写在前面:一篇魏云超博士的综述论文,完整题目为《基于DCNN的图像语义分割综述》,在这里选择性摘抄和理解,以加深自己印象,同时达到对近年来图像语义分割历史学习和了解的目的,博古才能通今!感兴趣的请根据自己情况找来完整文章阅读学习。
图像的语义分割是计算机视觉中重要的基本问题之一,其目标是对图像的每个像素点进行分类,将图像分割为若干个视觉上有意义的或感兴趣的区域,以利于后续的图像分析和视觉理解.近年来,深度卷积神经网络(Deep Convolutional Neural Network, DCNN)的出现,极大地推动了语义分割的发展。
图像分类、物体检测、图像语义分割是计算机视觉的三大核心研究问题。其中图像语义分割任务最具有挑战性。图像语义分割融合了传统的图像分割和目标识别两个任务,其目的是将图像分割成几组具有某种特定语义含义的像素区域,并识别出每个区域的类别,最终获得一副具有像素语义标注的图像。目前,图像语义分割是计算机视觉和模式识别领域非常活跃的研究方向,并在很多领域具有广泛的应用价值。例如,在时尚领域,通过对人体的语义分割可以定位出人脸、躯干、着装等信息,从而帮助网民在互联网购物过程中实现自动试衣等功能;在自动驾驶领域,通过对车体前方场景的语义分割可以精确定位道路、车体和行人等场景或物体信息,从而提升自动驾驶的安全性。图像语义分割技术正逐渐应用到人们生活的各个方面,并将改变人类的生活方式。
然而,图像语义分割任务是一个非常具有挑战性的问题,其难点主要体现在以下几个方面:
1 )物体层次:同一物体,由于光照、视角、距离的不同,拍摄出的图像也会有很大不同,另外,非刚性物体(如猫、狗等动物)由于运动所产生的形变也使拍出的图像产生很大的变化,同时,物体之间的相互交叉所带来的遮挡问题,也给图像语义分割带来很大的挑战。
2 )类别层次:类别层面上所面临的难点主要来自两个方面,即类内物体之间的相异性和类间物体之间的相似性。
3 )背景层次:通常干净的背景有助于实现图像的语义分割,但实际场景中的背景往往是错综复杂的,这种复杂性也大大提升了图像语义分割的难度。
图像语义分割由于其广阔的应用前景和挑战性引起了研究者和工业界广泛的关注,特别是近年来DCNN 等新技术和新工具的出现,为其发展注入新的活力。
本文作者首先介绍了DCNN的相关背景知识;
然后对当前图像语义分割方面的主流数据库进行了分析和介绍,并以PASCAL VOC数据库为主线对近年来基于DCNN的语义分割算法进行了梳理和总结,重点介绍了基于全监督和弱监督的图像语义分割算法;
最后,对语义分割未来的研究重点进行了探讨和预测。
1 DCNN的背景介绍
深度学习在图像识别领域取得的巨大成功主要得益于大规模标记图像的出现和计算机硬件的发展。Stanford大学Li等发起的ImageNet大规模视觉识别挑 战 (Image Net Large Scale Visual Recognition Challenge, ILSVRC)提供了上百万张有标签的图像,这很大程度上缓解了深度网络在训练过程中产生的过拟合问题。同时具有超强计算能力的 GPU也为深度学习复杂的运算带来了可能性。
2012年 Hinton的学生 Krizhevsky等在ILSVRC竞赛中通过8层的DCNN(简称AlexNet),以接近10%的优势击败了传统的基于人工设计特征的方法,在1000类的图像分类任务中获得冠军.自此之后的几年中,所有的参赛队伍 (纽 约 大 学,新 加 坡 国 立 大 学,牛 津 大 学,Google,Microsoft等)都无一例外的采用了基于深度CNN的方法,并进一步提升了图像分类的性能 。
相对于传统方法,深度学习在图像识别领域取得巨大进步的主要原因在于深度卷积神经网络是通过训练数据自动学习特征。
卷积神经网络主要包含了4种基本操作:卷积,池化(Pooling)、全连接和非线性变换,如图 1 所示,下面简要介绍这 4 种操作

图1 卷积神经网络示意图
1)卷积
卷积神经网络在初始化阶段主要是初始化卷积层中各个卷积核的权重和偏置量。卷积层的输入来源包括输入的图像和卷积或池化操作后生成的特征图(feature map)。
卷积操作主要是利用一个固定大小的卷积核,在输入的图像或特征图上按照一定的步长进行滑动,通过内积操作和非线性函数将图像或特征图映射到下一层的特征图上。
卷积层输出的特征图的数量是由人工定义的卷积核个数决定的,其输出的大小由卷积核大小、滑动的步长,以及上一层输入的特征图大小共同决定。
2)池化
池化又称降采样,卷积神经网络在通过卷积获得特征之后,可以利用提取到的特征训练相应的分类器.然而,若输入的图像尺寸较大,仅仅通过卷积操作获得的特征往往维度很高,因此在训练分类器过程中很容易出现过拟合现象。池化操作是对上一层特征图的一个降采样过程。通过对上一层特征图中相邻小区域的聚合统计,可以获得低维度的特征表示 。通过池化,可以实现利用小尺寸的特征图描述大尺寸特征图的目的,有效改善分类器的性能,防止过拟合。常用的池化操作包括平均池化和最大值池化,分别指将每个聚合区域的平均值和最大值映射到下一层特征图上。
3 )全连接
同传统神经网络中的层相似,在全连接层中下一层神经元的输出同上一层所有神经元的输入都有关 . 通过全连接层可以使得网络的参数在训练样本上快速收敛。
4)非线性函数
人脑对客观世界的理解并不是线性的,而是一种复杂的非线性映射.因此,神经网络在设计中往往会通过非线性激活函数来模拟人脑的非线性认知行为. 常用的非线性激活函数主要包括Sigmoid和修正线性单元(Rectified Linear Units,ReLU)。定义为:
![]()
![]()
![]()
AlexNet在训练过程中首先将图片变换到256*256大小,并从中随机分割出224*224大小的区域输入到神经网络中。受限于GPU的内存。整个训练过程需要多次迭代,每次迭代中输入256张图片,并利用这些图片在损失函数中计算得出的梯度值调整整个网络的参数 。在迭代过程中,学习速率也在逐渐变小,从而使整个网络能有效地收敛到某个局部最小值。在测试过程中,AlexNet 可以读入256*256 大小的测试样本,并在网络末端输出样本在各个类别上的概率分布,概率最大的类别即为测试图像中物体的类别。
2 图像语义分割相关数据库 (略讲)
当某种图像语义分割算法被提出时,需要采用一个或多个数据集来验证算法的有效性 。DCNN出现之后,数据库变得更加重要。基于同样的深度模型,数据量的增加通常可以有效提升图像语义分割的性能。
PASCAL VOC 2012
PASCAL-CONTEXT
PASCAL-PERSON-PART
HORSE-COW-PART
ACTIVE TEMPLATE REGRESSION(ATR)
CITYSCAPES
MS COCO
七个数据库!
3 基于DCNN的图像语义分割算法
图像语义分割算法已经有几十年的发展历史,本节主要对基于 DCNN (本节所涉及的用于语义分割的 DCNN 网络的初始参数大多数是通过 120万的ImageNet图像进行预训练获得)的图像语义分割算法的发展脉络进行了简单梳理和总结。特别以PASCAL VOC 数据库为主线对近年来具有代表性的全监督和弱监督的语义分割算法(如图 2所示)进行综述。
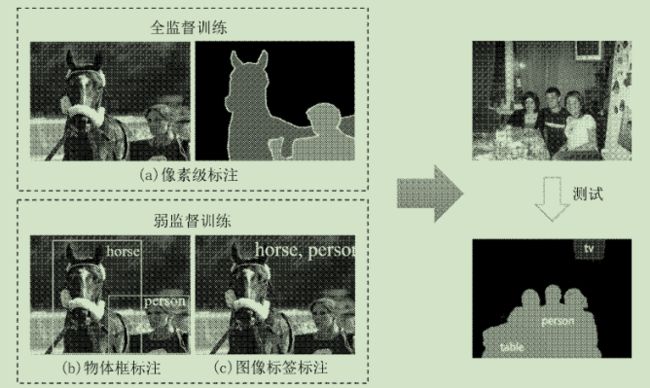
图2 全监督和弱监督语义分割方法的标注信息示意图
(1) 全监督的语义分割算法
1)14年的文章《Simultaneous Detection and Segmentation》首次利用DCNN解决语义分割问题。
该文提出了一个协同检测和分割(Simultaneous Detection and Segmentation,SDS)方法,并利用RCNN(Regions with Convolutional Neural Network Features)框架对网络参数进行训练,SDS首先利用似物性推荐框技术MCG(Multiscale Combinatorial Grouping) 抽取了图片中多个似物性推荐区域(proposal)。其次,SDS保留了每个proposal的前景区域同人工标注像素的交叉区域,并将剩余的背景区域的像素值替换为训练图像的像素平均值。最后,SDS利用每个 proposal的类别信息对网络参数进行训练,从而获得可以用于图像语义分割的DCNN。SDS的缺点在于依赖大量的proposal,其运算量和运算时间都非常高。
2)14年的文章《Fully convolutional networks for semantic segmentation》 提出了基于全卷积网络的图像语义分割方法,如图3所示。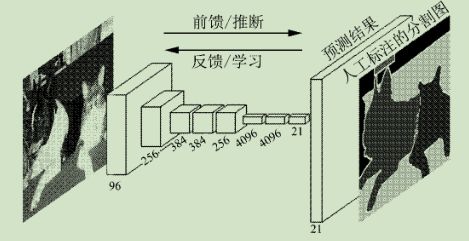
图3 FCN方法的框架图
FCN的主要特点是将用于DCNN 中的全连接层替换为卷积层,并将图像语义分割问题转化为对每个像素点的分类问题。图3中预测结果特征图上的21代表语义类别的个数(20个前景类加1个背景类),通过计算每个像素的预测结果和人工标注结果的差异,进而对网络参数进行优化。
在此之后,大量的基于FCN的图像语义分割算法被提出,如《Conditional Random Fields as Recurrent Neural Networks》、《High-performance Semantic Segmentation Using Very Deep FullyConvolutional Networks》、《Laplacian Pyramid Reconstruction and Refinementfor Semantic Segmentation》、《Higher Order Conditional Random Fields in Deep Neural Networks》、《Efficient Piecewise Trainingof Deep Structured Models for Semantic Segmentation》、《Semantic Image Segmentation via Deep Parsing Network》、《Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs》、《Exploring Context with Deep Structured models for Semantic Segmentation》等。进一步推动了图像语义分割的发展。
这些方法或将全连接的条件随机场引入到FCN中,对FCN的预测结果进行后处理;或基于更强的卷积神经网络(ResNet);或利用图像的上下文信息提升 DCNN 的图像语义分割能力。探索了图像中“区域 - 区域”和“区域 - 背景”的上下文信息。对于 “区域 - 区域”的上下文信息,构建了基于DCNNs和CRFs的深度模型用以学习不同图像区域块之间的语义关联.对于“区域 - 背景”的上下文信息,采用一种多尺度图像输入和滑动金字塔池化的方式获取,该方法基于FCN的框架进行训练。
(2) 弱监督的语义分割算法
DCNN在图像语义分割任务中展示了其出色的分割能力,但大多数方法都属于全监督的范畴,即利用像素级的标注图片对网络进行训练.然而,标注像素级的训练样本往往需要大量的时间和人力.目前,大量的研究人员正在试图采用弱监督的标注信息对DCNN进行训练,使其具有图像语义分割的能力,对于图像语义分割任务,弱监督的标注信息主要包括图像中的物体框和图像的标签。
1) 基于物体框的语义分割算法
15年的一篇文章《BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation》 提出一种利用物体框作为监督信息的语义分割方法BoxSup,如图4所示。
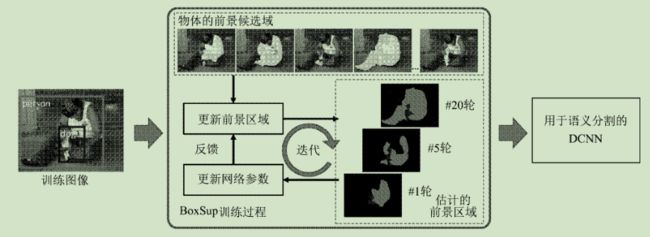
图4 BoxSup方法的框架图 .
该方法首先利用物体的位置框和 MCG方法得到物体粗略的前景区域,并以此作为监督信息,结合FCN框架对网络的参数进行更新 。进而,基于训练出的语义分割网络对物体框中的前景区域进行预测,提升前景区域的精度,并再次结合FCN框架对网络参数进行更新 。BoxSup的核心思想就是通过这种迭代过程不断提升网络的语义分割能力。
2) 基于图像标签的语义分割算法
相对于物体框的标注,图像级的标注信息更容易被获取,近些年受到了众多研究人员的关注。但图像级的语义信息很难同像素的语义产生关联,这是利用图像标签作为监督信息的语义分割面临的巨大挑战。
15年的《From Image-level to Pixel-level Labeling with Convolutional Networks》采用了多实例学习(MIL)机制构建图像标签同像素语义的关联 。 该方法的训练样本包含了70 万张来自ImageNet的图片,但其语义分割的性能很大程度上依赖于复杂的后处理过程,主要包括图像级语义的预测信息、超像素平滑策略、物体候选框平滑策略和 MCG分割区域平滑策略。
15年的《Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation》提出了一种EM-Adapt的训练方法。通过利用图像的标签信息动态地预测像素的语义信息,并将预测得到的语义分割图作为监督信息,按 照FCN的框架对网络的参数进行训练。
15年的《Constrained convolutional neural networks for weakly supervisedsegmentation》 提出了一种约束卷积神经网络(CCNN)通过一种损失函数来约束预测的像素标签类别的分布,并结合图像的标签信息,对语义分割结果进行优化.虽然这些方法很大程度上了促进弱监督语义分割算法的发展,但其分割结果很难令人满意。
15年的《STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation》提出了一种从简单到复杂(STC)的语义分割算法,极大地提升了基于图像标签语义分割的性能 . 该方法首先采用了互联网中的简单图片(即背景干净的图片),并利用判别区域特征融合的显著性检测算法对图片的显著区域(《Salient Object Detection: A Discriminative Regional Feature Integration Approach》)进行分析。其次STC利用图片的标签信息和显著性区域图构建像素点同语义之间的关联。最后,通过基于显著图的损失函数和一种从简单到复杂的迭代机制,逐渐提升了DCNN的语义分割能力。图5给出了STC算法的训练框架图。
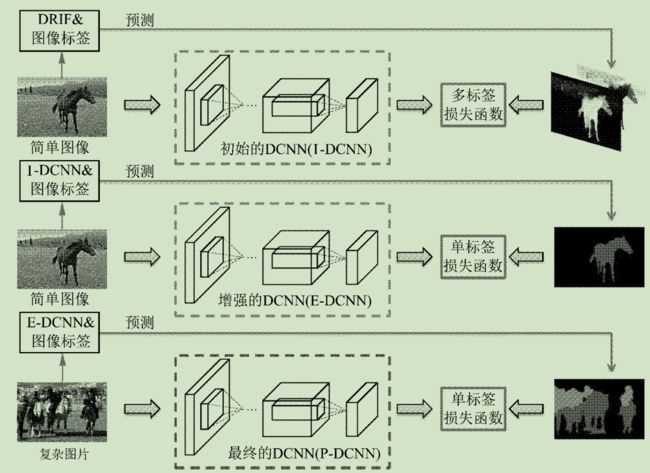
图5 STC算法框架图
同时还有《Fully Convolutional Multi-Class Multiple Instance learning》、《Learning to Segment with Image-level Annotations》、等不错的文章可以借鉴学习。
基于图像标签的语义分割算法在未来具有重要的研究意义。同时,如何有效地利用图像级的多标签预测信息和似物性推荐框技术对预测的语义分割图进行后处理,也具有重要的研究价值。
3 未来研究方向
当前,DCNN已经成为解决图像语义分割的主流方法,但目前DCNN依然面临着一些难点和挑战.这些难点和挑战一方面来自DCNN自身存在的问题,另一方面来自更具挑战性的语义分割任务。
DCNN存在的问题主要包括:
1 )计算复杂度高。DCNN的训练和测试很大程度上依赖具有超强计算能力的 GPU.因此,很难在普通PC端或移动设备端部署基于DCNN的相关应用。
2 )参数量大。当前主流的 DCNN模型包含几十兆甚至几百兆的参数,如何有效的压缩模型并保持其准确性是深度学习的一个重要研究内容。
3 )性能和速度之间的矛盾 。近期的研究成果表明:网络的层数越深,其识别物体的能力越强 。 然而,层数的增加,往往会导致速度变慢.一些应用场景(如自动驾驶)对 DCNN的性能和速度要求都很高。
此外,更具挑战性的语义分割任务主要包括:
1 )小物体的语义分割.同物体检测任务相似,当前的图像语义分割网络往往很难识别图像中尺度较小的物体.如何有效地识别图像中小尺度的物体是图像语义分割中的重要内容。
2 )示例级的语义分割.图8中展示了类别级的语义分割和示例级语义分割的区别.示例级的语义分割不仅要求识别像素的语义,也要求识别出像素所归属的示例.示例级的语义分割相比类别级的语义分割更具有挑战性,同时也具有更广阔的应用前景,是未来值得研究的方向之一 。
3 )弱监督的语义分割 . 虽然当前已经涌现出大量的弱监督算法,但其性能同全监督算法依然相差甚远 . 如何利用当前互联网中大量的具有语义标签的图片训练有效地语义分割网络是值得研究的另一方向。