随着Docker成为当下热门的容器技术,各大公司以及中小团队都开始选择Docker来进行应用部署,从原有部署方式迁移到Docker方式过程中难免会遇到各种问题,本次分享主要介绍当当网个性化推荐组应用Docker进行应用部署以及小团队试水Docker的的若干经验,分享主要包括以下几点:
现有应用Docker化的过程Docker化的过程
结合Jenkins的自动化构建
使用Mesos和Marathon的自动化部署与集群管理

大家好,非常高兴能有这样的机会跟大家交流。

我是当当网个性化推荐组项目负责人,我们主要是负责数据分析和后台算法支持,产出的推荐结果供其他部门使用。

今天的内容主要分为两部分,一部分讲讲对于一个小团队来说,打算使用Docker的可行性以及具体的使用方法。另一部分讲一下在这过程中遇到的一些问题以及需要注意的一些情况。

我先介绍一下我们的推荐系统,跟一般的电商都是一样的,如果浏览一个商品页,下面就会推荐一些和这个商品相关的其他商品,我点开一个热水壶,就会推荐其他的厨房用品。我们当当推荐的流量差不多是每天五千万请求,一共21台机器。
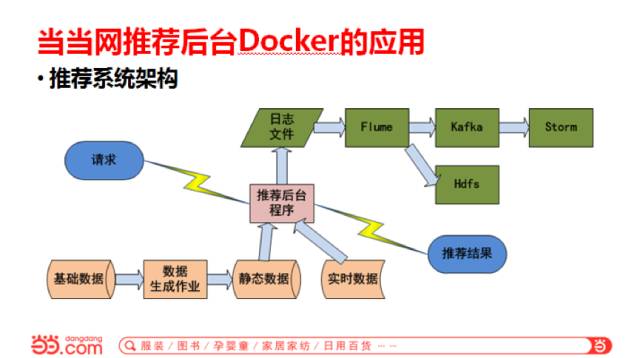
下面简单介绍一下我们推荐系统的架构。首先是基础数据,基础数据是生成推荐数据所使用的一些基本数据,包括商品信息、用户信息、用户行为信息等等。这些数据通过推荐算法与策略在每天运行的日作业上生成一份数据供推荐后台使用,同时还有一份实时数据。实时数据就是可能有促销,手机专享价等价格数据。把这些数据一起放在后台里面,前台请求商品的推荐信息,后台反馈对应的一组推荐品。
推荐后台日志也很重要,因为我们需要分析日志,日志里面包括用户什么时候点击的推荐商品,什么时候请求的推荐后台,点击率,曝光率,都是从日志数据里面出的,后台通过Flume把日志推到Kafka和Hdfs上,供后续离线数据分析和实时监控分析使用。同时还可以实时监控后台状态的功能,包括响应时间、请求数等,每一分钟更新一个点画曲线出来。

因为后台这边对我们来说,比较偏向数据和算法,后台这块,对于开发测试部署这块,尤其是测试和部署的时候,总是要拿出一个人专门跟着测试和部署,因为流程上可能有一些问题,所以就想用Docker了。想用Docker主要解决上线环境不同,配置不同的问题。
还有因为我们是电商,618、双11总会搞活动,之前大促时候扩容加机器也要提前加,把数定下来,运维部署之后数量就定下来了,如果到时候发现机器又不够了,再加机器时间要花费很多。基于这两点,我们打算用Docker试一下。

同时,使用Docker给我们带来的便利性还存在以下几方面,对于开发来说,可以使用root权限来方便的开发运行程序;对于测试来说,他们拿到的Docker镜像就包含了所有运行依赖的环境,这就保证了一致性;对运维来说,能够使用统一的指令来做相关的运维工作。
推荐后台这块,我们已经有一个成形的程序,包括配置、数据等。摆在我们面前的问题是原来的程序,我们应该怎么把它放在容器里,也就是现有程序的Docker化。Docker化这个问题,要是把程序放在容器里的话,这个程序至少应该是无状态的,不能依赖于宿主机的一切环境,如目录、IP。之前的推荐后台,推荐数据每天更新,达到50G,数据更新作业就要依赖自己IP和数据目录。从开发到测试到上线,都是很麻烦的。如果我们用Docker的话,在开发这块,以前如果用正常开发的话,root是不让用的,用Docker就可以。测试的时候,测试的同事经常问我们为什么程序起不来,一看是数据库配置错了,如果用Docker的话,环境都打包在一起,这个是没有问题的。运维是手动用脚本上21台,我们单拿出个人跟着,因为每次上线有很多东西要修改,运维不了解的话,有很多事需要我们去做。
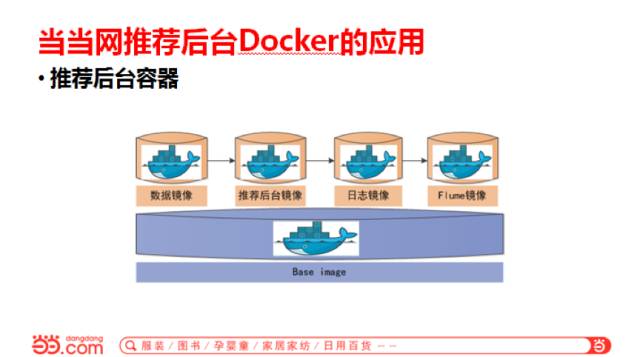
我们给后台设计这么一个简单的容器的结构,下面的Base p_w_picpath是CentOS 7,上面这层装了些必要的一些程序和工具,最上面这层才是我们推荐后台的程序镜像。除了上面这些我们自己应用镜像以外,下面其他的镜像越小越好,消耗的资源越少越好。如果想让它再小的话,可以用CoreOS等,或者自己定制都可以。我们的应用分了4个镜像,数据镜像、推荐后台本身程序镜像、日志镜像、收集日志用的Flume镜像。
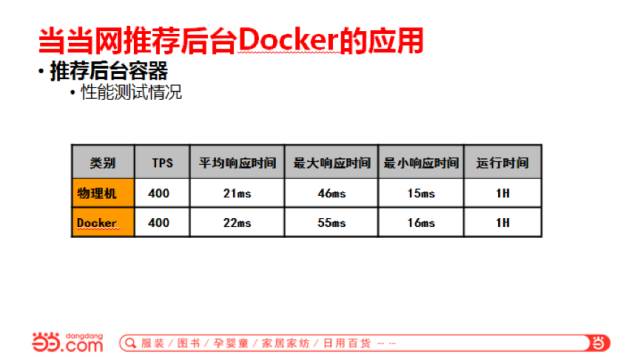
整个结构定好了以后,就要看看把程序跑在Docker里面和跑在物理机上相比,性能上有没有很大的差距。如果有的话,这个东西肯定不能上。测试来看,放在物理机上和放在容器里运行,性能基本上是差不多的。因为我们推荐后台是IO密集型的应用,对网络来说流量不是那么大,所以差的不是太多。
用了Docker以后,就想把整个生态的东西都用起来,如果都用起来的话,能让代码流水线管理,提高开发效率。这是我们现在用的流程图。开发完代码,把代码推到GitLab,Jenkins用Webhook发现有新代码推过来,把代码拿来编译一下,然后如果测试通过会到打成镜像并推到测试镜像库,同时发邮件给开发和测试。测试这边收到邮件就会把容器运行起来,这里编排用的是DockerCompose,如果那边测试通过,把镜像再提交到线上镜像库,同时通知运维用DockerCompose做相同的事情。

镜像库用的也是原生的,这个是仅供其他人查询的页面,不用登录Docker的机器就可以查询镜像的相关信息。

Jenkins从2.0开始有 Pipeline as Code,可以用类似写代码的方式把流程定义出来,同时还提供了对Docker默认的支持,比以前用起来舒服很多。Build成功就Test,然后Push到镜像库然后发邮件,这是比较简单的流程。
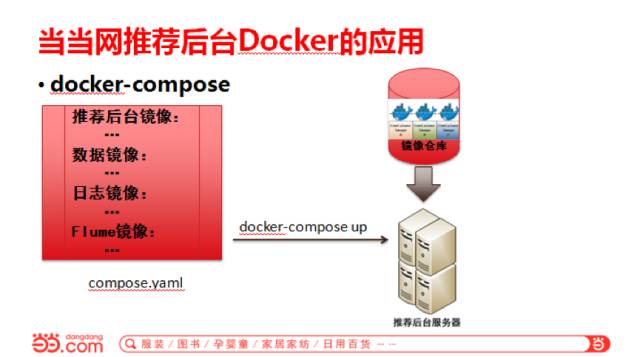
编排使用Docker Compose,因为有4个镜像一起上线。把推荐后台、数据、日志镜像、Flume镜像启动命令写到配置文件中用docker-compose up命令就可以启动了。
由于我们推荐后台里面有数据容器,刚开始的时候,数据有50多个G,拉数据镜像启动再加载的话要二十分钟,对于用Docker集群做管理的话有点不现实。所以我们一步步往外摘数据。像商品数据,拿图书来说,一个PID后面有价格、作者,评论数等等,我们会把这些比较结构化的数据放到ES里面,现在实际上已经把推荐数据放到ES里面了,其他的商品数据正在慢慢往外摘。
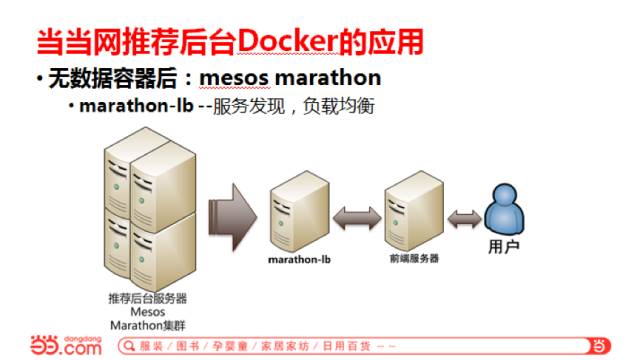
如果我们把前面说到的所有数据都摘掉,都不在本地保存,也不在运行的时候加载,那么下一步就可以上Mesos+Marathon。Mesos+Marathon可能大家都常用,这里使用的是一个最简单的结构:Mesos+Marathon的集群,后面用自带的Marathon_LB,Marathon_LB是服务发现和负载均衡的工具。如果想从前端访问推荐后台的话,都是定好的一个IP或者一个域名用LVS访问。但是用Mesos+Maratho时起来的实例都是随机IP和端口的,这里就要用Marathon lb做服务发现,同时有负载均衡的功能。Marathon_LB也可以部多台,然后前面加一级LVS。

下面说一下,想把现有的程序Docker化,我们需要注意哪些东西?首先就是镜像构建这块,一定要从Dockerfile生成,这样做最大的好处是可以通过Dockerfile“阅读”镜像。在后续的协作、升级维护等方面会带来巨大的便利。如果不从Dockerfile生成,以后更新、回滚是很麻烦的。我用Dockerfile生成的时候,其他的人可以通过Dockerfile或者镜像就可以阅读这个镜像是怎么来的。哪个镜像是base镜像,中间加了哪些软件,运行什么东西。
二是避免依赖过深。不要在基础镜像上加太多产生其他的镜像,我觉得这块最多是三四层。一层是base景像再往上是工具、中间件这样的,再往上一层就是你自己的程序,再多就比较乱了。
三是镜像里面部署的应用程序,包括对应的代码都必须有对应的Git,虽然Docker自己有一个记录历史更改的功能,但是代码对应的Git必须也要有。
镜像管理这块,虽然我们应用的是原生的,但是这几项只要跟数据有关系的都要考虑。单点问题,暂时我们用的是一台机器,不是很安全,对应的解决方案可以考虑DRBD、分布式存储以及云存储。性能问题,主要是下载加速,目前可用的解决方案是通过HTTP反向代理缓存来加速Layer的下载。权限问题可以用Nginx LUA提供一个简单快速的实现方案

发布方面,我们使用Docker,和传统的发布流程相比,Docker最大的好处是不需要考虑外部依赖,利用容器的自包含的特点,我们可以将发布回滚流程标准化和产品化。而传统的发布和回滚,需要casebycase去针对不同应用做升级回滚的方案。要做到基于Docker的发布,镜像的生成必须坚持自动化,否则会发现升级比传统的方法更麻烦。因此在现实中我们也发现很多人将代码目录放到主机目录映射到容器内,这样做破坏了Docker的自包含特性,解决的办法是坚持应用镜像更新自动化。
日志管理的话,如果把日志放在容器里面,由于容器是无状态的,所以存储在容器内的日志会随着容器的销毁而消失。你要把日志实时保存下来,或者把日志放在宿主机,但是放在宿主机的话,有点违反Docker化不依赖宿主机的任何环境的要求。建议放一些日志收集工具如Logstash或者Flume等。

如果用Docker配置管理,手工修改容器内的配置,再新建启动的时候,配置文件就没有了。我们要看一下有没有其他的方式去配置容器或者是配置容器里面运行程序的参数。第一个就是配置文件,每一个版本配置文件都要做一个容器,这是最简单的方法。设置环境变量,指定容器运行时的环境变量,然后应用再去用环境变量。配置中心,用数据库或者ZooKeeper,把配置放在里面做配置中心都可以。
网络管理这块,从Docker1.9开始,出了一个自定义的网络类型,而且不再推荐容器使用默认的bridge网卡,它的存在仅仅是为了兼容早期设计。还有Host,Host网络中容器和主机共享网络命名空间,不同容器需要做好端口规划,防止端口冲突。1.9的自定义网络,以前Docker就一个网络docker0,现在如果用自定义的话,可以建多个像docker0这样的网络,可以连接和隔离容器之间的通信。

应用Docker时发现的问题,一开始用Docker的时候,实际上我们的机器从内核到系统版本都不符合,这个要运维配合升级。如果自己团队想用Docker的话,这些东西都是要注意的。包括运行环境、内核版本、操作系统的发行版本,这些都是有要求的。
镜像载荷要求,如果一个现有的比较成熟的架构的应用,要放到Docker里面是必须要考虑如何Docker化的。原有程序是不是依赖宿主机的环境,包括用不用本机的IP,本地的目录。最开始的我们后台下载数据的时候是需要往我们开发的数据中心里面发送自己的IP,数据中心才会往IP对应的机器推数据,类似这样的问题还是需要考虑的和修改。
还有就是我们的推荐后台遇到的问题,是数据过大,数据50G。当时折中的方法,先往上扔一个空数据容器,后台第一次启动的时候,如果容器里面没有数据的话,自己就先下载,这也是一个折中的办法。
多实例运行,我们的机器可够跑多个实例的,启动的时候每个实例的占的内存和CPU都要考虑一下。
镜像管理、版本控制。如果提交一个镜像,提交时tag必须要有比较严格的规定,例如格式定义等,否则会比较混乱。

我们在正常物理机的情况下,ulimit的参数,直接可以改配置文件,或者直接运行一下指令修改。但是在Docker里面你不能用。就要在docker run是用–ulimit 来指定,如果使用默认的参数,要注意下CentOS6和7是不同的。
DNS,默认的是8.8.8.8和8.8.4.4,有的时候这个DNS访问就不好使了。如果有需要还是要手动用–dns来指定内部IP这块,如果原先的程序是依赖本地IP做一些事情的话,自己获取的话,用Bridge是内部IP,有这个需求的应用必须要注意一下。
latest tag,版本控制,运行镜像的时候,不要用latest,也不要把后面的tag省去。latest今天运行的是这个版本,第二天推了一个新的,latest就可能被覆盖了,有可能会注意不到这个问题。

Q:你提到数据量过大,扔一个空的,能不能具体介绍一下?还要下载数据?
A:这个是这样的,正常来说是把数据放到镜像里面起来以后,link到其他的容器里面。但是我先直接扔一个空的数据镜像,link的目录都是指定好的,后台启动的时候,先检测容器是不是空的,如果是空的,从数据服务器往这里同步,这是最开始的时候折中的办法。
Q:同步完应该也是50多G吧?
A:因为数据每天都要更新,如果每天更新50多个G的镜像的话,我们的镜像库也要每天往里放50个G,单独更新数据的话,包括用的空间,传输数据量来说要好很多。
Q:还有一个问题,ES是怎么使用的?
A:我们拿它当数据存储用,存储结构化的数据。
Q:选Marathon和Mesos的时候,有没有评价过Kubernetes?
A:因为Mesos比较成熟,Kubernetes也不好拉镜像,而且我们数据分析用Spark也是运行在Mesos上,比较熟悉,而且混合负载也比较好。
Q:容器网络用的是什么?
A:是用它自己的Bridge。