TableStore时序数据存储 - 架构篇
背景
随着近几年物联网的发展,时序数据迎来了一个不小的爆发。从DB-Engines上近两年的数据库类型增长趋势来看,时序数据库的增长是非常迅猛的。在去年我花了比较长的时间去了解了一些开源时序数据库,写了一个系列的文章(
综述、
HBase系、
Cassandra系、
InfluxDB、
Prometheus),感兴趣的可以浏览。
这几大开源时序数据库的实现各有千秋,都不是很完美,但是如果可以取长补短,倒是能实现一个比较完美的时序数据库。
TableStore作为阿里云自研的分布式NoSQL数据库,在数据模型上我们是多模型设计,包含和BigTable一样的Wide Column模型以及针对消息数据的Timeline模型。在存储模型、数据规模以及写入和查询能力上,都能比较好的满足时序数据场景的需求。但我们作为一个通用模型数据库,时序数据存储要完全发挥底层数据库的能力,在表Schema设计以及计算对接上,都要有比较特殊的设计,例如OpenTSDB针对HBase的RowKey设计以及UID编码等。
本篇文章是架构篇,主要探讨时序数据的数据模型定义、核心处理流程以及基于TableStore来构建时序数据存储的架构。之后还会有方案篇,会提供一个高效的时序数据和元数据存储的表Schema设计以及索引设计方案。最后还会有计算篇,会提供几个时序数据流计算和时序分析的方案设计。
什么是时序数据
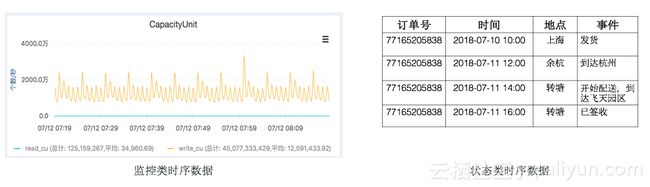
时序数据主要划分为两类,一类是监控类时序数据,另一类是状态类时序数据。当前开源的时序数据库,针对的都是监控类时序数据,针对该场景下数据特征做一些特定的优化。但按照时序数据的特征来看,还有一类是状态类时序数据。这两类时序数据分别对应不同的场景,监控类顾名思义对应的是监控场景,而状态类针对的是其他场景,例如轨迹溯源、异常状态记录等。我们最常见的包裹轨迹,就是状态类时序数据。
但为何把这两类数据都归类到时序,因为在数据模型定义、数据采集、数据存储以及计算上,两者是完全一致的,可以抽象出用同一个数据库及同一套技术架构。
时序数据模型
在定义时序数据模型之前,我们先对时序数据做一个抽象的表述。

-
个体或群体(WHO):描述产生数据的物体,可以是人、监控指标或者物体。通常描述个体会有多维的属性,可以通过某一类唯一ID来定位到个体,例如身份ID定位到人,设备ID定位到设备。也可以通过多维属性来定位到个体,例如通过集群、机器ID、进程名来定位到某个进程。
-
时间(WHEN):时间是时序数据最重要的特征,是区别于其他数据的关键属性。
-
时空(WHERE):通常是通过经纬度二维坐标定位到地点,在科学计算领域例如气象,通过经纬度和高度三维坐标来定位。
-
状态(WHAT):用于描述特定个体在某一刻的状态,监控类时序数据通常是数值类型描述状态,轨迹数据是通过事件表述状态,不同场景有不同的表述方式。
以上是对时序数据的一个抽象的表述,开源的时序数据库对时序数据模型有自己的定义,定义了监控类时序数据,例如拿OpenTSDB的数据模型来举例:

监控类时序数据模型定义包含:
-
Metric:用于描述监控指标。
-
Tags:用于定位被监控的对象,通过一个或多个Tag来描述。
-
Timestamp:监控值采集的时间点。
-
Value:采集的监控值,通常是数值类型。
监控类时序数据是时序数据最典型的一类数据,有特定的一类特征。监控类时序的特征决定了这类时序数据库在存储和计算上都有特定的方式,相比状态类时序数据,在计算和存储上有自己特定的优化方式。例如聚合计算会有特定的几种数值聚合函数,存储上会有特殊优化的压缩算法等。在数据模型上,监控类时序数据通常不需要表述地点即时空信息,但整体模型上是符合我们对时序的一个统一的抽象表述的。
基于监控类时序数据模型,按照上面表述的一个时序数据抽象模型,我们可以定义下时序数据的一个完整模型:
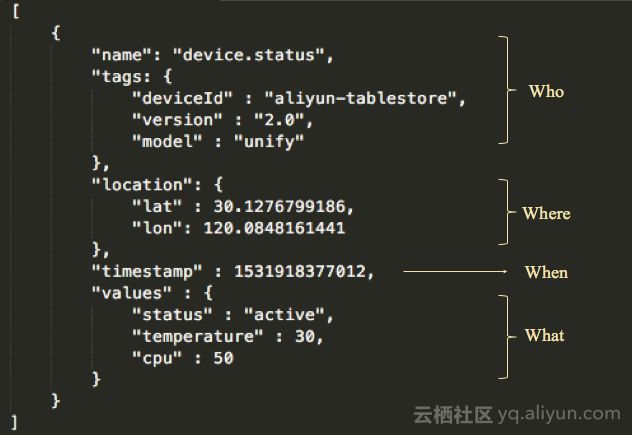
这个定义包含:
-
Name:定义数据的类别。
-
Tags:描述个体的元数据。
-
Location:数据的时空信息。
-
Timestamp:数据产生的时间戳。
-
Values:数据对应的值或状态,可提供多个值或状态,非一定是数值类型。
这个数据模型是一个更完整的时序数据模型,与OpenTSDB的监控类时序数据的模型定义主要有两个不同点,一是元数据上多了时空这一维度,二是能表述更丰富的值。
时序数据查询、计算和分析
时序数据有其特定的查询和计算的方式,大致可以分为以下几类:
时间线检索
根据数据模型定义,name+tags+location可以定位个体,每个个体拥有一条时间线,时间线上的点就是timestamp和values。时序数据的查询首先要定位到时间线,定位是一个检索的过程,需要能够根据一个或多个元数据的值的组合来做检索。也可以根据元数据的关联关系,来做drill down。
时间范围查询
通过检索定位到时间线后,会对时间线进行查询。时间线上很少有对单个时间点的查询,通常是一段连续时间范围内所有点的查询。而对于这个连续时间范围内缺失的时间点,通常会做插值处理。
聚合(Aggregation)
一次查询可以只针对单条时间线,也可以覆盖多条时间线。对于多条时间线的范围查询,通常会对返回结果做聚合。这个聚合是对相同时间点,不同时间线上值做聚合,通常称为『后聚合』。
和『后聚合』对应的是『预聚合』,预聚合是在时序数据存储之前提前将多条时间线聚合为一条时间线的过程。预聚合是提前对数据做聚合计算后存储,后聚合是查询存储数据之后做计算。
降精度(Down Sampling)
降精度的计算逻辑和聚合是类似的,区别是降精度是针对的单条时间线而不是多条时间线,是对单条时间线中一个时间范围内的数据点做聚合。降精度的目的之一是为了做大时间范围数据点的展示,另一个最主要的目的是为了降低存储成本。
分析(Analytic)
分析是为了从时序数据中挖掘更多数据价值出来,有专门的一块研究领域称为『时序分析』。
时序数据处理流程
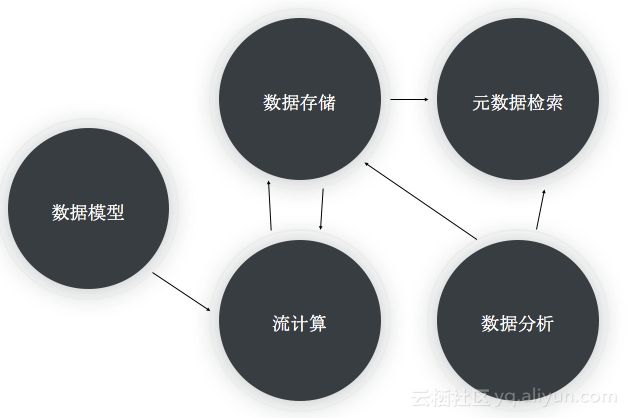
时序数据处理的核心流程如上图,包含:
-
数据模型:对时序数据的标准定义,采集上来的时序数据必须符合该模型的定义,包含时序数据的所有特征属性。
-
流计算:对时序数据做预聚合、降精度以及后聚合。
-
数据存储:存储系统提供高吞吐、海量、低成本存储,支持数据冷热分层,支持高效的范围查询。
-
元数据检索:提供元数据的存储和检索,规模在千万级到亿级的时间线元数据,并且能支持不同方式的检索(多维过滤和时空查询)。
-
数据分析:提供对时序数据的时序分析计算能力。
我们再来看这几个核心过程中,产品选型中可以用到的产品。
数据存储
时序数据是典型的非关系型数据,它的特征在于高并发高吞吐、数据体量大以及写多读少,查询模式通常是范围查询。针对这几个数据特征,是非常适合用NoSQL这类数据库的。几大流行的开源的时序数据库,均选择用NoSQL数据库作为数据存储层,例如基于HBase的OpenTSDB,基于Cassandra的KairosDB等。所以『数据存储』的产品选型,可以选择HBase或Cassandra这类开源分布式NoSQL数据库,也可以选择云服务例如阿里云TableStore。
流计算
流计算可选用开源产品例如JStrom、Spark Streaming、Flink等,也可以选择阿里的Blink以及云上产品Stream Compute。
元数据检索
时间线的元数据,在量级上也会很大,所以首先会考虑使用分布式数据库。另外在查询模式上,需要支持检索,所以数据库需要支持倒排索引和时空索引,可选择使用开源的Elasticsearch或Solr。
数据分析
数据分析需要有一个强大的分布式计算引擎,可以选择开源的Spark,也可选择云上的MaxCompute等,或者一些Serverless SQL引擎例如Presto或云上的Data Lake Analytic等。
开源时序数据库
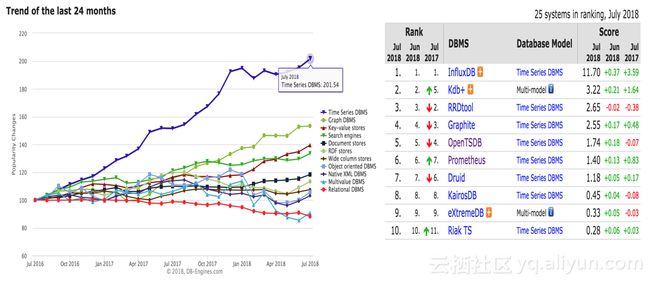
从DB-Engines上的数据库发展趋势可以看到,时序数据库在这两年的发展趋势非常迅猛,涌现了一批出色的开源时序数据库。各大时序数据库的实现也各有千秋,从几个维度来做一个综合对比:
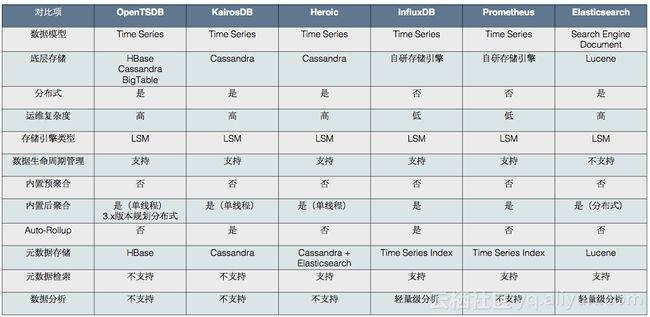
-
数据存储:都是选择了分布式NoSQL(LSM引擎)存储,有开源系的分布式数据库例如HBase、Cassandra,也有云服务系的例如BigTable,也有自研的存储引擎。
-
聚合:预聚合基本都只能依赖于外部的流计算引擎,例如Storm或Spark Streaming。在后聚合层面,查询后聚合是一个交互式的过程,所以一般不会依赖于流计算引擎,不同时序数据库提供了单线程的简单方式或者并发的计算方式。自动降精度也是一个后聚合的过程,不过不是交互式,而是一个流式的处理,这个计算是适合用流计算引擎的,但都没有实现为这么做。
-
元数据存储和检索:老牌的OpenTSDB没有专门的元数据存储,不支持对元数据的检索,元数据的获取和查询是通过扫描数据表的rowkey。KairosDB在Cassandra内是专门使用一张表做元数据存储,但是检索效率很低,需要扫描表。Heroic基于KairosDB做二次开发,使用Elasticsearch做元数据存储和索引,能支持比较好的元数据检索。InfluxDB和Prometheus则是自己实现了索引,不过索引实现也不是一件容易的事,需要承载千万甚至亿级的时间线元数据。InfluxDB在早期版本实现了一个内存版元数据索引,会有比较多的限制,例如受限于内存大小会限制时间线的规模,以及内存索引的构建需要扫描所有的时间线元数据,节点的failover时间会较长。
-
数据分析:除了简单的查询后聚合分析能力,大部分TSDB自身都不具备分析能力,除了Elasticsearch,这也是Elasticsearch能插足时序领域的重要优势。
TableStore时序数据存储
TableStore作为阿里云自研的分布式NoSQL数据库,在数据模型上我们是和Bigtable一样的Wide Column模型。在存储模型、数据规模以及写入和查询能力上,都能很好的满足时序数据的场景。在我们之上,也已经支持了监控类时序例如云监控,以及状态类时序例如阿里健康药品追踪以及邮政包裹轨迹等核心业务。也有完善的计算生态来支撑时序数据的计算与分析,在未来规划中,我们在元数据检索、时序数据存储、计算与分析以及成本优化这几个方面,都有针对时序场景特定的优化。
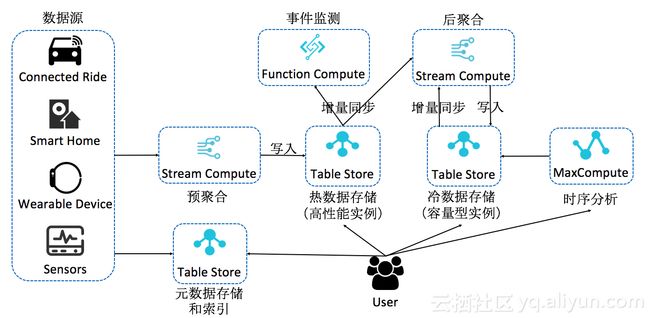
以上是基于TableStore来构建一个时序数据存储、计算和分析的完整架构。这是一套Serverless的架构,通过组合云产品的方式,能够做到提供完整的时序场景所需的所有功能。各个模块都是分布式架构,提供强大的存储和计算能力,且资源可动态扩容,各组件也可以替换成其他同类云产品,架构上比较灵活,相比开源时序数据库有很大的优势。分析下这套架构的核心优势:
存储计算分离
存储计算分离是一套领先的技术架构,其核心优势在于提供更灵活的计算和存储资源配置,成本能更弹性,同时在负载均衡和数据管理上会更优。在云上环境,让用户真正享受存储计算分离带来的红利,需要在产品层面提供存储计算分离的产品形态。
TableStore在技术架构和产品形态上,同时践行存储计算分离,能够以比较低的成本自由调配存储计算比。这个在时序数据场景尤为重要,时序数据场景是一个计算相对比较恒定的场景,但存储量是线性增长的。成本优化的首要方式是恒定的计算资源配上可无限扩容的存储,计算拉动存储,但是无需承担额外的计算成本。
数据冷热分层
时序数据有一个显著特征是数据访问冷热分明,最近写的数据会被更频繁的访问。基于这个特征,热数据采取更高IOPS的存储介质,会大大的提高整体查询的效率。TableStore提供高性能和容量型两种实例,底下分别对应SSD和SATA两种存储介质。服务化的特性,可以支持用户自由为不同精度的数据及不同的查询分析性能要求,分配使用不同规格的表。例如对于高并发低延迟查询,分配使用高性能实例,对于冷数据存储及低频查询,分配使用容量型实例。对于交互式的需要较快速度的数据分析,可以分配使用高性能实例。而对于时序数据分析,离线计算场景,可以分配使用容量型实例。
对于每个表,可自由定义数据的生命周期,例如对于高精度的表,可配置相对较短的生命周期。而对于低精度的表,可配置较长的生命周期。
存储量的大头在冷数据,对于这部分低频访问的数据,我们会通过Erasing Coding以及极致压缩算法进一步降低存储成本。
数据流动闭环
流计算是时序数据计算里最核心的计算场景,对时序数据做预聚合和后聚合。常见的监控系统架构,采用的是前置流计算的方案,预聚合以及对数据的降精度都在前置流计算内做。即数据在存储之前,都是已经处理完毕,存储的仅仅是结果,不再需要做二次降精度,最多做查询后聚合。
TableStore与Blink深度结合,目前已经可作为Blink的维表和结果表,作为Source表已开发完成待发布。TableStore可作为Blink的源和端后,整个数据流可形成闭环,这样能带来更灵活的计算配置。最原始数据进入Blink会做一次数据清洗和预聚合,之后将数据写入热数据表。这份数据可以自动流入到Blink做后聚合,并且支持回溯一定时间的历史数据,后聚合的结果可以写入冷存储。
TableStore除了对接Blink,目前也能对接函数计算(Function Compute)做事件编程,在时序场景可以做实时的异常状态监测。同时也可通过Stream API将增量数据读出,做定制化分析。
大数据分析引擎
TableStore与阿里云自研分布式计算引擎深度结合,例如MaxCompute(原ODPS)。MaxCompute可直读TableStore上的数据做分析,免去对数据的ETL过程。
整个分析过程正在做一些优化,例如通过索引去优化查询,底层提供更多的算子做计算下推等。
服务化能力
一句话总结,TableStore的服务化能力特色在于零成本接入、即开即用、全球部署、多语言SDK以及全托管服务。
元数据存储和检索
元数据在时序数据里也是很重要的一块数据,从体量上它相比时序数据会小很多,但是在查询复杂度上,比时序数据会复杂很多。
元数据从我们给的定义上来说,主要分为Tags和Location,Tags主要用做多维检索,Location主要做时空检索。所以对底层存储来说,Tags需要提供高效检索的话必须要实现倒排索引,Location则需要实现时空索引。一个服务级别的监控系统或者轨迹、溯源系统,时间线的量级在千万到亿级别,甚至更高级别。元数据要提供高并发低延迟的方案,也需要一个分布式的检索系统,所以业界比较好的实现是用Elasticsearch来存储和检索元数据。
总结
TableStore是一款通用的分布式NoSQL数据库,提供多 数据模型支持,目前已经提供的数据模型包括Wide Column(类BigTable)以及Timeline(消息数据模型)。
业界同类数据库产品(HBase、Cassandra)的应用中,时序数据是一块很重要的领域。TableStore在时序数据存储这一块,正在不停的做探索,在流计算数据闭环的打造、数据分析的优化以及元数据检索这几块,都在不断的做改进,力求能提供一个统一的时序数据存储平台。
最后,欢迎加入我们的钉钉群(群号:11789671)进行交流。