kubeadm HA master集群master重置故障恢复
文章楔子
对于一个具有HA master的集群来说,发生单点故障通常不会影响集群的正常运行,只要及时复原单点故障,就可以避免潜在的数据、状态丢失。本文旨在指导读者,在kubeadm搭建的HA master集群中,某一master主机遭遇硬件更换、系统重置、k8s配置重置的情况下,应当如何恢复K8s HA master集群。
前置需求
单点重置恢复
故障重现
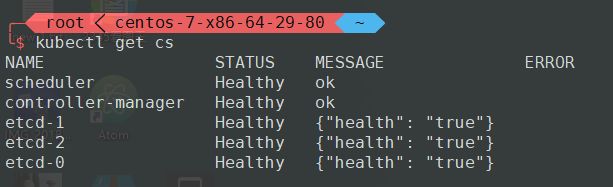
一个健康的HA master集群
首先登陆到其中一台master上,运行下面的命令以模拟单点重置的场景,随后k8s HA master陷入单点故障。
kubeadm reset - f

HA master进入单点故障
故障恢复
本章节的全过程可以在此处查看演示视频: DEMO
首先在一台健康的master上运行下面的命令获取etcd集群中故障member的ID
ETCD = ` docker ps | grep etcd | grep - v POD | awk '{print $1}' ` docker exec \ - it $ { ETCD } \ etcdctl \ -- endpoints https : / / 127.0.0.1 : 2379 \ -- ca - file / etc / kubernetes / pki / etcd / ca .crt \ -- cert - file / etc / kubernetes / pki / etcd / peer .crt \ -- key - file / etc / kubernetes / pki / etcd / peer .key \ cluster - health

10.130.29.81连接被拒绝,故障成员ID为19c5f5e4748dc98b
本例中的故障member ID为19c5f5e4748dc98b,由于故障节点已经被重置,因此相当于该ID对应的ETCD实例已经丢失,无法再取得联系。因此直接运行下面命令将故障的member从etcd集群中删除。
ETCD = ` docker ps | grep etcd | grep - v POD | awk '{print $1}' ` docker exec \ - it $ { ETCD } \ etcdctl \ -- endpoints https : / / 127.0.0.1 : 2379 \ -- ca - file / etc / kubernetes / pki / etcd / ca .crt \ -- cert - file / etc / kubernetes / pki / etcd / server .crt \ -- key - file / etc / kubernetes / pki / etcd / server .key \ member remove 19c5f5e4748dc98b

移除故障节点成功
随后将新的(重置过的)节点加入到集群中,重新组成三节点的HA master,注意重建master的过程中使用了kubeadm的配置文件,该配置文件为HA master首次部署过程中使用过的,此处直接复用该配置文件。本例中,文件内容如下,可以参考,请注意其中一条配置可能需要根据集群的现有状态进行修改:
apiVersion : kubeadm . k8s . io / v1alpha2
kind : MasterConfiguration
kubernetesVersion : v1 . 11.0
apiServerCertSANs : - 10.130 . 29.80 - 10.130 . 29.81 - 10.130 . 29.82 - centos - 7 - x86 - 64 - 29 - 80 - centos - 7 - x86 - 64 - 29 - 81 - centos - 7 - x86 - 64 - 29 - 82 - 10.130 . 29.83
kubeProxy :
config :
mode : ipvs
etcd : local :
extraArgs :
listen - client - urls : https : //127.0.0.1:2379,https://10.130.29.81:2379
advertise - client - urls : https : //10.130.29.81:2379
listen - peer - urls : https : //10.130.29.81:2380
initial - advertise - peer - urls : https : //10.130.29.81:2380 # 注意此处需要修改,确保包括该重置节点在内的所有etcd节点的HOST=IP地址对都被列出在该配置中,不然新节点的etcd启动失败
initial - cluster : centos - 7 - x86 - 64 - 29 - 80 = https : //10.130.29.80:2380,centos-7-x86-64-29-81=https://10.130.29.81:2380,centos-7-x86-64-29-82=https://10.130.29.82:2380
initial - cluster - state : existing
serverCertSANs : - centos - 7 - x86 - 64 - 29 - 81 - 10.130 . 29.81
peerCertSANs : - centos - 7 - x86 - 64 - 29 - 81 - 10.130 . 29.81
networking : # This CIDR is a Calico default. Substitute or remove for your CNI provider.
podSubnet : 172.168 . 0.0 / 16
如果读者是使用 kubeadm HA集群搭建指南该教程部署的,该文件存放在各个master机器的/etc/kubernetes/kubeadm-config.yaml,否则请在下面的命令中修改所有的”/etc/kubernetes/kubeadm-config.yaml”至读者被重置的master机器上的kubeadm-config.yaml文件路径。同时,需要将host变量和ip变量设为故障节点的hostname和IP地址
ETCD = `docker ps|grep etcd|grep -v POD|awk '{print $1}'`
host = centos - 7 - x86 - 64 - 29 - 81
ip = 10.130 . 29.81
bash - c """
ssh $host 'mkdir -p /etc/kubernetes/pki/etcd'
scp /etc/kubernetes/pki/ca.crt $host:/etc/kubernetes/pki/ca.crt
scp /etc/kubernetes/pki/ca.key $host:/etc/kubernetes/pki/ca.key
scp /etc/kubernetes/pki/sa.key $host:/etc/kubernetes/pki/sa.key
scp /etc/kubernetes/pki/sa.pub $host:/etc/kubernetes/pki/sa.pub
scp /etc/kubernetes/pki/front-proxy-ca.crt $host:/etc/kubernetes/pki/front-proxy-ca.crt
scp /etc/kubernetes/pki/front-proxy-ca.key $host:/etc/kubernetes/pki/front-proxy-ca.key
scp /etc/kubernetes/pki/etcd/ca.crt $host:/etc/kubernetes/pki/etcd/ca.crt
scp /etc/kubernetes/pki/etcd/ca.key $host:/etc/kubernetes/pki/etcd/ca.key
scp /etc/kubernetes/admin.conf $host:/etc/kubernetes/admin.conf
docker exec \
-it ${ETCD} \
etcdctl \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--cert-file /etc/kubernetes/pki/etcd/peer.crt \
--key-file /etc/kubernetes/pki/etcd/peer.key \
--endpoints=https://127.0.0.1:2379 \
member add $host https://$ip:2380
ssh ${host} '
kubeadm alpha phase certs all --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase kubeconfig controller-manager --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase kubeconfig scheduler --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase kubelet config write-to-disk --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase kubelet write-env-file --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase kubeconfig kubelet --config /etc/kubernetes/kubeadm-config.yaml
systemctl restart kubelet
kubeadm alpha phase etcd local --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase kubeconfig all --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase controlplane all --config /etc/kubernetes/kubeadm-config.yaml
kubeadm alpha phase mark-master --config /etc/kubernetes/kubeadm-config.yaml'
"""
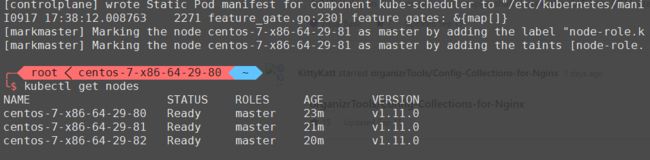
被重置的master被重新加入集群
至此,HA master单点重置故障恢复完毕。
本文转自中文社区-kubeadm HA master集群master重置故障恢复