深度学习的NLP工具

本文为 AI 研习社编译的技术博客,原标题 :
NLP tools of DL
作者 | Thomas Delteil
翻译 | 孙稚昊2
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/apache-mxnet/gluonnlp-deep-learning-toolkit-for-natural-language-processing-98e684131c8a
深度学习的NLP工具

为什么最新的模型结果这么难以复现?为什么去年可以工作的代码和最新发布的深度学习框架不适配?为什么一个很直白的基线这么难以建立?在今天的世界中,这些都是自然语言处理(NLP)的研究员遇到的问题。
我们来看一个假想的博士学生。我们叫它亚历山大,他刚开始机械翻译(NMT)的研究。有一天早上他看到了Google 最著名的 论文“注意力是你全部需要的”,其中介绍了Transformer 模型,完全基于注意力机制。被结果惊艳到了,Alex搜索了一下google,结果告诉他T恩送染发咯哇的 Tensor2Tensor包已经包含了这个模型的实现。他的实验室里充满了快乐的尖叫;他应该可以在下午就复现出来结果,并且享受一个放松的晚上来和朋友在酒吧看世界杯!他还想。。。
然后,我们的朋友发现官方实现用的超参数和论文中提到的很不一样。他的导师建议:稍微调整一下参数,跑一下看看,结果应该还好--真的吗?
三天之后 。。。。实验室里所有的GPU都冒烟了,在不停地100%负荷运转。他的同事强制把他登出了,并且告诉他回家休息。我们不行的英雄照做了,并且去了Tensor2Tensor的Github 页面去报告这个问题,看看有没有别人遇到了同样的问题。很快,很多人回复他们遇到了同样的问题,但他们还没找到解决方案。
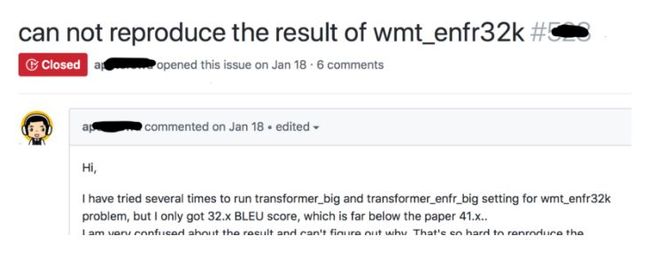
半个月过去了。。。终于项目的维护者出现了并回复说他会看看。
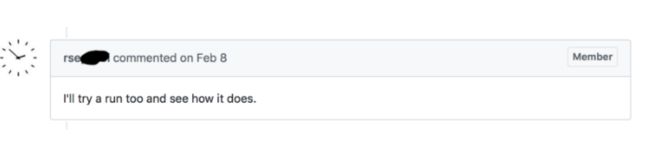
三个月过去了。。。。Alex 还在无助地询问:有没有进展?
在亚马逊云服务(AWS)上研究深度学习和自然语言处理之后,我发现这不是个例。重现NLP模型比计算机视觉模型难得多。数据预处理管道包括需要重要步骤,并且模型本身有很多可调节组件。例如,人们需要注意下面的东西,比如:
字符串编码/解码和Unicode格式
文本解析和分割
来自多种语言的文本遵循不同的语法和句法规则
左到右和右到左的阅读顺序
词语表征
输入填充
梯度切割
处理变长输入数据和状态
从载入训练数据集到在测试集上计算输出的BLEU分数,有一千种可能做错。如果没有合适的工具,每次你开始新的项目,你都有遭遇全新问题的风险。
许多MXNet的贡献者和我曾经分享我们在做NLP时遇到的问题,并且每个人都有相似的故事,我们之间有很强的共鸣。我们都同意虽然NLP很困难,我们还是想做些事情!我们决定开发一个工具来帮助你复现最新的研究结果,并且简单的在Gluon中开发新模型。这个团队包括 Xingjian Shi (@sxjscience), Chenguang Wang (@cgraywang), Leonard Lausen (@leezu), Aston Zhang (@astonzhang), Shuai Zheng (@szhengac), 和我自己 (@szha). GluonNLP 诞生了!
症状:自然语言处理论文难以复现。Github上的开源实现质量参差不齐,并且维护者可以停止维护项目。
√GluonNLP处方:复现最新的研究结果。频繁更新复现代码,包括训练脚本,超参数,运行日志等。
你曾经也被无法复现结果困扰过,而且这并不少见。理论上,你的代码不会随时间变质,但事实上会这样。一个主要原因是深度学习库的API会随时间变化。
为了了解这种现象,我们在Google搜索中跑了这个请求 --- “X API 挂了”
┌────────────┬────────────────┐
│ X │ Search Results │
├────────────┼────────────────┤
│ MXNet │ ~17k │
│ Tensorflow │ ~81k │
│ Keras │ ~844k │
│ Pytorch │ ~23k │
│ Caffe │ ~110k │
└────────────┴────────────────┘
虽然MXNet 社区花了很多努力来保持API最小的变化,搜索结果还是返回了1万7千个结果。为了防止我们的包遭遇这样的问题,我们在开发中特别注意了。每个训练脚本都进入连续集成(CI)来捕捉任何回退并避免给用户不好的影响。
症状:复现代码对API变化很敏感,所有只有很短的寿命。
√GluonNLP处方:自动化对训练和评估脚本的测试,尽早适应最新API的变化。
去年做了一些NLP的服务,我最后有五个 Beam 搜索算法的实现,每个都和别的不太一样。原因是每个模块的接口都因为要赶截止日去而被潦草设计。为了不同的使用情景,最简单的方法就是复制并稍稍修改他们中的一个。结果是,我最后有了五个版本的Beam 搜索算法,只在打分和步函数上略有不同。
做一个可服用,易扩展的接口需要很多努力,研究使用场景,并且和许多开发做讨论。在GlunonNLP中,我们不仅专注于复现现存的例子,还要把它设计得易用,接口可扩展,使以后的研究更简单。
症状:复制粘贴以前的项目并做少许修改,作为短期解决方法,因为赶工期而没有精细的设计接口,导致了难以维护的代码。
√GluonNLP 处方:易用并可扩展的接口,基于GluonNLP团队对各种使用场景的研究。
最近,我在做一个新项目,并且发现一个常见问题,就是很多有用的资源没有被聚拢起来。每个人都知道预训练的词语表征和语言模型对很多应用都很有用。然而对特定问题该用哪一个模型需要很多实验才能知道。开发人员经常需要在探索阶段安装很多工具。比如,Google的 Word2vec 对gensim有依赖,然而Salesforce的AWD语言模型是用PyTorch实现的,并且不提供预训练模型。Facebook的Fasttext是自己开发的独立包。为了正确地使用这些资源,用户经常需要话费大量努力来搭建环境,并把数据转化为各种格式。
我们都知道资源共享是社区的特点。在 GluonNLP中,我们不仅提供工具和社区给NLP 爱好者们,还要让他们易于使用这些资源,通过整合这些来自不同平台的资源,使GluonNLP成为一站式解决方案。
症状:NLP资源太分散了。为了完成一个项目需要依赖很多包。
√GluonNLP 处方:整合并重新分发这些有用的公开资源。一键为不同应用下载预训练词表征,预训练语言模型,常用的数据集和预训练模型。
说的够多了,给我看代码!
import mxnet as mx
import gluonnlp as nlp
# Load GloVe word embeddings
glove = nlp.embedding.create('glove', source='glove.6B.50d')
# Compute 'baby' and 'infant' word embeddings
baby_glove, infant_glove = glove['baby'], glove['infant']
# Load pre-trained AWD LSTM language model and get the embedding
lm_model, lm_vocab = nlp.model.get_model(name='awd_lstm_lm_1150',
dataset_name='wikitext-2',
pretrained=True)
baby_idx, infant_idx = lm_vocab['baby', 'infant']
lm_embedding = lm_model.embedding[0]
# Get the word embeddings of 'baby' and 'infant'
baby_lm, infant_lm = lm_embedding(mx.nd.array([baby_idx, infant_idx]))
# cosine similarity
def cos_similarity(vec1, vec2):
return mx.nd.dot(vec1, vec2) / (vec1.norm() * vec2.norm())
print(cos_similarity(baby_glove, infant_glove)) # 0.74056691
print(cos_similarity(baby_lm, infant_lm)) # 0.3729561
gluonnlp.py hosted with by GitHub
在这个例子中,我们用 GluonNLP来加载Glove 词语表征,和预训练好的AWD语言模型,然后比较了他们在测量相似度问题伤的准确性。我们通过在 'baby'和 'infant'这两个例子上比较词语表征之间的余弦相似度。从结果可以看到,Glove 表征能更好地捕捉语义相似度。
项目在哪里?
最新的GluonNLP 和最新版的MXNet可以在 gluon-nlp.mxnet.io 上获得,并且可以通过指令 pip install gluonnlp 来安装。
v.0.3.2版本的GluonNLP 包含这个功能:
预训练模型:超过300个词语表征模型(GloVe, FastText, Word2vec),5种语言模型 (AWD, Cache, LSTM)。
神经机器翻译(Google NMT, Transformer)模型训练
用来训练Word2vec 和 FastText的词语表征,包括未知词表征和用部分词来产生的表征。
灵活的数据管道工具和许多公开数据集。
NLP的例子,比如情感分析。
我们会在接下来的版本中继续增加功能和模型。如果你对某个模型有兴趣或者有反馈给我们,可以在Github上找到我们。雷锋网(公众号:雷锋网)
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开【深度学习的NLP工具】:雷锋网
https://ai.yanxishe.com/page/TextTranslation/731
AI研习社每日更新精彩内容,观看更多精彩内容:雷锋网
用Python实现遗传算法
如何将深度学习应用于无人机图像的目标检测
机器学习和深度学习大PK!昆虫分类谁更强?
Python高级技巧:用一行代码减少一半内存占用
等你来译:
五个很厉害的 CNN 架构
如何在神经NLP处理中引用语义结构
特朗普都被玩坏了,用一张照片就能做出惟妙惟肖的 Memoji
让神经网络说“我不知道”——用Pyro/PyTorch实现贝叶斯神经网络
◆◆ 敲黑板,划重点啦! ◆◆
AI求职百题斩已经悄咪咪上线啦,点击下方小程序卡片,开始愉快答题吧!