基于Flink的实时日志分析系统实践
前言
目前业界基于 Hadoop 技术栈的底层计算平台越发稳定成熟,计算能力不再成为主要瓶颈。 多样化的数据、复杂的业务分析需求、系统稳定性、数据可靠性, 这些软性要求, 逐渐成为日志分析系统面对的主要问题。2018 年线上线下融合已成大势,“新零售”的战略已经开始实施,其本质是数据驱动,为消费者提供更好的服务, 日志分析系统作为数据分析的第一环节,为数据运营打下了坚实基础。
数据分析流程与架构介绍
业务背景
电商线上、线下运营人员,对数据分析需求多样化、时效性要求越来越高。目前实时日志分析系统每天处理数十亿条流量日志,不仅需要保证:低延迟、数据不丢失等要求,还要面对复杂的分析计算逻辑,这些都给系统建设提出了高标准、高要求。
-
数据来源丰富:线上线下流量数据、销售数据、客服数据等
-
业务需求多样: 支撑营销、采购、财务、供应链商户等数据需求
流程与架构
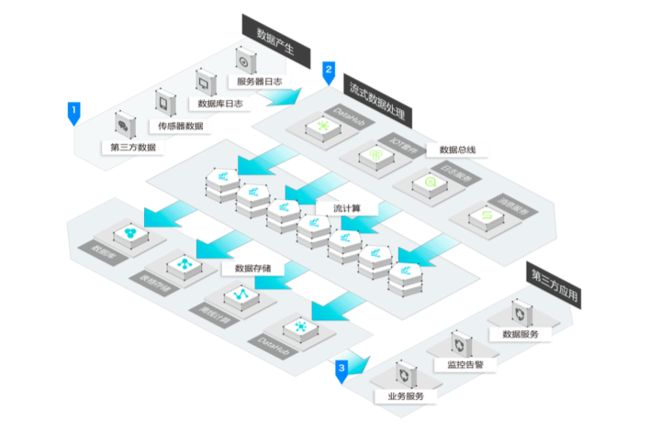
实时日志分析系统底层数据处理分为三个环节:采集、清洗、指标计算。
-
采集模块:收集各数据源日志,通过 Flume 实时发送 Kafka。
-
清洗模块:实时接收日志数据,进行数据处理、转换,清洗任务基于Flink实现,目前每天处理十亿级别流量数据,经过清洗任务处理后的结构化数据将再次发送到 Kafka 队列
-
指标计算:从 Kafka 实时接收结构化流量数据,实时计算相关指标, 指标计算任务是基于Flink的任务,其优点是:低延时、高吞吐、支持标准 SQL、开发简单、exactly-once语义、支持窗函数计算等。

指标计算后数据主要存储到 HBase、Druid 等存储引擎,业务系统读取实时计算好的指标数据,为运营人员提供数据分析服务。
Flink在指标分析实践
Flink介绍
众所周知 Flink 是流式数据处理框架,而 Flink借鉴流处理的理念实现的实时算框架,通过将数据按时间顺序处理,实际应用中根据延迟要求合理设置聚合窗口。
Flink支持多种数据源:Kafka、MQ、SLS、Datahub 等,原生支持写入到 MQ、OTS、常见关系数据库等存储介质。
对比 Storm、Spark,Flink的实时架构,延时更低,吞吐量更高,支持 SQL,与 上下游消息队列、数据库等存储介质支持的更好,开发方便,并且支持 Window 特性,能支持复杂的窗口函数计算。
NDCG指标分析
Normalized Discounted Cumulative Gain,即 NDCG,常用作搜索排序的评价指标,理想情况下排序越靠前的搜索结果,点击概率越大,即得分越高 (gain)。CG = 排序结果的得分求和, discounted 是根据排名,对每个结果得分 * 排名权重,权重 = 1/ log(1 + 排名) , 排名越靠前的权重越高。首先我们计算理想 DCG(称之为 IDCG), 再根据用户点击结果, 计算真实的 DCG, NDCG = DCG / IDCG,值越接近 1, 则代表搜索结果越好。DCG 计算公式如下:
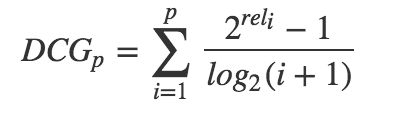
IDCG是理想情况下的DCG,即对于一个查询语句和p来说,DCG的最大值。公式如下:

其中|REL|表示,文档按照相关性从大到小的顺序排序,取前p个文档组成的集合。也就是按照最优的方式对文档进行排序。
由于每个查询语句所能检索到的结果文档集合长度不一,p值的不同会对DCG的计算有较大的影响。所以不能对不同查询语句的DCG进行求平均,需要进行归一化处理。nDCG就是用IDCG进行归一化处理,表示当前DCG比IDCG还差多大的距离。公式如下:

NDCG计算方案设计
通过统计搜索行为时间跨度,86% 的搜索行为在 5 分钟内完成、90% 的在 10 分钟内完成(从搜索开始到最后一次点击结果列表时间间隔),通过分析比较, NDCG 实时计算时间范围设定在 15 分钟。这就提出了两个计算难点:
-
时间窗口计算:每一次都是对前 15 分钟数据的整体分析
-
去重: 时间窗口内保证一次搜索只计算一次
最终我们选择了Flink框架,利用其 Window 特性,实现Sliding Time Window窗口计算。时间窗口为 15 分钟,步长 5 分钟,意味着每 5 分钟计算一次。每次计算,只对在区间[15 分钟前, 10 分钟前]发起的搜索行为进行 NDCG 计算,这样就不会造成重复计算。

按照方案开发后,线上测试很快发现问题,保存 15 分钟的数据消耗资源太多,通过分析发现:搜索数据仅占流量数据很小一部分, 清洗任务在 Kafka 单独存储一份搜索数据,NDCG 计算订阅新的搜索数据,大大减小了资源消耗
性能与数据安全保障
性能保障
容量预估与扩展
容量预估不是一个静态工作
-
流量日志在不断增长,而系统处理能力是有限的
-
大促活动会造成额外的数据高峰。
针对这些情况, 提前根据业务增长情况进行扩容是最重要的保障手段。扩容依赖系统的水平扩展能力,利用Flink
支持自动扩容的特点,通过调大Kafka Topic 分区数量,模拟数据峰值实现自动调优分配Flink处理节点和并发数等参数调节,保障数据处理性能满足业务需求。
多维分析计算优化
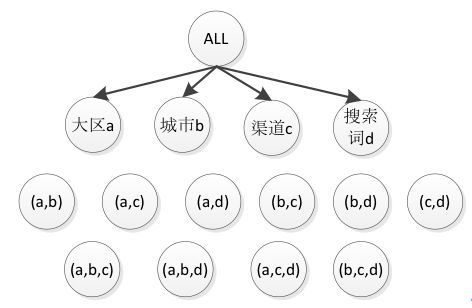
以 NDCG 指标为例子,目前支持 4 个维度组合的计算:大区、城市、渠道、搜索词,为了支持 4 个维度任意组合,需要进行 15 次计算,在 HBase 进行 15 次存储更新操作。如下图所示。
目前时间粒度是可以支持杪,分钟,小时,天,周,月,任务数、存储都要翻几倍。此时,一个高性能的 OLAP 计算引擎,来提升指标分析效率,变得更加迫切。
Flink支持 sum、max、min、avg、count、distinct count 等常规聚合计算,支持从 Kafka 实时数据接入,其列式存储结构提升数据检索效率, 通过数据预聚合提升了计算效率。
经过方案预研以及性能测试,Druid 大大提升了 NDCG 这类指标的计算分析效率,让指标分析任务变得更轻量级,指标多维分析能力交给 Druid 来解决。
数据保障
保障数据不丢失
Flink数据任务可能会需要重启进行发布操作,保障数据在一定时间内不丢失,尤为重要。分解下来需要保证两点:
-
数据源保证数据不丢失
-
数据任务保证数据被处理
第一点,Kafka 通过数据落磁盘、备份机制保证数据不丢失;
第二点,Flink 提供了 Checkpoint 机制,保障数据必须被处理切处理一次(exactly-once 语义)。
Flink提供了 checkpoint备份机制(基于state),任务失败或重启后,可以利用 checkpoint 数据进行恢复,保障数据被处理完成, state 日志会把所有数据存储异步上传 HDFS。Flink state 针对 Kafka 进行了优化,数据源保存了消费Kafka的偏移量(offset)。 任务恢复的时候,根据 offset 重新读取 Kafka 数据即可。
exactly-once 语义保障
对于销售类数据,不仅要保证数据被处理,还需要保证数据仅被处理一次,涉及销售财务指标数据必须 100% 准确。
第一种方案:Labmda 架构 + Redis 去重
-
实时去重:一个订单被计算后,将订单号写入 Redis,通过比对订单号,保证数据不重复处理。
-
离线更新:每天凌晨重新计算销售指标,更新前一天指标数据

第二种方案:MPP + 主键
-
使用场景:适于外部使用场景,外部系统从 Mpp 数据查询、分析数据
-
技术方案:MPP 选用 PG CITUS 数据库,在 MPP 数据库建表,对订单号等唯一性字段设为主键。
未来架构演进与优化
目前整个底层处理系统都是基于业界的开源框架,系统还远远谈不上完美,尤其是做底层数据是个比较细致、辛苦的工作,数据质量问题频发,由于没有监控系统,经常是被动发现、解决问题。由于新业务长势喜人,数据清洗逻辑变更是家常便饭,代码发布频繁。
在实践过程中,对系统进行架构优化设计,可以增加两个模块。
-
数据质量监控: 通过配置质量监控规则, 对实时、离线数据进行规则校验,支持:抽样校验、全量校验两种方式, 对数据异常通过告警方式及时通知开发人员。
-
数据清洗规则配置系统:让清洗逻辑抽象成可配置的规则,通过定义变更清晰规则,实现数据清洗逻辑的变更,这里的难点是规则抽象化,经过技术预研,初步确定使用 Drools、Groovy 两种方式配合实现清洗规则配置化。
总结与展望
日志处理分析系统作为数据挖掘、BI 分析等高阶应用的幕后支撑, 起着承上启下的作用, 尤其对于业务线多、大数据量场景,没有系统化平台化的支撑,大数据终将是一句空话。我相信不止是算法模型,底层的数据质量、时效性、系统稳定性,都将成为智慧零售的胜负手。