为什么80%的码农都做不了架构师?>>> 
| 1 2 3 4 5 6 7 8 |
声明: 采集程序只做技术研究使用,切不可做出格的事以免惹来麻烦 首先感谢广大网友的支持,现将源代码公开,地址如下: https://github.com/owner888/phpspider github地址的demo目录下的 mafengwo.php 和 mafengwo.sql 本程序所采集的数据都是马蜂窝上面公开的数据,并未触及隐私内容,也不公开数据库,广大网友无需担心。 你们有什么想要的功能可以在下面留言给我,我会收集一下给大家做出来。也可以加入Q群 PHP爬虫研究中心(147824717)一起讨论。 转载请注明本文地址,及作者[email protected] |
随着物质的提高,旅游渐渐成为人们的焦点,火热的国庆刚刚过去,乘着这股余热,我想很多人都想知道,大家一般会去哪里玩呢,于是我花了10分钟写了一个采集马蜂窝游记的小程序,当然速度能有这么快,完全依赖于PHP著名爬虫框架phpspider。
国际惯例,我们先来看看代码怎么写,算作抛砖引玉吧 ^_^
马蜂窝不同于常规网站,因为并发量高并且某些数据需要实时,比如观看人数,点赞人数,所以网站多处使用了Ajax,而Ajax对于普通采集者来说,是个比较大的问题。
观察了一下马蜂窝网站,最终确定了采集路线:
获取热门城市 -> 获取城市下的游记列表 -> 获取游记内容 -> 提取游记内容的游记标题、城市、出发时间等,接下来我们用三个步骤来实现它。。。
1、获取热门城市
http://www.mafengwo.cn/mdd/citylist/21536.html

首先我们要采集下这些热门城市
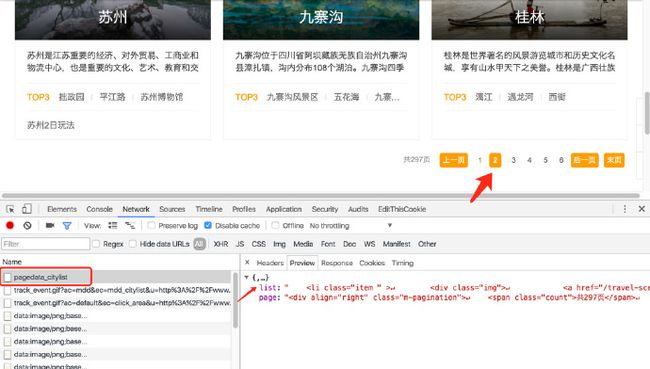
当我们点击页数的时候,发现他的数据是Ajax加载的,末页是297,而且使用的是POST方法

提交的参数如下:

很明显这个page就是页数了,这里就有个问题,phpspider框架是有 URL 去重机制的,POST的话URL只有一个,但是query_string是不影响POST数据的,我们可以在后面加上 ?page=1|2|3…,所以我们代码可以这么写:
设置列表页规则:
| 1 2 3 |
'list_url_regexes' => array( "http://www.mafengwo.cn/mdd/base/list/pagedata_citylist?page=d+", ) |
在入口回调函数入口所有城市列表:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$spider->on_scan_page = function($page, $content, $phpspider) { // 上面Ajax分页的末页是297页 for ($i = 0; $i $url, 'method' => 'post', 'fields' => array( 'mddid'=>21536, 'page'=>$i, ) ); // 热点城市列表页URL入队列 $phpspider->add_url($url, $options); } }; |
2、获取热门城市下的游记列表
点击进入一个城市后,我们可以看到他下面的游记列表
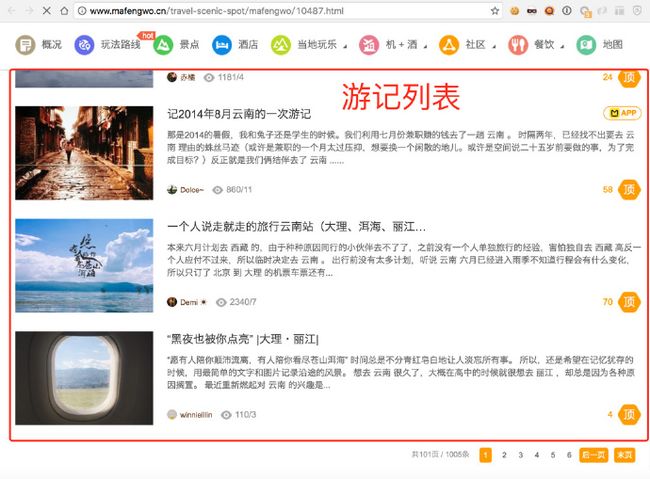
当然和上面一样,也是Ajax加载的,我们可以打开chrome的开发者工具,点击Network,然后随意点击一个分页得到Ajax的URL:

和城市列表一样,也是POST,参数如下:
很明显page就是页数了,当然我们直接通过POST方式访问Ajax地址:
http://www.mafengwo.cn/gonglve/ajax.php?act=get_t…
是直接报错的,他需要来路,综合以上,我们代码可以这么来写:
首先我们要在 on_start 回调函数里面加上来路URL
| 1 2 3 4 |
$spider->on_start = function($phpspider) { $phpspider->add_header('Referer','http://www.mafengwo.cn/mdd/citylist/21536.html'); }; |
和上面获取城市列表一样,设置列表匹配规则:
| 1 2 3 |
'list_url_regexes' => array( "http://www.mafengwo.cn/gonglve/ajax.php?act=get_travellist&mddid=d+", ) |
然后在 on_list_page 回调里面判断如果是第一页就获取总页数,然后循环入队列:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
preg_match('#共(.*?)页#', $data_page, $out); for ($i = 0; $i $url, 'method' => 'post', 'fields' => array( 'mddid'=>$v, 'pageid'=>'mdd_index', 'sort'=>1, 'cost'=>0, 'days'=>0, 'month'=>0, 'tagid'=>0, 'page'=>$i, ) ); // 游记列表页URL入队列 $phpspider->add_url($url, $options); } |
通过上面两个步骤,我们就把所有热门城市下的游记列表都放入到了队列,接下来我们进行第三步,从这些列表里面获取内容页URL,然后提取内容。
3、获取热门城市下的游记列表
在 on_list_page 方法里面会得到列表页的内容,从这些内容里面我们可以提取内容页的URL
| 1 2 3 4 5 6 7 8 9 10 11 12 |
// 获取内容页 preg_match_all('##', $html, $out); if (!empty($out[1])) { foreach ($out[1] as $v) { $url = "http://www.mafengwo.cn/i/{$v}.html"; // 内容页URL入队列 $phpspider->add_url($url); } } |
接下来我们来配置field提取内容页字段
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
'fields' => array( // 标题 array( 'name' => "name", 'selector' => "//h1[contains(@class,'headtext')]", 'required' => true, ), // 分类 array( 'name' => "city", 'selector' => "//div[contains(@class,'relation_mdd')]//a", 'required' => true, ), // 出发时间 array( 'name' => "date", 'selector' => "//li[contains(@class,'time')]", 'required' => true, ), ) |
设计一张数据表:

当然我们还可以获取游记的浏览量、收藏、分享、置顶、游玩金额等等,太多了,方法类似。
到此程序就设计完了,总共不到200行的代码,得益于phpspider自带了多进程采集功能,数据很快就采集完成,总共7W多点。


得到这些数据以后,我们能干什么呢?!
Top10 旅游城市分别是

可以看得出,云南是一个好地方,也是博主日夜思念的地方啊。。。
五一和国庆期间旅游城市占比
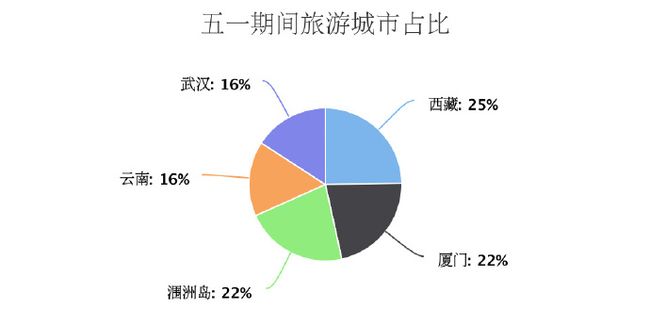

可以看得出,五一的时候大家喜欢去西藏玩,国庆却更青睐青岛,好吧,这两个地方博主都没去过,表示好受伤~_~!
接下来我们来看看这一年来北京和杭州的旅游旺季
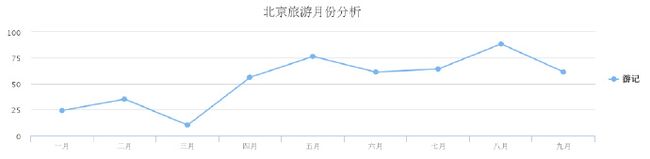
可以看出七八月份去北京的人会比较多,这个时候北京是最爽的,不热也不冷,博主就曾经有有一年8月份去的北京,舒服死了^_^
我们再来看看杭州

看得出3月底到4月中旬是杭州适合游玩的季节啊,那时候春暖花开,天气也不错,听说太子湾公园每年那时候都会有樱花和郁金花展,非常美,艾玛旅游病又犯了~_~!
好吧文章到此就结束了,其实还想分析更多,比如采集热门路线啊,热门景点啊,热门图集啊,还有旅游路线的价位啊,最终形成一个旅游的APP,如果你们有好的想法,也可以来告诉我,我把他采集下来,供大家参考 ^_^
最后,对源代码感兴趣的同学可以上github搜索phpspider哈 ^_^