2019独角兽企业重金招聘Python工程师标准>>> 

skywalking 简介(链路跟踪与分析)
随着业务越来越复杂,企业应用也进入了分布式服务化的阶段,随着模块的不断增多,一次请求可能会涉及到十几个甚至几十个服务的协同处理,那么如何准确快速的定位到线上故障和性能瓶颈,便成为我们不得不面对的棘手问题,传统的日志监控等方式无法很好达到跟踪调用,排查问题等需求。在谷歌论文《 Dapper,大规模分布式系统的跟踪系统》的指导下,许多优秀的APM应运而生。
分布式追踪系统发展很快,种类繁多,给我们带来很大的方便。但在数据采集过程中,有时需要侵入用户代码,并且不同系统的 API 并不兼容,这就导致了如果您希望切换追踪系统,往往会带来较大改动。OpenTracing为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范。OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。详细介绍见
opentracing文档中文版。
Skywalking是一款APM(应用程序性能监视器),尤其适用于微服务,Cloud Native和基于容器的架构系统。也称为分布式跟踪系统。它提供了一种自动检测应用程序的方法:无需更改目标应用程序的任何源代码; 以及具有高效流媒体模块的收集器。
针对分布式系统的APM(应用性能监控)系统,特别针对微服务、cloud native和容器化(Docker, Kubernetes, Mesos)架构, 其核心是个分布式追踪系统。
该项目由国人吴晟基于OpenTracking实现的开源项目skywalking(码云、github)
2017年12月8日,Apache软件基金会孵化器项目管理委员会 ASF IPMC宣布“SkyWalking全票通过,进入Apache孵化器”
skywalking 特点
性能好,针对单实例5000tps的应用,在全量采集的情况下,只增加 10% 的CPU开销。详细评测见《skywalking agent performance test》。
支持多语言探针
支持自动及手动探针;自动探针:Java支持的中间件、框架与类库列表; 手动探针:OpenTrackingApi、@Trace注解、trackId集成到日志中。
采用探针技术,在使用过程中,完全是0代码,无侵入,分布式自动采集与监控系统运行;
skywalking 下载
官方网站:
http://skywalking.apache.org/
http://incubator.apache.org/projects/skywalking.html
github项目地址:
https://github.com/OpenSkywalking/skywalking-netcore
下载
http://skywalking.apache.org/downloads/
可以从上述地址下载,也可以直接到github上下载,选择最新版本,运行环境:jdk7,jdk8,tomcat7,tomcat8(tomcat针对web项目),建议安装使用过程,多看github上的doc文档;
部署 java agent
拷贝agent目录到所需位置. 日志,插件和配置都包含在包中,请不要改变目录结构.建议将该agent目录与客户端应用放在同一台服务器,多台服务器需要监控则都部署agent目录,每台服务器上的应用配置本机的agent参数;
增加JVM启动参数, -javaagent:/path/to/skywalking-agent/skywalking-agent.jar. 参数值为skywalking-agent.jar的绝对路径。
新的 agent package 目录结构如下:
+-- skywalking-agent
+-- activations
apm-toolkit-log4j-1.x-activation.jar
apm-toolkit-log4j-2.x-activation.jar
apm-toolkit-logback-1.x-activation.jar
...
+-- config
agent.config
+-- plugins
apm-dubbo-plugin.jar
apm-feign-default-http-9.x.jar
apm-httpClient-4.x-plugin.jar
.....
skywalking-agent.jar启动被监控应用.
高级特性
插件全部放置在 /plugins 目录中.新的插件,也只需要在启动阶段,放在目录中,就自动生效,删除则失效.
Log默认使用文件输出到 /logs目录中.
部署 java agent FAQs
Linux Tomcat 7, Tomcat 8
修改 tomcat/bin/catalina.sh,在首行加入如下信息:
CATALINA_OPTS="$CATALINA_OPTS -javaagent:/path/to/skywalking-agent/skywalking-agent.jar"; export CATALINA_OPTSWindows Tomcat 7, Tomcat 8
修改 tomcat/bin/catalina.bat,在首行加入如下信息:
set "CATALINA_OPTS=-javaagent:/path/to/skywalking-agent/skywalking-agent.jar"JAR file
在启动你的应用程序的命令行中添加 -javaagent 参数. 并确保在-jar参数之前添加它. 例如:
java -javaagent:/path/to/skywalking-agent/skywalking-agent.jar -jar yourApp.jar
更改agent配置
在agent\config目录中的agent.config内修改如下:
agent.application_code=CollectorDBCluster #对应elasticsearch中的clusterName,表示数据存储的集合名称
collector.servers=10.176.16.39:10800 #对应collector配置中的 naming
collector安装与配置
所需的第三方软件
JDK6+(被监控的应用程序运行在jdk6及以上版本)
JDK8+(SkyWalking collector和WebUI部署在jdk8及以上版本)
Elasticsearch 5.x(集群模式或不使用)
Zookeeper 3.4.10(单机可不使用)
被监控应用的宿主服务器系统时间(包含时区)与collectors,UIs部署的宿主服务器时间设置正确且相同
部署 Zookeeper(集群需要)
Zookeeper用于collector协作,仅在需要多个collector实例时才需要.
在每个collector实例的application.yml中添加Zookeeper集群配置
cluster:
# zk用于管理collector集群协作.
zookeeper:
# 多个zk连接地址用逗号分隔.
hostPort: localhost:2181
sessionTimeout: 100000部署Elasticsearch
修改elasticsearch.yml文件
设置 cluster.name: CollectorDBCluster。此名称需要和collector配置文件一致。
设置 node.name: anyname,可以设置为任意名字,如Elasticsearch为集群模式,则每个节点名称需要不同。
增加如下配置
# ES监听的ip地址
network.host: 0.0.0.0
thread_pool.bulk.queue_size: 1000请参阅ElasticSearch官方文档以了解如何部署集群(推荐)
启动 Elasticsearch
配置 collector
下面是关于collector连接配置的5种类型方式
naming :agent使用HTTP协议连接collectors
agent_gRPC :agent使用gRPC协议连接collectors
remote :Collector使用gRPC协议连接collector
ui :使用HTTP协议连接collector,(大多数情况不需要修改)
agent_jetty:agent使用HTTP协议连接collectors(可选连接)
以下是 application.yml的详细的配置
config/application.yml
cluster:
# The Zookeeper cluster for collector cluster management.
zookeeper:
hostPort: localhost:2181
sessionTimeout: 100000
naming:
# Host and port used for agent config
jetty:
# 配置agent发现collector集群,host必须要系统真实网络ip地址. agent --(HTTP)--> collector
host: localhost
port: 10800
contextPath: /
remote:
gRPC:
# 配置collector节点在集群中相互通信,host必须要系统真实网络ip地址. collectorN --(gRPC) --> collectorM
host: localhost
port: 11800
agent_gRPC:
gRPC:
# 配置agent上传(链路跟踪和指标)数据到collector,host必须要系统真实网络ip地址. agent--(gRPC)--> collector
host: localhost
port: 11800
agent_jetty:
jetty:
# 配置agent上传(链路跟踪和指标)数据到collector,host必须要系统真实网络ip地址. agent--(HTTP)--> collector
# SkyWalking native Java/.Net/node.js agents don't use this.
# Open this for other implementor.
host: localhost
port: 12800
contextPath: /
analysis_register:
default:
analysis_jvm:
default:
analysis_segment_parser:
default:
bufferFilePath: ../buffer/
bufferOffsetMaxFileSize: 10M
bufferSegmentMaxFileSize: 500M
ui:
jetty:
# 配置UI访问collector,host必须要系统真实网络ip地址.
host: localhost
port: 12800
contextPath: /
# 配置Elasticsearch 集群连接信息
storage:
elasticsearch:
clusterName: CollectorDBCluster
clusterTransportSniffer: true
clusterNodes: localhost:9300
indexShardsNumber: 2
indexReplicasNumber: 0
highPerformanceMode: true
# 设置统计指标数据的失效时间,当指标数据失效时系统将数据自动删除.
traceDataTTL: 90 # 单位为分
minuteMetricDataTTL: 45 # 单位为分
hourMetricDataTTL: 36 # 单位为小时
dayMetricDataTTL: 45 # 单位为天
monthMetricDataTTL: 18 # 单位为月
configuration:
default:
# namespace: xxxxx
# 告警阀值
applicationApdexThreshold: 2000
serviceErrorRateThreshold: 10.00
serviceAverageResponseTimeThreshold: 2000
instanceErrorRateThreshold: 10.00
instanceAverageResponseTimeThreshold: 2000
applicationErrorRateThreshold: 10.00
applicationAverageResponseTimeThreshold: 2000
# 热力图配置,修改配置后需要删除热力指标统计表,由系统重建
thermodynamicResponseTimeStep: 50
thermodynamicCountOfResponseTimeSteps: 40参见下图示例配置:
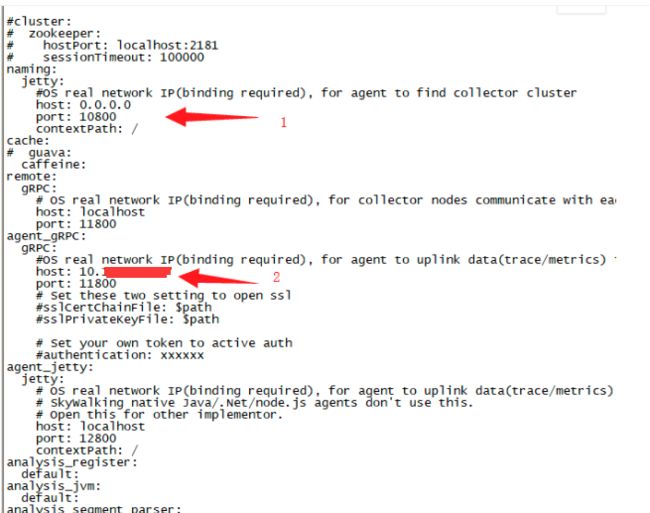
默认zk是注释的;
1表示的naming,是agent代理连接collector的连接,配置配置0.0.0.0或localhsot,表示对当前collector所在的服务器端口进行监听;
2表示的agent_gRPC,是指通过naming连接到collertor之后,由collertor返回和告知agent发送监控数据的gRPC连接,通常这个是配置,当前collector所在服务器,端口默认;

3.表示当前的elasticsearch的连接配置,只需要配置clusterName和clusterNodes就行,如果有多个节点,则IP:prot之后用逗号隔开;clusterName必需agnet和collector一致;
配置 UI
UI的配置项保存在webapp/webapp.yml中. 参考下面描述,更改 collector.ribbon.listOfServers并且与 naming.jetty参数值对应.
Config Description
server.port 默认监听8080端口,修改该端口不能生效,则在skywalking-webapp.jar包application.yml中更改
collector.ribbon.listOfServers collector的访问服务名称(与config/application.yml中naming.jetty配置保持相同) 且若是多个 collector 服务名称用','分隔
collector.path Collector 查询uri地址. 默认是/graphql
collector.ribbon.ReadTimeout 查询超时时间,默认是10秒
security.user.* 登录用户名/密码. 默认是 admin/admin
启动 collector 节点
使用 bin/startup.sh同时启动collector和UI,若不使用1启动,需要单独启动,参考2,3
单独启动collector,运行 bin/collectorService.sh
单独启动UI,运行 bin/webappService.sh
自定义配置路径过滤
提供了一个可选插件 apm-trace-ignore-plugin
这个插件的作用是对追踪的个性化服务过滤.
你可以设置多个需要忽略的URL路径, 意味着包含这些路径的追踪信息不会被agent发送到 collector.
当前的路径匹配规则是 Ant Path匹配风格 , 例如 /path/*, /path/**, /path/?.
将apm-trace-ignore-plugin-x.jar拷贝到agent/plugins后,重启探针即可生效
Skywalking-使用可选插件 apm-trace-ignore-plugin 有详细使用介绍
如何配置路径
有两种配置方式,可使用任意一种,配置生效的优先级从高到低:
第一种:
在系统环境变量中配置,你需要在系统变量中添加skywalking.trace.ignore_path, 值是你需要忽略的路径,多个以,号分隔
如:在启动参数设置,添加-Dskywalking.trace.ignore_path=/your/path/**
第二种:
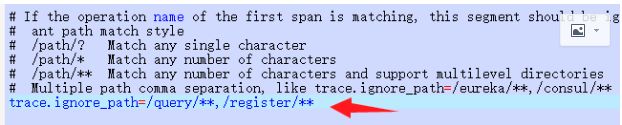
将/agent/optional-plugins/apm-trace-ignore-plugin/apm-trace-ignore-plugin.config 复制或剪切到 /agent/config/ 目录下,加上配置
trace.ignore_path=/your/path/1/**,/your/path/2/**
支持Mysql数据库分片存储
除了默认的Elasticsearch存储外,用户可以用shardingJDBC结合MySQL作为存储实现。 注意:目前仅支持MYSQL数据库的分片存储,且由于license限制,需要用户手动引入mysql驱动包。
配置要求
手工导入MYSQL的驱动包mysql-connector-java-5.1.36.jar到collector libs目录下。
config/application.yml中,删除Elasticsearch配置,添加shardingjdbc配置如下。
storage:
shardingjdbc:
driverClass: com.mysql.jdbc.Driver
# JDBC Datasource connections for ShardingJDBC, multiple should be separated by comma
url: jdbc:mysql://ip1:port1/skywalking,jdbc:mysql://ip2:port2/skywalking
# Usernames, which match the sequence of Datasource URLs
userName: admin,admin
# Passwords, which match the sequence of Datasource URLs
password: 123456,123456
使用SkyWalking手动追踪API
使用 maven 和 gradle 依赖相应的工具包,该工具包通过mavne有可能无法下载,可手动下载jar导入到maven
org.apache.skywalking
apm-toolkit-trace
${skywalking.version}
随时使用 TraceContext.traceId() API,在应用程序的任何地方获取traceId.
import org.apache.skywalking.apm.toolkit.trace.TraceContext;
...
modelAndView.addObject("traceId", TraceContext.traceId());
示例代码,仅供参考
import org.apache.skywalking.apm.toolkit.trace.Trace;
对任何需要追踪的方法,使用 @Trace 标注,则此方法会被加入到追踪链中。
在被追踪的方法中自定义 tag.
ActiveSpan.tag("my_tag", "my_value");
/**
* 对任何需要追踪的方法,使用 @Trace 标注,则此方法会被加入到追踪链中。
* 在被追踪的方法中自定义 tag.
*/
@RequestMapping("/login")
@Trace
public String login(@RequestParam("userName") String userName, @RequestParam("passwrod") String passwrod){
logger.info("login to system1, user: " + userName);
//TraceContext.traceId() API,在应用程序的任何地方获取traceId.
System.out.println(userName + "======" + passwrod + "========"+ TraceContext.traceId());
ActiveSpan.tag("login_tag", "login to system, user: " + userName);
return userService.login(userName,passwrod);
}
增加log4j2日志组件集成
使用 maven 和 gradle 依赖相应的工具包
org.apache.skywalking
apm-toolkit-log4j-2.x
{project.release.version}
在log4j2.xml中的pattern 配置节,配置[%traceId]
当你使用-javaagent参数激活sky-walking的探针, 如果当前上下文中存在traceid,log4j2将在输出traceId。如果探针没有被激活,将输出TID: N/A.
监控界面
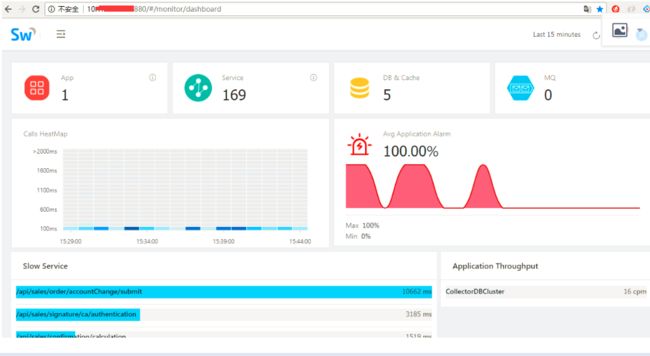
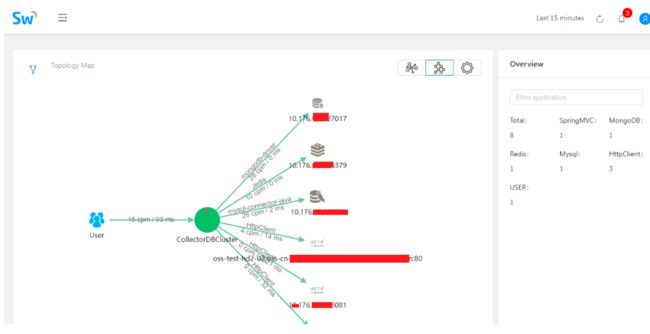

问题:
18-Jul-2018 18:55:26.296 严重 [SkywalkingAgent-2-GRPCChannelManager-0] org.apache.skywalking.apm.dependencies.io.grpc.internal.ManagedChannelImpl$ManagedChannelReference.cleanQueue *~*~*~ Channel org.apache.skywalking.apm.dependencies.io.grpc.internal.ManagedChannelImpl-83 for target localhost:11800 was not shutdown properly!!! ~*~*~*
Make sure to call shutdown()/shutdownNow() and awaitTermination().
答:将application.yml配置中的agent_gRPC下的host改成当前部署服务器的IP,端口根据需要更改;
参考:
https://www.oschina.net/news/95324/apache-skywalking-apm-support-dot-net-core
https://juejin.im/post/5ab5b0e26fb9a028e25d7fcb
http://www.iocoder.cn/categories/SkyWalking/(强烈推荐)