*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes
一、简介
pandas提供了很多方便简洁的方法,用于对单列、多列数据进行批量运算或分组聚合运算,熟悉这些方法后可极大地提升数据分析的效率,也会使得你的代码更加地优雅简洁,本文就将针对pandas中的map()、apply()、applymap()、groupby()、agg()等方法展开详细介绍,并结合实际例子帮助大家更好地理解它们的使用技巧(本文使用到的所有代码及数据均保存在我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes对应本文的文件夹下)。
二、非聚合类方法
这里的非聚合指的是数据处理前后没有进行分组操作,数据列的长度没有发生改变,因此本章节中不涉及groupby(),首先读入数据,这里使用到的全美婴儿姓名数据,包含了1880-2018年全美每年对应每个姓名的新生儿数据,在jupyterlab中读入数据并打印数据集的一些基本信息以了解我们的数据集:
import pandas as pd #读入数据 data = pd.read_csv('data.csv') data.head()

#查看各列数据类型、数据框行列数 print(data.dtypes) print() print(data.shape)

2.1 map()
类似Python内建的map()方法,pandas中的map()方法将函数、字典索引或是一些需要接受单个输入值的特别的对象与对应的单个列的每一个元素建立联系并串行得到结果,譬如这里我们想要得到gender列的F、M转换为女性、男性的新列,可以有以下几种实现方式:
● 字典映射
这里我们编写F、M与女性、男性之间一一映射的字典,再利用map()方法来得到映射列:
#定义F->女性,M->男性的映射字典 gender2xb = {'F': '女性', 'M': '男性'} #利用map()方法得到对应gender列的映射列 data.gender.map(gender2xb)

● lambda函数
这里我们向map()中传入lambda函数来实现所需功能:
#因为已经知道数据gender列性别中只有F和M所以编写如下lambda函数 data.gender.map(lambda x:'女性' if x is 'F' else '男性')

● 常规函数
也可以传入def定义的常规函数:
def gender_to_xb(x): return '女性' if x is 'F' else '男性' data.gender.map(gender_to_xb)

map()可以传入的内容有时候可以很特殊,如下面的例子:
● 特殊对象
一些接收单个输入值且有输出的对象也可以用map()方法来处理:
data.gender.map("This kid's gender is {}".format)

map()还有一个参数na_action,类似R中的na.action,取值为'None'或'ingore',用于控制遇到缺失值的处理方式,设置为'ingore'时串行运算过程中将忽略Nan值原样返回。
2.2 apply()
apply()堪称pandas中最好用的方法,其使用方式跟map()很像,主要传入的主要参数都是接受输入返回输出,但相较于map()针对单列Series进行处理,一条apply()语句可以对单列或多列进行运算,覆盖非常多的使用场景,下面我们来分别介绍:
● 单列数据
这里我们参照2.1向apply()中传入lambda函数:
data.gender.apply(lambda x:'女性' if x is 'F' else '男性')

可以看到这里实现了跟map()一样的功能。
● 多列数据
apply()最特别的地方在于其可以同时处理多列数据,譬如这里我们编写一个使用到多列数据的函数用于拼成对于每一行描述性的话,并在apply()用lambda函数传递多个值进编写好的函数中(当调用DataFrame.apply()时,apply()在串行过程中实际处理的是每一行数据而不是Series.apply()那样每次处理单个值),注意在处理多个值时要给apply()添加参数axis=1:
def generate_descriptive_statement(year, name, gender, count): year, count = str(year), str(count) gender = '女性' if gender is 'F' else '男性' return '在{}年,叫做{}性别为{}的新生儿有{}个。'.format(year, name, gender, count) data.apply(lambda row:generate_descriptive_statement(row['year'], row['name'], row['gender'], row['count']), axis = 1)

● 结合tqdm给apply()过程添加进度条
我们知道apply()在运算时实际上仍然是一行一行遍历的方式,因此在计算量很大时如果有一个进度条来监视运行进度就很舒服,在(数据科学学习手札53)Python中tqdm模块的用法中,我对基于tqdm为程序添加进度条做了介绍,而tqdm对pandas也是有着很好的支持,我们可以使用progress_apply()代替apply(),并在运行progress_apply()之前添加tqdm.tqdm.pandas(desc='')来启动对apply过程的监视,其中desc参数传入对进度进行说明的字符串,下面我们在上一小部分示例的基础上进行改造来添加进度条功能:
from tqdm import tqdm def generate_descriptive_statement(year, name, gender, count): year, count = str(year), str(count) gender = '女性' if gender is 'F' else '男性' return '在{}年,叫做{}性别为{}的新生儿有{}个。'.format(year, name, gender, count) #启动对紧跟着的apply过程的监视 tqdm.pandas(desc='apply') data.progress_apply(lambda row:generate_descriptive_statement(row['year'], row['name'], row['gender'], row['count']), axis = 1)
可以看到在jupyter lab中运行程序的过程中,下方出现了监视过程的进度条,这样就可以实时了解apply过程跑到什么地方了。
2.3 applymap()
applymap()是与map()方法相对应的专属于DataFrame对象的方法,类似map()方法传入函数、字典等,传入对应的输出结果,不同的是applymap()将传入的函数等作用于整个数据框中每一个位置的元素,因此其返回结果的形状与原数据框一致,譬如下面的简单示例,我们把婴儿姓名数据中所有的字符型数据消息小写化处理,对其他类型则原样返回:
def lower_all_string(x): if isinstance(x, str): return x.lower() else: return x data.applymap(lower_all_string)

其形状没有变化:

配合applymap(),可以简洁地完成很多数据处理操作。
三、聚合类方法
有些时候我们需要像SQL里的聚合操作那样将原始数据按照某个或某些离散型的列进行分组再求和、平均数等聚合之后的值,在pandas中分组运算是一件非常优雅的事。
3.1 利用groupby()进行分组
要进行分组运算第一步当然就是分组,在pandas中对数据框进行分组使用到groupby()方法,其主要使用到的参数为by,这个参数用于传入分组依据的变量名称,当变量为1个时传入名称字符串即可,当为多个时传入这些变量名称列表,DataFrame对象通过groupby()之后返回一个生成器,需要将其列表化才能得到需要的分组后的子集,如下面的示例:
#按照年份和性别对婴儿姓名数据进行分组 groups = data.groupby(by=['year','gender']) #查看groups类型 type(groups)
![]()
可以看到它此时是生成器,下面我们用列表解析的方式提取出所有分组后的结果:
#利用列表解析提取分组结果 groups = [group for group in groups]
查看其中的一个元素:

可以看到每一个结果都是一个二元组,元组的第一个元素是对应这个分组结果的分组组合方式,第二个元素是分组出的子集数据框,而对于DataFrame.groupby()得到的结果,主要可以进行以下几种操作:
● 直接调用聚合函数
譬如这里我们提取count列后直接调用max()方法:
#求每个分组中最高频次 data.groupby(by=['year','gender'])['count'].max()
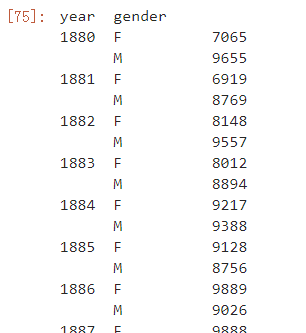
注意这里的year、gender列是以索引的形式存在的,想要把它们还原回数据框,使用reset_index(drop=False)即可:

● 结合apply()
分组后的结果也可以直接调用apply(),这样可以编写更加自由的函数来完成需求,譬如下面我们通过自编函数来求得每年每种性别出现频次最高的名字及对应频次,要注意的是,这里的apply传入的对象是每个分组之后的子数据框,所以下面的自编函数中直接接收的df参数即为每个分组的子数据框:
import numpy as np def find_most_name(df): return str(np.max(df['count']))+'-'+df['name'][np.argmax(df['count'])] data.groupby(['year','gender']).apply(find_most_name).reset_index(drop=False)

3.2 利用agg()进行更灵活的聚合
agg即aggregate,聚合,在pandas中可以利用agg()对Series、DataFrame以及groupby()后的结果进行聚合,其传入的参数为字典,键为变量名,值为对应的聚合函数字符串,譬如{'v1':['sum','mean'], 'v2':['median','max','min]}就代表对数据框中的v1列进行求和、均值操作,对v2列进行中位数、最大值、最小值操作,下面用几个简单的例子演示其具体使用方式:
● 聚合Series
在对Series进行聚合时,因为只有1列,所以可以不使用字典的形式传递参数,直接传入函数名列表即可:
#求count列的最小值、最大值以及中位数 data['count'].agg(['min','max','median'])

● 聚合数据框
对数据框进行聚合时因为有多列,所以要使用字典的方式传入聚合方案:
data.agg({'year': ['max','min'], 'count': ['mean','std']})

值得注意的是,因为上例中对于不同变量的聚合方案不统一,所以会出现NaN的情况。
● 聚合groupby()结果
data.groupby(['year','gender']).agg({'count':['min','max','median']}).reset_index(drop=False)

可以注意到虽然我们使用reset_index()将索引列还原回变量,但聚合结果的列名变成红色框中奇怪的样子,而在pandas 0.25.0以及之后的版本中,可以使用pd.NamedAgg()来为聚合后的每一列赋予新的名字:
data.groupby(['year','gender']).agg( min_count=pd.NamedAgg(column='count', aggfunc='min'), max_count=pd.NamedAgg(column='count', aggfunc='max'), median=pd.NamedAgg(column='count', aggfunc='median')).reset_index(drop=False)

以上就是本文全部内容,如有笔误望指出!