(x) ((x) >= '0' && (x) <= '9')
int read() {
int res = 0;
char c = getchar();
while(!isdigit(c)) c = getchar();
while(isdigit(c)) res = (res << 1) + (res << 3) + c - 48, c = getchar();
return res;
}
void printi(int x) {
if(x / 10) printi(x / 10);
putchar(x % 10 + '0');
}
int main() {
scanf("%d", &n);
size = sqrt(n);
bnum = ceil((double)n / size);
for(int i = 1; i <= bnum; ++i)
for(int j = (i - 1) * size + 1; j <= i * size; ++j) {
belong[j] = i;
}
for(int i = 1; i <= n; ++i) aa[i] = read();
m = read();
for(int i = 1; i <= m; ++i) {
q[i].l = read(), q[i].r = read();
q[i].id = i;
}
sort(q + 1, q + m + 1, cmp);
int l = 1, r = 0;
for(int i = 1; i <= m; ++i) {
int ql = q[i].l, qr = q[i].r;
while(l < ql) now -= !--cnt[aa[l++]];
while(l > ql) now += !cnt[aa[--l]]++;
while(r < qr) now += !cnt[aa[++r]]++;
while(r > qr) now -= !--cnt[aa[r--]];
ans[q[i].id] = now;
}
for(int i = 1; i <= m; ++i) printi(ans[i]), putchar('\n');
return 0;
} 4、莫队算法的扩展——带修改的莫队
抛出个例题:Luogu P1903 [国家集训队]数颜色 / 维护队列
题目描述
墨墨购买了一套N支彩色画笔(其中有些颜色可能相同),摆成一排,你需要回答墨墨的提问。墨墨会向你发布如下指令:
1、 \(Q\) \(L\) \(R\)代表询问你从第\(L\)支画笔到第\(R\)支画笔中共有几种不同颜色的画笔。
2、 \(R\) \(P\) \(Col\) 把第\(P\)支画笔替换为颜色\(Col\)。
为了满足墨墨的要求,你知道你需要干什么了吗?
输入输出格式
输入格式:
第1行两个整数\(N\),\(M\),分别代表初始画笔的数量以及墨墨会做的事情的个数。
第2行N个整数,分别代表初始画笔排中第i支画笔的颜色。
第3行到第2+M行,每行分别代表墨墨会做的一件事情,格式见题干部分。
输出格式:
对于每一个Query的询问,你需要在对应的行中给出一个数字,代表第L支画笔到第R支画笔中共有几种不同颜色的画笔。
输入输出样例
输入样例#1:
6 5
1 2 3 4 5 5
Q 1 4
Q 2 6
R 1 2
Q 1 4
Q 2 6输出样例#1:
4
4
3
4说明
对于\(100%\)的数据,\(N≤50000\),\(M≤50000\),所有的输入数据中出现的所有整数均大于等于1且不超过\(10^6\)。
前面说过,莫队算法是离线算法,不支持修改,强制在线需要另寻他法。的确,遇到强制在线的题目莫队基本上萎了,但是对于某些允许离线的带修改区间查询来说,莫队还是能大展拳脚的。做法就是把莫队直接加上一维,变为带修莫队。
那么加上一维什么呢?具体怎么实现?我们的做法是把修改操作编号,称为"时间戳",而查询操作的时间戳沿用之前最近的修改操作的时间戳。跑主算法时定义当前时间戳为 \(t\) ,对于每个查询操作,如果当前时间戳相对太大了,说明已进行的修改操作比要求的多,就把之前改的改回来,反之往后改。只有当当前区间和查询区间左右端点、时间戳均重合时,才认定区间完全重合,此时的答案才是本次查询的最终答案。
通俗地讲,就是再弄一指针,在修改操作上跳来跳去,如果当前修改多了就改回来,改少了就改过去,直到次数恰当为止。
这样,我们当前区间的移动方向从四个(\([l-1,r]\)、\([l+1,r]\)、\([l,r-1]\)、\([l,r+1]\))变成了六个(\([l-1,r,t]\)、\([l+1,r,t]\)、\([l,r-1,t]\)、\([l,r+1,t]\)、\([l,r,t-1]\)、\([l,r,t+1]\)),但是代码并没有增加多少,还是很好背的(雾
带修改莫队的排序:
其实排序的主要方法还是跟普通莫队没两样,只不过是加了个关键字而已。
排序函数:
int cmp(query a, query b) {
return (belong[a.l] ^ belong[b.l]) ? belong[a.l] < belong[b.l] : ((belong[a.r] ^ belong[b.r]) ? belong[a.r] < belong[b.r] : a.time < b.time);
}但是实测有时排序写错还会快些。。。也许是评测机的锅吧。
主算法中的修改操作
修改操作其实也没啥值得注意的,就跟移\(l\)、\(r\)指针一样,加个对总数的特判就行了。
不过有个代码长度的小优化——移完 \(t\),做完一处修改后,有可能要改回来,所以我们还要把原值存好备用。但其实我们也可以不存,只要在修改后把修改操作的值和原值swap一下,那么改回来时也只要swap一下,swap两次相当于没搞,就改回来了\(qwq\)(所以不还是存了嘛)
分块大小和复杂度
有的\(dalao\)证明了当块的大小设\(\sqrt[3]{n^4t}\)时理论复杂度达到最优,但是小蒟蒻我并不能推出来。不过可以证明,块大小取\(n^{\frac{2}{3}}\)优于取\(\sqrt{n}\)的情况,总体复杂度\(O(n^{\frac{5}{3}})\)。而块大小取\(\sqrt{n}\)时会退化成\(O(n^2)\),不建议使用。
例题参考代码:
#include
#include
#include
#include
using namespace std;
#define maxn 50500
#define maxc 1001000
int a[maxn], cnt[maxc], ans[maxn], belong[maxn];
struct query {
int l, r, time, id;
} q[maxn];
struct modify {
int pos, color, last;
} c[maxn];
int cntq, cntc, n, m, size, bnum;
int cmp(query a, query b) {
return (belong[a.l] ^ belong[b.l]) ? belong[a.l] < belong[b.l] : ((belong[a.r] ^ belong[b.r]) ? belong[a.r] < belong[b.r] : a.time < b.time);
}
#define isdigit(x) ((x) >= '0' && (x) <= '9')
inline int read() {
int res = 0;
char c = getchar();
while(!isdigit(c)) c = getchar();
while(isdigit(c)) res = (res << 1) + (res << 3) + (c ^ 48), c = getchar();
return res;
}
int main() {
n = read(), m = read();
size = pow(n, 2.0 / 3.0);
bnum = ceil((double)n / size);
for(int i = 1; i <= bnum; ++i)
for(int j = (i - 1) * size + 1; j <= i * size; ++j) belong[j] = i;
for(int i = 1; i <= n; ++i)
a[i] = read();
for(int i = 1; i <= m; ++i) {
char opt[100];
scanf("%s", opt);
if(opt[0] == 'Q') {
q[++cntq].l = read();
q[cntq].r = read();
q[cntq].time = cntc;
q[cntq].id = cntq;
}
else if(opt[0] == 'R') {
c[++cntc].pos = read();
c[cntc].color = read();
}
}
sort(q + 1, q + cntq + 1, cmp);
int l = 1, r = 0, time = 0, now = 0;
for(int i = 1; i <= cntq; ++i) {
int ql = q[i].l, qr = q[i].r, qt = q[i].time;
while(l < ql) now -= !--cnt[a[l++]];
while(l > ql) now += !cnt[a[--l]]++;
while(r < qr) now += !cnt[a[++r]]++;
while(r > qr) now -= !--cnt[a[r--]];
while(time < qt) {
++time;
if(ql <= c[time].pos && c[time].pos <= qr) now -= !--cnt[a[c[time].pos]] - !cnt[c[time].color]++;
swap(a[c[time].pos], c[time].color);
}
while(time > qt) {
if(ql <= c[time].pos && c[time].pos <= qr) now -= !--cnt[a[c[time].pos]] - !cnt[c[time].color]++;
swap(a[c[time].pos], c[time].color);
--time;
}
ans[q[i].id] = now;
}
for(int i = 1; i <= cntq; ++i)
printf("%d\n", ans[i]);
return 0;
} 5、莫队算法的扩展——树上莫队
前面我们所使用的莫队都是在一维的序列上进行,即使加了一维的时间轴,但是主题还是一维序列。那么树上统计问题能否用莫队来处理呢?答案是肯定的。
不要认为这个东西很高级,实际上它还是个序列。
问题一:子树统计
子树统计算是这里面最简单的了。在原树上跑一遍dfs序,然后发现一颗子树其实就是里面一段固定区间……

边跑dfs边弄子树对应的左右端点即可。
这里序列的长度=结点的个数。
实际上子树上的统计完全不需要莫队,传个标记就可以\(O(nlogn)\)了
问题二:路径上的统计
比如说这个题目:SP10707 COT2 - Count on a tree II
题目描述
给定一个n个节点的树,每个节点表示一个整数,问u到v的路径上有多少个不同的整数。
输入格式
第一行有两个整数n和m(n=40000,m=100000)。
第二行有n个整数。第i个整数表示第i个节点表示的整数。
在接下来的n-1行中,每行包含两个整数u v,描述一条边(u,v)。
在接下来的m行中,每一行包含两个整数u v,询问u到v的路径上有多少个不同的整数。
输出格式
对于每个询问,输出结果。
输入输出样例
输入样例#1:
8 2
105 2 9 3 8 5 7 7
1 2
1 3
1 4
3 5
3 6
3 7
4 8
2 5
7 8输出样例#1:
4
4这还不简单吗?dfs序一遍找区间……诶?区间呢qwq?

参照上图,我可以负责地告诉你:普通dfs序是完全不行的(因为区间没有对应关系)。
但是还好我们有欧拉序,这是一种特殊的dfs序,可以解决很多普通dfs序解决不了的问题(就比如我们的树上莫队)。
那欧拉序有什么特点呢?怎么求它?
还是那张图,我们对它求一遍欧拉序:
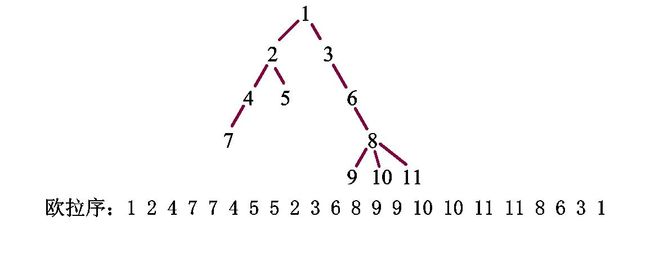
这是个什么东西?!它怎么求得的暂且不谈(不过你也应该已经知道了),先看看它的性质:
我们看一看每个编号出现的次数——两次,无一例外。再看看它出现的两个位置有什么特点:
我们以编号\(2\)为例,它出现在位置2和9,它中间的编号有\(4×2\)、\(7×2\)、\(5×2\)。
再观察这棵树,诶,这些编号不都是\(2\)的子树上的结点吗??!
就这样,我们得出它的一条性质:树的欧拉序上两个相同编号(设为\(x\))之间的所有编号都出现两次,且都位于\(x\)子树上。(前半句话其实可以由后半句话间接证明)
它的求法也很简单,在刚dfs到一个点时加入序列,最后退出时也加入一遍。现在知道这个性质的来源了吧qwq
那么为什么用欧拉序可以把路径搬到区间上呢?我们来看一下这张图:
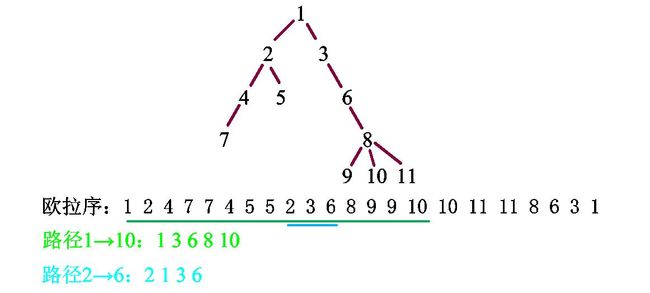
我们在欧拉序中找到路径\(1\rightarrow10\)起点(1)终点(10)的位置。我们发现,我们完全可以在找到对应的区间(绿色部分),而由于其中有一些点出现了两次,这些出现了两次的点可以证明不在路径上(路径不会经过一个点两次,而如果只经过一次则不会出现两个相同的编号),所以出现了两次的点我们不予算入。
那我们尝试找一下\(2\rightarrow 6\)对应的区间吧。唔,这还不简单吗,不就是2、4、7……3、6……嗯?1哪去了?1呢?^1可是他们的\(lca\)啊!!看来这样单纯的找区间还是不行的,还有其他特殊方法。
具体做法:设每个点的编号\(a\)首次出现的位置\(first[a]\),最后出现的位置为\(last[a]\),那么对于路径\(x\rightarrow y\),设\(first[x]<=first[y]\)(不满足则swap,这个操作的意义在于,如果\(x\)、\(y\)在一条链上,则\(x\)一定是\(y\)的祖先或等于\(y\)),如果\(lca(x,y)=x\),则直接把\([first[x],first[y]]\)的区间扯过来用,反之使用\([last[x],first[y]]\)区间(为什么不用\([first[x],first[y]]\)?因为\((first[x],last[x])\)不会在路径上,根据性质,里面的编号都会出现两次,考虑了等于没考虑),但这个区间内不包含\(x\)和\(y\)的最近公共祖先,查询的时候加上即可。
注意,这里序列长度为\(2×n\),千万不要在这T了啊……qwq
做完了这些,树上莫队的其他东西就和普通莫队差不多啦。值得注意的是,我们又可以像上文的带修莫队那样优化代码长度——由于无需考虑的点会出现两次,我们可以弄一个标记数组(标记结点是否被访问),没访问就加,访问过就删,每次操作把标记·异或个1,完美解决所有添加、删除、去双问题。
例题参考代码:
#include
#include
#include
#include
using namespace std;
#define maxn 200200
#define isdigit(x) ((x) >= '0' && (x) <= '9')
inline int read() {
int res = 0;
char c = getchar();
while(!isdigit(c)) c = getchar();
while(isdigit(c)) res = (res << 1) + (res << 3) + (c ^ 48), c = getchar();
return res;
}
int aa[maxn], cnt[maxn], first[maxn], last[maxn], ans[maxn], belong[maxn], inp[maxn], vis[maxn], ncnt, l = 1, r, now, size, bnum; //莫队相关
int ord[maxn], val[maxn], head[maxn], depth[maxn], fa[maxn][30], ecnt;
int n, m;
struct edge {
int to, next;
} e[maxn];
void adde(int u, int v) {
e[++ecnt] = (edge){v, head[u]};
head[u] = ecnt;
e[++ecnt] = (edge){u, head[v]};
head[v] = ecnt;
}
void dfs(int x) {
ord[++ncnt] = x;
first[x] = ncnt;
for(int k = head[x]; k; k = e[k].next) {
int to = e[k].to;
if(to == fa[x][0]) continue;
depth[to] = depth[x] + 1;
fa[to][0] = x;
for(int i = 1; (1 << i) <= depth[to]; ++i) fa[to][i] = fa[fa[to][i - 1]][i - 1];
dfs(to);
}
ord[++ncnt] = x;
last[x] = ncnt;
}
int getlca(int u, int v) {
if(depth[u] < depth[v]) swap(u, v);
for(int i = 20; i + 1; --i)
if(depth[u] - (1 << i) >= depth[v]) u = fa[u][i];
if(u == v) return u;
for(int i = 20; i + 1; --i)
if(fa[u][i] != fa[v][i]) u = fa[u][i], v = fa[v][i];
return fa[u][0];
}
struct query {
int l, r, lca, id;
} q[maxn];
int cmp(query a, query b) {
return (belong[a.l] ^ belong[b.l]) ? (belong[a.l] < belong[b.l]) : ((belong[a.l] & 1) ? a.r < b.r : a.r > b.r);
}
void work(int pos) {
vis[pos] ? now -= !--cnt[val[pos]] : now += !cnt[val[pos]]++;
vis[pos] ^= 1;
}
int main() {
n = read(); m = read();
for(int i = 1; i <= n; ++i)
val[i] = inp[i] = read();
sort(inp + 1, inp + n + 1);
int tot = unique(inp + 1, inp + n + 1) - inp - 1;
for(int i = 1; i <= n; ++i)
val[i] = lower_bound(inp + 1, inp + tot + 1, val[i]) - inp;
for(int i = 1; i < n; ++i) adde(read(), read());
depth[1] = 1;
dfs(1);
size = sqrt(ncnt), bnum = ceil((double) ncnt / size);
for(int i = 1; i <= bnum; ++i)
for(int j = size * (i - 1) + 1; j <= i * size; ++j) belong[j] = i;
for(int i = 1; i <= m; ++i) {
int L = read(), R = read(), lca = getlca(L, R);
if(first[L] > first[R]) swap(L, R);
if(L == lca) {
q[i].l = first[L];
q[i].r = first[R];
}
else {
q[i].l = last[L];
q[i].r = first[R];
q[i].lca = lca;
}
q[i].id = i;
}
sort(q + 1, q + m + 1, cmp);
for(int i = 1; i <= m; ++i) {
int ql = q[i].l, qr = q[i].r, lca = q[i].lca;
while(l < ql) work(ord[l++]);
while(l > ql) work(ord[--l]);
while(r < qr) work(ord[++r]);
while(r > qr) work(ord[r--]);
if(lca) work(lca);
ans[q[i].id] = now;
if(lca) work(lca);
}
for(int i = 1; i <= m; ++i) printf("%d\n", ans[i]);
return 0;
} 6、莫队算法的扩展——回滚莫队
莫队维护区间统计信息虽然方便,但在某些场合下却非常鸡肋。比如如下这题:
AT1219 [JOI2013]歴史の研究
题目描述
IOI国历史研究的第一人——JOI教授,最近获得了一份被认为是古代IOI国的住民写下的日记。JOI教授为了通过这份日记来研究古代IOI国的生活,开始着手调查日记中记载的事件。
日记中记录了连续N天发生的时间,大约每天发生一件。
事件有种类之分。第i天\((1<=i<=N)\)发生的事件的种类用一个整数\(X_i\)表示,\(X_i\)越大,事件的规模就越大。
JOI教授决定用如下的方法分析这些日记:
\(1\).选择日记中连续的一些天作为分析的时间段
\(2\).事件种类t的重要度为t×(这段时间内重要度为t的事件数)
\(3\).计算出所有事件种类的重要度,输出其中的最大值
现在你被要求制作一个帮助教授分析的程序,每次给出分析的区间,你需要输出重要度的最大值。
输入格式
第一行两个空格分隔的整数\(N\)和\(Q\),表示日记一共记录了\(N\)天,询问有\(Q\)次。
接下来一行N个空格分隔的整数\(X_1\)...\(X_N\),\(X_i\)表示第\(i\)天发生的事件的种类
接下来Q行,第i行\((1<=i<=Q)\)有两个空格分隔整数\(A_i\)和\(B_i\),表示第i次询问的区间为\([A_i,B_i]\)。
输入输出样例
输入样例#1:
5 5
9 8 7 8 9
1 2
3 4
4 4
1 4
2 4输出样例#1:
9
8
8
16
16题目到手很快就能想到用莫队维护这个最大值,添加值很好做,直接加个计数器,然后乘一下取个max就完事了。然后删除……不会。想到的唯一办法就是在当前计数器清零后往前枚举,找到一个可行的最大值再替换。这样的复杂度会多一维,达到\(O(n^2\sqrt{n})\),还不如直接n方暴力,说不定就能过百万了呢
此时,由于莫队的无敌(雾),有神犇发明了一个玄学高效的算法,复杂度最坏\(O(n\sqrt{n})\),而且常数碾压同为\(O(n\sqrt{n})\)的块状数组做法。
我们观察莫队的性质:左端点在同一块中的所有查询区间右端点单调递增。这样,对于左端点在同一块中的每个区间,我们都可以\(O(n)\)解决所有的右端点,且不用回头删除值(单调递增)。考虑枚举每个块,总共需要枚举\(\sqrt{n}\)个块,这部分的总复杂度\(O(n\sqrt{n})\)。
又对于每个块内的左端点:假设每个块内的每个左端点都从块右端开始统计,每次都重新开始暴力统计一次,做完每个左端点复杂度\(O(\sqrt{n})\),共\(n\)个左端点,总复杂度\(O(n\sqrt{n})\)。
我们发现这两部分是很容易结合起来的。做法就是枚举每个块,每次把\(l\)、\(r\)指针置于块尾+1的位置和块尾(至于为什么+1还请看前面),先暴力处理掉左右端点在一块的特殊情况(\(O(\sqrt{n})\)),然后右端点暴力向右推,左端点一个个解决,在移动左指针前纪录一下当前状态,移动保存值后复原即可,也无需删除。以上的问题完美解决。(岂不美滋滋??#滑稽#)
注意暴力和正常推指针时的\(cnt\)不要共用,而且每做一个新块都要把\(cnt\)清零。这样回滚莫队代码不难写出啦(难调啊):
例题参考代码:
#include
#include
#include
#include
using namespace std;
#define maxn 100100
#define maxb 5050
#define ll long long
int aa[maxn], typ[maxn], cnt[maxn], cnt2[maxn], belong[maxn], lb[maxn], rb[maxn], inp[maxn];
ll ans[maxn];
struct query {
int l, r, id;
} q[maxn];
int n, m, size, bnum;
#define isdigit(x) ((x) >= '0' && (x) <= '9')
inline int read() {
int res = 0;
char c = getchar();
while(!isdigit(c)) c = getchar();
while(isdigit(c)) res = (res << 1) + (res << 3) + (c ^ 48), c = getchar();
return res;
}
int cmp(query a, query b) {
return (belong[a.l] ^ belong[b.l]) ? belong[a.l] < belong[b.l] : a.r < b.r;
}
int main() {
n = read(), m = read();
size = sqrt(n);
bnum = ceil((double) n / size);
for(int i = 1; i <= bnum; ++i) {
lb[i] = size * (i - 1) + 1;
rb[i] = size * i;
for(int j = lb[i]; j <= rb[i]; ++j) belong[j] = i;
}
rb[bnum] = n;
for(int i = 1; i <= n; ++i) inp[i] = aa[i] = read();
sort(inp + 1, inp + n + 1);
int tot = unique(inp + 1, inp + n + 1) - inp - 1;
for(int i = 1; i <= n; ++i) typ[i] = lower_bound(inp + 1, inp + tot + 1, aa[i]) - inp;
for(int i = 1; i <= m; ++i) {
q[i].l = read(), q[i].r = read();
q[i].id = i;
}
sort(q + 1, q + m + 1, cmp);
int i = 1;
for(int k = 0; k <= bnum; ++k) {
int l = rb[k] + 1, r = rb[k];
ll now = 0;
memset(cnt, 0, sizeof(cnt));
for( ; belong[q[i].l] == k; ++i) {
int ql = q[i].l, qr = q[i].r;
ll tmp;
if(belong[ql] == belong[qr]) {
tmp = 0;
for(int j = ql; j <= qr; ++j) cnt2[typ[j]] = 0;
for(int j = ql; j <= qr; ++j) {
++cnt2[typ[j]]; tmp = max(tmp, 1ll * cnt2[typ[j]] * aa[j]);
}
ans[q[i].id] = tmp;
continue;
}
while(r < qr) {
++r; ++cnt[typ[r]]; now = max(now, 1ll * cnt[typ[r]] * aa[r]);
}
tmp = now;
while(l > ql){
--l; ++cnt[typ[l]]; now = max(now, 1ll * cnt[typ[l]] * aa[l]);
}
ans[q[i].id] = now;
while(l < rb[k] + 1) {
--cnt[typ[l]];
l++;
}
now = tmp;
}
}
for(int i = 1; i <= m; ++i) printf("%lld\n", ans[i]);
return 0;
} 注意这里分块时有个坑点:向上取整的ceil不要写成floor,这样在普通莫队中会多出一个块0,完全不影响AC,但在回滚莫队中就是WA,WA到我浑身不得劲qwq
回滚莫队完结撒花✿✿ヽ(°▽°)ノ✿qwq
7、练习题
这里放的主要是莫队裸题,没有与其他算法的综合应用,但部分有思维难度。如需要综合应用题请左转【Luogu OJ】 右转【BZOJ】
虽然莫队算法思想很简单,但与它有关的应用还是很经(du)典(liu)的。下面是一些经(du)典(liu)的例题:
1、【基础题】Luogu P2709 小B的询问
这题的话,手推公式很容易就能做出来,而且题目无坑点,甚至无需卡常
代码不给了qwq,和例题差不了两句话qwq
2、【进阶题】Luogu P1494 [国家集训队]小Z的袜子
这题需要一些基础但较为复杂的数学演算,打表基本不靠谱(另外还要注意约分)
留给大家自行推理(代码还是很简单哒qwq)
3、【进阶题】Luogu P3709 大爷的字符串题
内个,题意别看了,题目要求的是区间众数的出现次数(出题人语文不好)(当然你也可以直接把题意推出来qwq)
即便题意明了了,这题还是有点综合性的(区间众数这东西并不好求)
真是一道好(du)题(liu)(逃
4、【最终挑战】Luogu P4074 [WC2013]糖果公园
承诺的黑题终于来啦,撒花✿✿ヽ(°▽°)ノ✿
然而这题并不难,树上带修莫队模板题,相信你很快就能切掉它qwq
参考代码:
#include
#include
#include
#include
using namespace std;
#define maxn 200200
#define ll long long
int cnt[maxn], aa[maxn], belong[maxn], inp[maxn], n, m, Q, ncnt, size, bnum, w[maxn], v[maxn], ccnt, qcnt;
int val[maxn], fa[maxn][30], depth[maxn], head[maxn], ecnt;
int fir[maxn], la[maxn], vis[maxn];
int l = 1, r = 0, t = 0;
ll now, ans[maxn];
struct edge {
int to, next;
} e[maxn];
void adde(int u, int v) {
e[++ecnt] = (edge){v, head[u]};
head[u] = ecnt;
e[++ecnt] = (edge){u, head[v]};
head[v] = ecnt;
}
void dfs(int x) {
aa[++ncnt] = x;
fir[x] = ncnt;
for(int k = head[x]; k; k = e[k].next) {
int to = e[k].to;
if(depth[to]) continue;
depth[to] = depth[x] + 1;
fa[to][0] = x;
for(int i = 1; (1 << i) <= depth[to]; ++i) fa[to][i] = fa[fa[to][i - 1]][i - 1];
dfs(to);
}
aa[++ncnt] = x;
la[x] = ncnt;
}
int getlca(int u, int v) {
if(depth[u] < depth[v]) swap(u, v);
for(int i = 20; i + 1; --i) if(depth[fa[u][i]] >= depth[v]) u = fa[u][i];
if(u == v) return u;
for(int i = 20; i + 1; --i) if(fa[u][i] != fa[v][i]) u = fa[u][i], v = fa[v][i];
return fa[u][0];
}
struct query {
int l, r, id, lca, t;
} q[maxn];
int cmp(query a, query b) {
return (belong[a.l] ^ belong[b.l]) ? belong[a.l] < belong[b.l] : ((belong[a.r] ^ belong[b.r]) ? belong[a.r] < belong[b.r] : a.t < b.t );
}
inline void add(int pos) {
now += 1ll * v[val[pos]] * w[++cnt[val[pos]]];
}
inline void del(int pos) {
now -= 1ll * v[val[pos]] * w[cnt[val[pos]]--];
}
inline void work(int pos) {
vis[pos] ? del(pos) : add(pos);
vis[pos] ^= 1;
}
struct change {
int pos, val;
} ch[maxn];
void modify(int x) {
if(vis[ch[x].pos]) {
work(ch[x].pos);
swap(val[ch[x].pos], ch[x].val);
work(ch[x].pos);
}
else swap(val[ch[x].pos], ch[x].val);
}
#define isdigit(x) ((x) >= '0' && (x) <= '9')
inline int read() {
int res = 0;
char c = getchar();
while(!isdigit(c)) c = getchar();
while(isdigit(c)) res = (res << 1) + (res << 3) + (c ^ 48), c = getchar();
return res;
}
int main() {
n = read(), m = read(), Q = read();
for(int i = 1; i <= m; ++i) v[i] = read();
for(int i = 1; i <= n; ++i) w[i] = read();
for(int i = 1; i < n; ++i) {
int u = read(), v = read();
adde(u, v);
}
for(int i = 1; i <= n; ++i) val[i] = read();
depth[1] = 1;
dfs(1);
size = pow(ncnt, 2.0 / 3.0);
bnum = ceil((double)ncnt / size);
for(int i = 1; i <= bnum; ++i)
for(int j = size * (i - 1) + 1; j <= i * size; ++j) belong[j] = i;
for(int i = 1; i <= Q; ++i) {
int opt = read(), a = read(), b = read();
if(opt) {
int lca = getlca(a, b);
q[++qcnt].t = ccnt;
q[qcnt].id = qcnt;
if(fir[a] > fir[b]) swap(a, b);
if(a == lca) q[qcnt].l = fir[a], q[qcnt].r = fir[b];
else q[qcnt].l = la[a], q[qcnt].r = fir[b], q[qcnt].lca = lca;
}
else {
ch[++ccnt].pos = a;
ch[ccnt].val = b;
}
}
sort(q + 1, q + qcnt + 1, cmp);
for(int i = 1; i <= qcnt; ++i) {
int ql = q[i].l, qr = q[i].r, qt = q[i].t, qlca = q[i].lca;
while(l < ql) work(aa[l++]);
while(l > ql) work(aa[--l]);
while(r < qr) work(aa[++r]);
while(r > qr) work(aa[r--]);
while(t < qt) modify(++t);
while(t > qt) modify(t--);
if(qlca) work(qlca);
ans[q[i].id] = now;
if(qlca) work(qlca);
}
for(int i = 1; i <= qcnt; ++i) printf("%lld\n", ans[i]);
return 0;
} 5、其它
自己找qwq,百度是个很好的东西qwq
尾声
耗时将近两天的长篇大论终于要结束啦,再来无耻的求一波赞qwq(逃
感谢各位坚持着看过来(雾)的dalao,文章如有错误欢迎指出哦qwq