1. 简介/动机
在多线程(multithreaded, MT)编程出现之前,计算机程序的执行是由单个步骤序列组成的,该序列在主机的 CPU 中按照同步顺序执行。无论是任务本身需要按照步骤顺序执行,还是整个程序实际上包含多个子任务,都需要按照这种顺序方式执行。那么,假如这些子任务相互独立,没有因果关系(也就是说,各个子任务的结果并不影响其他子任务的结果),这种做法是不是不符合逻辑呢?要是让这些独立的任务同时运行,会怎么样呢?很明显,这种并行处理方式可以显著地提高整个任务的性能。这就是多线程编程。
多线程编程对于具有如下特点的编程任务而言是非常理想的:本质上是异步的;需要多个并发活动;每个活动的处理顺序可能是不确定的,或者说是随机的、不可预测的。这种编程任务可以被组织或划分成多个执行流,其中每个执行流都有一个指定要完成的任务。根据应用的不同,这些子任务可能需要计算出中间结果,然后合并为最终的输出结果。
计算密集型的任务可以比较容易地划分成多个子任务,然后按顺序执行或按照多线程方式执行。而那种使用单线程处理多个外部输入源的任务就不那么简单了。如果不使用多线程,要实现这种编程任务就需要为串行程序使用一个或多个计时器,并实现一个多路复用方案。
一个串行程序需要从每个 I/O 终端通道来检查用户的输入;然而,有一点非常重要,程序在读取 I/O 终端通道时不能阻塞,因为用户输入的到达时间是不确定的,并且阻塞会妨碍其他 I/O 通道的处理。串行程序必须使用非阻塞 I/O 或拥有计时器的阻塞 I/O(以保证阻塞只是暂时的)。
由于串行程序只有唯一的执行线程,因此它必须兼顾需要执行的多个任务,确保其中的某个任务不会占用过多时间,并对用户的响应时间进行合理的分配。这种任务类型的串行程序的使用,往往造成非常复杂的控制流,难以理解和维护。
使用多线程编程,以及类似 Queue 的共享数据结构(本章后面会讨论的一种多线程队列数据结构),这个编程任务可以规划成几个执行特定函数的线程。
- UserRequestThread:负责读取客户端输入,该输入可能来自 I/O 通道。程序将创建多个线程,每个客户端一个,客户端的请求将会被放入队列中。
- RequestProcessor:该线程负责从队列中获取请求并进行处理,为第 3 个线程提供输出。
- ReplyThread:负责向用户输出,将结果传回给用户(如果是网络应用),或者把数据写到本地文件系统或数据库中。
使用多线程来规划这种编程任务可以降低程序的复杂性,使其实现更加清晰、高效、简洁。每个线程中的逻辑都不复杂,因为它只有一个要完成的特定作业。比如,UserRequestThread 的功能仅仅是读取用户输入,然后把输入数据放到队列里,以供其他线程后续处理。每个线程都有其明确的作业,你只需要设计每类线程去做一件事,并把这件事情做好就可以了。这种特定任务线程的使用与亨利·福特生产汽车的流水线模型有些许相似。
2. 线程和进程
2.1 进程
计算机程序只是存储在磁盘上的可执行二进制(或其他类型)文件。只有把它们加载到内存中并被操作系统调用,才拥有其生命期。 进程(有时称为重量级进程)则是一个执行中的程序。每个进程都拥有自己的地址空间、内存、数据栈以及其他用于跟踪执行的辅助数据。操作系统管理其上所有进程的执行,并为这些进程合理地分配时间。进程也可以通过派生(fork 或 spawn)新的进程来执行其他任务,不过因为每个新进程也都拥有自己的内存和数据栈等,所以只能采用进程间通信(IPC)的方式共享信息。
2.2 线程
线程(有时候称为轻量级进程)与进程类似,不过它们是在同一个进程下执行的,并共享相同的上下文。可以将它们认为是在一个主进程或“主线程”中并行运行的一些“迷你进程”。
线程包括开始、执行顺序和结束三部分。它有一个指令指针,用于记录当前运行的上下文。当其他线程运行时,它可以被抢占(中断)和临时挂起(也称为睡眠) ——这种做法叫做让步(yielding)。
一个进程中的各个线程与主线程共享同一片数据空间,因此相比于独立的进程而言,线程间的信息共享和通信更加容易。线程一般是以并发方式执行的,正是由于这种并行和数据共享机制,使得多任务间的协作成为可能。当然,在单核 CPU 系统中,因为真正的并发是不可能的,所以线程的执行实际上是这样规划的:每个线程运行一小会儿,然后让步给其他线程(再次排队等待更多的 CPU 时间)。在整个进程的执行过程中,每个线程执行它自己特定的任务,在必要时和其他线程进行结果通信。
当然,这种共享并不是没有风险的。如果两个或多个线程访问同一片数据,由于数据访问顺序不同,可能导致结果不一致。这种情况通常称为竞态条件(race condition)。幸运的是,大多数线程库都有一些同步原语,以允许线程管理器控制执行和访问。
另一个需要注意的问题是,线程无法给予公平的执行时间。这是因为一些函数会在完成前保持阻塞状态,如果没有专门为多线程情况进行修改,会导致 CPU 的时间分配向这些贪婪的函数倾斜。
3. 线程和 Python
本节将讨论在如何在 Python 中使用线程,其中包括全局解释器锁对线程的限制和一个快速的演示脚本。
3.1 全局解释器锁
Python 代码的执行是由Python虚拟机(又名解释器主循环)进行控制的。 Python 在设计时是这样考虑的,在主循环中同时只能有一个控制线程在执行;就像单核 CPU 系统中的多进程一样,内存中可以有许多程序,但是在任意给定时刻只能有一个程序在运行。同理,尽管 Python 解释器中可以运行多个线程,但是在任意给定时刻只有一个线程会被解释器执行。
对 Python 虚拟机的访问是由全局解释器锁(GIL)控制的。这个锁就是用来保证同时只能有一个线程运行的。在多线程环境中, Python 虚拟机将按照下面所述的方式执行:
- 设置 GIL。
- 切换进一个线程去运行。
- 执行下面操作之一。
a. 指定数量的字节码指令。
b. 线程主动让出控制权(可以调用time.sleep(0)来完成)。 - 把线程设置回睡眠状态(切换出线程)。
- 解锁 GIL。
- 重复上述步骤。
当调用外部代码(即,任意 C/C++扩展的内置函数)时, GIL 会保持锁定,直至函数执行结束(因为在这期间没有 Python 字节码计数)。编写扩展函数的程序员有能力解锁 GIL,然而,作为 Python 开发者, 你并不需要担心 Python 代码会在这些情况下被锁住。例如,对于任意面向 I/O 的 Python 例程(调用了内置的操作系统 C 代码的那种),GIL 会在 I/O 调用前被释放,以允许其他线程在 I/O 执行的时候运行。而对于那些没有太多 I/O 操作的代码而言,更倾向于在该线程整个时间片内始终占有处理器(和 GIL)。换句话说就是, I/O 密集型的 Python 程序要比计算密集型的代码能够更好地利用多线程环境。
如果你对源代码、解释器主循环和 GIL 感兴趣,可以看看Python/ceval.c文件。
3.2 退出线程
当一个线程完成函数的执行时,它就会退出。另外,还可以通过调用诸如thread.exit()之类的退出函数,或者 sys.exit()之类的退出 Python 进程的标准方法,亦或者抛出SystemExit异常,来使线程退出。不过,你不能直接“终止”一个线程。
下一节将会详细讨论两个与线程相关的 Python 模块,不过在这两个模块中,不建议使用thread模块。给出这个建议有很多原因,其中最明显的一个原因是模块thread在主线程退出之后,所有其他线程都会在没有清理的情况下直接退出。而另一个模块 threading 会确保在所有“重要的”子线程退出前,保持整个进程的存活(对于“重要的”这个含义的说明,请阅读下面的核心提示:“避免使用 thread 模块”)。
而主线程应该做一个好的管理者,负责了解每个单独的线程需要执行什么,每个派生的线程需要哪些数据或参数,这些线程执行完成后会提供什么结果。这样,主线程就可以收集每个线程的结果,然后汇总成一个有意义的最终结果。
3.3 在 Python 中使用线程
Python 虽然支持多线程编程,但是还需要取决于它所运行的操作系统。如下操作系统是支持多线程的:绝大多数类 UNIX 平台(如 Linux、 Solaris、 Mac OS X、 *BSD 等),以及Windows 平台。 Python 使用兼容 POSIX 的线程,也就是众所周知的 pthread。
默认情况下,从源码构建的 Python(2.0 及以上版本)或者 Win32 二进制安装的 Python,线程支持是已经启用的。要确定你的解释器是否支持线程,只需要从交互式解释器中尝试导入 thread 模块即可,如下所示(如果线程是可用的,则不会产生错误)。
>>> import thread
>>>
如果你的 Python 解释器没有将线程支持编译进去,模块导入将会失败。
>>> import thread
Traceback (innermost last):
File "" , line 1, in ?
ImportError: No module named thread
这种情况下,你可能需要重新编译你的 Python 解释器才能够使用线程。一般可以在调用configure 脚本的时候使用–with-thread 选项。查阅你所使用的发行版本的 README 文件,来获取如何在你的系统中编译线程支持的 Python 的指定指令。
注意:Python3.x 线程中 thread 模块已被废弃,用户可以使用 threading 模块代替。在 Python3.x 中不能再使用"thread" 模块。为了兼容性,Python3.x 将 thread 重命名为 “_thread”。
In [1]: import thread
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-1-e75c663b2a08> in <module>
----> 1 import thread
ModuleNotFoundError: No module named 'thread'
In [2]: import threading
In [3]: import _thread
In [4]:
3.4 不使用线程的情况
在第一个例子中, 我们将使用 time.sleep()函数来演示线程是如何工作的。 time.sleep()函数需要一个浮点型的参数,然后以这个给定的秒数进行“睡眠”,也就是说,程序的执行会暂时停止指定的时间。
创建两个时间循环:一个睡眠 4 秒(loop0());另一个睡眠 2 秒(loop1())(这里使用“loop0”和“loop1”作为函数名,暗示我们最终会有一个循环序列)。如果在一个单进程或单线程的程序中顺序执行 loop0()和 loop1(),就会像示例 4-1 中的 onethr.py 一样,整个执行时间至少会达到 6 秒钟。而在启动 loop0()和 loop1()以及执行其他代码时,也有可能存在 1 秒的开销,使得整个时间达到 7 秒。
示例1 使用单线程执行循环(
onethr.py)
该脚本在一个单线程程序里连续执行两个循环。一个循环必须在另一个开始前完成。总共消耗的时间是每个循环所用时间之和。
from time import sleep, ctime
def loop0():
print('start loop 0 at:', ctime())
sleep(4)
print('loop 0 done at:', ctime())
def loop1():
print('start loop 1 at:', ctime())
sleep(2)
print('loop 1 done at:', ctime())
def main():
print('starting at:', ctime())
loop0()
loop1()
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
可以通过执行onethr.py来验证这一点,下面是输出结果:
$python onethr.py
starting at: Thu Feb 28 10:54:40 2019
start loop 0 at: Thu Feb 28 10:54:40 2019
loop 0 done at: Thu Feb 28 10:54:44 2019
start loop 1 at: Thu Feb 28 10:54:44 2019
loop 1 done at: Thu Feb 28 10:54:46 2019
all DONE at: Thu Feb 28 10:54:46 2019
现在,假设 loop0()和 loop1()中的操作不是睡眠,而是执行独立计算操作的函数,所有结果汇总成一个最终结果。那么,让它们并行执行来减少总的执行时间是不是有用的呢?这就是现在要介绍的多线程编程的前提。
3.5 Python 的 threading 模块
Python 提供了多个模块来支持多线程编程,包括 thread、 threading 和 Queue 模块等。程序是可以使用 thread 和 threading 模块来创建与管理线程。 thread 模块提供了基本的线程和锁定支持;而 threading 模块提供了更高级别、功能更全面的线程管理。使用 Queue 模块,用户可以创建一个队列数据结构,用于在多线程之间进行共享。我们将分别来查看这几个模块,并给出几个例子和中等规模的应用。
核心提示:避免使用 thread 模块
推荐使用更高级别的 threading 模块,而不使用 thread 模块有很多原因。 threading 模块更加先进,有更好的线程支持,并且 thread 模块中的一些属性会和 threading 模块有冲突。另一个原因是低级别的 thread 模块拥有的同步原语很少(实际上只有一个),而 threading模块则有很多。
不过,出于对 Python 和线程学习的兴趣,我们将给出使用 thread 模块的一些代码。给出这些代码只是出于学习目的,希望它能够让你更好地领悟为什么应该避免使用thread 模块。我们还将展示如何使用更加合适的工具,如 threading 和 Queue 模块中的那些方法。
避免使用 thread 模块的另一个原因是它对于进程何时退出没有控制。当主线程结束时,所有其他线程也都强制结束,不会发出警告或者进行适当的清理。如前所述,至少threading 模块能确保重要的子线程在进程退出前结束。
我们只建议那些想访问线程的更底层级别的专家使用 thread 模块。为了强调这一点,在 Python3 中该模块被重命名为_thread。你创建的任何多线程应用都应该使用 threading 模块或其他更高级别的模块。
4. thread 模块
让我们先来看看 thread 模块提供了什么。除了派生线程外, thread 模块还提供了基本的同步数据结构,称为锁对象(lock object,也叫原语锁、 简单锁、 互斥锁、 互斥和二进制信号量)。如前所述,这个同步原语和线程管理是密切相关的。
表 4-1 列出了一些常用的线程函数,以及 LockType 锁对象的方法。
thread 模块的核心函数是 start_new_thread()。它的参数包括函数(对象)、函数的参数以及可选的关键字参数。将专门派生新的线程来调用这个函数。
把多线程整合进onethr.py这个例子中。把对 loop*()函数的调用稍微改变一下,得到示例4-2 中的mtsleepA.py文件。
表 4-1 thread 模块和锁对象
| 函数/方法 | 描 述 |
|---|---|
thread |
模块的函数 |
start_new_thread(function, args, kwargs=None) |
派生一个新的线程,使用给定的 args 和可选的 kwargs 来执行 function |
allocate_lock() |
分配 LockType 锁对象 |
exit() |
给线程退出指令 |
LockType |
锁对象的方法 |
acquire(wait=None) |
尝试获取锁对象 |
locked() |
如果获取了锁对象则返回 True,否则,返回 False |
release() |
释放锁 |
示例2 使用thread模块(
mtsleepA.py)
这里执行的循环和onethr.py是一样的,不过这次使用了thread模块提供的简单多线程机制。两个循环是并发执行的(很明显,短的那个先结束),因此总的运行时间只与最慢的那个线程相关,而不是每个线程运行时间之和。
import _thread as thread
from time import sleep, ctime
def loop0():
print('start loop 0 at:', ctime())
sleep(4)
print('loop 0 done at:', ctime())
def loop1():
print('start loop 1 at:', ctime())
sleep(2)
print('loop 1 done at:', ctime())
def main():
print('starting at:', ctime())
thread.start_new_thread(loop0, ())
thread.start_new_thread(loop1, ())
sleep(6)
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
start_new_thread()必须包含开始的两个参数,于是即使要执行的函数不需要参数,也需要传递一个空元组。
与之前的代码相比,本程序执行后的输出结果有很大不同。原来需要运行 6~7 秒的时间,而现在的脚本只需要运行 4 秒,也就是最长的循环加上其他所有开销的时间之和。
$python mtsleepA.py
starting at: Thu Feb 28 11:09:56 2019
start loop 0 at: Thu Feb 28 11:09:56 2019
start loop 1 at: Thu Feb 28 11:09:56 2019
loop 1 done at: Thu Feb 28 11:09:58 2019
loop 0 done at: Thu Feb 28 11:10:00 2019
all DONE at: Thu Feb 28 11:10:02 2019
睡眠 4 秒和睡眠 2 秒的代码片段是并发执行的,这样有助于减少整体的运行时间。你甚至可以看到 loop 1 是如何在 loop 0 之前结束的。
这个应用程序中剩下的一个主要区别是增加了一个 sleep(6)调用。为什么必须要这样做呢?这是因为如果我们没有阻止主线程继续执行,它将会继续执行下一条语句,显示“all DONE”然后退出,而 loop0()和 loop1()这两个线程将直接终止。
我们没有写让主线程等待子线程全部完成后再继续的代码,即我们所说的线程需要某种形式的同步。在这个例子中,调用 sleep()来作为同步机制。将其值设定为 6 秒是因为我们知道所有线程(用时 4 秒和 2 秒的)会在主线程计时到 6 秒之前完成。
你可能会想到,肯定会有比在主线程中额外延时 6 秒更好的线程管理方式。由于这个延时,整个程序的运行时间并没有比单线程的版本更快。像这样使用 sleep()来进行线程同步是不可靠的。如果循环有独立且不同的执行时间要怎么办呢?我们可能会过早或过晚退出主线程。这就是引出锁的原因。
再一次修改代码,引入锁,并去除单独的循环函数,修改后的代码为mtsleepB.py,如示例 4-3 所示。我们可以看到输出结果与mtsleepA.py相似。唯一的区别是我们不需要再像mtsleepA.py那样等待额外的时间后才能结束。通过使用锁,我们可以在所有线程全部完成执行后立即退出。其输出结果如下所示。
$ mtsleepB.py
starting at Thu Feb 28 11:38:17 2019
start loop 0 at: Thu Feb 28 11:38:17 2019
start loop 1 at: Thu Feb 28 11:38:17 2019
loop 1 done at: Thu Feb 28 11:38:19 2019
loop 0 done at: Thu Feb 28 11:38:21 2019
all DONE at: Thu Feb 28 11:38:21 2019
那么我们是如何使用锁来完成任务的呢?下面详细分析源代码。
示例 3 使用线程和锁(
mtsleepB.py)
与mtsleepA.py中调用 sleep()来挂起主线程不同,锁的使用将更加合理。
import _thread as thread
from time import sleep, ctime
loops = [4, 2]
def loop(nloop, nsec, lock):
print('start loop', nloop, 'at:', ctime())
sleep(nsec)
print('loop', nloop, 'done at:', ctime())
lock.release()
def main():
print('starting at', ctime())
locks = []
nloops = range(len(loops)) # 返回[0, len(loops))范围内的一个可迭代对象(类型是对象),而不是列表类型,所以打印的时候不会打印列表。
for i in nloops:
lock = thread.allocate_lock() # 得到锁对象
lock.acquire() # 取得锁,效果等同于将锁锁上
locks.append(lock) # 将锁添加到锁列表中
for i in nloops:
thread.start_new_thread(loop, (i, loops[i], locks[i]))
for i in nloops:
while locks[i].locked():
pass
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
逐行解释
第 1~4 行
在 UNIX 启动行后,导入了 time 模块的几个熟悉属性以及 thread 模块。我们不再把 4秒和 2 秒硬编码到不同的函数中,而是使用了唯一的 loop()函数,并把这些常量放进列表loops 中。
第 6~10 行
loop()函数代替了之前例子中的 loop*()函数。因此,我们必须在 loop()函数中做一些修改,以便它能使用锁来完成自己的任务。其中最明显的变化是我们需要知道现在处于哪个循环中,以及需要睡眠多久。最后一个新的内容是锁本身。每个线程将被分配一个已获得的锁。当sleep()的时间到了的时候,释放对应的锁,向主线程表明该线程已完成。
第 12~29 行
大部分工作是在 main()中完成的,这里使用了 3 个独立的 for 循环。首先创建一个锁的列表,通过使用 thread.allocate_lock()函数得到锁对象,然后通过 acquire()方法取得(每个锁)。取得锁效果相当于“把锁锁上”。一旦锁被锁上后,就可以把它添加到锁列表 locks 中。下一个循环用于派生线程,每个线程会调用 loop()函数,并传递循环号、睡眠时间以及用于该线程的锁这几个参数。那么为什么我们不在上锁的循环中启动线程呢?这有两个原因:其一,我们想要同步线程,以便“所有的马同时冲出围栏”;其二,获取锁需要花费一点时间。如果线程执行得太快,有可能出现获取锁之前线程就执行结束的情况。
在每个线程执行完成时,它会释放自己的锁对象。最后一个循环只是坐在那里等待(暂停主线程),直到所有锁都被释放之后才会继续执行。因为我们按照顺序检查每个锁,所有可能会被排在循环列表前面但是执行较慢的循环所拖累。这种情况下,大部分时间是在等待最前面的循环。当这种线程的锁被释放时,剩下的锁可能早已被释放(也就是说,对应的线程已经执行完毕)。结果就是主线程会飞快地、没有停顿地完成对剩下锁的检查。最后,你应该知道只有当我们直接调用这个脚本时,最后几行语句才会执行 main()函数。
正如在前面的核心笔记中所提示的,这里使用 thread 模块只是为了介绍多线程编程。多线程应用程序应当使用更高级别的模块,比如下一节将要讨论到的 threading 模块。
5. threading 模块
现在介绍更高级别的 threading 模块。除了 Thread 类以外,该模块还包括许多非常好用的同步机制。表 4-2 给出了 threading 模块中所有可用对象的列表。
表 4-2 threading 模块的对象:
| 对 象 | 描 述 |
|---|---|
Thread |
表示一个执行线程的对象 |
Lock |
锁原语对象(和 thread 模块中的锁一样) |
RLock |
可重入锁对象,使单一线程可以(再次)获得已持有的锁(递归锁) |
Condition |
条件变量对象,使得一个线程等待另一个线程满足特定的“条件”,比如改变状态或某个数据值 |
Event |
条件变量的通用版本,任意数量的线程等待某个事件的发生,在该事件发生后所有线程将被激活 |
Semaphore |
为线程间共享的有限资源提供了一个“计数器”,如果没有可用资源时会被阻塞 |
BoundedSemaphore |
与 Semaphore 相似,不过它不允许超过初始值 |
Timer |
与 Thread 相似,不过它要在运行前等待一段时间 |
Barrier1 |
创建一个“障碍”,必须达到指定数量的线程后才可以继续 |
本节将研究如何使用 Thread 类来实现多线程。由于之前已经介绍过锁的基本概念,因此这里不会再对锁原语进行介绍。因为 Thread()类同样包含某种同步机制,所以锁原语的显式使用不再是必需的了。
核心提示:守护线程
避免使用 thread 模块的另一个原因是该模块不支持守护线程这个概念。当主线程退出时,所有子线程都将终止,不管它们是否仍在工作。如果你不希望发生这种行为,就要引入守护线程的概念了。
threading 模块支持守护线程,其工作方式是:守护线程一般是一个等待客户端请求服务的服务器。如果没有客户端请求,守护线程就是空闲的。如果把一个线程设置为守护线程,就表示这个线程是不重要的,进程退出时不需要等待这个线程执行完成。如同在第 2 章中看到的那样,服务器线程远行在一个无限循环里,并且在正常情况下不会退出。
如果主线程准备退出时,不需要等待某些子线程完成,就可以为这些子线程设置守护线程标记。该标记值为真时,表示该线程是不重要的,或者说该线程只是用来等待客户端请求而不做任何其他事情。
要将一个线程设置为守护线程,需要在启动线程之前执行如下赋值语句:thread.daemon = True(调用thread.setDaemon(True)的旧方法已经弃用了)。同样,要检查线程的守护状态,也只需要检查这个值即可(对比过去调用 thread.isDaemon()的方法)。一个新的子线程会继承父线程的守护标记。整个 Python 程序(可以解读为:主线程)将在所有非守护线程退出之后才退出,换句话说,就是没有剩下存活的非守护线程时。
5.1 Thread 类
threading 模块的 Thread 类是主要的执行对象。它有 thread 模块中没有的很多函数。表 4-3 给出了它的属性和方法列表。
表 4-3 Thread 对象的属性和方法
| 属 性 | 描 述 |
|---|---|
| Thread对象数据属性: | |
name |
线程名 |
ident |
线程的标识符 |
daemon |
布尔标志,表示这个线程是否是守护线程 |
| Thread对象方法: | |
_init_(group=None, tatget=None, name=None, args=(),kwargs ={}, verbose=None, daemon=None) ③ |
实例化一个线程对象,需要有一个可调用的 target,以及其参数 args或 kwargs。还可以传递 name 或 group 参数,不过后者还未实现。此外 , verbose 标 志 也 是 可 接 受 的。 而 daemon 的 值 将 会 设定thread.daemon 属性/标志 |
start() |
开始执行该线程 |
run() |
定义线程功能的方法(通常在子类中被应用开发者重写) |
join(timeout=None) |
直至启动的线程终止之前一直挂起;除非给出了 timeout(秒),否则会一直阻塞 |
getName()① |
返回线程名 |
setName(name)① |
设定线程名 |
isAlivel /is_alive ()② |
布尔标志,表示这个线程是否还存活 |
isDaemon()③ |
如果是守护线程,则返回 True;否则,返回 False |
setDaemon(daemonic)③ |
把线程的守护标志设定为布尔值 daemonic(必须在线程 start()之前调用) |
注:
① 该方法已弃用,更好的方式是设置(或获取)thread.name属性,或者在实例化过程中传递该属性。
② 驼峰式命名已经弃用,并且从 Python 2.6 版本起已经开始被取代。
③ is/setDaemon()已经弃用,应当设置 thread.daemon 属性;从 Python 3.3 版本起,也可以通过可选的 daemon 值在实例化过程中设定 thread.daemon 属性。
使用 Thread 类,可以有很多方法来创建线程。我们将介绍其中比较相似的三种方法。选择你觉得最舒服的,或者是最适合你的应用和未来扩展的方法(我们更倾向于最后一种方案)。
- 创建 Thread 的实例,传给它一个函数。
- 创建 Thread 的实例,传给它一个可调用的类实例。
- 派生 Thread 的子类,并创建子类的实例。
你会发现你将选择第一个或第三个方案。当你需要一个更加符合面向对象的接口时,会选择后者;否则会选择前者。老实说,你会发现第二种方案显得有些尴尬并且稍微难以阅读。
创建 Thread 的实例,传给它一个函数
在第一个例子中,我们只是把 Thread 类实例化,然后将函数(及其参数)传递进去,和之前例子中采用的方式一样。当线程开始执行时,这个函数也会开始执行。把示例 4-3 的mtsleepB.py 脚本进行修改,添加使用 Thread 类,得到示例 4-4 中的 mtsleepC.py 文件。
示例 4 使用 threading 模块(
mtsleepC.py)
threading 模块的 Thread 类有一个 join()方法,可以让主线程等待所有线程执行完毕。
import threading
from time import sleep, ctime
loops = [4, 2]
def loop(nloop, nsec):
print('start loop', nloop, 'at:', ctime())
sleep(nsec)
print('loop', nloop, 'done at:', ctime())
def main():
print('starting at', ctime())
threads = []
nloops = range(len(loops)) # 返回[0, len(loops))范围内的一个可迭代对象(类型是对象),而不是列表类型,所以打印的时候不会打印列表。
for i in nloops:
t = threading.Thread(target=loop, args=(i, loops[i])) # args是调用target的参数
threads.append(t)
for i in nloops:
threads[i].start()
for i in nloops:
threads[i].join()
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
当运行示例 4 中的脚本时,可以得到和之前相似的输出。
$ mtsleepC.py
starting at Thu Feb 28 16:05:05 2019
start loop 0 at: Thu Feb 28 16:05:05 2019
start loop 1 at: Thu Feb 28 16:05:05 2019
loop 1 done at: Thu Feb 28 16:05:07 2019
loop 0 done at: Thu Feb 28 16:05:09 2019
all DONE at: Thu Feb 28 16:05:09 2019
那么,这里到底做了哪些修改呢?使用 thread 模块时实现的锁没有了,取而代之的是一组 Thread 对象。当实例化每个 Thread 对象时,把函数(target)和参数(args)传进去,然后得到返回的 Thread 实例。==实例化 Thread(调用 Thread())和调用 thread.start_new_thread()的最大区别是新线程不会立即开始执行。==这是一个非常有用的同步功能,尤其是当你并不希望线程立即开始执行时。
当所有线程都分配完成之后,通过调用每个线程的 start()方法让它们开始执行,而不是在这之前就会执行。相比于管理一组锁(分配、获取、释放、检查锁状态等)而言,这里只需要为每个线程调用 join()方法即可。 join()方法将等待线程结束,或者在提供了超时时间的情况下,达到超时时间。使用 join()方法要比等待锁释放的无限循环更加清晰(这也是这种锁又称为自旋锁的原因)。
对于 join()方法而言,其另一个重要方面是其实它根本不需要调用。一旦线程启动,它们就会一直执行,直到给定的函数完成后退出。如果主线程还有其他事情要去做,而不是等待这些线程完成(例如其他处理或者等待新的客户端请求),就可以不调用 join()。 join()方法只有在你需要等待线程完成的时候才是有用的。
创建 Thread 的实例,传给它一个可调用的类实例
在创建线程时,与传入函数相似的一个方法是传入一个可调用的类的实例,用于线程执行——这种方法更加接近面向对象的多线程编程。这种可调用的类包含一个执行环境,比起一个函数或者从一组函数中选择而言,有更好的灵活性。现在你有了一个类对象,而不仅仅是单个函数或者一个函数列表/元组。
在 mtsleepC.py 的代码中添加一个新类 ThreadFunc,并进行一些其他的轻微改动,得到mtsleepD.py,如示例 5 所示。
示例 5 使用可调用的类(
mtsleepD.py)
本例中,将传递进去一个可调用类(实例)而不仅仅是一个函数。相比于 mtsleepC.py,这个实现中提供了更加面向对象的方法。
import threading
from time import sleep, ctime
loops = [4, 2]
class ThreadFunc(object):
def __init__(self, func, args,
# name=''
):
# self.name = name
self.func = func
self.args = args
# __call__(self,\*args) 把实例对象作为函数调用
# 一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__()。
def __call__(self):
self.func(*self.args) # 拆包
def loop(nloop, nsec):
print('start loop', nloop, 'at:', ctime())
sleep(nsec)
print('loop', nloop, 'done at:', ctime())
def main():
print('starting at', ctime())
threads = []
nloops = range(len(loops)) # 返回[0, len(loops))范围内的一个可迭代对象(类型是对象),而不是列表类型,所以打印的时候不会打印列表。
for i in nloops: # create all threads
t = threading.Thread(target=ThreadFunc(loop, (i, loops[i]),
# loop.__name__
))
# print("loop.__name__", loop.__name__, type(loop.__name__)) # loop.__name__类名
# out: loop.__name__ loop 当运行 mtsleepD.py 时,得到了下面的输出:
$ mtsleepD.py
starting at Thu Feb 28 16:39:03 2019
start loop 0 at: Thu Feb 28 16:39:03 2019
start loop 1 at: Thu Feb 28 16:39:03 2019
loop 1 done at: Thu Feb 28 16:39:05 2019
loop 0 done at: Thu Feb 28 16:39:07 2019
all DONE at: Thu Feb 28 16:39:07 2019
那么,这次又修改了什么呢?主要是添加了 ThreadFunc 类,并在实例化 Thread 对象时做了一点小改动,同时实例化了可调用类 ThreadFunc。实际上,这里完成了两个实例化。让我们先仔细看看 ThreadFunc 类吧。
我们希望这个类更加通用,而不是局限于 loop()函数,因此添加了一些新的东西,比如让这个类保存了函数的参数、函数自身以及函数名的字符串。而构造函数__init__()用于设定上述这些值。
当创建新线程时, Thread 类的代码将调用 ThreadFunc 对象,此时会调用__call__()这个特殊方法。由于我们已经有了要用到的参数,这里就不需要再将其传递给 Thread()的构造函数了,直接调用即可。
派生 Thread 的子类,并创建子类的实例
最后要介绍的这个例子要调用 Thread()的子类,和上一个创建可调用类的例子有些相似。当创建线程时使用子类要相对更容易阅读(第 29~30 行)。示例 4~6 中给出mtsleepE.py的代码,并给出它执行的输出结果,最后会留给读者一个比较mtsleepE.py和mtsleepD.py的练习。
下面是 mtsleepE.py 的输出,和预期的一样。
$ mtsleepE.py
starting at Thu Feb 28 17:46:32 2019
start loop 0 at: Thu Feb 28 17:46:32 2019
start loop 1 at: Thu Feb 28 17:46:32 2019
loop 1 done at: Thu Feb 28 17:46:34 2019
loop 0 done at: Thu Feb 28 17:46:36 2019
all DONE at: Thu Feb 28 17:46:36 2019
示例 6 子类化的 Thread(
mtsleepE.py)
本例中将对 Thread 子类化,而不是直接对其实例化。这将使我们在定制线程对象时拥有更多的灵活性,也能够简
化线程创建的调用过程。
import threading
from time import sleep, ctime
loops = [4, 2]
class MyThread(threading.Thread):
def __init__(self, func, args,
# name=''
):
threading.Thread.__init__(self)
# self.name = name
self.func = func
self.args = args
def run(self):
self.func(*self.args)
def loop(nloop, nsec):
print('start loop', nloop, 'at:', ctime())
sleep(nsec)
print('loop', nloop, 'done at:', ctime())
def main():
print('starting at', ctime())
threads = []
nloops = range(len(loops))
for i in nloops: # create all threads
t = MyThread(loop, (i, loops[i])
# , loop.__name__
)
threads.append(t)
for i in nloops: # start all threads
threads[i].start()
for i in nloops: # wait for completion
threads[i].join()
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
当比较mtsleepD和mstsleepE这两个模块的代码时,注意其中的几个重要变化:
1)MyThread子类的构造函数必须先调用其基类的构造函数(第 9 行);
2)之前的特殊方法__call__()在这个子类中必须要写为 run()。
现在,对 MyThread 类进行修改,增加一些调试信息的输出,并将其存储为一个名为myThread 的独立模块(见示例 4-7),以便在接下来的例子中导入这个类。除了简单地调用函数外,还将把结果保存在实例属性 self.res 中,并创建一个新的方法 getResult()来获取这个值。
示例 7 Thread 子类 MyThread(
myThread.py)
为了让 mtsleepE.py 中实现的 Thread 的子类更加通用,将这个子类移到一个专门的模块中,并添加了可调用的getResult()方法来取得返回值。
import threading
from time import sleep, ctime
loops = [4, 2]
class MyThread(threading.Thread):
def __init__(self, func, args,
# name=''
):
threading.Thread.__init__(self)
# self.name = name
self.func = func
self.args = args
def getResult(self):
return self.res
def run(self):
print('starting', self.name, 'at:', ctime())
self.res = self.func(*self.args)
print(self.name, 'finished at:', ctime())
def loop(nloop, nsec):
# print('start loop', nloop, 'at:', ctime())
sleep(nsec)
# print('loop', nloop, 'done at:', ctime())
def main():
print('starting at', ctime())
threads = []
nloops = range(len(loops))
for i in nloops: # create all threads
t = MyThread(loop, (i, loops[i])
# , loop.__name__
)
threads.append(t)
for i in nloops: # start all threads
threads[i].start()
for i in nloops: # wait for completion
threads[i].join()
print('all DONE at:', ctime())
if __name__ == '__main__':
main()
执行结果:
$ python mtsleepE.py
starting at Thu Feb 28 21:53:19 2019
starting Thread-1 at: Thu Feb 28 21:53:19 2019
starting Thread-2 at: Thu Feb 28 21:53:19 2019
Thread-2 finished at: Thu Feb 28 21:53:21 2019
Thread-1 finished at: Thu Feb 28 21:53:23 2019
all DONE at: Thu Feb 28 21:53:23 2019
5.2 threading 模块的其他函数
除了各种同步和线程对象外, threading 模块还提供了一些函数,如表 4-4 所示。
表 4-4 threading 模块的函数
| 函 数 | 描 述 |
|---|---|
activeCount/ active_count()① |
当前活动的 Thread 对象个数 |
current Thread() / current_thread① |
返回当前的 Thread 对象 |
enumerate() |
返回当前活动的 Thread 对象列表 |
settrace(func) ② |
为所有线程设置一个 trace 函数 |
setprofile(func) ② |
为所有线程设置一个 profile 函数 |
stack_size(size=0) ③ |
返回新创建线程的栈大小;或为后续创建的线程设定栈的大小为 size |
① 驼峰式命名已经弃用,并且从 Python 2.6 版本起已经开始被取代。
② 自 Python 2.3 版本开始引入。
③ thread.stack_size()的一个别名,(都是)从 Python 2.5 版本开始引入的。
6. 单线程和多线程执行对比
示例 8 的mtfacfib.py脚本比较了递归求斐波那契、阶乘与累加函数的执行。该脚本按照单线程的方式运行这三个函数。之后使用多线程的方式执行同样的任务,用来说明多线程环境的优点。
示例 8 斐波那契、阶乘与累加(
mtfacfib.py)
在这个多线程应用中,将先后使用单线程和多线程的方式分别执行三个独立的递归函数。
import threading
from time import sleep, ctime
class MyThread(threading.Thread):
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args
def getResult(self):
return self.res
def run(self):
print('starting', self.name, 'at:', ctime())
self.res = self.func(*self.args)
print(self.name, 'finished at:', ctime())
def fib(x):
sleep(0.005)
if x < 2:
return 1
return (fib(x - 2) + fib(x - 1))
def fac(x):
sleep(0.1)
if x < 2:
return 1
return (x * fac(x - 1))
def sum(x):
sleep(0.1)
if x < 2:
return 1
return (x + sum(x - 1))
funcs = [fib, fac, sum]
n = 12
def main():
nfuncs = range(len(funcs))
print('*** SINGLE THREAD')
for i in nfuncs:
print('starting', funcs[i].__name__, 'at:', ctime())
print(funcs[i](n))
print(funcs[i].__name__, 'finished at:', ctime())
print('\n*** MULTIPLE THREADS')
threads = []
for i in nfuncs:
t = MyThread(funcs[i], (n, ), funcs[i].__name__)
threads.append(t)
for i in nfuncs:
threads[i].start()
for i in nfuncs:
threads[i].join()
print(threads[i].getResult())
print('all DONE')
if __name__ == '__main__':
main()
以单线程模式运行时,只是简单地依次调用每个函数,并在函数执行结束后立即显示相应的结果。
而以多线程模式运行时,并不会立即显示结果。 因为我们希望让 MyThread 类越通用越好(有输出和没有输出的调用都能够执行),我们要一直等到所有线程都执行结束,然后调用getResult()方法来最终显示每个函数的返回值。
因为这些函数执行起来都非常快(也许斐波那契函数除外),所以你会发现在每个函数中都加入了 sleep()调用,用于减慢执行速度,以便让我们看到多线程是如何改善性能的。在实际工作中,如果确实有不同的执行时间,你肯定不会在其中调用 sleep()函数。无论如何,下面是程序的输出结果。
$ python mtfacfib.py
*** SINGLE THREAD
starting fib at: Fri Mar 1 15:55:40 2019
233
fib finished at: Fri Mar 1 15:55:43 2019
starting fac at: Fri Mar 1 15:55:43 2019
479001600
fac finished at: Fri Mar 1 15:55:44 2019
starting sum at: Fri Mar 1 15:55:44 2019
78
sum finished at: Fri Mar 1 15:55:45 2019
*** MULTIPLE THREADS
starting fib at: Fri Mar 1 15:55:45 2019
starting fac at: Fri Mar 1 15:55:45 2019
starting sum at: Fri Mar 1 15:55:45 2019
fac finished at: Fri Mar 1 15:55:47 2019
sum finished at: Fri Mar 1 15:55:47 2019
fib finished at: Fri Mar 1 15:55:48 2019
233
479001600
78
all DONE
7. 多线程实践
到目前为止,我们已经见到的这些简单的示例片段都无法代表你要在实践中写出的代码。除了演示多线程和创建线程的不同方式外,之前的代码实际上什么有用的事情都没有做。我们启动这些线程以及等待它们结束的方式都是一样的,它们也全都睡眠。
3.1 节曾提到,由于 Python 虚拟机是单线程(GIL)的原因,只有线程在执行 I/O 密集型的应用时才能更好地发挥 Python 的并发性(对比计算密集型应用,它只需要做轮询),因此让我们看一个 I/O 密集型的例子,然后作为进一步的练习,尝试将其移植到 Python 3 中,以让你对向 Python 3 移植的处理有一定认识。
7.1 图书排名示例
示例 9 的 bookrank.py 脚本非常直接。它将前往我最喜欢的在线零售商之一 Amazon,然后请求你希望查询的图书的当前排名。在这个示例代码中,你可以看到函数 getRanking()使用正则表达式来拉取和返回当前的排名,而函数_showRanking()用于向用户显示结果。
请记住,根据 Amazon 的使用条件,“Amazon 对您在本网站的访问和个人使用授予有限许可,未经 Amazon 明确的书面同意,不允许对全部或部分内容进行下载(页面缓存除外)或修改。”在该程序中,我们所做的只是查询指定书籍的当前排名,没有任何其他操作,甚至都不会对页面进行缓存。
示例 4-9 是我们对于 bookrank.py 的第一次(不过与最终版本也很接近了)尝试,这是一个没有使用线程的版本。
示例 9 图书排名“Screenscraper”(
bookrank.py)
该脚本通过单线程进行下载图书排名信息的调用。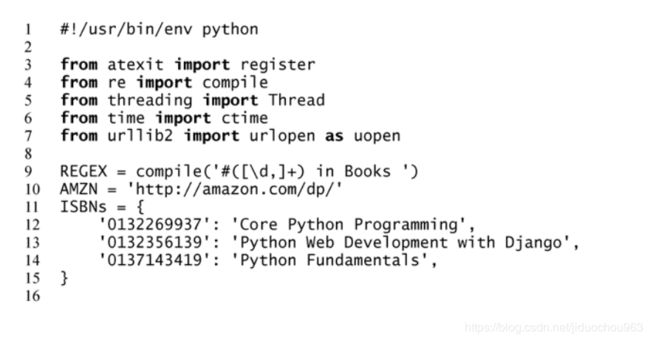

逐行解释
第 1~7 行
这些行用于启动和导入模块。这里将使用 atexit.register()函数来告知脚本何时结束(你将在后面看到原因)。这里还将使用正则表达式的 re.compile()函数,用于匹配 Amazon 商品页中图书排名的模式。然后,为未来的改进(很快就会出现)导入了 threading.Thread 模块,为显示时间戳字符串导入了 time.ctime(),为访问每个链接导入了 urllib2.urlopen()。
第 9~15 行
在脚本里使用了 3 个常量:正则表达式对象 REGEX(对匹配图书排名的正则模式进行了编译); Amazon 商品页基本链接 AMZN,为了使这个链接完整,我们只需要在最后填充上这本书的国际标准书号(ISBN),即用于区分不同作品的图书 ID。 ISBN 有两种标准: 10 字符长的 ISBN-10,以及它的新版——13 字符长的 ISBN-13。目前, Amazon 的系统对于两种
ISBN 格式都可以识别,这里使用了更短的 ISBN-10。在 ISBNs 字典中存储了这个值及其对应的书名。
第 17~21 行
getRanking()函数的用途是根据 ISBN,创建与 Amazon 服务器通信的最终 URL,然后调用 urllib2.urlopen()来打开这个地址。这里使用字符串格式化操作符来拼接 URL(第 18 行),如果你使用的是 2.6 或以上版本,也可以尝试 str.format()方法,比如'{0}{1}'.format(AMZN,isbn)。
得到完整的 URL 之后,调用 urllib2.urlopen()函数——这里简写为 uopen(),一旦 Web 服务器连接成功,就可以得到服务器返回的类似文件的对象。然后调用 read()函数下载整个网页,以及关闭这个“文件”。如果正则表达式与预期一样精确,应当有且只有一个匹配,因此从生成的列表中抓取这个值(任何额外的结果都将丢弃),并将其返回。
第 23~25 行
_showRanking()函数只有一小段代码,通过 ISBN,查询其对应的书名,调用 getRanking()函数从 Amazon 网站上获得这本书的当前排名,然后把这些值输出给用户。函数名最前面的单下划线表示这是一个特殊函数,只能被本模块的代码使用,不能被其他使用本文件作为库或者工具模块的应用导入。
第 27~30 行
_main()函数同样是一个特殊函数,只有这个模块从命令行直接运行时才会执行该函数(并且不能被其他模块导入)。该函数会显示起止时间(让用户了解整个脚本运行了多久),为每个 ISBN 调用_showRanking()函数以查询和显示其在 Amazon 上的当前排名。
第 32~37 行
这些行展现了一些完全不同的东西。 atexit.register()是什么呢?这个函数(这里使用了装饰器的方式)会在 Python 解释器中注册一个退出函数,也就是说,它会在脚本退出之 前 请 求 调 用 这 个 特 殊 函 数 。( 如 果 不 使 用 装 饰 器 的 方 式 , 也 可 以 直 接 使 用register(_atexit()))。
为什么要在这里使用这个函数呢?当然,目前而言,它并不是必需的。输出语句也可以放在第 27~31 行的_main()函数结尾,不过那里并不是一个真的好位置。另外,这也是一个可能会在某种情况下用于实际生产应用的功能。假设你知道第 36~37 行的含义,可以得到如下输出结果:
$ python bookrank.py
At Wed Mar 30 22:11:19 2011 PDT on Amazon...
- 'Core Python Programming' ranked 87,118
- 'Python Fundamentals' ranked 851,816
- 'Python Web Development with Django' ranked 184,735
all DONE at: Wed Mar 30 22:11:25 2011
你可能会感到疑惑,为什么我们会把数据的获取(getRanking())和显示(_showRanking()和_main())过程分开呢?这样做是为了防止你产生除了通过终端向用户显示结果以外的想法。在实践中,你可能会有将数据通过 Web 模板返回、存储在数据库中或者发送结果文本到手机上等需求。如果把所有代码都放在一个函数里,会难以复用和/或重新调整。
此外,如果 Amazon 修改了商品页的布局,你可能需要修改正则表达式“screenscraper”以继续从商品页提取数据。还需要说明的是,在这个简单的例子中使用正则表达式(或者只是简学的旧式字符串处理)是没有问题的,不过你可能需要一个更强大的标记解析器,比如标准库中的 HTMLParser,第三方工具 BeautifulSoup、 html5lib 或者 lxml(第 9 章会演示其中部分工具)。
引入线程
不需要你告诉我这仍然是一个愚蠢的单线程程序,我们接下来就要使用多线程来修改这个应用。由于这是一个 I/O 密集型应用,因此这个程序使用多线程是一个好的选择。简单起见,我们不会在这里使用任何类和面向对象编程,而是使用 threading 模块。我们将直接使用Thread 类,所以你可以认为这更像是 mtsleepC.py 的衍生品,而不是它之后的例子。我们将只是派生线程,然后立即启动这些线程。
将应用中的_showRanking(isbn)进行如下修改。
Thread(target=_showRanking, args=(isbn,)).start().
就是这样!现在,你得到了 bookrank.py 的最终版本,可以看出由于增加了并发,这个应用(一般)会运行得更快。不过,程序能够运行多快还取决于最慢的那个响应。
$ python bookrank.py
At Thu Mar 31 10:11:32 2011 on Amazon...
- 'Python Fundamentals' ranked 869,010
- 'Core Python Programming' ranked 36,481
- 'Python Web Development with Django' ranked 219,228
all DONE at: Thu Mar 31 10:11:35 2011
正如你在输出中所看到的,相比于单线程版本的 6 秒,多线程版本只需要运行 3 秒。而另外一个需要注意的是,多线程版本按照完成的顺序输出,而单线程版本按照变量的顺序。
在单线程版本中,顺序是由字典的键决定的,而现在查询是并发产生的,输出的先后则会由每个线程完成任务的顺序来决定。
在之前 mtsleepX.py 的例子中,对所有线程使用了 Thread.join()用于阻塞执行,直到每个线程都已退出。这可以有效阻止主线程在所有子线程都完成之前继续执行,所以输出语句“all DONE at”可以在正确的时间调用。
在这些例子中,对所有线程调用 join()并不是必需的,因为它们不是守护线程。无论如何主线程都不会在派生线程完成之前退出脚本。由于这个原因,我们将在 mtsleepF.py中删除所有的 join()操作。不过,要意识到如果我们在同一个地方显示“all done”这是不正确的。
主线程会在其他线程完成之前显示“ all done”,所以我们不能再把 print 调用放在_main()里了。有两个地方可以放置 print 语句:第 37 行_main()返回之后(脚本最后一行),或者使用 atexit.register()来注册一个退出函数。因为之前没有讨论过后面这种方法,而且它可能对你以后更有帮助,所以我们认为这是一个介绍它的好位置。此外,这还是一个在 Python 2 和 3 中保持一致的接口,接下来我们就要挑战如何将这个程序移植到 Python 3中了。
移植到 Python 3
下面我们希望这个脚本能够在 Python 3 中运行。对于项目和应用而言,都需要继续进行迁移,这是你必须要熟悉的事情。幸运的是,有一些工具可以帮助我们,其中之一是 2to3 这个工具。它的一般用法如下。
$ 2to3 foo.py # only output diff
$ 2to3 -w foo.py # overwrites w/3.x code
在第一条命令中, 2to3 工具只是显示原始脚本的 2.x 版本与其生成的等价的 3.x 版本的区别。而-w 标志则让 2to3 工具使用新生成的 3.x 版本的代码重写原始脚本,并将 2.x 版本重命名为 foo.py.bak。
让我们对 bookrank.py 运行 2to3 工具,在已有的文件上进行改写。除了给出区别外,它还会像之前描述的那样保存新版本的脚本。
$ 2to3 -w bookrank.py
RefactoringTool: Skipping implicit fixer: buffer
RefactoringTool: Skipping implicit fixer: idioms
RefactoringTool: Skipping implicit fixer: set_literal
RefactoringTool: Skipping implicit fixer: ws_comma
--- bookrank.py (original)
+++ bookrank.py (refactored)
@@ -4,7 +4,7 @@
from re import compile
from threading import Thread
from time import ctime
-from urllib2 import urlopen as uopen
+from urllib.request import urlopen as uopen
REGEX = compile('#([\d,]+) in Books ')
AMZN = 'http://amazon.com/dp/'
@@ -21,17 +21,17 @@
return REGEX.findall(data)[0]
def _showRanking(isbn):
- print '- %r ranked %s' % (
- ISBNs[isbn], getRanking(isbn))
+ print('- %r ranked %s' % (
+ ISBNs[isbn], getRanking(isbn)))
def _main():
- print 'At', ctime(), 'on Amazon...'
+ print('At', ctime(), 'on Amazon...')
for isbn in ISBNs:
Thread(target=_showRanking,
args=(isbn,)).start()#_showRanking(isbn)
@register
def _atexit():
- print 'all DONE at:', ctime()
+ print('all DONE at:', ctime())
if __name__ == '__main__':
_main()
RefactoringTool: Files that were modified:
RefactoringTool: bookrank.py
接下来的步骤对于读者而言是可选的,我们使用 POSIX 命令行将文件重命名为bookrank.py 和 bookrank3.py(Windows 用户应当使用 ren 命令)。
$ mv bookrank.py bookrank3.py
$ mv bookrank.py.bak bookrank.py
如果你尝试运行新生成的代码,就会发现假定它是一个完美翻译,不需要你再做任何操作的想法只是你的一厢情愿。糟糕的事情发生了,你会在每个线程执行时得到如下异常信息(下面的输出只针对一个线程,因为每个线程的输出都一样)。
$ python3 bookrank3.py
Exception in thread Thread-1:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/
3.2/lib/python3.2/threading.py", line 736, in
_bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/
3.2/lib/python3.2/threading.py", line 689, in run
self._target(*self._args, **self._kwargs)
File "bookrank3.py", line 25, in _showRanking
ISBNs[isbn], getRanking(isbn)))
File "bookrank3.py", line 21, in getRanking
return REGEX.findall(data)[0]
TypeError: can't use a string pattern on a bytes-like object
:
问题看起来是:正则表达式是一个 Unicode 字符串,而 urlopen()返回来的类似文件对象的结果经过 read()方法得到的是一个 ASCII/bytes 字符串。这里的修复方案是将其编译为一个bytes 对象,而不是文本字符串。因此,修改第 9 行,让 re.compile()编译一个 bytes 字符串(通过添加 bytes 字符串)。为了做到这个,可以在左侧的引号前添加一个 bytes 字符串的标记 b,如下所示。
REGEX = compile(b'#([\d,]+) in Books ')
现在,让我们再试一次。
$ python3 bookrank3.py
At Sun Apr 3 00:45:46 2011 on Amazon...
- 'Core Python Programming' ranked b'108,796'
- 'Python Web Development with Django' ranked b'268,660'
- 'Python Fundamentals' ranked b'969,149'
all DONE at: Sun Apr 3 00:45:49 2011
现在又是什么问题呢?虽然这个输出结果比之前要好一些(没有错误),但是它看起来还是有些奇怪。当传给 str()时,正则表达式抓取的排名值显示了 b 和引号。你的第一直觉可能是尝试丑陋的字符串切片。
>>> x = b'xxx'
>>> repr(x)
"b'xxx'"
>>> str(x)
"b'xxx'"
>>> str(x)[2:-1]
'xxx'
不过,更合适的方法是将其转换为一个真正的(Unicode)字符串,可能会用到 UTF-8。
>>> str(x, 'utf-8')
'xxx'
为了实现这一点,在脚本里,对第 53 行进行一个类似的修改,如下所示。
return str(REGEX.findall(data)[0], 'utf-8')
现在, Python 3 版本的脚本输出就和 Python 2 的脚本一致了。
$ python3 bookrank3.py
At Sun Apr 3 00:47:31 2011 on Amazon...
- 'Python Fundamentals' ranked 969,149
- 'Python Web Development with Django' ranked 268,660
- 'Core Python Programming' ranked 108,796
all DONE at: Sun Apr 3 00:47:34 2011
一般来说,你会发现从 2.x 版本移植到 3.x 版本会遵循类似下面的模式:你需要确保所有的单元测试和集成测试都已经通过,使用 2to3(或其他工具)进行所有的基础修改,然后进行一些善后工作,让代码运行起来并通过相同的测试。我们将在下一个例子中再次尝试这个练习,这个例子将演示线程同步的使用。
7.2 同步原语
在本章的主要部分,我们了解了线程的基本概念,以及如何在 Python 应用中利用线程。然而,我们遗漏了多线程编程中一个非常重要的方面:同步。一般在多线程代码中,总会有一些特定的函数或代码块不希望(或不应该)被多个线程同时执行,通常包括修改数据库、更新文件或其他会产生竞态条件的类似情况。回顾本章前面的部分,如果两个线程运行的顺序发生变化,就有可能造成代码的执行轨迹或行为不相同,或者产生不一致的数据(可以在 Wikipedia 页面上阅读有关竞态条件的更多信息: http://en.wikipedia.org/wiki/Race_condition )。
这 就 是 需 要 使 用 同 步 的 情 况 。 当 任 意 数 量 的 线 程 可 以 访 问 临 界 区 的 代 码
( http://en.wikipedia.org/wiki/Critical_section )但在给定的时刻只有一个线程可以通过时,就是使用同步的时候了。程序员选择适合的同步原语,或者线程控制机制来执行同步。进程同步有不同的类型(参见 http://en.wikipedia.org/wiki/Synchronization_(computer_science) ), Python 支持多种同步类型,可以给你足够多的选择,以便选出最适合完成任务的那种类型。
本章前面对同步进行过一些介绍,所以这里就使用其中两种类型的同步原语演示几个示例程序:锁/互斥,以及信号量。锁是所有机制中最简单、最低级的机制,而信号量用于多线程竞争有限资源的情况。锁比较容易理解,因此先从锁开始,然后再讨论信号量。
7.3 锁示例
锁有两种状态:锁定和未锁定。而且它也只支持两个函数:获得锁和释放锁。它的行为和你想象的完全一样。
当多线程争夺锁时,允许第一个获得锁的线程进入临界区,并执行代码。所有之后到达的线程将被阻塞,直到第一个线程执行结束,退出临界区,并释放锁。此时,其他等待的线程可以获得锁并进入临界区。不过请记住,那些被阻塞的线程是没有顺序的(即不是先到先执行),胜出线程的选择是不确定的,而且还会根据 Python 实现的不同而有所区别。
让我们来看看为什么锁是必需的。 mtsleepF.py 应用派生了随机数量的线程,当每个线程执行结束时它会进行输出。下面是其核心部分的源码(Python 2)。
from atexit import register
from random import randrange
from threading import Thread, currentThread
from time import sleep, ctime
class CleanOutputSet(set):
def str(self):
return ', ‘.join(x for x in self)
loops = (randrange(2,5) for x in xrange(randrange(3,7)))
remaining = CleanOutputSet()
def loop(nsec):
myname = currentThread().name
remaining.add(myname)
print ‘[%s] Started %s’ % (ctime(), myname)
sleep(nsec)
remaining.remove(myname)
print ‘[%s] Completed %s (%d secs)’ % (
ctime(), myname, nsec)
print ’ (remaining: %s)’ % (remaining or ‘NONE’)
def _main():
for pause in loops:
Thread(target=loop, args=(pause,)).start()
@register
def _atexit():
print ‘all DONE at:’, ctime()
当我们完成这个使用锁的代码后,会有一个比较详细的逐行解释,不过mtsleepF.py所做的基本上就是之前例子的扩展。和 bookrank.py 一样,为了简化代码,没有使用面向对象编程,删除了线程对象列表和线程的 join(),重用了 atexit.register()(和 bookrank.py相同的原因)。
另一个和之前的那些 mtsleepX.py 例子不同的地方是,这里不再把循环/线程对硬编码成睡眠 4 秒和 2 秒,而是将它们随机地混合在一起,创建 3~6 个线程,每个线程睡眠2~4 秒。
这里还有一个新功能,使用集合来记录剩下的还在运行的线程。我们对集合进行了子类化而不是直接使用,这是因为我们想要演示另一个用例:变更集合的默认可印字符串。当显示一个集合时,你会得到类似 set([X, Y, Z,…])这样的输出。而应用的用户并不需要(也不应该)知道关于集合的信息,或者我们使用了这些集合。我们只需要显示成类似 X, Y, Z, …这样即可。这也就是派生了 set 类并实现了它的__str__()方法的原因。
如果幸运,进行了这些改变之后,输出将会按照适当的顺序给出。
$ python mtsleepF.py
[Sat Apr 2 11:37:26 2011] Started Thread-1
[Sat Apr 2 11:37:26 2011] Started Thread-2
[Sat Apr 2 11:37:26 2011] Started Thread-3
[Sat Apr 2 11:37:29 2011] Completed Thread-2 (3 secs)
(remaining: Thread-3, Thread-1)
[Sat Apr 2 11:37:30 2011] Completed Thread-1 (4 secs)
(remaining: Thread-3)
[Sat Apr 2 11:37:30 2011] Completed Thread-3 (4 secs)
(remaining: NONE)
all DONE at: Sat Apr 2 11:37:30 2011
不过,如果不幸,你将会得到像下面几对执行示例这样奇怪的输出结果。
$ python mtsleepF.py
[Sat Apr 2 11:37:09 2011] Started Thread-1
[Sat Apr 2 11:37:09 2011] Started Thread-2
[Sat Apr 2 11:37:09 2011] Started Thread-3
[Sat Apr 2 11:37:12 2011] Completed Thread-1 (3 secs)
[Sat Apr 2 11:37:12 2011] Completed Thread-2 (3 secs)
(remaining: Thread-3)
(remaining: Thread-3)
[Sat Apr 2 11:37:12 2011] Completed Thread-3 (3 secs)
(remaining: NONE)
all DONE at: Sat Apr 2 11:37:12 2011
$ python mtsleepF.py
[Sat Apr 2 11:37:56 2011] Started Thread-1
[Sat Apr 2 11:37:56 2011] Started Thread-2
[Sat Apr 2 11:37:56 2011] Started Thread-3
[Sat Apr 2 11:37:56 2011] Started Thread-4
[Sat Apr 2 11:37:58 2011] Completed Thread-2 (2 secs)
[Sat Apr 2 11:37:58 2011] Completed Thread-4 (2 secs)
(remaining: Thread-3, Thread-1)
(remaining: Thread-3, Thread-1)
[Sat Apr 2 11:38:00 2011] Completed Thread-1 (4 secs)
(remaining: Thread-3)
[Sat Apr 2 11:38:00 2011] Completed Thread-3 (4 secs)
(remaining: NONE)
all DONE at: Sat Apr 2 11:38:00 2011
那么出现什么问题了呢?一个问题是,输出可能部分混乱(因为多个线程可能并行执行I/O)。同样地,之前的几个示例代码也都有交错输出的问题存在。而另一问题则出现在两个线程修改同一个变量(剩余线程名集合)时。
I/O 和访问相同的数据结构都属于临界区,因此需要用锁来防止多个线程同时进入临界区。为了加锁,需要添加一行代码来引入 Lock(或 RLock),然后创建一个锁对象,因此需要添加/修改代码以便在合适的位置上包含这些行。
from threading import Thread, Lock, currentThread
lock = Lock()
现在应该使用刚创建的这个锁了。下面代码中突出显示的 acquire()和 release()调用就是应当在 loop()函数中添加的语句。
def loop(nsec):
myname = currentThread().name
lock.acquire()
remaining.add(myname)
print ‘[%s] Started %s’ % (ctime(), myname)
lock.release()
sleep(nsec)
lock.acquire()
remaining.remove(myname)
print ‘[%s] Completed %s (%d secs)’ % (
ctime(), myname, nsec)
print ’ (remaining: %s)’ % (remaining or ‘NONE’)
lock.release()
一旦做了这个改变,就不会再产生那种奇怪的输出了。
$ python mtsleepF.py
[Sun Apr 3 23:16:59 2011] Started Thread-1
[Sun Apr 3 23:16:59 2011] Started Thread-2
[Sun Apr 3 23:16:59 2011] Started Thread-3
[Sun Apr 3 23:16:59 2011] Started Thread-4
[Sun Apr 3 23:17:01 2011] Completed Thread-3 (2 secs)
(remaining: Thread-4, Thread-2, Thread-1)
[Sun Apr 3 23:17:01 2011] Completed Thread-4 (2 secs)
(remaining: Thread-2, Thread-1)
[Sun Apr 3 23:17:02 2011] Completed Thread-1 (3 secs)
(remaining: Thread-2)
[Sun Apr 3 23:17:03 2011] Completed Thread-2 (4 secs)
(remaining: NONE)
all DONE at: Sun Apr 3 23:17:03 2011
修改后的最终版 mtsleepF.py 如示例 10 所示。
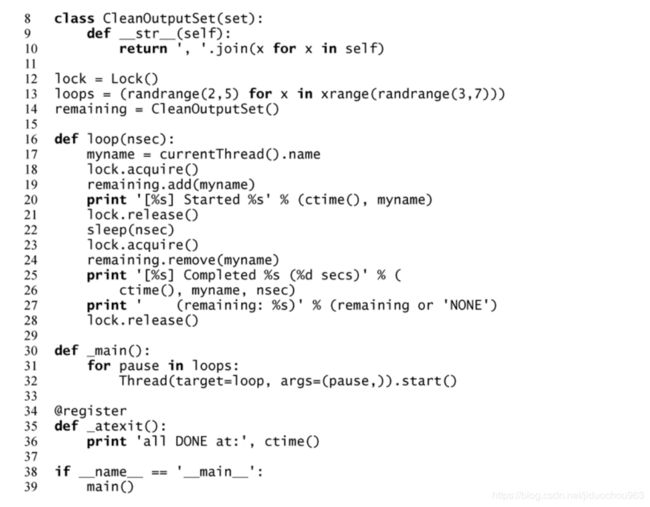
示例 10 锁和更多的随机性(
mtsleepF.py)
在本示例中,演示了锁和一些其他线程工具的使用。

逐行解释
第 1~6 行
这部分按照惯例是启动行和导入模块的行。请注意, threading.currentThread()从 2.6 版本开始重命名为 threading.current_thread(),不过为了保持后向兼容性,旧的写法仍旧保留了下来。
第 8~10 行
这是之前提到过的集合的子类。它包括一个对__str__()的实现,可以将默认输出改变为将其所有元素按照逗号分隔的字符串。
第 12~14 行
该部分包含 3 个全局变量:锁;上面提到的修改后的集合类的实例;随机数量的线程(3~6 个线程),每个线程暂停或睡眠 2~4 秒。
第 16~28 行
loop()函数首先保存当前执行它的线程名,然后获取锁,以便使添加该线程名到 remaining集合以及指明启动线程的输出操作是原子的(没有其他线程可以进入临界区)。释放锁之后,这个线程按照预先指定的随机秒数执行睡眠操作,然后重新获得锁,进行最终输出,最后释放锁。
第 30~39 行
只有不是为了在其他地方使用而导入的情况下, _main()函数才会执行。它的任务是派生和执行每个线程。和之前提到的一样,使用 atexit.register()来注册_atexit()函数,以便让解释器在脚本退出前执行该函数。
作为维护你自己的当前运行线程集合的一种替代方案,可以考虑使用 threading.enumerate(),该方法会返回仍在运行的线程列表(包括守护线程,但不包括没有启动的线程)。在本例中并没有使用这个方案,因为它会显示两个额外的线程,所以我们需要删除这两个线程以保持输出的简洁。这两个线程是当前线程(因为它还没结束),以及主线程(没有必要去显示)。
此外,如果你使用的是 Python 2.6 或更新的版本(包括 3.x 版本),别忘了还可以使用str.format()方法来代替字符串格式化操作符。换句话说, print 语句
print ‘[%s] Started %s’ % (ctime(), myname)
可以在 2.6+版本中被替换成
print ‘[{0}] Started {1}’.format(ctime(), myname)
或者在 3.x 版本中调用 print()函数:
print(’[{0}] Started {1}’.format(ctime(), myname))
如果只需要对当前运行的线程进行计数,那么可以使用 threading.activeCount()(2.6 版本开始重命名为 active_count())来代替。
使用上下文管理
如果你使用 Python 2.5 或更新版本,还有一种方案可以不再调用锁的 acquire()和 release()方法,从而更进一步简化代码。这就是使用 with 语句,此时每个对象的上下文管理器负责在进入该套件之前调用 acquire()并在完成执行之后调用 release()。
threading 模块的对象 Lock、 RLock、 Condition、 Semaphore 和 BoundedSemaphore 都包含上下文管理器,也就是说,它们都可以使用 with 语句。当使用 with 时,可以进一步简化 loop()循环,如下面的代码所示。
from __future__ import with_statement # 2.5 only
def loop(nsec):
myname = currentThread().name
with lock:
remaining.add(myname)
print '[%s] Started %s' % (ctime(), myname)
sleep(nsec)
with lock:
remaining.remove(myname)
print '[%s] Completed %s (%d secs)' % (
ctime(), myname, nsec)
print ' (remaining: %s)' % (
remaining or 'NONE',)
移植到 Python 3
现在通过对之前的脚本运行 2to3 工具,进行向 Python 3.x 版本的移植(下面的输出进行了截断,因为之前已经看到过完整的 diff 转储)。
$ 2to3 -w mtsleepF.py
RefactoringTool: Skipping implicit fixer: buffer
RefactoringTool: Skipping implicit fixer: idioms
RefactoringTool: Skipping implicit fixer: set_literal
RefactoringTool: Skipping implicit fixer: ws_comma
:
RefactoringTool: Files that were modified:
RefactoringTool: mtsleepF.py
当把 mtsleepF.py 重命名为 mtsleepF3.py 并把 mtsleep.py.bak 重命名为 mtsleepF.py后,我们会发现,这一次出乎我们的意料,这个脚本移植得非常完美,没有出现任何问题。
$ python3 mtsleepF3.py
[Sun Apr 3 23:29:39 2011] Started Thread-1
[Sun Apr 3 23:29:39 2011] Started Thread-2
[Sun Apr 3 23:29:39 2011] Started Thread-3
[Sun Apr 3 23:29:41 2011] Completed Thread-3 (2 secs)
(remaining: Thread-2, Thread-1)
[Sun Apr 3 23:29:42 2011] Completed Thread-2 (3 secs)
(remaining: Thread-1)
[Sun Apr 3 23:29:43 2011] Completed Thread-1 (4 secs)
(remaining: NONE)
all DONE at: Sun Apr 3 23:29:43 2011
现在让我们带着关于锁的知识,开始介绍信号量,然后看一个既使用了锁又使用了信号量的例子。
7.4 信号量示例
如前所述,锁非常易于理解和实现,也很容易决定何时需要它们。然而,如果情况更加复杂,你可能需要一个更强大的同步原语来代替锁。对于拥有有限资源的应用来说,使用信号量可能是个不错的决定。
信号量是最古老的同步原语之一。它是一个计数器,当资源消耗时递减,当资源释放时递增。你可以认为信号量代表它们的资源可用或不可用。消耗资源使计数器递减的操作习惯上称为 P() (来源于荷兰单词 probeer/proberen),也称为 wait、try、acquire、pend 或 procure。
相对地,当一个线程对一个资源完成操作时,该资源需要返回资源池中。这个操作一般称为 V()(来源于荷兰单词 verhogen/verhoog),也称为 signal、 increment、 release、 post、 vacate。
Python 简化了所有的命名,使用和锁的函数/方法一样的名字: acquire 和 release。信号量比锁更加灵活,因为可以有多个线程,每个线程拥有有限资源的一个实例。
在下面的例子中,我们将模拟一个简化的糖果机。这个特制的机器只有 5 个可用的槽来保持库存(糖果)。如果所有的槽都满了,糖果就不能再加到这个机器中了;相似地,如果每个槽都空了,想要购买的消费者就无法买到糖果了。我们可以使用信号量来跟踪这些有限的资源(糖果槽)。示例 11 为其源代码(candy.py)。
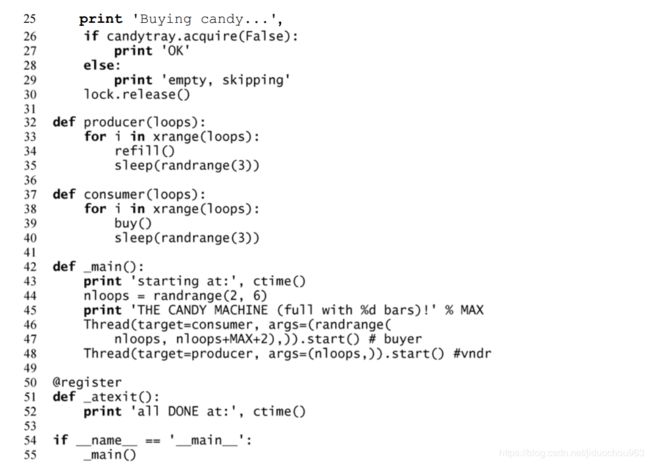
示例 4-11 糖果机和信号量(
candy.py)
该脚本使用了锁和信号量来模拟一个糖果机。

逐行解释
第 1~6 行
启动行和导入模块的行与本章中之前的例子非常相似。唯一新增的东西是信号量。
threading 模块包括两种信号量类: Semaphore 和 BoundedSemaphore。如你所知,信号量实际上就是计数器,它们从固定数量的有限资源起始。
当分配一个单位的资源时,计数器值减 1,而当一个单位的资源返回资源池时,计数器值加 1。 BoundedSemaphore 的一个额外功能是这个计数器的值永远不会超过它的初始值,换句话说,它可以防范其中信号量释放次数多于获得次数的异常用例。
第 8~10 行
这个脚本的全局变量包括:一个锁,一个表示库存商品最大值的常量,以及糖果托盘。
第 12~21 行
当虚构的糖果机所有者向库存中添加糖果时,会执行 refill()函数。这段代码是一个临界区,这就是为什么获取锁是执行所有行的仅有方法。代码会输出用户的行动,并在某人添加的糖果超过最大库存时给予警告(第 17~18 行)。
第 23~30 行
buy()是和 refill()相反的函数,它允许消费者获取一个单位的库存。条件语句(第 26 行)检测是否所有资源都已经消费完。计数器的值不能小于 0,因此这个调用一般会在计数器再次增加之前被阻塞。通过传入非阻塞的标志 False,让调用不再阻塞,而在应当阻塞的时候返回一个 False,指明没有更多的资源了。
第 32~40 行
producer()和 consumer()函数都只包含一个循环,进行对应的 refill()和 buy()调用,并在调用间暂停。
第 42~55 行
代码的剩余部分包括:对_main()的调用(如果脚本从命令行执行),退出函数的注册,以及最后的_main()函数提供表示糖果库存生产者和消费者的新创建线程对。
创建消费者/买家的线程时进行了额外的数学操作,用于随机给出正偏差,使得消费者真正消费的糖果数可能会比供应商/生产者放入机器的更多(否则,代码将永远不会进入消费者尝试从空机器购买糖果的情况)。运行脚本,会产生类似下面的输出结果。
$ python candy.py
starting at: Mon Apr 4 00:56:02 2011
THE CANDY MACHINE (full with 5 bars)!
Buying candy… OK
Refilling candy… OK
Refilling candy… full, skipping
Buying candy… OK
Buying candy… OK
Refilling candy… OK
Buying candy… OK
Buying candy… OK
Buying candy… OK
all DONE at: Mon Apr 4 00:56:08 2011
移植到 Python 3
与 mtsleepF.py 类似 candy.py,又是一个使用 2to3 工具生成可运行的 Python 3 版本的例子,这里将其重命名为 candy3.py。将把这次移植作为一个练习留给读者来完成。
总结
这里只演示了 threading 模块的两个同步原语,还有很多同步原语需要你去探索。不过,请记住它们只是原语。虽然使用它们来构建你自己的线程安全的类和数据结构没有问题,但是要了解 Python 标准库中也包含了一个实现: Queue 对象。
核心提示:进行调试
在某种情况下,你可能需要调试一个使用了信号量的脚本,此时你可能需要知道在任意给定时刻信号量计数器的精确值。在本章结尾的一个练习中,你将为 candy.py 实现一个显示计数器值的解决方案,或许可以将其称为 candydebug.py。为了做到这一点,需要查阅threading.py 的源码(可能需要查阅 Python 2 和 Python 3 两个版本)。
你会发现 threading 模块的同步原语并不是类名,即便它们使用了驼峰式拼写方法,看起来像是类名。实际上,它们是仅有一行的函数,用来实例化你认为的那个类的对象。
这里有两个问题需要考虑:其一,你不能对它们子类化(因为它们是函数);其二,变量名在 2.x 和 3.x 版本间发生了改变。
如果这个对象可以给你整洁/简单地访问计数器的方法,整个问题就可以避免了,但实际上并没有。如前所述,计数器的值只是类的一个属性,所以可以直接访问它,这个变量名从 Python2 版本的 self.__value,即 self._Semaphore__value,变成了 Python 3 版本的 self.value。
对于开发者而言,最简洁的 API(至少我们的意见)是继承 threading.BoundedSemaphore类,并实现一个__len()方法,不过要注意,如果你计划对 2.x 和 3.x 版本都支持,还是需要使用刚才讨论过的那个正确的计数器值。
8. 生产者-消费者问题和 Queue/queue 模块
最后一个例子演示了生产者-消费者模型这个场景。在这个场景下,商品或服务的生产者生产商品,然后将其放到类似队列的数据结构中。生产商品的时间是不确定的,同样消费者消费生产者生产的商品的时间也是不确定的。
我们使用 Queue 模块(Python 2.x 版本,在 Python 3.x 版本中重命名为 queue)来提供线程间通信的机制,从而让线程之间可以互相分享数据。具体而言,就是创建一个队列,让生产者(线程)在其中放入新的商品,而消费者(线程)消费这些商品。表 4-5 列举了这个模块中的一些属性。
表 4-5 Queue/queue 模块常用属性
属 性 描 述
Queue/queue 模块的类
Queue(maxsize=0) 创建一个先入先出队列。如果给定最大值,则在队列没有空间时阻塞;否则(没
有指定最大值),为无限队列
LifoQueue(maxsize=0) 创建一个后入先出队列。如果给定最大值,则在队列没有空间时阻塞;否则(没
有指定最大值),为无限队列
属 性 描 述
PriorityQueue(maxsize=0) 创建一个优先级队列。如果给定最大值,则在队列没有空间时阻塞,否则(没
有指定最大值) ,为无限队列
Queue/queue 异常
Empty 当对空队列调用 get*()方法时抛出异常
Full 当对已满的队列调用 put*()方法时抛出异常
Queue/queue 对象方法
qsize () 返回队列大小(由于返回时队列大小可能被其他线程修改,所以该值为近似值)
empty() 如果队列为空,则返回 True;否则,返回 False
full() 如果队列已满,则返回 True;否则,返回 False
put (item, block=Ture, timeout=None) 将 item 放入队列。如果 block 为 True(默认)且 timeout 为 None,则在有可用
空间之前阻塞;如果 timeout 为正值,则最多阻塞 timeout 秒;如果 block 为 False,
则抛出 Empty 异常
put_nowait(item) 和 put(item, False)相同
get (block=True, timeout=None) 从队列中取得元素。如果给定了 block(非 0),则一直阻塞到有可用的元素
为止
get_nowait() 和 get(False)相同
task_done() 用于表示队列中的某个元素已执行完成,该方法会被下面的 join()使用
join() 在队列中所有元素执行完毕并调用上面的 task_done()信号之前,保持阻塞
我们将使用示例 4-12( prodcons.py)来演示生产者-消费者 Queue/queue。下面是这个脚本某次执行的输出。
$ prodcons.py
starting writer at: Sun Jun 18 20:27:07 2006
producing object for Q… size now 1
starting reader at: Sun Jun 18 20:27:07 2006
consumed object from Q… size now 0
producing object for Q… size now 1
consumed object from Q… size now 0
producing object for Q… size now 1
producing object for Q… size now 2
producing object for Q… size now 3
consumed object from Q… size now 2
consumed object from Q… size now 1
writer finished at: Sun Jun 18 20:27:17 2006
consumed object from Q… size now 0
reader finished at: Sun Jun 18 20:27:25 2006
all DONE
示例 12 生产者-消费者问题(
prodcons.py)
该生产者-消费者问题的实现使用了 Queue 对象,以及随机生产(消费)的商品的数量。生产者和消费者独立且并发地执行线程。

如你所见,生产者和消费者并不需要轮流执行。(感谢随机数!)严格来说,现实生活通常都是随机和不确定的。
逐行解释
第 1~6 行
在本模块中,使用了 Queue.Queue 对象,以及之前给出的 myThread.MyThread 线程类。另外还使用了 random.randint()以使生产和消费的数量有所不同(注意, random.randint()与random.randrange()类似,不过它会包括其上限值)。
第 8~16 行
writeQ()和 readQ()函数分别用于将一个对象(例如,我们这里使用的字符串’xxx’)放入队列中和消费队列中的一个对象。注意,我们每次只会生产或读取一个对象。
第 18~26 行
writer()将作为单个线程运行,其目的只有一个:向队列中放入一个对象,等待片刻,然后重复上述步骤,直至达到每次脚本执行时随机生成的次数为止。 reader()与之类似,只不过变成了消耗对象。
你会注意到, writer 睡眠的随机秒数通常比 reader 的要短。这是为了阻碍 reader 从空队列中获取对象。通过给 writer 一个更短的等候时间,使得轮到 reader 时,已存在可消费对象的可能性更大。
第 28~29 行
这两行用于设置派生和执行的线程总数。
第 31~47 行
最后是 main()函数,该函数和本章中其他脚本的 main()函数都非常相似。这里创建合适的线程并让它们执行,当两个线程都执行完毕后结束。
从本例中可以得出,对于一个要执行多个任务的程序,可以让每个任务使用单独的线程。相比于使用单线程程序完成所有任务,这种程序设计方式更加整洁。
本章阐述了单线程进程是如何限制应用的性能的。尤其是对于那些任务执行顺序存在着独立性、不确定性以及非因果性的程序而言,把多个任务分配到不同线程执行对性能的改善会非常大。由于线程的开销以及 Python 解释器是单线程应用这个事实,并不是所有应用都可以从多线程中获益,不过现在你已经了解到了 Python 多线程的功能,你可以在适当的时候使用该工具来发挥它的优势。
9. 线程的替代方案
在开始编写多线程应用之前,先做一个快速回顾:通常来说,多线程是一个好东西。不过,由于 Python 的 GIL 的限制,多线程更适合于 I/O 密集型应用(I/O 释放了 GIL,可以允许更多的并发),而不是计算密集型应用。对于后一种情况而言,为了实现更好的并行性,你需要使用多进程,以便让 CPU 的其他内核来执行。
这里将不再进行详细介绍(这个主题内已经在 Core Python Programming 或 Core Python Language Fundamentals 的“执行环境”章节中有所涵盖),对于多线程或多进程而言, threading模块的主要替代品包括以下几个。
9.1 subprocess 模块
这是派生进程的主要替代方案,可以单纯地执行任务,或者通过标准文件(stdin、 stdout、stderr)进行进程间通信。该模块自 Python 2.4 版本起引入。
9.2 multiprocessing 模块
该模块自 Python 2.6 版本起引入,允许为多核或多 CPU 派生进程,其接口与 threading模块非常相似。该模块同样也包括在共享任务的进程间传输数据的多种方式。
9.3 concurrent.futures 模块
这是一个新的高级库,它只在“任务”级别进行操作,也就是说,你不再需要过分关注同步和线程/进程的管理了。你只需要指定一个给定了“worker”数量的线程/进程池,提交任务,然后整理结果。该模块自 Python 3.2 版本起引入,不过有一个 Python 2.6+可使用的移植版本,其网址为 http://code.google.com/p/pythonfutures。
使用该模块重写后 bookrank3.py 会是什么样子呢?假定代码的其他部分保持不变,下面的代码是新模块的导入以及对_main()函数的修改。
from concurrent.futures import ThreadPoolExecutor
. . .
def _main():
print(‘At’, ctime(), ‘on Amazon…’)
with ThreadPoolExecutor(3) as executor:
for isbn in ISBNs:
executor.submit(_showRanking, isbn)
print(‘all DONE at:’, ctime())
传递给 concurrent.futures.ThreadPoolExecutor 的参数是线程池的大小,在这个应用里就是指要查阅排名的 3 本书。当然,这是个 I/O 密集型应用,因此多线程更有用。而对于计算密集型应用而言,可以使用 concurrent.futures.ProcessPoolExecutor 来代替。
当我们得到执行器(无论线程还是进程)之后,它负责调度任务和整理结果,就可以调用它的 submit()方法,来执行之前需要派生线程才能运行的那些操作了。
如果我们做一个到Python 3的完全移植,方法是将字符串格式化操作符替换为str.format()方法,自由利用 with 语句,并使用执行器的 map()方法,那么我们完全可以删除_showRanking()函数并将其功能混入_main()函数中。示例 4-13 的 bookrank3CF.py 是该脚本的最终版本。
示例 13 高级任务管理(
bookrank3CF.py)
使用了 concurrent.futures 模块的图书排名 screenscraper。

逐行解释
第 1~14 行
除了新的 import 语句以外,该脚本的前半部分都和本章之前的 bookrank3.py 相同。
第 16~18 行
新的 getRanking()函数使用了 with 语句以及 str.format()。也可以对 bookrank.py 进行相同的修改,因为这些功能在 Python 2.6+版本上都是可用的(它们不只用于 3.x 版本)。
第 20~26 行
在前面的例子中,使用了 executor.submit()来派生作业。这里使用 executor.map()进行轻微的调整,从而将_showRanking()函数的功能合并进来,然后将该函数从代码中完全删除。
输出结果与之前看到的基本一致。
$ python3 bookrank3CF.py
At Wed Apr 6 00:21:50 2011 on Amazon…
- ‘Core Python Programming’ ranked 43,992
- ‘Python Fundamentals’ ranked 1,018,454
- ‘Python Web Development with Django’ ranked 502,566
all DONE at: Wed Apr 6 00:21:55 2011
可以在以下链接中获取到更多关于 concurrent.futures 模块的信息。
• http://docs.python.org/dev/py3k/library/concurrent.futures.html
• http://code.google.com/p/pythonfutures/
• http://www.python.org/dev/peps/pep-3148/
下一节将对上述这些选择以及其他与线程相关的模块和包进行总结。
10. 相关模块
表 4-6 列出了多线程应用编程中可能会使用到的一些模块。
表 4-6 与线程相关的标准库模块
模 块 描 述
thread① 基本的、低级别的线程模块
threading 高级别的线程和同步对象
multiprocessing② 使用“threading”接口派生/使用子进程
subprocess③ 完全跳过线程,使用进程来执行
Queue 供多线程使用的同步先入先出队列
mutex④ 互斥对象
concurrent.futures⑤ 异步执行的高级别库
SocketServer 创建/管理线程控制的 TCP/UDP 服务器
① 在 Python 3.0 中重命名为_thread。
② 自 Python 2.6 版本开始引入。
③ 自 Python 2.4 版本开始引入。
④ 自 Python 2.6 版本起不建议使用,并在 Python 3.0 版本移除。
⑤ 自 Python 3.2 版本引入(但是可以通过非标准库的方式在 2.6+版本上使用)。
参考:
Python3入门之线程threading常用方法 https://www.cnblogs.com/chengd/articles/7770898.html
Python 3.2 版本中引入。 ↩︎